著者抄録
最速で最善の答えを導き出せると,統計学が今,注目を浴びている。しかしどのようなデータを,どう分析し,どう生かしていくか,明確にわかっている人は少ないのではないだろうか。そこでまず,偏りを避け客観的な結果を導くランダム化比較実験(ランダム化比較試験)や,日本の高品質生みの親・デミング博士のマネジメントの根幹となった統計学を紹介する。そして実践編として,リサーチデザインを駆使し,仕事に生かせるデータ分析の理想サイクルを作る方法を伝授する。
本稿は2016年12月1日に科学技術振興機構東京本部で開催された第13回情報プロフェッショナルシンポジウムの特別講演を,編集事務局で編集したものである。なお,同シンポジウムの開催報告は,『情報の科学と技術』vol. 67 no. 5(2017年5月)に掲載予定である。
はじめに
皆さん,こんにちは,西内です。今,経歴をご紹介いただきましたが,医学部を卒業した私がなぜビジネスの話をするのか,疑問に思われた方も多いのではないかと思います。医学部といってもお医者さんになるコースを卒業したわけではないのです。だからここで急に体調が悪くなる方がいらっしゃっても,残念ながら私は全く力にはなれません(笑)。
ではなぜ,医学部を目指したかというと,日本には,統計学部とか統計学科というものがないのです。そこで人間を対象とする統計学をどこで勉強できるのか探したら,医学部だったんです。人間をハードとソフトの両面から研究する医学部へ,統計学を勉強しに進学したというのが経緯です。
そこでもともと興味のあった生活習慣病の予防を勉強しました。たばこを吸いたくない気持ちにさせるには,どういうメッセージや都市環境をそろえれば,行動がどれくらい変わるのかを調査・分析し,何が大事な要素かわかってきました。ところが,その結果を世の中にどう役立てていいか皆目見当がつかなかったのです。
東大の教員をしていた頃に,たまたま知り合いの会社が受注した政策調査を手伝ったら面白くて,まだ論文で発表されていないような統計手法まで作り出して,めちゃくちゃ頑張りました。でもせっかく頑張って納品した成果が,なんと今になってもまだ世に出ず,もちろん全然使われてもいないのです。残念だ,どうしたらいいかなと思っていたとき,ちょうどビッグデータやデータサイエンスという言葉が注目を浴び始めた時期だったので,むしろ企業のお手伝いをしてはどうかと。データを使った分析でその企業がもうかるのだったら,企業のかたはもっとスピーディーに実行に移されるのではないかと思ったのです。
さらにはこんな夢も描きました。送られてきたアンケートを見て「データの取り方すらわかっていない,ひどいアンケートだ」と判断できるリテラシーを,誰もがもつ世の中にできたらいいな,その一助になれるかもしれないと,コンサルティング業務を始めました。
ランダム化比較実験が示した,衝撃のEvidence-Based Medicine
医学では統計学をどう使っているか,少し話をしたいと思います。経験と勘とロジカルシンキングで考えましょうという世界は,10年か20年前ぐらいにはもう終わりを告げています。ドラマの「ドクターX」などは,恐らくこのあたりで意思決定をしているように見受けられますが(笑)。
もし心臓発作で病院に担ぎ込まれても,今では一命を取りとめることはまあまあできるようになっています。しかしそれで絶対大丈夫というわけではありません。その後,不整脈でたくさんの方が亡くなっていることは,お医者さんでしたらよく知っている事実です。ロジカルに考えられる皆さんですから,不整脈で亡くなるのだったら,不整脈を止めればいいじゃないかと思いますよね。そこで1980年代ぐらいまでは,急性心筋梗塞の方が一命を取りとめたら,不整脈の薬を使うというのが一般的でした。
その薬について実際にどれくらい効果があるか,ある人が検証し1),これが大問題になりました。そのグラフが図1です。本来はもう少し研究を続けるはずが,事の重大さに驚き,早く世に知らせなくてはと途中結果を報告したら,最も権威ある米国の医学雑誌『The New England Journal of Medicine』に載るほどインパクトのある結果だと注目を集めたのです。
この研究は,参加者1,400人ほどをランダムに半々に分け,全員(100%)が生存しているところからスタートします。50日,100日と日数が経過するにしたがって,生存率を示す線は階段状に下がっていきます。これは少しずつ人が亡くなっている状態を示しています。
青と緑の線は1点の差異を除いて,ほぼ一緒です。緑グループは当時一般的に使われていた不整脈の薬を,青グループはダミーの薬を使っています。図1を見ると,緑グループでは500日間で6~7%ほどの方が亡くなっていますが,効果がないはずの薬を使っている青グループは2~3%ほどしか亡くなっていないのです。この結果は「いくらロジカルに正しかろうが,実際にデータを集めてみると逆効果だということが存在しうる」ことを歴然と示してしまったのです。
このような実験を「ランダム化比較実験(ランダム化比較試験)」というのですが,この結果は大変議論を呼びました。一番多かった反論が,「均等に分けたといっても,たまたま緑の方に状態の悪い患者さんが多くいただけなんじゃないのか」でした。しかし1,400枚のコインを一斉に投げたとき,やたら表が多いということはまずありません。つまりランダムに半々に分けるということは,完璧に一緒ではないにしても,大体均等に分かれるということです。どちらかに男性が多い,高齢者が多い,健康状態の悪い人が多いということにはほぼならないんです。もちろん確率としてゼロではなく,あってもそれは0.06%ぐらいの確率です。
つまりこの研究結果から,0.06%の確率でしか得られないような奇跡的なデータが,たまたま得られたと考えますか。あるいは,自分が心臓発作を起こしたとき不整脈の薬は使ってほしくないと考えますか。そういうことなんです。恐らくほとんどの方は,この薬は使ってほしくないと考えるのではないでしょうか。
この話は,実は,「Evidence-Based Medicine」の典型的な例です。Evidence-Based Medicineの意味は,「論より証拠」。なんと江戸時代のいろはがるたの「ろ」でいきなり出てくる「論より証拠」です。話はそれましたが,「Evidence-Based Medicine」という言葉が最初に登場したのは1992年か1993年です。それがあっという間に皆さんの生活に入り込んできました。2002年に成立した米国の教育関係の法律には,100回もこのエビデンスという言葉が登場するそうです。教育はエビデンスに基づいて,ちゃんとした効果のあるものを行いなさいといっているのですね。たったの10年で,法律の中に何回も出てくる言葉なんてなかなかありません。
ビジネスの世界ではエビデンス・ベースト・マネジメント(Evidence-Based Management),行政の世界ではエビデンス・ベースト・ポリシー(Evidence-Based Policy)というようにありとあらゆるところでエビデンスに基づきなさいという表現が生まれています。では,論より証拠の「証拠」に当たるものは何でしょう。それが「データ」なんです。

図1
不整脈の薬の有無と生存率
デミング博士の「Kaizen」で,右肩上がりの日本へ
実は世界史上,最も統計学でもうけた国は日本なんです。世界中のビジネススクールでは,「Kaizen」という日本語を1回は使っていると思います。日本人からみると,よくしていくことは全部Kaizenですけれども,彼らは違う意味で使っています。データをみながら,現場レベルで品質とか生産性を上げ続ける継続的なプロセス(QC活動)を,Kaizenと表現するそうです。
このKaizenは日本にもともとあった文化ではなく,意外と歴史が浅く,戦後,GHQが連れてきたウィリアム・エドワーズ・デミング博士注1)(図2)が,この知恵の土台を作ったといわれています。彼のアイデアを,石川馨(かおる)をはじめとした日本の工学や統計学の専門家がうまくかみ砕き,トヨタほか多くの企業が実践し普及したというのが歴史的な流れです。
デミング博士は国勢調査などの設計のために来日した統計学の専門家です。GHQの東京本部から大阪本部へ電話したときの通話品質があまりにも劣悪で,日本国内の製造業をはじめ産業界の経営者に対して統計学を使うともうかる,エンジニアに対しては統計学をこう使えばいいという講義をされたそうです。
実際,戦後すぐ(1945年)から,どれくらい日本の工業が変わったのかというと,図3のようにどんどん右肩上がりになっています。最初は数兆円だったのが,1990年代には300兆円を超えています。もちろん統計学だけの成果ではないのですが,少なくともこの時期,品質が大きく変わっています。
「バック・トゥ・ザ・フューチャー」という1985年の映画をご覧になったことがありますか。映画の中で,80年代の若者がタイムスリップし,50年代の若者と話をする場面があります。80年代の若者は「日本製品は格好良くていいだろう」と自慢するんですよ。一方,50年代の若者はその話を聞いて,「何だ,日本製品なんて壊れやすいパチモンじゃねえか」みたいなことを言うわけです。つまり50年代の粗悪品からわずか30年で,ジャパン・アズ・ナンバーワン,日本製品は格好よくて世界でも最高レベルの品質を備えているというイメージが確立したのです。
余談ですが,80年代までデミング博士は米国内では無名だったそうです。貿易摩擦が起きるくらい日本が右肩上がりで伸びると,なぜだと米国人は研究を始めた。すると「米国人のデミング博士が伝えたらしい」「えっ,誰だ」という話になり,彼は一躍有名人に。そして大企業や政府のコンサルタント・経営顧問,90年代クリントン政権下の経済成長著しい「素晴らしい10年(The Fabulous Decade)」には委員も務められていたそうです。

図2
「Kaizen」の知恵を授けた統計学者
ウィリアム・エドワーズ・デミング(1900~1993年)

図3
デミング博士後の日本の工業の推移
マネジメントの根幹とは
デミング博士は,「米国と日本ではマネジメントの仕方が違う。統計学うんぬんという前に,それがとても大事なポイントだ」とよく話をされていたそうです。
デミング博士のころの米国的なマネジメントは,管理する人・マネジャーが中心でした。マネジャーは現場に目標を指示し,現場からの報告に対して褒美をあげたり罰したりして成果を上げようとしていました。ところが当時の日本にはマネジャーに当たる人がいません。マネジャーという肩書があっても労働者と同じ方向を向き,一緒に現場レベルで生産性や品質を上げようとしていました。デミング博士は,著書『デミングで甦ったアメリカ企業』(草思社)2)の中で,米国のマネジメントの限界を理解してもらうために,実際に行ったビーズ実験を挙げています。
赤ビーズ(不良品)と白ビーズ(優良品)がそれぞれたくさん入った大きな容器を用意します。50個の穴が開いたヘラを使って,白ビーズだけを注意深く取り出していきます。1回ヘラを突っ込んでビーズを取り出すのを1日の仕事と設定し,6人が労働者役を,感じの悪いマネジャー役をデミング博士が演じました。1日目,つまり,1回目のトライ後の結果が図4です。6人のうち,一番成績のよいジョディーさんの不良品は5個,ポーリンさんとアールさんの不良品は12個でした。
この結果を受けマネジャーは,「ジョディーを見習え。注意深くやれば,不良品だって5個ぐらいにできるんだよ」「それに比べポーリンとアールは,たるんどる!」と怒るんです。しかしその後,ジョディーさんの不良品率が毎日ちょっとずつ上がり,8個になったり,10個を超えたりしていきます(図5)。感じの悪いマネジャーは「おい,最初に褒められたぐらいでいい気になりやがって」と今度はジョディーさんを非難します。実はこのマネジャーの叱咤(しった)激励は,全く意味がないんです。
なぜかというと,いくつ赤ビーズをすくうかは,確率的なばらつきで説明することが可能です。実は容器の中には20%の割合で赤ビーズが入っています。慎重にやろうが,ヘラの角度が45度だろうが30度だろうが関係なく,20%ぐらいは赤ビーズをすくってしまうんですね。ジャスト20%(50個中10個)になる確率が一番高く,全体の約14%(図6)です。毎回ジャスト10個になるわけではなく,9個や11個になる確率も10%以上あります。めちゃくちゃ確率は低いけれど,20%の50乗という計算をすると,たまたま全部白というのも厳密にゼロではない確率で出現します。
つまり20回に1回ぐらいは5個以下になるんです。それをいつ誰が引き当てるかというだけの問題で,別にジョディーさんが初日にやる気満々だったからとか,すごい能力があったからではないのです。マネジャーが目標だけを示し,達成できたかどうかを褒めたり叱ったりしてもあまり意味がないと,この実験は立証したのです。
確率的なばらつきが含まれている状態では,何がばらつきの原因か理解しそれをなくす対策を取らないと,いつまでたっても解決しません。ビーズ実験なら,たとえば最初から赤ビーズの割合(不良品)を少なくする,ピンセットを配布して白ビーズだけつまみ取らせるなどをすれば不良品率は下げられるのです。
デミング博士は,ここを何とかしたい,このやり方では駄目だという現場のアイデアをうまく吸い上げ,ばらつきに影響を与えている根本的な原因を探り,その原因を取り除くようプロセスを変換し「Kaizen」する,それがマネジメントの根幹だと教えています。
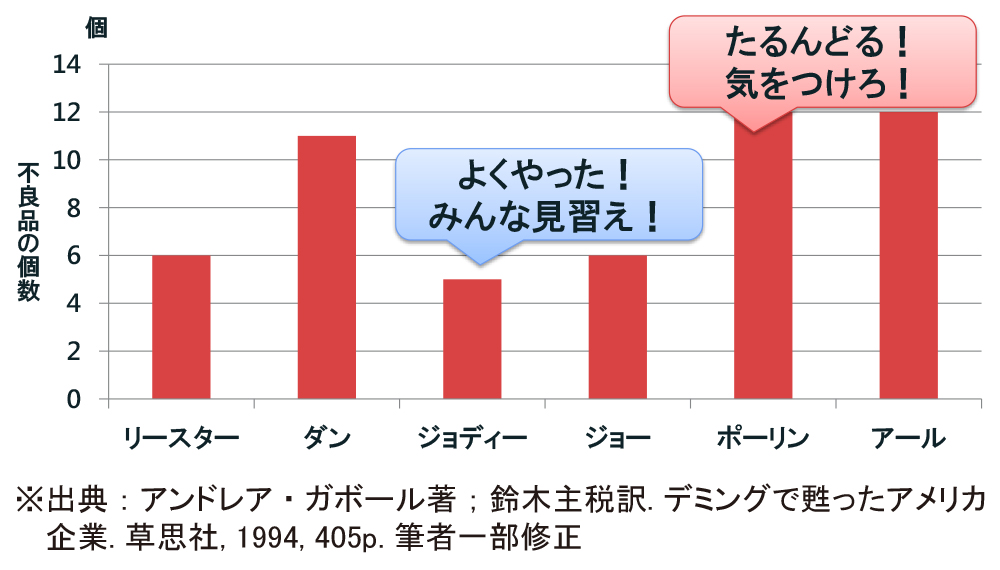
図4
実際の結果(1日目)

図5
その後のジョディーの不良品率

図6
欠陥品数の理論上の分布(赤玉の割合は20%)
データ分析後,どうアクションを取るか
デミング博士を例に品質向上の話をしてきましたが,少なくともある時期まで,品質というのはそのまま利益に直結します。だって同じ値段で品質がいいものと悪いものがあったら,絶対品質がいいものを買いますよね。
一方で,品質が高いイコール不良品が生まれにくい,無駄がないということにもなります。エネルギーを使って,手間暇かけて作り,その結果できたものが不良品だったら捨てるしかありません。それは無駄なコストですよね。さらに気づかずに出荷し,購入先でトラブルが起きたら補償もしなくてはいけない。膨大なコストになってしまいます。
ここで重要なのは,品質以外にも利益につながるたくさんの要因があるということです。廃棄在庫を減らす,商品のターゲットを見直すなどいろんな指標があります。
ではデータには,どのようなものがあるかというと,B to C(Business-to-Consumer:企業と消費者との取引)のビジネスならば,企業はブランドイメージや商品の認知率など顧客アンケートからさまざまなデータをもっているでしょう。従業員についてなら,どういう勉強をしてきたか,筆記試験や面接での評価,採用後どのような経験を積んだかなどのデータをもっているはずです。
得られたデータの分析結果から,どういうアクションを取ればいいのか説明しましょう。大きく3つの考え方しかありません。
1つは,分析結果を基に変えることです。もっと買ってほしい,もっと売ってほしいというゴールを達成するならば,こういう気分にさせたら買ってくれるらしい,こういう性格は営業として売り上げが高い…など。つまり,信頼できる企業と思われることが大事なのか,親しみがある営業マンと思われた方がいいのか,何が大事なのかを分析し,それに合わせて変えなさいというのが1つ目のアクションです。
2つ目が,狙いをずらすというやり方です。たとえばお店の前を通る100人のうち女性の購買比率が高い商品ならば,女性がたくさん通る所にお店を出す,女性が見てくれる媒体に広告を出すなど,より目的を達成しやすい人たちに狙いを絞っていく。同じコストをかけるならリターンが大きい方にかじを切り替えるのが2つ目のアクションです。
3つ目は,上記2つがどうしてもできない場合の最後の手段です。季節や天候しか要因(説明変数)がわかりませんでしたということもあります。夏に買ってくれる人が増えるとわかっても,夏にだけお店を開けるわけにもいきません。
たとえば店に来客が多いときは,対応するスタッフが多くないと機会損失になってしまいます。逆に誰も買いに来ないのに,従業員がスタンバイをしていては意味がありません。無駄なコストをかけず,しかし機会損失なく,リソースを最適化していくためにはどうしたらいいのか。変えられない条件ではなく,自分たちのもっているリソースをうまくコントロールしていきましょうというのが3つ目のアクションです。
分析が失敗する理由
ついでに話しますと,いろいろ分析をやったが失敗してしまったという話をよく聞きます。その理由は,以下の2つのどちらかといえるでしょう。
1つが,利益に影響を与えないデータ同士の関係性を分析してしまったケースです。最近,ショッピングモールでセンサーなどを使い,スマホを持っているお客さんの動線を把握する試みが行われています。そのデータを基に出てきたレポートが,「一番の発見は,午前中に来店した人の滞在時間が長くなりがちです」でした。
そこで「滞在時間って,長いほどいいのですか」と伺うと,「一概には言えないね。サクッと来てサクッとお金を使って帰ってくれた方が駐車場などの有限リソースには効果的だし,でも滞在してくれた方が買い物をしてくれる気がするし。どうだろうねぇ」。これ,分析する必要がない話だと思います。いくら高度な手法を使おうが,どれだけハイテクなデータであろうが,利益にどうつながるかわからなかったら,企業のもうかり方には関係ないですよね。
もう1つが,その分析は当たり前じゃないかというケースです。「ファミリーレストランに来店するお客さんが1人増えると,売り上げも1,000円ぐらい増えます」という分析結果。これ,君はファミリーレストランへ行ったことがないのか,という話ですよね。ファミリーレストランのメニューは大体1,000円ぐらいだし,500円で済む人はお茶だけ頼む人で,1,500円支払った人はステーキを食べたかデザートも頼んだかどちらかではないでしょうか。1億円もかけて得られた結果がこれではうれしくもなんともない。こんな失敗を今でもよく聞いたりします。
ボトルネックのないデータ分析の,理想的なサイクルを作れ
ここまで,こうやればビジネスってもうかるという話をしてきましたが,実際に世の中の人がうまく統計を活用できているかというと,残念ながらそうでもありません。私のところに相談に来る皆さん,お困りのようです。ビッグデータを活用する際に何に困っているのかを調査した,日本情報システム・ユーザー協会の調査結果があります。その上位5つを示したのが図7です。
一番困っているのは,体制/組織の整備で,誰にやらせていいのかわからないということです。次は,導入する目的の明確化。つまり,「ビッグデータを使って何かやらないと遅れちゃうらしい。だけど何をしていいかわからない」ということですね。目的がわからなかったら,費用対効果の説明なんてつくはずがありません。「これからはビッグデータだ」と,多くの企業が何億円というお金を大々的に投資していますが,実は誰が何をやったらいいのかわからない状態で,日本企業の半分ぐらいの方はお困りなわけです。
データを集め分析し,その結果を基に,時には取締役などのレベルまで話が上がり意思決定されます。それから,現場がその内容に沿って実際のアクションを取ります。
重要なのはアクションを取って終わりではなく,その後の結果をデータに取ることです。なぜなら,こうしたらいいという分析結果は果たして本当に効果があったのか,きちんと評価しておかないとずっと見当違いのことをし続けることになってしまうからです。図8の「データ→分析→意思決定→現場」の循環サイクルを作れるかどうかが,企業でデータを活用できるか否かの境目だと思います。
しかし,図8のサイクルのどこかで引っかかり止まってしまっては,データをそろえ分析することすらできません。これからそれぞれの引っかかり(ボトルネック)の例をみていきましょう。
まず,データが分析できる状態ではない,データ自体に問題がある場合です。たとえば販売データと人事データを結合して,どういう人が売り上げを上げているか分析しようと思ったときに,両方のデータベースにおいて共通IDでスタッフが管理されていないとデータの結合すらできません。
次に,分析する人が,現場に関して無知ということがあります。高額で依頼した分析の専門家が現場を知らず,「それは昔から絶対うまくいかないから」ということを提案してくるという話を聞いたことがあります。分析の専門家でも情報のインプットが足りないと分析の応用ができないのですね。これが2つ目のボトルネックです。
そして,意思決定が障害になることも多々あります。私の経験ですが,分析から導き出した提案に現場の人たちは「これなら絶対仕事も楽になるし,生産性が上がる。これ,いいですよ」と賛同してくれました。意気揚々と事業部のトップへプレゼンに行ったら,あんまり表情がよろしくない。「いや,君ね,世の中数字じゃないんだよ」ってすげなく言われ,「あれれ。何で俺,呼ばれたのだろう」と。こういうことが,実際には結構あるのです。逆に,現場が数字嫌いで動かなかった場合もあり,これもまた無為なことです。

図7
ビッグデータ活用の課題
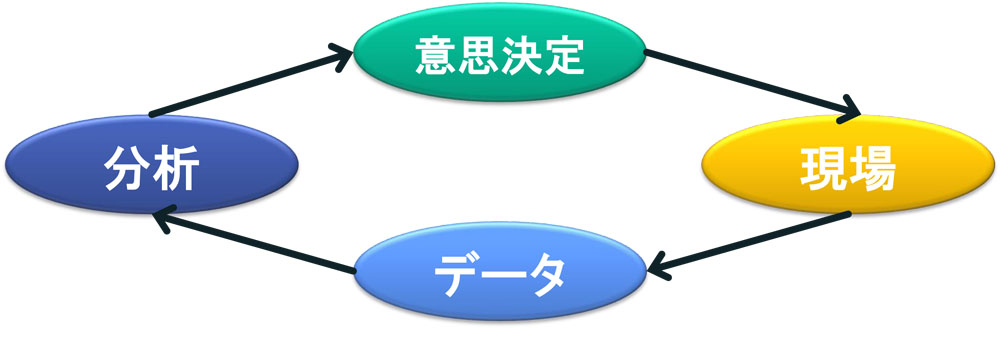
図8
データ分析の理想の状態
リサーチデザインで,共通言語を作れ
では,ボトルネックをなくすために何をしたらいいのでしょう。そこでご紹介したいのが「リサーチデザイン」という考え方です。リサーチデザインとは,本来,研究者が研究するにあたって,どのようによい研究課題を考え,またその課題に対してどのような調査や分析を行うべきかを考えるものです。米国の大学では授業が組まれているらしいですが,日本で体系的に教えられているという印象はあまりないですね。
私がリサーチデザインを企業でどう実践するかというと,まず企業の組織を,管理職・経営層など意思決定する人たち,データを管理・分析するエンジニアやリサーチャー,そして現場の人たち(その他全社員)の3つに分け,「共通言語」を作りましょうと持ちかけます。リサーチデザインの中で最も重要な部分に絞り込み,グループディスカッション中心のトレーニングを半日ほどやると,意思決定する人もエンジニアも,現場の人たちも大体何をどう分析することが必要なのかわかってくるんですね。
その後,3つのグループそれぞれが別々の課題に取り組みます(図9)。意思決定グループは分析ができなくてもいいので,批判的な見方も含め,分析結果を適切に読み取れる分析のリテラシーを身に付けることを教えます。データ管理・分析グループには,オープンソースのツールだけを使って,SQLによるデータ処理とRによる分析など高度なことまで自分たちでやれるように指導します。現場グループには,Excelを使用しデータの加工から分析までにトライしてもらいます。
数日かけて上記のリサーチデザインを行って,やっとボトルネックが解消されるんです。
というのも,現場の人は,システムエンジニアがデータをどう加工し分析するのかを理解できるようになり,こことここはちゃんと整合的なIDでなければ駄目とか,変な外れ値や抜けを何とかしようという視点が生まれてきます。そして重役会でこの指標は最大化すべきだと決め,実際の分析結果からこういう施策を打ってみようと意思決定し,それが現場に届いたときに,「何か面倒くさいレポートが来た」ではなく,「この分析すべき課題は自分たちも納得できる」とか,逆に「それちょっと違いますよ」などフィードバックすることができるようにすらなっています。分析を一度でもやると,どうしてこういう分析結果が出てきたのか想像がつくようになるんです。そうすることで社内にちゃんと「共通言語」ができて,それぞれの仕事でデータ分析を生かす,よい頭がそろうことになります。

図9
リサーチデザインで行う,各グループの内容
よいリサーチデザインは,十分なエビデンスから
リサーチデザインとはなんぞやの講義は普通でしたら半日ほどかけて行うのですが,この場にいらっしゃる皆さん向けにということで,基底となる考え「よいリサーチデザインの第一歩は,十分なエビデンスから」を説明します(図10)。
エビデンスにはレベルがあり,一番下は権威の意見とメカニズムです。つまり,「偉い博士がこう言っています」という,有識者会議などでよく言われるものです。生理学的なメカニズムや,試験管の中ではどうなっている,ネズミの実験ではどうなっているという話もこの一番下のレベルです。
論より証拠なので,1人でも1社でもいいから,実際にあったケースを報告する方が重要な情報と判断されます。しかし1人だと心もとないので,何十人,何百人と集め,その中で全体的にどうだったというのが次のレベルです(事例報告)。
さらに上位が,最初にお話ししたランダム化比較実験です。ランダム化比較実験をしてどれくらいの差がついたのかが重要な情報になります。
そしてランダム化比較実験や観察研究などを考えられる限り集めて,その結果をトータルでみた場合に,本当に効果があるといえるのかというところまで結論づけましょうというのが,最上級レベルの「系統的レビュー(systematic review)」になります。
よくこういう話が出てきますよね。「こういう物質が人間のやる気を向上させることがわかりました」とか「人間の知能を向上させることがわかりました」など。科学的な報道とされているものですが,私は結構性格が悪いので,そういうものの裏を取るんです。すると大体がネズミの実験なんですね。ネズミの人生の成功って何,やる気って何でしょうね。医学部卒なのでどんな実験か想像がつきますが,知能が高いとか仕事ができるという話題では,ネズミに迷路を解かせる実験をよくやります。迷路を走るスピードを大学院生がストップウオッチで測り分析すると,この栄養成分を与えたネズミの方が迷路は得意だぞという話が生まれ,伝言ゲームを経て,報道されるときにはこれを食べた方が仕事のパフォーマンスが上がるみたいな話へと変わったりするのです。でもこれは完璧に,論より証拠の「論」に当たります。
IQや学校の勉強なんて仕事の役には立たない,特に営業は体育会系で根性ある人の方がいいみたいな話題も多いですね。この意見に対して,「私の経験では,教育とか知能って経済的な成功につながるよ」「心理学的な理論の裏付けや,マウスでの実験結果もあります」と反論されますが,これも完璧に論です。これらはすべて,このピラミッドにも入りません。

図10
エビデンスにはレベルがある
交絡要因をゼロに近づける,ランダム化比較実験
今一度,ランダム化比較実験の話に戻りましょう。若い頃は全然勉強していなかったけど,ビジネスで成功していますという人を1人連れてきたとします。ここで大切なのは,この人以外はどうなのか考えなくてはいけないということです。そういう人がいる・いないではなく,どっちが多いかという分析が必要なんです。たとえば勉強した10万人のうち25%の2.5万人がお金持ちになっていた。一方勉強していなかった10万人では20%・2万人がお金持ちになっていたのであれば,勉強しなかった人の5%ほどは,勉強することでお金持ちになったかもしれないのではないか。この差が偶然から生まれる差かどうか,統計解析などで確認していくのです。
そこには因果関係の向きというややこしい問題もあり,つまり,勉強したから所得が上がったという考え方は一つの可能性として成り立ちますが,所得が高い人が勉強していただけという逆の考えも成立します。
さらには他の要因もあります。もしかしたら社交性やIQ,非認知能力といわれるIQ以外のセルフコントロール,家庭環境などが関係するかもしれませんし,家庭外の友人や信頼できる大人がそばにいたことなども影響を与えているかもしれません。これを「交絡要因」(図11)といいますが,勉強と所得に完璧な関係がなかったとしても,たまたま交絡要因が両方に配慮して,見かけ上,勉強と所得とが関係しているという結果が出てきたりするんですね。そこで統計学では考えうる限りの条件のデータを取り,その条件を補正したうえで,果たしてどれくらいの差がつくのか分析するものなんです。
考えうる心理特性や社会環境の条件をそろえても,条件はこれで全部かという質問には誰も答えられません。まだ人類が知らない,発見していない何かの概念があって,それによって交絡する可能性もゼロではないんです。それを限りなくゼロに近づけられるのが,冒頭でお話ししたランダム化比較実験(図12)です。

図11
今回の例で考えるべき交絡要因
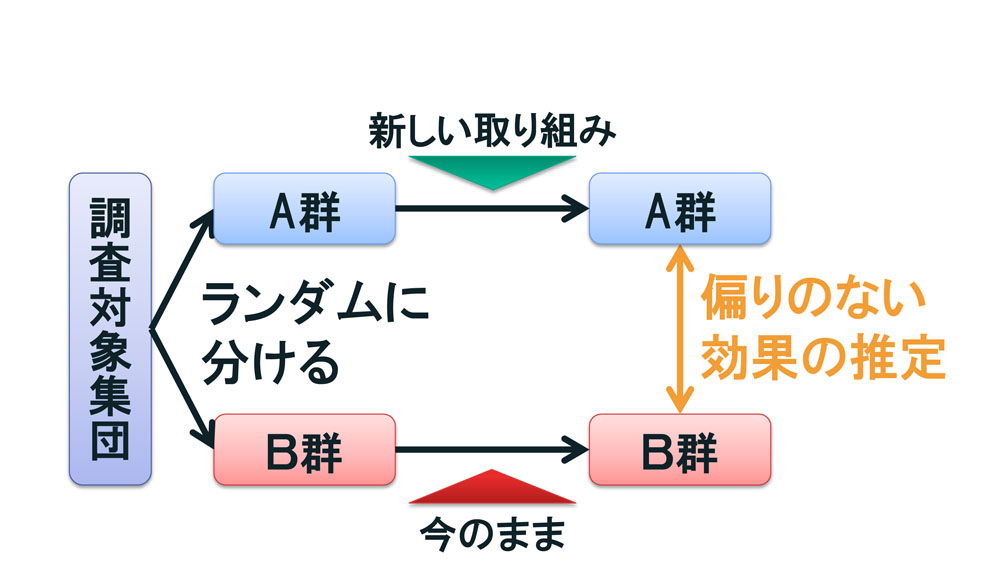
図12
最終手段:ランダム化比較実験
アイデアの宝庫・系統的レビュー
残念ながらこのランダム化比較実験にも,限界が1つだけあります。
それはランダム化比較実験に参加した人以外にもそれが当てはまるかという問題です。たとえば残酷なゲームをやると暴力性が上がるという話があります。その実験は,ランダムに学生を半々に分け,片方のグループにはかなり暴力的なゲームを,もう片方には平和なゲームをプレーしてもらいます。その後,「悪いことをした人が来るので,電気ショックを流してください,流す時間はお任せします」と依頼します。すると暴力的なゲームをやった人の方が,電気ショックのボタンを押す時間が長いというデータが出ているんです。
この結果を踏まえ,暴力的なゲームは暴力性を上げるのではないかという意見がありますが,果たして暴力的なゲームを規制すると世の中の暴力が減るかというと,別問題なんです。というのも心理学での実験対象は,大学教授などが参加を依頼しやすい生徒・大学生が大半を占めています。仮に大学生といった偏った集団の中でそうした因果関係が生じたとしても,他の集団において同様のことがいえるとは限りません。そこで,過去に行われたさまざまな集団に対する研究においてはどうなのかを調べるために,「系統的レビュー」(図13)を行います。
世界中には同じような研究テーマに対して,多種多様な実験,分析がたくさんあります。それらを可能な限り全部集めるのです。医学だったらPubMed,経済学だったらEconLit,教育学だったらERICなど,各分野の文献データベースで,キーワード&ランダム化比較実験で検索をし,そのすべての論文に目を通し,実際にどういう結果が起こったか,統合分析「メタアナリシス(meta-analysis)」を行います。
メタアナリシスとは,アナリシス(分析)に対するアナリシスなんですね。論文の分析結果に対して分析するということです。効果があった,あるいはなかったという文献も,この対象についてはまだ調べていませんという文献も全部収集して分析し,その結果,何がわかるか結論をまとめていくのが系統的レビューです。研究者が行った系統的レビューの論文はたくさんありますし,アイデア構築に実際に役に立ちますので参考にしてください。系統的レビューではメインの結果を表で整理していることが多いので,英語が苦手な方は,表だけでも見ることをおすすめします。
試しにGoogle Scholarを使い,営業マンのパフォーマンス(salesman performance)とメタアナリシス(meta-analysis)で検索をしたのが図14です。検索時点で2万100件の文献があることがわかります。すごい数ですね。
図15はビンチュールらが1998年に,営業セールスの成績に何がどのくらい影響を与えているかについて,系統的レビューを行った結果です。それによると営業成績の説明力は,ビッグファイブ特性注2)項目では誠実性(10%)が最も高く,下位項目では達成性(17%)が大事だとわかります。つまり目標を最後まで達成し切るかどうかが重要な能力だというのです。またIQなどの一般認知機能は,1%未満しか効いていなかったのに比べ,興味テストは25%の説明力をもっていると示されていました。つまり営業マンという仕事に対して,興味の軸が向いているか向いてないかという方が,その人の備えている一般的な認知機能よりも営業成績を左右すると伝えているのです。大学卒の優秀な人を営業マンで働かせ,思うほど成績が伸びず宝の持ち腐れになってしまうとしたらもったいない話ですね。
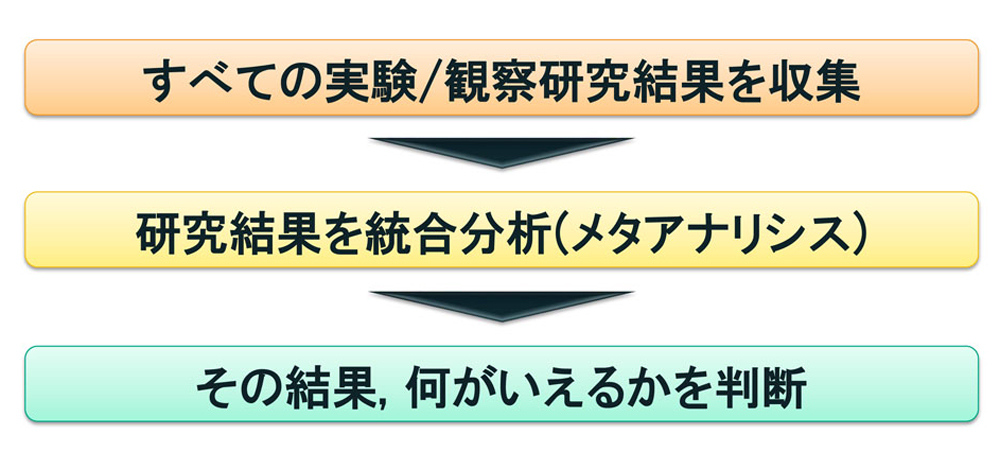
図13
系統的レビューとは

図14
系統的レビューの探し方

図15
営業セールスの成績に何が影響を与えるか
おわりに
以上,話をまとめますと,データから得られた数値が高い低いと一喜一憂するのではなく,その背後に何が関係しているのかを考えることが,データ分析の意義だと思います。分析の結果,成果への背後に潜む影響を与える事象がわかったら,変えられるものは変えてみる,狙いをずらしてみる,どちらが駄目でもリソースを最適化してみるなど,求める成果に直結するアクションを取ってみましょう。いきなり行うのではなく,分析結果が出た後でもかまわないので,必ずランダム化比較実験を行い,どのくらいの差がつくか確認するのがいいと思います。
何を分析するか悩んだら,ご自分の経験やセンスに頼って仮説を立てるのではなく,先行研究を探し,少なくとも系統的レビューを試し先人の成果を把握してください。考えていた分析をすでに学者が行っていたということは多々あるのです。そしてブレーンストーミングや議論を行い,「学者の研究は自分たちの会社にどれくらい当てはまるのか」「わが社でまだ気がついていない重要なポイントは何か」を見つけていただく。それが,リサーチデザインの基礎になるといっても過言ではないでしょう。今日はこのあたりをぜひ皆さんにお伝えしたいと思いました。長いことご清聴ありがとうございました。

図16
講演中の西内氏
執筆者略歴

統計家。東京大学 医学部(生物統計学)卒。東京大学大学院 医学系研究科医療コミュニケーション学分野 助教,大学病院医療情報ネットワーク研究センター副センター長,ダナファーバー/ハーバードがん研究センター客員研究員を経て,2014年株式会社データビークル創業。自身のノウハウを生かしたデータ分析支援ツール「Data Diver」などの開発・販売,官民のデータ活用プロジェクト支援に従事。著書『統計学が最強の学問である』(ダイヤモンド社)はビジネス書大賞2014大賞を受賞。他に『統計学が最強の学問である[実践編]』(ダイヤモンド社),『統計学が最強の学問である[ビジネス編]』(ダイヤモンド社),『統計学が日本を救う』(中央公論新社)などがある。
本文の注
注2) 1980年代に複数の心理学者が人間の性格に関する検査の結果から,性格は結局のところ5つにまとめられることを,因子分析などの統計手法によって明らかにした。その性格特性の5つの軸を「ビッグファイブ特性」という。ビッグファイブ特性の量的な比較で,各人の性格がとらえられるという。さらに,それぞれに下位項目がある。 5つの軸とは,外向性(社交性),調和性(人当たりのよさや気立てのよさ),誠実性(責任感の強さや完璧主義),感情の安定性(物事への動じなさや慎重さ),経験への開放性(想像力や芸術的な感性)である。 ※西内啓著『統計学が最強の学問である(ビジネス編)』(ダイヤモンド社)より一部引用。