SEMINAR
Introduction to Multiple Imputation
Keywords:
missing data,
mechanisms of missing data,
complete-case analysis,
single imputation,
multiple imputation
2021 Volume 3 Issue 1 Pages 1-4
Details
2021 Volume 3 Issue 1 Pages 1-4
Missing data is a common problem in clinical epidemiology research. Inappropriate handling of missing data leads to biased results. This paper explains the mechanisms of missing data and several methods for handling missing data. In particular, multiple imputation is a more valid approach than other methods. Therefore, this paper focuses on the assumptions and procedures for multiple imputation and describes its limitations.
In clinical research, perfect measurement and recording of data are rare. In interventional studies, missing data can occur for many reasons. For example, when patients do not visit their attending physicians (loss to follow-up), data cannot be obtained. The problem of missing data also arises in observational studies using real-world data. For example, in the Clinical Practice Research Datalink in the United Kingdom, 15% of blood pressure data and 20% of body mass index data are missing [1].
Consultation with an epidemiologist or a statistician is generally recommended when clinical researchers perform statistical analyses of missing data [2]. In fact, the number of clinical studies dealing with missing data has been increasing in recent years. For readers who are unfamiliar with how to deal with missing data, this article aims to explains basic knowledge on the mechanisms of missing data and several statistical methods for dealing with missing data, including multiple imputation (MI).
The following three mechanisms of missing data are generally used to identify situations wherein missing data can occur [3]. Selection of the most suitable statistical method depends on the mechanism through which the missing data have occurred.
Missing Completely at Random (MCAR)MCAR is a situation wherein occurrence of missing data is not related to any unobserved or observed characteristics of the study population. For example, blood pressure cannot be measured on a day when the sphygmomanometer has accidentally broken down. Thus, MCAR is a rare situation.
Missing at Random (MAR)MAR is a situation wherein occurrence of missing data is unrelated to the missing values themselves but is related to other observed data. MAR assumes that other observed data can be used to help predict what the missing data would be. For example, blood pressure data are more likely to be missing among young patients or those without cardiovascular diseases, but this situation is not related to the blood pressure data themselves.
Missing Not at Random (MNAR)MNAR is a situation wherein the missingness is dependent on the unobserved values themselves. For example, people with low socioeconomic status are less likely to respond to questions on their income in questionnaire surveys.
There is no way to determine the actual mechanisms for missingness of data. Researchers can only compare the distributions of other observed variables between those with and without missing data. If the distributions of the other observed variables differ between the groups, the mechanism of missing data is unlikely to be MCAR. However, even if the distributions of the other observed variables are similar between the groups, the actual mechanism of missing data remains uncertain.
Several methods have been developed and used to conduct analyses on datasets with missing data.
Complete-Case AnalysisComplete-case analysis uses data for patients without missing data, and thus excludes data for patients with missing data. When the mechanism is based on MCAR, the excluded patients can be regarded as a random sample among all patients. Thus, complete-case analysis is a reasonable method when the mechanism of missing data is MCAR and provides unbiased results [4]. However, when a large proportion of patients have missing data, complete-case analysis will reduce the statistical power and precision of estimates in the study [5].
Complete-case analysis will provide biased results unless the mechanism of missing data is MCAR. Nevertheless, this method is generally misused because of its simplicity and is the default setting for handling of missing data by statistical software programs [5, 6].
Single ImputationSingle imputation replaces missing data with single plausible values and conducts statistical analysis for the research objectives as though all data were originally observed. There are several ways to replace missing data with single plausible values, including mean value imputation, regression imputation, and last observation carried forward [5, 6]. Single imputation is frequently used. However, single imputation methods are not recommended for all mechanisms of missing data because they do not take uncertainty in imputed missing values into account and are likely to introduce biased results and inappropriately narrow confidence intervals.
Multiple ImputationFor MCAR and MAR, several statistical methods can be used to obtain valid estimates for missing data. These methods include maximum likelihood estimation, Expectation-Maximization (EM) algorithm, inverse probability weighting, and MI [7]. Among these methods, MI is the most commonly used and is relatively easy to apply in standard statistical software programs [8]. MI consists of three stages (Fig. 1) as described below.
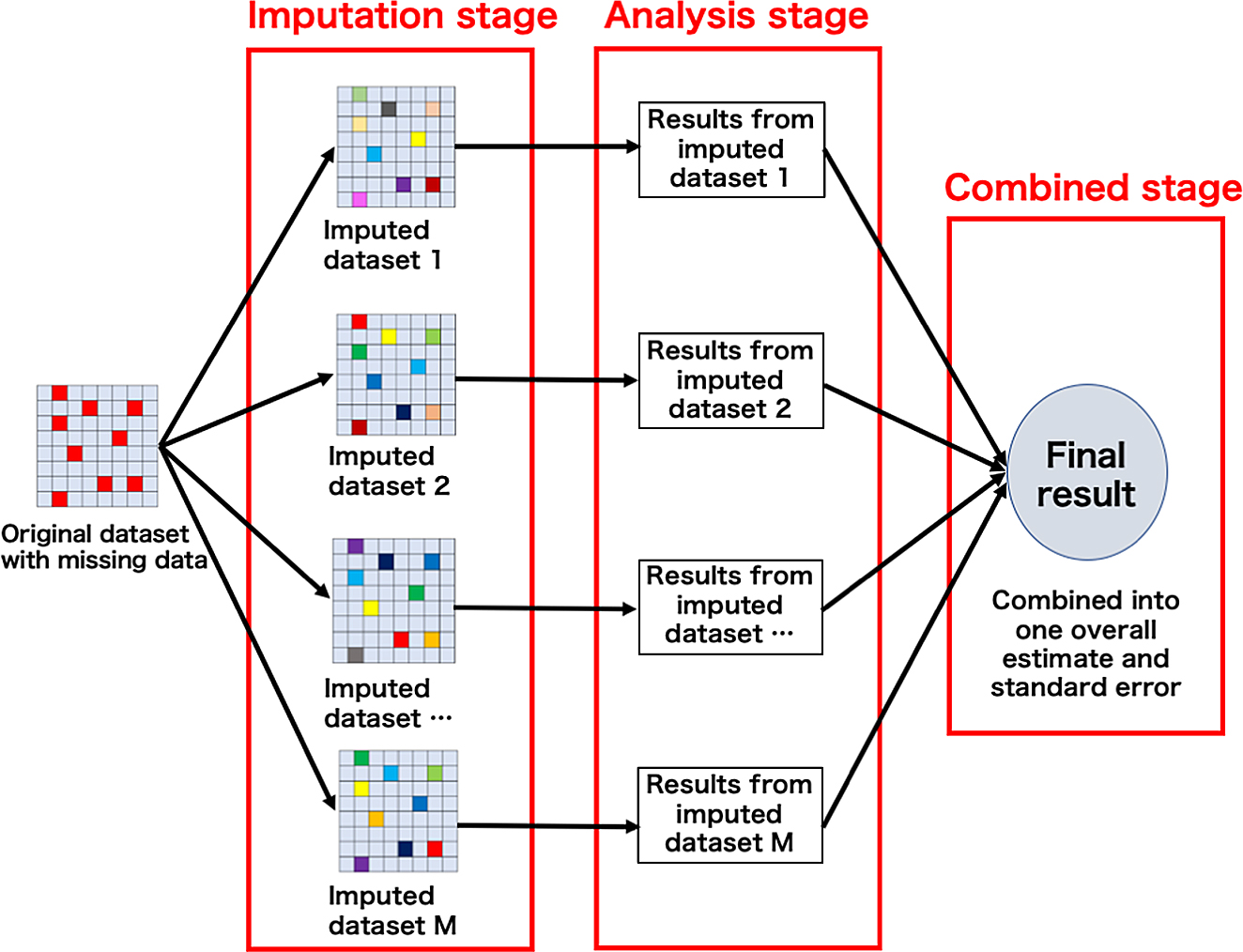
(1) Imputation stage
The original dataset with missing data is copied multiple times (M sets), and the missing values in each dataset are replaced by imputed values to create M sets of pseudo-complete datasets. The imputed values are estimated based on the predicted distribution of the observed data.
(2) Analysis stage
In each of the pseudo-complete datasets, statistical analysis is conducted for the research objectives to obtain estimates of interest for the M sets.
(3) Combined stage
All the results for each imputed dataset are combined into one overall estimate and standard error using standard combination rules (Rubin’s rules) [9].
Regarding the number of pseudo-complete datasets, it was initially suggested that five imputed datasets would be sufficient to obtain a valid estimation [9, 10]. Recently, however, there have been some recommendations that it is preferable to generate 50–100 (at least 20) imputed datasets to reduce sampling variability from the imputation stage [2, 11, 12].
MI is used not only when the value for just one variable in the dataset is missing but also when the values for several variables are missing. Specific MI algorithms that generate imputed values for several missing variables include the Markov Chain Monte Carlo simulation and Fully Conditional Specification. In particular, multivariate imputation using chained equations is frequently used as a typical algorithm for Fully Conditional Specification [12].
Strengths of multiple imputationMI reflects uncertainty about the missing values by creating several different plausible imputed datasets and obtaining one combined overall estimate and standard error based on Rubin’s rules [3].
Limitations of multiple imputationThe validity of results obtained by MI depends on the validity of its assumptions. If the MAR assumption is not satisfied, the results from MI may be biased. To satisfy the assumption that the mechanism of missing data is MAR, it is necessary to include all variables that would predict the missing values in the imputation model at the imputation stage. Even if these variables are not considered exposure variables, confounders, or outcome variables at the analysis stage, they should be included in the imputation model as “auxiliary variables” to create the pseudo-complete datasets [13]. Methodologists have recommended a so-called “inclusive analysis strategy” that incorporates several auxiliary variables into the imputation model to satisfy the MAR assumption [13]. It is recommended that outcome variables are also included in the imputation model as predictors for missing values when MI is used because no variables are distinguished as exposure variables, confounders, or outcome variables in this imputation model [14].
It should be emphasized again that it is impossible to identify the actual mechanism of missing data. MCAR is the most unrealistic assumption and there is no way to distinguish between MAR and MNAR. However, at least under MCAR or MAR, the inclusive analysis strategy is an appropriate way to reduce bias from missing data. In other words, the results from MI are always more valid than those from complete-case analysis.
Relationships Between Mechanisms of Missing Data and Methods for Handling Missing Data(1) Under the MCAR assumption, both complete-case analysis and MI can be used. Complete-case analysis may be reasonable if the statistical power and precision of estimates in the study are preserved.
(2) Under the MAR assumption, it is expected that valid estimates of the relationships between exposures and outcomes can be obtained by MI. Using MI is justified by striving to meet the MAR assumption as much as possible.
(3) Under the MNAR assumption, a valid statistical method has not yet been sufficiently established, and further innovation of technology is expected.
Occurrence of missing data involves three mechanisms: MCAR, MAR, and MNAR. An appropriate statistical method should be selected, based on the underlying mechanism. When the mechanism of missing data occurrence is MCAR or MAR, MI can provide unbiased estimates and standard errors.
Not applicable.
None.