要旨
マーケティング・リサーチの分野では,従来の市場調査の領域に加え,デジタルデータ分析の領域も必要とされ,多種多様なデータを活用するインサイトビジネスが拡大している.デジタルデータ分析で利用されるビッグデータはリアルタイムに収集でき,アンケートによる実態調査の代替となることが多い.一方で,あるテーマに対する興味関心度を把握するためには,アンケートによる意識調査が有効な手段である.しかし,年次で実施されることが多い意識調査において,リアルタイム性を高めるために調査回数を増やしたとしても,回答負荷やコストの大きさから日次での継続的な実施は難しく,月次でさえも不向きである.そこで,入手しやすいWikipediaデータに着目し,個人の興味関心が反映されたデジタルデータとしての有用性を調べる.本論文では,データの種類と場所の観点からWikipediaデータの位置づけを整理し,Wikipediaページへのアクセス数の変化を可視化する方法を提案する.この方法により,コロナ禍で生活者が興味関心を持った記事ページへのアクセス数から世の中の意識変化を把握する.行動データとしてではなく,意識データとしてのWikipediaデータの役割を示す.
Abstract
In the field of marketing research, in addition to the traditional market research, digital data analytics are required, and the insight business that utilizes various data is expanding. Big data used in digital data analytics can be collected in real time and often serves as an alternative to factual surveys using questionnaires. Questionnaire-based consciousness surveys are an effective means of understanding the level of interest in a theme. However, even if the number of consciousness surveys, which are often conducted annually, is increased to enhance their real-time performance, it is difficult to conduct them daily because of the large burden of responses and cost, even monthly surveys are not feasible. Therefore, we focus on the easily obtainable Wikipedia data and investigate their usefulness as digital data in reflecting individual interests. In this paper, we organize the characteristics of Wikipedia data from the viewpoints of data type and location and propose a method to illustrate changes in the number of accesses to Wikipedia pages. Using this method, we grasp the change in public consciousness from the number of accesses to article pages that consumers were interested in during the COVID-19 pandemic. We demonstrate the role of Wikipedia data as consciousness data and not as behavioral data.
1. はじめに
日本のスマートフォンの普及率は年々増加し,2022年には個人所有率が77.3%と8割近くまで増えており,個人のインターネット利用率は84.9%と高い(総務省, 2023).日常生活でインターネットを利用している多くの生活者(柏木, 2000;森脇, 2001)は,手元のスマートフォンから「いつでも」「どこからでも」インターネットに接続できるため,少し気になる事柄があった際には,その場ですぐに知りたい情報を調べることができる.このとき生活者が検索した行動履歴はインターネット上に蓄積されていく.
インターネットはWindows95の発売を契機に普及したが,1990年代はISDNなど電話回線で接続したPCで通信速度が遅く,料金も高かったため,アクセスできる場所と時間帯は限られていた.その後2001年に,Yahoo! BBが安価にブロードバンドでつながるサービスを始めると(ソフトバンク, 2023),次第にインターネットは「いつでも」使えるものとなっていった.一方,モバ
イルインターネットは,1999年にNTTドコモがi-modeを開始し(NTTドコモ, 2023),携帯回線の遅さによってアクセスできるコンテンツに限りはあったが,「どこからでも」インターネットにつながる環境の始まりとなる.2002年には 3G回線に移行していくが,まだ携帯回線の速度は遅く,パケット代がかかった携帯向けのコンテンツは,ブロードバンドのPC向けのコンテンツとは別に作られていた.2008年に日本で初めてiPhoneが発売されると,携帯電話がスマートフォンへと置き換わり,PCと携帯電話の垣根は次第に無くなっていく.
こうして「いつでも」「どこからでも」アクセスできるようになったインターネットには,デジタルコンテンツが急増していく.これには発信方法と検索技術の進化が大きな影響を与えた.まず,ブログやレビューサイト,Wikipediaに代表されるCGM(Consumer Generated Media)の登場により,HTMLの手書きなしでインターネットユーザであれば誰でも気軽に発信できるようになる.Wikipediaは大規模Web百科事典であり,Webブラウザから自由に編集可能なWikiというシステムを利用し,文学・芸術・歴史・自然科学・技術など幅広い分野の記事コンテンツが網羅的に収録されている(Leuf and Cunningham, 2001).その後,検索エンジンがYahoo!などのディレクトリ検索型からGoogleなどのロボット検索型へと変わる(JPNIC, 2023).インターネットユーザは,爆発的に増え続けるデジタルコンテンツの中から,検索ワードを入力することで効率よく良質なWebサイトを探すことができるようになった.
生活者の検索行動が当たり前になってくると,検索ワードから捉えた興味関心に応じて広告をマッチさせる検索連動型のリスティング広告が普及し,Googleの影響力が次第に大きくなっていく.Web広告サービスが拡大していく中,消費者行動の研究では,生活者の購買意思決定プロセスが「注意 →興味・関心 →欲求 →記憶 →行動」のAIDMAモデルから「注意 →興味・関心 →検索 →行動 →情報シェア」のAISASモデルへと変わり,生活者の興味関心が検索行動につながることが示唆されている (清水, 2013).他にも数理モデリングの研究では,個人の興味関心の変化や,流行を取り入れるタイミングの違いといった情報伝播の特徴を整理し,流行推移を予測する数理モデルが構築されている(植田・朝日, 2014;大田・水谷 , 2021).また,社会現象と検索行動の相関関係を基にした口コミ指数も提案されている (大知他, 2016).
近年はGoogleを中心に世界のビッグテック企業が,インターネット上に蓄積された検索の行動履歴データやSNS(Social Networking Service)のテキストデータを分析し,ビジネス活用しているが,Wikipediaデータも重要なデータソースの1つである.Wikipediaの言語数は多岐にわたり,2024年1月1日時点では339言語のページが存在し,記事コンテンツは,英語で約676万語,日本語で139万語となっている1.多言語で入手しやすいWikipediaデータは,デジタルコンテンツを学習する生成AIにとって必要不可欠なデータとなっている(Wu et al., 2023).このように行動履歴やSNSだけでなく,コンテンツの内容自体も活用が進んでいる.Wikipediaデータに加え,SNSやニュース記事などをテキスト分析し,コロナ禍における人々のリスク認識や行動変化について国比較した研究例もある(Gozzi et al., 2020).
デジタル技術の発展とデジタルデータの蓄積により,マーケティング・リサーチ業界は従来の市場調査の領域だけでなくデジタルデータ分析の領域も必要となり,新たにインサイト産業と定義され,市場規模が拡大した(ESOMAR, 2020).インサイト産業におけるデジタルデータ分析では,実態把握のためにオンラインの行動履歴データの分析や,ソーシャルリスニングによってSNSやVOC(Voice Of Customer)に代表される生活者の声を収集して分析する.このとき生活者の記憶に頼るアンケート調査ではなく,生活者がどのような行動をしたのかリアルタイムに蓄積された事実そのものを扱う.ただし,その行動は何がきっかけで,なぜ興味を持ったのかという理由についてまでは不明である.一方,市場調査や社会調査は,生活者の興味関心の把握を得意とするが,ビッグデータの特徴のひとつであるリアルタイム性には乏しい.インターネット調査の利用で訪問調査や郵送調査よりも調査回数を増やすことも可能だが,集めるデータである限りはコストが大きく,回答負荷も大きいため,日次や月次での継続的な調査は実用的ではない.そこで,Wikipediaデータは生活者の興味関心が反映されていると仮定し,Wikipediaへのアクセスデータを用いて,世の中の興味関心度の変化を調べる.
本論文では,利用可能なデータの種類とその時代変化に着目し,デジタルデータの特徴を整理した上で,Wikipediaページへのアクセス数の変化を可視化する方法を提案する.コロナ禍で生活者が興味関心を持った記事ページを抽出し,そのアクセス数の変化を可視化することで,興味関心の高まりの把握やその予兆の検知への活用を模索する.
2. データの情報源の変化
従来,生活者の興味関心の移り変わりを把握するには,新聞・雑誌の売上やテレビ視聴率など一部に限られたデータしか利用できず,代わりにアンケートによる意識調査に頼らざるを得なかった.しかし,インターネットが普及するにつれ利用できるデータの種類が増え,例えば,ネットニュースのアクセスランキング,SNSのトピックランキング,検索サイトの急騰ランキングなど,生活者の行動履歴データから類推が可能となっている.マーケティング・リサーチでは,調査で得られた「集めるデータ」だけでなく,別目的で記録された「集まるデータ」の活用も必要とされる(星野・上田, 2018).
集めるデータは,事前に計画して収集したデータを指し,基本的には市場調査や社会調査,世論調査などで実態や意識のデータが得られる.インターネット以前は,記録を目的とした観察調査や,特定の人を対象としたインタビュー調査,標本調査法に基づく各種調査を実施することでデータが収集されていた.データ入力については,欧米では先行してインターネットの利用なしでコンピュータ支援調査と呼ばれる方法が実施されていた(大隅, 2001).日本でもコンピュータ支援調査は導入されたがその多くがインターネット調査へと移行し,現在では世論調査のためにCATI (Computer Assisted Telephone Interview)と RDD (Random Digit Dialing)を組み合わせた電話調査などで利用されている.
インターネットの登場によって,「いつでも」「どこからでも」アクセスできる利便性を活かし,人気投票の実施や,公募型のWebモニターに依頼をする形式で,安価で速くデータを収集するインターネット調査が始まる.インターネット利用者が増加するにつれ,調査対象者が特殊なネットユーザから一般の生活者へと変化し,インターネット調査の普及が進んでいった(長崎, 2008).SNSが登場する頃には,スマートフォンの普及やクラウド環境の整備が進み,パネル型ビッグデータの収集も増えていく.電話調査については,コンピュータ支援調査から自動音声やSMS(Short Message Service)でWebサイトに誘導するなどインターネットを利用した方法が使われ始め,段階を経て収集方法が変化していった(鈴木, 2021).
集まるデータは,実務など別目的で収集されたデータを指し,アクセスログやPOS(Point Of Sales),GPS(Global Positioning System)などのビッグデータが代表的である.インターネット以前は,辞書や書籍に情報が集約され,口コミ(WOM; Word Of Mouth)や掲示板,ファンの書き込みノートなどでコミュニケーションした内容が記録されていた.インターネットが登場してから,CGMの利用でデジタルコンテンツが増加したため,ブログや電子掲示板(BBS; Bulletin Board System)を口コミデータとみなして分析する多くのブログ分析サービスが登場した.その後,mixiやGREEといったSNSが登場し,公開範囲の広いメディア寄りの Twitter(現 X),公開範囲の狭い実名重視の Facebook,Instagramへと移っていく.これにより,従来,同じ興味関心でつながることが多かったインターネットのネットワークは,地縁や血縁,同じ組織同士といった多様なつながりへと変化した(岩崎・小川, 2017).
SNSの中でもTwitterは,公開範囲が広く, Twitter社が有料でデータソースへのアクセス権を販売したことから,リアルタイムに消費者の感情を捉えるツールとしてTwitterをデータソースにした分析サービスが増えていった(牧野, 2014).マーケティング研究では,インターネット上の消費者情報を利用する動きが活発となり,CGMや SNSで発信されたテキストデータの分析や,オンライン上でフォーカスグループインタビューなどを実施し,消費者参加型で企業の商品開発に活用されるようになる(清水, 2004).オンライン上でコミュニティを形成して質問していく定性調査をMROC(Marketing Research Online Community)という.
以上を踏まえて,表1ではデータの種類と場所に着目し,時代変化をまとめている.

表1
データの種類と場所
3. Wikipediaデータの特徴理解
本節では,まずWikipediaデータを用いてコロナ禍でどのような事柄に関心が高まったのかを把握する.次に,コロナ禍で急増した記事コンテンツを抽出し,そのWikipediaページへのアクセス数の変化を生活者の行動と意識の2つの側面から調べる.データソースは,Googleが BigQuery上で公開しているデータベースを使用し,日本語サイトに限定する2.各記事コンテンツへのアクセス数をWikipedia Page View(以下,PV)とする.
3.1. コロナ禍でアクセスが増加したページ名
コロナ禍での関心事をWikipediaデータから抽出するため,日別のWikipedia PVを集計する.特定の期間に区切ってWikipedia PVを集計する場合,短時間に大量のアクセスが集中する記事コンテンツが抽出されてしまう.このようにして得られた記事コンテンツには,瞬間的に話題になる人物名や期間中に配信されたドラマやアニメに関連するページ名が多い.コロナ禍のようなニュース性の高い社会問題に関連する記事コンテンツを抽出するため,特定の期間に新しく作成されたページのWikipedia PVを集計する.
表2は,2020年上半期と2020年4月7日から5月25日までの緊急事態宣言中の2つの期間で,新規ページへのWikipedia PVをランキング形式で集計したときの上位ページ名である.なお,緊急事態宣言は2020年4月7日に当時の安倍首相が東京,神奈川など7都府県に発出した.新規ページの抽出では,対象期間の開始日より前のWikipedia PVが0件のページを集計対象とする.2020年上半期の場合は2019年下半期,緊急事態宣言中の場合は,同じ期間だけ遡ったときのWikipedia PVが0件のページである.
2020年上半期の1位は“2019新型コロナウイルス”であり,25位までのページ名を見ると流行状況や疾患に関する情報が調べられていたことがわかる.緊急事態宣言中の1位は“西浦博”氏であり,新型コロナウイルスの流行状況を把握する数理モデルによるシミュレーションの実施や,厚労省のクラスター対策班に参画し,“3つの密”の条件を特定した人物である.他にもオンライン会議ツールの“Microsoft Teams”や“自粛警察”など緊急事態宣言中に注目を浴びた記事コンテンツが上位に登場している.特定期間の新規ページのWikipedia PVからコロナ禍で生活者が気になったページ名を抽出できたことがわかる.

表2
新規ページのアクセス数ランキング(コロナ関連に網掛け)
Wikipedia PVからコロナ禍に興味関心があったページ名を絞り込み,そのWikipediaページへのアクセス変化と人々の行動や意識の変化との関連性を確認する.時系列変化を比較するため,前節で確認した増加傾向の新規ページではなく,増減が確認しやすい Wikipedia PVが急増したページ名を対象とする.行動との関連性についてはGoogle Trendsのデータを利用し,意識との関連性については株式市場における先行きの不透明感と連動しやすい日経平均ボラティリティー・インデックス(以下,日経 VI)のデータを利用する.日経 VIは,投資家が将来の株価変動をどのように想定しているかを表した株価指数であり,ボラティリティーは日経平均の変動率を表す(日本経済新聞社, 2023).Yahoo!ファイナンス掲示板の投稿内容が日経 VIの予測に有効とされており(Suwa et al., 2017),投資家心理が反映された「未来への不安」を表しているともいえる.なお,これらのデータの期間は 2020年の 1年間とする.
時系列変化の一致を評価する指標として相関係数と増減一致率(UDCR; Up Down Correct Rate)を算出する.増減一致率は,2つの系列データx =(x1,x2,・・・ ,xn), y =(y1,y2,・・・ ,yn)が与えられたとき,以下のように定義される(吉田他, 2015).
 は
は と同様に計算する.ただし,Wikipedia PVとGoogle Trendsと比較する際は,事前にWikipedia PVを Google Trendsに合わせて最大値 100の整数に規格化する.
と同様に計算する.ただし,Wikipedia PVとGoogle Trendsと比較する際は,事前にWikipedia PVを Google Trendsに合わせて最大値 100の整数に規格化する.
Wikipedia PVが急増したページを確認するため,2019下半期にアクセス数が1以上あり,2020年上半期にアクセス数が10万以上あったページのWikipedia PVを集計し,前年比を算出する.表3は,Wikipedia PVの増加率をランキング形式で集計したときの上位ページ名である.前節の新規ページと同様にコロナ禍に関連するページ名が含まれていることがわかる.
表3から4位の“アマビエ”と25位の“スペインかぜ”に着目する.“アマビエ”は妖怪の一種であり,未知の感染症の流行で注目が集まりSNS上で拡散され,厚生労働省の外出自粛啓発キャラクターへの起用もされたことで,生活者の興味関心が高まったとされる(高橋・藤井 , 2022).“スペインかぜ”は約100年前に発生した世界的に流行した感染症の通称である.未知の感染症の流行で,過去の世界規模の感染症例に興味関心が高まったと考えられる.

表3
2020 年上半期年急増ページの前年比ランキング(コロナ関連に網掛け)
まず,Wikipedia PVは検索行動と関連して変化するデータであることを確認する.図1では,2020年上半期に急増した“アマビエ”のWikipedia PVとGoogle Trends3を時系列で比較した.時系列の傾向として,急増のタイミングや増加から減少への変化点などは似ているように見える.図2の散布図と回帰直線や表4の相関係数と増減一致率から,Wikipedia PVと Google Trendsで相関関係があることがわかる.生活者は気になる事柄が発生したとき,検索エンジンで検索し,検索結果の上位に出現したWikipediaの記事コンテンツページをクリックしていると予想される.

図1
Wikipedia PVとGoogle Trendsの時系列比較:“アマビエ”

図2
Wikipedia PVとGoogleTrendsの散布図と回帰直線:“アマビエ” ※2020年の366時点

表4
Wikipedia PVとGoogle Trendsの比較評価:“アマビエ” ※2020年の366時点
次に,Wikipedia PVは生活者の興味関心度と関連して変化するデータであることを確認するが,冒頭で述べたようにリアルタイムな意識調査の実施は難しいため,投資家心理ではあるが「未来への不安」が反映された日経VIを用いる.コロナ禍で最初に起きたのは「未来への不安」であると考えられ,前回のパンデミックを参考にしたいと思う生活者によってアクセスが増加した“スペインかぜ”との関連性を調べる.図3では,2020年上半期に急増した“スペインかぜ”のWikipedia PVと日経VIを時系列で比較した.ただし,平日など日経VIが観測できる日付のみを対象としている.時系列の傾向として,数日のタイムラグがあるようにも見え,投資家の行動が先行している可能性があるが,増減の傾向は少し似ているように見える.日経VIは“スペインかぜ”を特定した指数ではないため,検索行動のような直接的な結果ではなく,複合的な不安要素が混じった結果であるとも考えられる.図4の散布図と回帰直線や表5の相関係数と増減一致率から,Wikipedia PVと日経VIでも相関関係があることがわかる.このように,Wikipedia PVは,検索の行動履歴データであると同時に,世の中の興味関心を反映した意識データになり得る可能性がある.
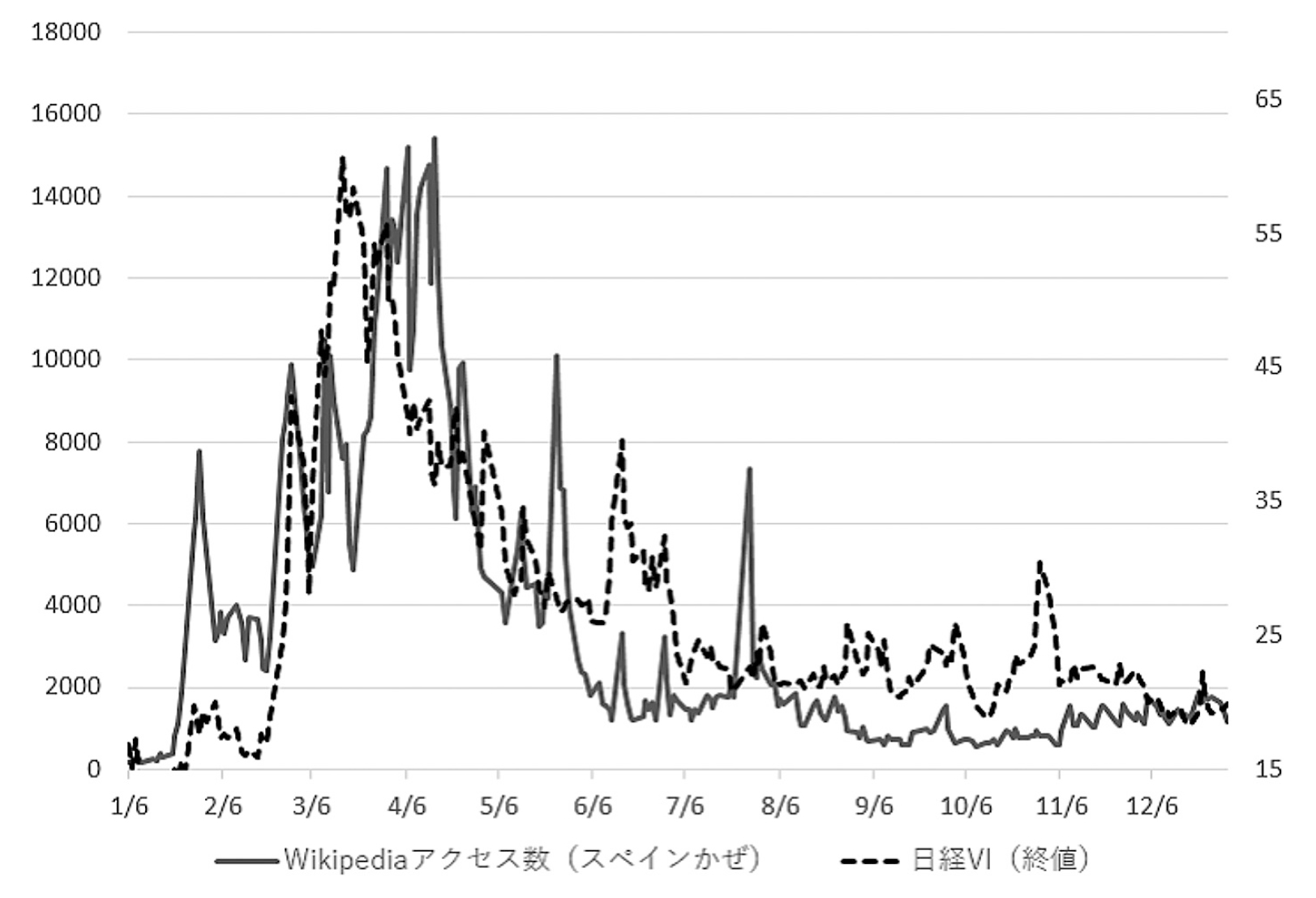
図3
Wikipedia PVと日経VIの時系列比較:“スペインかぜ”
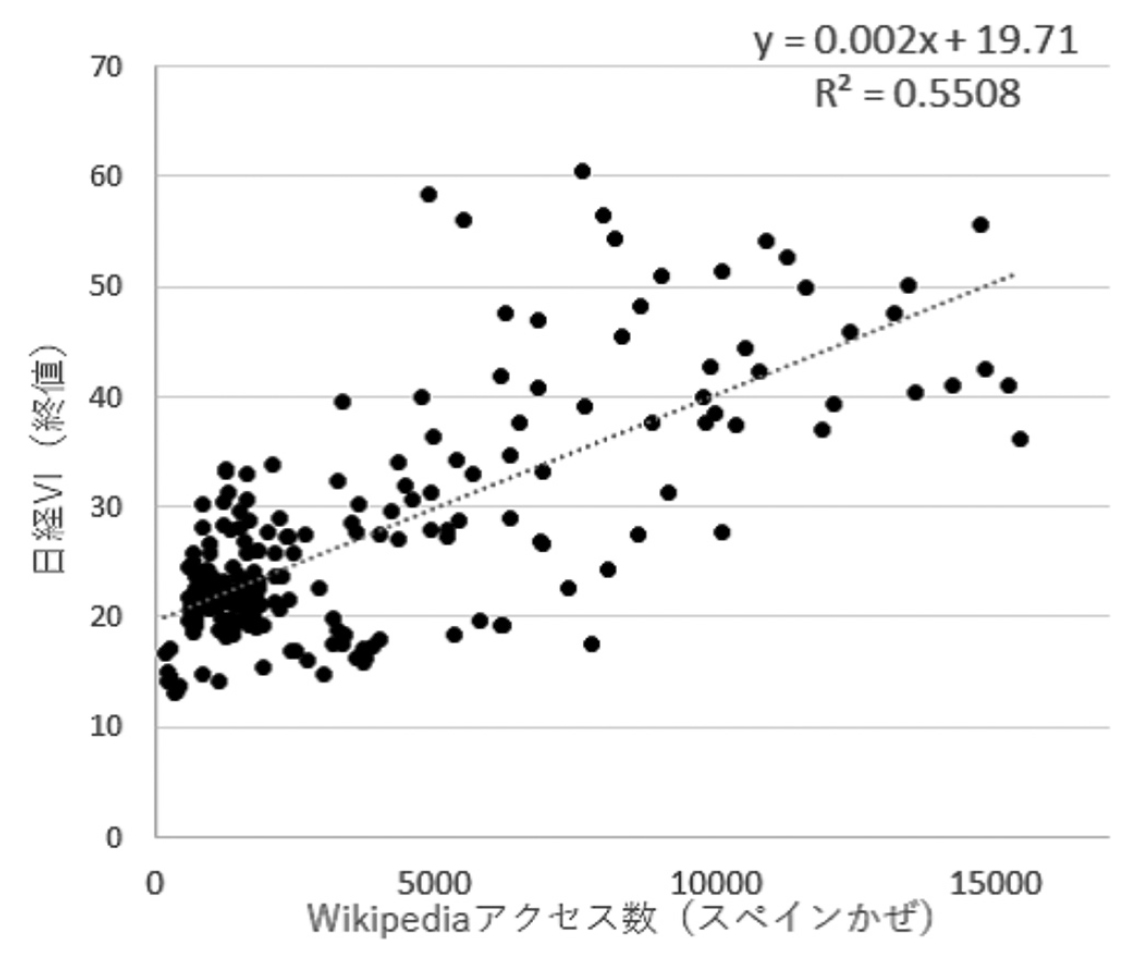
図4
Wikipedia PVと日経VIの散布図と回帰直線:“スペインかぜ”※2020年平日の243時点

表5
Wikipedia PVと日経VIの比較評価:“スペインかぜ”※2020年平日の243時点
4. 興味関心の移り変わりの可視化
世の中の興味関心が検索行動に反映されていると仮定し,Wikipedia PVを使って興味関心の高いページ名の時系列変化を可視化する方法を提案する.前節の表3の中からコロナ禍で興味関心度が高まったとされる“Zoomビデオコミュニケーションズ”に着目する.コロナ禍で外出制限が始まったことで,ビジネスの現場ではオンライン会議が急速に普及した影響が出ていると考えられ,表3からWikipedia PVの前年比は約69倍である.この系列データを用いて,期間は2020年の1年間とし,最初は小さな興味関心が次第に大きくなり,ピークを迎えたのち,やがて関心が薄れていく一連のプロセスを可視化する.
まずは,Wikipediaページのアクセス数の高まりと収束のデータを元にアクセス数の増減を指標化する.xtをt 期のアクセス数, をt − k 期からt 期までのアクセス数の平均値としたとき,曜日の特性を除くため, 7日間の移動平均
をt − k 期からt 期までのアクセス数の平均値としたとき,曜日の特性を除くため, 7日間の移動平均 を計算する.その上で,ここでは 21日前(3週間前)との差分
を計算する.その上で,ここでは 21日前(3週間前)との差分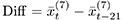 を算出した.3週間より短くすると,関心の高まりをいち早く検知できるが,瞬間的に盛り上がって下火になる記事コンテンツを抽出する可能性がある.一方で期間を長くすると,一時的ではない長期的な関心の高まりを捉えるが検知は遅くなる.図5は,この差分を横軸,アクセス数の移動平均
を算出した.3週間より短くすると,関心の高まりをいち早く検知できるが,瞬間的に盛り上がって下火になる記事コンテンツを抽出する可能性がある.一方で期間を長くすると,一時的ではない長期的な関心の高まりを捉えるが検知は遅くなる.図5は,この差分を横軸,アクセス数の移動平均 を縦軸に取ったグラフである.このような可視化によって,4つ象限に分割すると関心の一生は左回りで推移することがわかる.4分割する際,今回は縦軸のリファレンスラインを1000とした.これより小さくすると盛り上がる前の早い段階で検知ができるが,すぐに下火になる記事コンテンツを多く含むなど一長一短あり,目的に応じて変更する.
を縦軸に取ったグラフである.このような可視化によって,4つ象限に分割すると関心の一生は左回りで推移することがわかる.4分割する際,今回は縦軸のリファレンスラインを1000とした.これより小さくすると盛り上がる前の早い段階で検知ができるが,すぐに下火になる記事コンテンツを多く含むなど一長一短あり,目的に応じて変更する.
.右下(発芽期):まだアクセス数は少ないが増え始めており,関心の高まりの予兆が表れている.
.右上(拡大期):関心が大きく広がる.
.左上(低下期):関心が少しずつ下がり始める.
.左下(収束期):関心が低下し,収束する.
図5では,2020年の3月下旬頃からZoomへの関心は徐々に高まり(右下),4月から5月にかけて拡大期を迎える(右上).6月に入ると関心は徐々に薄れ始め(左上),9月以降は収束を迎える(左下).図6ではWikipediaのページ名ごとに時系列変化を確認することができるが,図5のように4つの象限に分割して確認できれば,特定の日のスナップショットで散布図を描くことで,各ページが同時に比較でき,右上の拡大期にあるページ名の抽出が可能となる.
さらに,右下の発芽期から右上の拡大期に入ったポイントを捉えることで,今後関心が急拡大し,大きな盛り上がりに発展する「きざし」があるテーマを捉えることができる.指標のアルゴリズムは非公開だが,この考え方のビジネスへの活用事例として,日本経済新聞社のプロジェクト「NOBLY(ノブリー)」がある.「NOBLYプロジェクト」では,Wikipedia PVから曜日による周
期性を取り除き,数週間前と比べた増加を重視した指標でページ名のランキングを作成し,「きざし」の発見を支援している(日経クロステック, 2021).

図5
発芽期から収束期までの可視化:“Zoomビデオコミュニケーションズ”
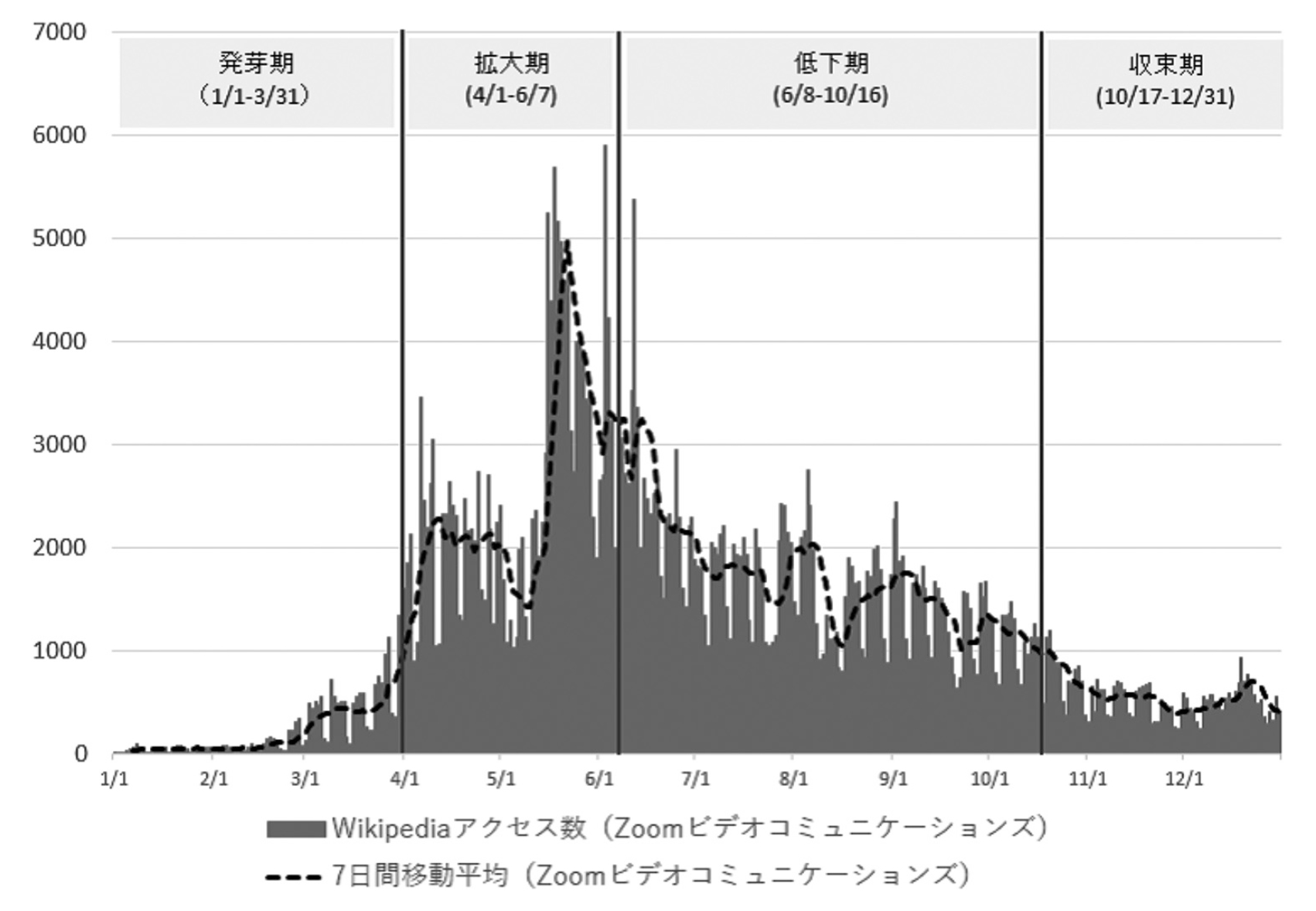
図6
Wikipedia PV6 の時系列変化:“Zoom ビデオコミュニケーションズ”
5. おわりに
本論文では,インターネットの技術革新で利用可能となったデジタルデータについて,集めるデータと集まるデータ,リアル空間とサイバー空間の両軸の観点から整理した.その上で,デジタルデータであるWikipediaデータに着目し,生活者の興味関心が検索行動に反映されていると仮定し,世の中の興味関心度を可視化する方法を提案した.コロナ禍に興味関心度が高まったWikipediaの記事コンテンツを抽出し,Wikipedia PVの時系列変化を4つの期間に分割して可視化した.
インターネット以前は,リアル空間でのアンケート調査によって,人々の行動や意識のデータを収集していたが,「いつでも」「どこからでも」アクセスできるインターネットとSNSの発展により,サイバー空間にビッグデータが蓄積され,Wikipediaページへのアクセスという行動データが利用可能となった.Wikipediaへのアクセスは行動履歴ではあるが,興味関心事を調べることがアクセス行動につながり,意識データとしても扱うことで,アンケート調査では難しかったリアルタイム性を実現し,世の中の興味関心の移り変わりの把握に役立つ.
コロナ禍でアクセスが急増したWikipediaページの分析では,Google Trendsや日経VIとの連関から,検索行動を反映し,「未来への不安」も反映されていると解釈した.その時々で社会で起きた事柄に対して,生活者は興味関心を持ち,Wikipediaで調べるという行動をとっていることが予想できる.不安に限らず,未来の世の中の興味関心事の「きざし」の発見にもWikipediaは有用であり,即座に流行の初期段階での盛り上がりに気付くことができる.マーケティング・リサーチでは,過去の行動データを学習して予測する分析よりも,アンケート調査で未来の意向を聴取することが重要な場面もあるが,その代替としての役割も期待できる.
今後の課題として,Wikipedia PVの時系列変化と定点で実施するような時系列調査とを比較し,Wikipediaデータの意識データとしての活用がどこまで有用かを調べることが必要だと考える.実施回数が少ないアンケート調査と補完しあえるデジタルデータとして,日時で取得可能なWikipeiaデータが活用できるようになれば,意識データの活用範囲が拡がるだろう.
謝辞
本論文の執筆にあたり,査読者の方には多くのコメントを頂きました.ここに深く感謝申し上げます.
脚注
脚注1 データ取得先https://ja.wikipedia.org/wiki/Wikipedia:全言語版の統計
脚注2 データ取得先はhttps://cloud.google.com/bigquery/public-dataにあるja.wikipedia.orgへのアクセス履歴が収録されたデータベースのうちbigquery-public-data.wikipedia.pages 2019とbigquery-publicdata.wikipedia.pages 2020 を利用
脚注3 データ取得https://trends.google.co.jp/
References
- ESOMAR (2020). Global Market Research 2020. Amsterdam: ESOMAR.
- Gozzi, N., Tizzani, M., Starnini, M., Ciulla, F., Paolotti, D., Panisson, A., & Perra, N. (2020). Collective response to media coverage of the COVID-19 pandemic on Reddit and Wikipedia: mixed-methods analysis. Journal of Medical Internet Research, 22, e21597.
- 星野崇宏・上田雅夫 (2018). マーケティング・リサーチ入門. 有斐閣.
- 岩崎達也・小川孔輔 (2017). メディアの循環「伝えるメカニズム」(法政大学イノベーション・マネジメント研究センター叢書14). 生産性出版.
- JPNIC (2023). インターネット歴史年表. JPNIC アーカイブス. https://www.nic.ad.jp/timeline/ (2023年10月10日閲覧)
- 柏木信一 (2000). 生活者概念の経済学的一考察. 生活経済学研究, 15, 145-154.
- Leuf, B., & Cunningham, W. (2001). The Wiki way: Collaboration and sharing on the Internet. Addison-Wesley.
- 牧野友衛 (2014). Twitterの作るエコシステム構築におけるプラクティス. デジタルプラクティス, 5, 280-283.
- Moat, H. S., Curme, C., Avakian, A., Kenett, D. Y., Stanley, H. E., & Preis, T. (2013). Quantifying Wikipedia usage patterns before stock market moves. Scientific reports, 3, 1801.
- 森脇丈子 (2001). 「消費者」から「生活者」へ— 大熊信行氏の「生活者」論を素材として. 立命館経済学, 50, 54-71.
- 長崎貴裕 (2008). インターネット調査の歴史とその活用. 情報の科学と技術, 58, 295-300.
- 日本経済新聞社 (2023). 「日経平均ボラティリティー・インデックス」リアルタイム算出要領. 日本経済新聞社.
- 日経クロステック (2021). ISO5218、NFT…、押さえていますか? 初秋の注目キーワード. 事業化のススメ、テクノロジーの生かし方. https://xtech.nikkei.com/atcl/nxt/column/18/01010/00012/ (2023年10月10日閲覧)
- NTTドコモ (2023). 会社の沿革. 会社案内. https://www.docomo.ne.jp/corporate/about/outline/history/ (2023年10月10日閲覧)
- 大知正直・長濱憲・榊剛史・森純一郎・坂田一郎 (2016). 口コミ指数による事例類型化に基づく複数メディアのヒット前の露出を 先行指標とした情報拡散過程の分析. 広報研究, 20, 35-51.
- 大田靖・水谷直樹 (2021). 人間社会的流行における数理モデルの提案 イノベータ理論と時間遅れの方程式を用いて. 日本オペレーションズ・リサーチ学会和文論文誌, 64, 22-45.
- 大隅昇 (2001). 電子調査,その周辺の話題— 電子的データ取得法の現状と問題点— , 統計数理, 49, 201-213.
- 清水麻衣 (2013). CGMが消費者の購買意思決定プロセスに及ぼす影響— 消費者発信情報と企業発信情報の比較— . 商学論集, 81, 93-121.
- 清水信年 (2004). インターネットで収集する消費者情報と製品開発. マーケティング・ジャーナル, 24, 18-30.
- ソフトバンク (2023). 沿革(旧ソフトバンクBB株式会社). 会社概要. https://www.softbank.jp/corp/aboutus/profile/history/sbb/ (2023年10月10日閲覧)
- 総務省 (2023). 令和5年版情報通信白書. 総務省.
- 鈴木督久 (2021). 世論調査の真実. 日本経済新聞出版.
- Suwa, H., Ogawa, Y., Umehara, E., Kakigi, K., Yasumoto, K., Yamashita, T., & Tsubouchi, K. (2017). Develop method to predict the increase in the Nikkei VI index. In: 2017 IEEE International Conference on Big Data, 3133-3138.
- 高橋綾子・藤井修平 (2022). 新型コロナウイルス禍のアマビエにみる妖怪の社会的機能. 心理学研究, 93, 58-64.
- 植田雄介・朝日弓未 (2014). Twitter利用者の関心移行モデルの構築と検証. オペレーションズ・リサーチ, 59, 219-228.
- Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., & Mann, G. (2023). Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564.
- 吉田光男・荒瀬由紀・角田孝昭・山本幹雄 (2015). 検索頻度推定のためのWikipediaページビューデータの分析. 2015年度人工知能学会全国大会(第29回).
