佛教大学図書館におけるウェブスケールディスカバリーSummonの導入効果と課題
2014 年 57 巻 2 号 p. 99-108
詳細
2014 年 57 巻 2 号 p. 99-108
佛教大学図書館では,2011年4月よりウェブスケールディスカバリーのSummonを導入している。ウェブスケールディスカバリーは,ディスカバリーサービスの次世代型といえる存在である。導入当初,検索対象のコンテンツは,雑誌記事索引に由来するデータが中心であった。このため,利用者は冊子体の所蔵へのアクセスを目的として,論文検索を行っていたが,CiNii Articlesの登載後には,電子コンテンツへのアクセスが優勢になった。現状,電子ブックについては,国立国会図書館デジタルコレクションのコンテンツが圧倒的多数を占めている。そのほか,学内イントラネット専用の新聞コンテンツとの連携も,利用者サービスの改善につながった。今後ディスカバリーサービスにおけるビッグデータの活用が進むだろう。ディスカバリーサービスを情報発信ツールとしてどうデザインし,利用するか,図書館やデータベースベンダーの手腕が問われるに違いない。
佛教大学図書館(以下,本館)では,2011年4月にProQuest(旧Serials Solutions)社のSummon1)を日本で初めて導入した2)。時に「ウェブスケールディスカバリー(web-scale discovery)」,あるいは単に「ディスカバリーサービス(discovery service)」などと各種の呼称で認識されるSummonであるが,本館においては2年半を超える実運用を通して,利用者に与えた影響や課題が明らかになってきた。本稿ではその具体的事象や,課題解決のための取り組みなどについて報告する。
なお本稿においては,2013年度と銘打った統計が提示されるが,執筆の都合上,いずれも2014年1月末までのデータによって作成されている。この点をご寛恕いただきたい。
1990年代後半の電子ジャーナルやウェブデータベースといった,デジタル化された学術コンテンツの量的拡大は,これらに特化した網羅的な検索機能の必要性を図書館に問いかけることとなった。このような状況に対応すべく,最初に登場したシステムが,横断検索(メタサーチ)や統合検索(フェデレイテッドサーチ)と呼ばれるシステムであった。
2.2 横断検索(統合検索)の仕組みと弱点横断検索の仕組みは以下のようなものである。すなわち,①利用者が単一の検索窓にキーワードを入れて,検索ボタンを押すと,②登録されている複数のデータベースのそれぞれにキーワードが送信され,各データベースにおいて検索が行われる。その後,③これらデータベースごとの検索結果が,随時横断検索側に返され,④横断検索は,受信した検索結果をユーザーインターフェース上に統合して表示する,というものである。
このように簡易な技術でデータベースを網羅的に検索できる横断検索は,欧米を中心に急速に普及したが,一方で弱点も存在していた。それは
電子コンテンツの出現は,図書館の情報検索機能について,横断検索に代表されるような,新たな必要性を提起した一方で,その検索結果の「見せ方」に対しても新たな需要を喚起した。つまり,①冊子に留まらず多様化したコンテンツをデザイン的に洗練された検索結果を通じて提供できること,②その検索結果を用いて,ユーザーインターフェース上に,利用者の新たな知見や発見を導けるような環境が提供できること,などが新たに求められるようになってきたのである。このような需要に応じて生まれたシステムが,当初,次世代OPAC3),4)と呼ばれた一群のシステムであった。近年,これらのシステムは,その「発見を導く」という目的に鑑み,「ディスカバリーサービス」と称されることが一般的となっている。
図1に,ディスカバリーサービスの1つであるAquaBrowserの検索結果画面を示す5)。
画面右側で検索キーワードと他の単語との相関性をワードクラウドと呼ばれる仕組みで図式化し,利用者へのサジェスチョンを行っていることが特徴的である。また画面左側のファセットと呼ばれる絞り込み技法は,ディスカバリーサービスに共通の要件となっている。

横断検索は,電子コンテンツに対する網羅的検索の要求に応じて生まれたシステムであり,一方ディスカバリーサービスは,多様化したコンテンツに適した,洗練された検索結果を求める声に応じて出現したシステムであった。従って横断検索だけでは,洗練されたインターフェースは望むべくもなく,またディスカバリーサービスだけでは,多くのデータベースを横断的に検索する,といった機能は有していなかった。このためディスカバリーサービスのインターフェース上に,横断検索の結果を表示する,という運用が一時期注目されたこともあったが,横断検索の弱点を補えるものではなく,広く受容されることはなかった。
このような状況下で,横断検索のもつ弱点を補完し,ディスカバリーサービスの長所を生かした「次世代型」として登場したシステムが,ウェブスケールディスカバリーである。
2.5 ウェブスケールディスカバリーウェブスケールディスカバリーは,従来からのディスカバリーサービスの特徴を踏まえたうえで,以下のような4つの要件を有している6)。
この中で,もっとも着目すべきは(2)であろう。これはウェブスケールディスカバリーが,あたかもGoogleのように,多くの商用データベースから収集した検索データを統合し,自身の検索に特化したインデックスを内部に構築しているということである。したがって,横断検索のように,検索にあたって各データベースにアクセスする必要はもはやない。検索が自己において完結できることで,横断検索が有していた検索のレスポンスや再現性,信頼性に対する問題はすべて解消されたと言える。
またウェブスケールディスカバリーは,その名が示すように,検索対象となるコンテンツのスケーラビリティを,図書館ローカルとしてのインスティテューションスケール(Institution-Scale)から,世界的グローバルとしてのウェブスケール(Web-Scale)にまで拡大させた。この検索対象の拡大の意義は非常に大きく,図書館における新たなパラダイムであると考えられている7)。
図2はSummonにおいて,検索フレーズをあえて入力せず,本館で検索対象となるすべてのレコードをヒットさせた画面である。
実際のところ,ウェブスケールディスカバリーは,巨大な2次情報データベースであり,それ自身が1次情報を有しているわけではない。しかし,2次情報のレコードに限られるとはいえ,9.5億件以上というレコードを有することは,1次情報へのアプローチ手段としての圧倒的な潜在力を如実に示している。

本館におけるSummonは,横断検索の後継として導入され,「お気軽検索」という名前で,利用者に認知されている。お気軽検索の主要なターゲットは,専門教育に入る以前の学部の1・2回生や通信教育課程の学生であり,たとえば専門領域のデータベースに習熟しているような大学院生や,英語文献を自在に操るような教員を対象としたものではない。したがって,本館としては,日本語の論文情報コンテンツを最も重要視している。
3.2 日本語コンテンツの検索対応お気軽検索において日本語コンテンツが,検索対象のメタデータとして登載された時系列は表1のようになる。

ここで示された登載時期はあくまでも,データベースの契約情報などに照らして,お気軽検索で検索が可能になるように設定された時期である。ゆえに他館と必ずしも同時期とは限らない。
ここで注目すべきは,2011年4月の導入の当初から,2012年9月のCiNii Articlesの登載に至るまで,お気軽検索における大規模な日本語の論文情報コンテンツは,事実上,国立国会図書館の雑誌記事索引のみであったということである。
3.3 雑誌記事索引の影響本家の雑誌記事索引は2次情報データベースであり,そこから1次情報へ誘導する機能は有していない。しかしお気軽検索においては,雑誌記事索引由来のレコードから,リンクリゾルバへのリンクを形成することで,1次情報へのシームレスな誘導に道を開いたことに特徴があった。また1次情報そのものに誘導できなくても,たとえばリンクリゾルバを通し,本館所蔵雑誌のOPACレコードへと誘導することで,利用者が1次情報にアクセスしやすい環境を整えた。
図3は,お気軽検索の検索回数に対する,お気軽検索からリンクリゾルバを通じて本館の雑誌書誌(冊子体レコード)にアクセスを行った割合である。2011年度には,お気軽検索で論文タイトルを検索し,そこからリンクリゾルバを通じて本館の「冊子体」所蔵レコードへという流れが,多い月で12%ほど存在していた。これは,雑誌記事索引の収録対象誌が必ずしも電子化されているわけではない,ということに起因するものだと考えられる。
しかし2012年度以降,利用者において,そこまでの冊子に対する指向性はみられない。そこには2012年9月のCiNii Articlesの登載の影響が反映している可能性がある。

正直なところ,CiNii Articlesがお気軽検索の利用者に与えた影響を定量的に判断することは難しい。というのも,Summonにおいては,データベースごとの利用統計を取得する機能が存在しないためである。しかし2つの側面から,利用者がお気軽検索を通して,CiNii Articlesを積極的に利用するようになったことがわかる。それは,①CiNii Articlesの登載により,お気軽検索の検索回数が著しく伸びたことと,②同時期にCiNii Articlesの全文コンテンツのダウンロード数も著しく伸びたことによる。
3.4.1 お気軽検索の検索回数お気軽検索の検索回数について,2011年4月の本運用以降の推移をグラフ化したものが図4である。

検索回数の増減をもたらす要因には,多くの要素が絡んでいると考えられる。たとえば,佛教大学においては,学生を中心とした構成人員が毎年1~2%という増加を見せているが,これも検索回数の伸びに影響する可能性がある。また経年による利用者間における認知度や浸透度の向上なども,一定の影響を与えるだろう。
とはいえ,本館の場合には,図4の状況を見る限り,2012年9月のCiNii Articlesの登載が,検索回数増加の最大の要因となっているようである。とくにCiNiiレコードが存在する月と,前年の存在しない月との比較ができる,2012年9月から,2013年8月までの1年間の検索回数の推移に着目すると,前年同時期に比べて,増加傾向が著しい。
この傾向を明確に認識するために,図5において,2012年4月から2014年1月までの期間における,過去年度の同月に対する検索回数の伸び率を示す。
図5では,CiNiiレコードの登載状況を基準にして,3つの時期を設定した。中央の(2)期は,上記のCiNiiレコードの「存在月」から前年同月の「非存在月」を比較した時期である。同様に(1)期は,CiNiiレコードの「非存在月」から前年同月の「非存在月」を比較した時期,(3)期はCiNiiレコードの「存在月」から前年同月の「存在月」を比較した時期に当たる。母数となる月数が異なるという問題があるが,各時期における平均の伸び率を算出すると,(1)~(3)期までのそれぞれで,23%,70%,12%であった。ここからは(2)期の伸び率が,他の時期に比して突出していることがわかる。構成人員の増加を加味したとしても,この伸び率は有意に大きく,CiNii Articlesの登載が検索回数を大幅に引き上げたことを証明しているといえる。
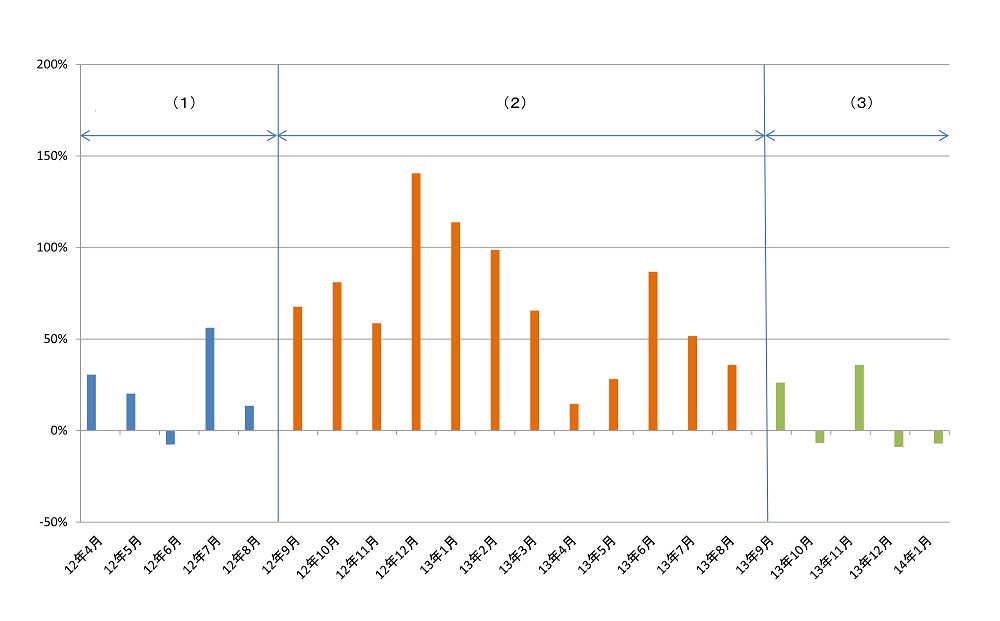
図6において,CiNii Articlesのダウンロード回数の前年同月に対する伸び率を示す。(1)~(3)期までの区分は,図5に準拠している。
(1)~(3)期のそれぞれにおける平均の伸び率は,-2%,23%,-10%であった。やはり構成人員の増加を加味しても,(2)期の伸び率は十分に大きい。状況証拠としてではあるが,ここからは,お気軽検索におけるCiNiiレコードの検索対応が,CiNii Articlesのダウンロード回数を押し上げている姿が浮かび上がる。

結局のところ,従来存在していた「お気軽検索から冊子体」という指向性は,CiNii Articlesの検索が,お気軽検索上で行えるようになったことで,埋没してしまったと考えられる。無論,雑誌記事索引に由来し,CiNii Articlesに収録されていない論文レコードの数が減少したわけではない。しかし,CiNii Articlesに由来し,「ダウンロード可能な全文テキスト」へのリンクを含むレコードの量が大幅に増加したことで,冊子体へと向かうレコードが目立たなくなり,結果として,利用の中心が電子に移ったと考えるのが妥当であろう。かくして本館の利用者も「お気軽検索から電子コンテンツ」という明確な指向性を有するようになったといえる。
本館の利用者は論文情報以外に,どのような情報を入手する目的でお気軽検索を利用しているのだろうか。無論,利用者は千差万別であり,その使い方を逐一観察できるわけではない,だがいくつかの要素から,その断片を把握することは可能である。それは①検索結果の絞り込みに使用された「コンテンツタイプ」(フォーマット)と,②検索キーワードである。
たとえば図7に,絞り込みを行った際に指定されるコンテンツタイプの割合を示した。
利用者は「雑誌論文」を指定する率がもっとも高いが,ついで「図書/電子ブック」「新聞記事」を指定して絞り込む動きがみられる。

「図書/電子ブック」については,いわゆるOPACから取り込まれた冊子体の所蔵情報を求めている場合が多いと思われるが,ジャパンナレッジの東洋文庫や文庫クセジュ,ネットライブラリーの国史大系,国立国会図書館デジタルコレクション(近代デジタルライブラリー),青空文庫などへのアクセスを求めての行動も含まれていると考えられる。
これらの日本語を中心とした電子ブックのメタデータであるが,お気軽検索においては現状タイトルや出版社といった従来型の書誌情報にとどまっているものが多数を占める。とはいえ,ジャパンナレッジ由来の東洋文庫や文庫クセジュについては,図書の概要(あらすじ)に関しての検索が行えるようになっており,従来に比べメタデータのエンリッチメントがなされている。図8に「全ユーラシア大陸」という言葉での検索結果のレコードを示す。

図書の概要についてのスニペット表示上に,太字で「全ユーラシア大陸」との文字が見え,該当の文字列がヒットしていることを示している。ただし,スニペットについては,ライセンスの関係から,学内からのアクセス時のみ表示される設定となっている。
なお東洋文庫や文庫クセジュの場合には,検索結果のレコードから,ワンクリックで本文へのアクセスが可能になっている。また,国立国会図書館デジタルコレクションの場合には,NDL Searchの詳細画面を介してのアクセスとなっている。一方で,NDL OPACの書誌を利用して青空文庫にアクセスするといった場合には,リンクリゾルバを介すことで,シームレスな電子コンテンツへのアクセスが行えるように配慮している。
現在,本館で利用できる電子ブックの総数は,約36万タイトルと推定される。内訳としては,国立国会図書館デジタルコレクションが約35万タイトルと圧倒的な多数を占めている状況にあるが,本資料については,お気軽検索からのアクセスに関する問い合わせが多く,よく利用されている感がある。
4.2 新聞記事コンテンツタイプにおける,「新聞記事」の指定については,検索キーワードとして記録された「アベノミクス」や「尖閣」「ビットコイン」といった時事用語とともに,お気軽検索における新聞記事の検索需要を示すものであると考えられる。とはいえ,これについては若干の補足が必要である。実はSummonのグローバルな日本語コンテンツにおいては,現状,新聞やニュースといったデータベースの収録がない。このため,日本語の時事的な用語で検索を行っても,そのままでは利用者が満足できるような結果を得ることができない。またこの場合,記事が存在しないため,コンテンツタイプとして「新聞記事」が表示されることもない。
しかし本館においては,2011年10月に,お気軽検索のローカルコンテンツとして,14万件の戦前期の新聞記事データを登載した。このため日本語検索の際に,コンテンツタイプとして,「新聞記事」が比較的表示されやすい環境にあった。図7での「新聞記事」の出現はこの状況の反映であると考えられる。
とはいえ,アベノミクスといった現在進行形の時事用語については,戦前期の新聞記事はまったく意味をなさない。したがってSummonが,早急にいずれかの新聞社のデータベースを登載し,カレントの記事データについて検索できるようになることが望ましい。しかしさまざまな要因により,現時点で登載の許諾が得られる見通しは立っていないようである。
4.2.1 ローカルコンテンツとしての供給実のところ,グローバルコンテンツとしての新聞記事の登載がかなわなくても,ローカルコンテンツの枠組みで,解決できる可能性もある。実際,本館では,「京都新聞電子縮刷版」のウェブサービス化事業と組み合わせて,状況の打開を図ることができた。
京都新聞電子縮刷版とは,本館で2006年より購入している,地元紙「京都新聞」のアーカイブコンテンツである。DVD形式により販売されており,1枚に1か月分の紙面と記事のメタデータが併せて収録されている(図9)。本館では従来,DVDサーバーを介しての提供を行っていたが,検索などの使い勝手が悪く,利用が伸び悩んでいた。このため,京都新聞側と覚書を締結したうえで,DVDをコンバートし,ウェブサービスとして提供する事業を企画した。同時に本館のローカルコンテンツの扱いで,新聞記事のメタデータをお気軽検索に取り込むこととした。
ウェブサービスの学内向けリリースは2013年10月に行われた。同時にお気軽検索における対応も完了した。これにより利用者は,学内ネットワークを経由してお気軽検索にアクセスする場合に限り,論文や図書に加え,近年の新聞記事データを対象とする統合的な検索が可能になった。

図10は利用者の京都新聞電子縮刷版へのアクセス(ログイン)回数と,お気軽検索経由のアクセス割合を示すグラフである。2013年10月のウェブサービスのリリース時には,ウェブサイト上でのアナウンス効果か,トップページからのアクセスが多かったが,その後は,お気軽検索経由のアクセスが多数を占める状況になったことがわかる。またログイン回数の増加も衝撃的である。利用者がお気軽検索において,新聞記事データとそれを含むデータベースの存在を「発見」しつつあることが,この統計からわかるだろう。

ウェブスケールディスカバリーの4つの要件は,このサービスの未来を考えるうえで極めて示唆的である。たとえば,クラウドサービスとして,最新のセントラルインデックスを有することは,ディスカバリーベンダーが,学術情報について,全世界の利用動向を把握できるということを意味する。すなわちウェブスケールな利用統計,言い換えれば学術情報におけるビッグデータの活用に道が開かれることになる。そこからは学術情報におけるトレンドや,インパクトファクターとは異なる意味での,利用者に支持されるジャーナルの情報などが,より正確な形で浮き出てくるだろう。今後の図書館は,その情報を自らにフィードバックさせたうえで,世界,あるいは国や地域としての枠組みの中で,利用者に対して,自らの存在価値を高めていく手段を考えなければならない。すなわち,図書館はウェブスケールディスカバリーを通し,学術情報におけるデータサイエンティストとしての役割を担わなければならない。
一方でウェブスケールディスカバリーは,情報の発信手段であるという視点も重要である。図書館やデータベースベンダーは,関連度という枠組みを通じ,伝えたい情報を正しく利用者に伝えるには,どういったメタデータの構成にし,どういった水準で提供すべきなのかを突き詰めていく必要がある。実際,ユーザーインターフェース上の可視的なデザインだけでなく,背後の不可視的なメタデータのデザインに至るまで,「デザイン」こそが,ディスカバリーサービスの根幹である。ウェブスケールディスカバリーの主たる利用者が,次世代を担う「世界中の」学生である以上,日本の図書館やデータベースベンダーであっても,メタデータの最適化に向けた努力を怠るわけにはいかない。セントラルインデックスにおいて,日本発のデータが埋没することは,技術立国日本そのものの埋没につながるのかもしれないのだから。