要 旨
本研究の目的は,ソーシャルメディアの1つであるTwitter上の新製品についての話題を分類しその時系列的な変化をとらえることにある.そのため,Twitter上の新製品についての書き込みデータを収集し分析を行った.近年,Twitterは利用者を急激に増やしており,市場動向をとらえるソーシャルリスニングのためのツールとして注目されている.本研究では,そのようなTwitterにおける新製品についての書き込みを分析対象として新製品発表からの時系列に沿って,どのような内容がどのようなタイミングで書き込まれているのか,また企業のコミュニケーション戦略とツイートの関連性はどのようになっているのかということを明らかとすることを目指して研究を行った.Twitter上の新製品についての話題を分類するための分析では非負行列因子分解を用いた.その結果,話題の分類と時系列的な変化,また企業のコミュニケーション戦略との関連性をとらえることができた.
1. はじめに
近年,消費者が製品やサービスについて情報の発信や共有を容易に行える環境が整備されつつある.スマートフォンは急速な普及傾向を維持し,タブレット型端末も着実に普及している1.スマートフォンやタブレット型端末の普及もあいまって,消費者自らが製品やサービスについての情報を生成・発信することのできるブログ,Twitter,Facebook などのソーシャルメディアの利用者が増加している.2012 年度末での我が国におけるTwitter とFacebook の利用者数は,それぞれ14.0 百万人と14.9 百万人となっている2.利用端末別にソーシャルメディアの利用率をみるとスマートフォンやタブレット型端末を利用している人の方がパソコンや携帯電話を利用している人よりも,ソーシャルメディアを利用している割合が高い3.いつでも手軽にアクセスできるスマートフォンやタブレット型端末等の普及が今後さらに進めば,ソーシャルメディアの利用はさらに高まると考えられる.
これらのソーシャルメディア上で語られる消費者が発信する情報の特徴としては,消費者の生の声であり,受け手と同じ消費者の第三者の意見であるから信頼を与えうるということがあげられる.この特徴はテレビ,新聞,ラジオ,雑誌の4 大マスディアを中心とした従来型メディアにおいて企業側が生成し発信している広告により提供される情報とは大きく性質が異なる.Rosen(2002) は口コミの重要性を高める要因として,ノイズ,懐疑的態度,つながりの3 つをあげている.ノイズとは現代の情報過多の中で口コミ情報が埋没しないか,懐疑的態度とはその口コミ情報が第三者の意見であり信頼できるかどうか,つながりとはその情報が広がる経路があるかどうか,ということである.もし,ソーシャルメディアでの情報の発信者がなんらかの報酬を受け取っているということが判明した場合,その情報の受け手である消費者はその情報を広告と受け取り,信頼できる情報なのかと疑問をもつ.仮にその情報の発信者が正直な意見を書いたとしても,受け手の方ではそのようには感じにくくなる.これまでのソーシャルメディアを用いた企業のコミュニケーション戦略では,バズ・マーケティングと呼ばれる自社の製品やサービスを記事として取り上げてもらうことを目的としたプッシュ型のマーケティング活動が行われてきた(田村,2006).バズ・マーケティングでは書き手に製品や報酬を提供することにより,製品についての情報をソーシャルメディアに書き込んでもらう.したがって,書き手がなんらかの報酬を受け取っているということが判明した場合,懐疑的態度により,その口コミ情報が同じ消費者の第三者の意見であり信用できるという受け手の信頼は損なわれ,その情報は,企業が発信している広告と同じものとして受け取られる危険がある.ケースによっては,受け手に嫌悪感を与え,コメント欄に誹謗中傷が数多く書き込まれる炎上という現象までも発生しうる.
しかしながら,ソーシャルメディアを用いた消費者による情報発信は,企業のコミュニケーション戦略においてコントロールできないが,無視することもできないものになりつつある.平成25年通信利用動向調査(総務省)4 によれば,ソーシャルメディアサービスを一部でも活用していると回答した企業の割合は15.8%で,その利用していると回答した企業を対象に,その活用目的・用途をみると「商品や催物の紹介,宣伝」が65.7%と最も多く,次いで「定期的な情報の提供」が50.5%,「会社案内,人材募集」が34.4%となっている.今後もさらに消費者のソーシャルメディアの利用が拡大することが予想でき,その傾向が企業のコミュニケーション戦略に与える影響も拡大すると推察される.よって,今後はさらにソーシャルメディアにおける消費者間のコミュニケーション活動をも包括したコミュニケーション戦略の立案が求められる.そして,その際には従来のバズ・マーケティングのようなプッシュ型の戦略ではなく,消費者が書く記事の傾向を把握し,自社のコミュニケーション戦略とソーシャルメディアで取り上げられる記事との関連性を明らかとすることで,より効果的に自社製品の情報が取り上げられるように工夫するプル型の戦略が重要になると考えられる.
消費者のソーシャルメディア上での書き込み内容の特徴を把握し,企業のコミュニケーション戦略と書き込み内容との関連性を明らかとすることを目的とした研究は,これまで主にブログをメインとして研究が行われてきた(例えば,日本広告主協会Web 広告研究会(2005) や中山・竹内・酒折・鶴見・横山・増田(2008) など).しかしながら,今後の消費者のソーシャルメディアの利用が拡大することを踏まえると,ブログ以外のTwitter などについても書き込み内容の特徴を把握することが重要となる.また,これまでの調査・研究では書き込みが行われやすい耐久消費財,旅行,レストランなどのサービスを分析対象として研究が行われることが多く,一般消費財についてはそれらに比べるとブログに書き込まれる頻度が少ないため分析対象とされることが少なかった.しかし,Twitter はブログとは異なり,140 文字の入力文字制限があることからスマートフォンやタブレット型端末からリアルタイムでの書き込みを行いやすい.そのためブログであまり書き込みの見られなかった一般消費財についても書き込みが行われる頻度が高いと予想される.以上から,本研究では,飲料などの一般消費財のTwitter 上の書き込み内容を分類することで,企業のコミュニケーション戦略とソーシャルメディア上で取り上げられる記事との関連性を明らかとし,より効果的に自社製品の情報が取り上げられるようにするためにはどうしたら良いのかプル型の戦略のための示唆を導くことを目指す.
日本広告主協会Web 広告研究会(2005) では,企業の製品がどのようにブログに書きこまれているのかを把握するために専門家の目視により書き込み内容を分類している.約100 万のブログ(ココログ,ライブドアブログなど)を対象とし,キーワード(製品名)を指定した上で,レッドクルーズ株式会社独自のパターンマッチングによる高性能抽出を実行し,専門家による分類と分析(目視)を行っている.その結果,「ニュース(ニュースリリース意見追加型,リピーター型,レビューアー型)」「広告(広告評論型,懸賞情報提供型,アフィリエーター型)」「体験・感動(体験・感想・感動型(ファン),体験・感想・感動型(ニュートラル),体験・感動・感想型(批判的)),日記(マイペーサー型)」の記事のタイプが存在していることを示している.また,書き込みの内容の時系列的変化について「新製品発表と同時にニュースサイトへの掲載記事や広告に関する書き込みが急激に増加し,ニュースサイト関連がすぐ下火になる.広告関連は比較的継続性が高いものの徐々に減少していき,製品についての体験,感動,感想が変わって増加し,ロングランになるに従って日常生活の中でのさりげない言及にだんだん移行していく」と報告している.そして,ブログで製品が言及される場合ポジティブなものが多く,マーケティング活用の可能性が期待できることが述べられている.このように,新製品の発表から新製品の発売以降の消費者の当該製品に対する認知率の変化,当該製品のトライアルやリピート購買の発生といった製品がおかれている状況の変化(製品時系列)にともない,書き込みの質も変化していると考えられる.そこで,本研究では,製品時系列を考慮した上で製品に対する書き込みを分類し,その書き込みの質的な変化から,消費者の製品認知の状況,トライアルやリピート購買の発生といった消費者行動の把握を目指す.
日本広告主協会Web 広告研究会(2005) の事例のように製品時系列に沿ったTwitter 上の書き込み内容の分類を行う際に,専門家の目視により書き込み内容を分類することも可能である.ただし,応用可能性を考えると書き込みの情報は膨大なため,その書き込みを目視により分類するには多大な時間と労力が必要であり,即応性のある対応は難しく,コストもかかるため現実的とはいえない.実際に,Twitter 上の書き込みを目視により分類しようとしてもどのようなトピックが存在しているのかを判別するのは難しい.表1 は2011 年9 月に発売されたキリン午後の紅茶パンジェンシーについての10 件の書き込みであるが,これらの書き込みを目視により確認したとしてもその中にどのようなトピックが存在しているのかを判断するのは容易ではない.

表1
10 件のキリン午後の紅茶パンジェンシーについての書き込み
目視による分類を行う際に生じる上述の課題を解決し,効率的に適切な分類を実行するためには,テキストマイニング手法を活用することが考えられる6.なお,書き込みを分類する際に使用するデータは,形態素解析を行うことで得られる文書(書き込み)× 単語からなるデータであり,非常にスパース(疎)なデータとなる.スパースなデータを分析するためには,大量の記憶容量を必要とし,類似度計算などにも時間がかかる.そのため,データの次元圧縮を行って分析するための手法がこれまで数多く提案されている(柘植・獅々堀・北,2001).文書× 単語からなる行列の次元圧縮を行う最も代表的な手法には,特異値分解(SVD)の概念に基づく潜在的意味解析(Latent Semantic Analysis, LSA; またはLatent Semantic Indexing, LSI; Deerwester, Dumais, Furnas, Landauer, & Harshman, 1990) や確率的潜在意味解析(Probabilistic Latent Semantic Analysis, PLSA; またはProbabilistic Latent Semantic Indexing, PLSI; Hofmann, 1999a, b) が提案されている.潜在的意味解析では,文書× 単語の行列に対してSVD を用いて,元の行列をより低い次元のデータに縮約する.潜在的意味解析はSVD に基づく方法であり,概念的にわかりやすい.ただし,計算に時間がかかり,大規模なデータに対して適用することは難しい(柘植・獅々堀・北,2001).また,SVD に基づく方法で分析を実行すると,出現率の低い単語が大きな影響を与え,結果から単語間の関係性をうまく解釈できないことが多い.一方,確率的潜在意味解析は潜在的意味解析に確率的概念を導入し,各文書の背景にある話題(トピック)に基づいて各単語が確率的に生成されるとする確率的な自然言語モデルである.中山他(2008) では,確率的潜在意味解析を用いてお茶と液晶テレビをキーワードとして抽出したブログ記事の分類を試みている.中山他(2008) では,形態素解析により認識された単語の中から,キーワードとなりえる「名詞」(一般名詞,形容動詞語幹,サ変接続,固有名詞)と「形容詞」を抽出し,その後,各単語を単純集計して,出現率の多い上位約200 語の単語(お茶210 語,液晶テレビ208 語)を,分析対象として,ブログの記事に各単語が登場するかどうかを表したデータ(文書× 単語)を分析している.分析にあたり,最初にコレスポンデンス分析により記事内容の把握を試みたが,出現率の低い単語が大きな影響を与えている結果が出力され,有益な示唆を導くことができなかったことが述べられている.この原因として,アフィリエイト広告などの影響でブログの記事内容にはまったく同じ文章が多数存在するためであり,行と列の要素の相関が最大になるように分析するコレスポンデンス分析のような相関構造に基づいてデータ構造を明らかとする古典的な手法は適していないということが述べられている.中山他(2008) ではこの結果を踏まえ,確率的潜在意味解析を用いて分析を行っている.そして,ブログの記事には「日記型」「アフィリエイト型」「使用経験・感想型」「専門的・説明型」「ニュース型」が存在することを示している.この分類結果は,日本広告主協会Web 広告研究会(2005) において示された記事内容の4 分類と類似した結果となっている.なお,中山他(2008) では,日本広告主協会Web 広告研究会(2005) の「体験・感動」について,商品の性能や機能についての記事・書き込みを「専門的・説明型」,商品を使用しての感想についての記事・書き込みを「使用経験・感想型」と細分化している.このように,テキストマイニング手法を活用することで専門家による目視による分類と同程度の分類を実行することが可能となる.
以上から,本研究では,これまでブログを対象とした研究ではあまり分析対象とされてこなかった飲料などの一般消費財のTwitter 上の書き込みに注目して,書き込み内容の分類を試みる.また,新製品の発表から新製品の発売以降の消費者の当該製品に対する認知率の変化や当該製品のトライアル購買,リピート購買の発生といった製品がおかれている状況の変化にともない,書き込みの質も変化しているものと考えられる.そこで,本研究では,製品時系列を考慮した上で製品に対する書き込みを分類し,その書き込みの質的な変化から,消費者の製品認知の状況,トライアルやリピート購買の発生といった消費者行動の把握を目指す.そして,これらの分析から得られる知見により,消費者行動に即したプル型の書き込みを促すような情報提供が可能になると考える.各状況に即したプル型の書き込みを促すような製品の情報提供が可能となれば,企業のコミュニケーション戦略において有益といえよう.なお,書き込み内容の分類を実行するための分析には単純な繰り返し演算のみで,もとの非負行列を2 つの非負行列の積に分解し次元縮約を行うため大規模な行列に対しても有効性が高いといわれている非負行列因子分解(Non-Negative Matrix Factorization, NMF; Lee & Seung, 2000) を活用し,製品時系列を考慮したTwitter 上での書き込みに登場するトピック(話題)の分類を試みる.なお,NMF の基本的な原理は確率的潜在意味解析と本質的に同じであることが示されている(Ding, Li, & Peng, 2006).NMF では,縮約後の各軸をトピックと考えるため,その軸へ射影した各単語の値がトピックと各単語との関連度を表す.また,NMF では非負制約条件の下で行列分解を行うので,元の行列は得られた分解行列の減算をともなわない加算のみの線形結合で表現される.そのため特定要素のみで全体の行列を表現することが可能となり,自然で直感的に分かりやすく解釈が行いやすい結果が得られるという利点がある.非負制約条件の下で行列を分解するため縮約後の各軸は独立ではない点に注意が必要であるが,各軸にはそのトピックに共通して現れる単語が集まっていると考えれば解釈上の利点ともいえる(新納,2007).
2. データ
本研究では一般消費財の中から飲料(アルコール飲料を含む)を分析対象として選択した.ただし,既存製品の場合には過去のコミュニケーションの影響が考えられるため,その影響を排除するとともに,製品時系列を考慮するために2011 年9 月発売の新製品を対象アイテムとした.そして,対象製品名が記載された書き込みをTwitter 上から定期的に検索して期間中の対象製品に関する書き込みデータを収集するプログラムを開発し,2011 年8 月からデータの収集を開始した.開発したプログラムの概要については鶴見・中山・増田(2013) を参照のこと7.なお,本研究では対象アイテムの中から「キリン午後の紅茶パンジェンシー茶葉2 倍ミルクティー」を分析対象とした.その他の対象アイテムの中にはTwitter を活用したキャンペーンが実施され,キャンペーンと連動した書き込みが非常に多く行われているような製品も存在した.しかし,キリン午後の紅茶パンジェンシーではキャンペーンの影響はあまりみられなかった.また,飲料などの一般消費財についてはブログではあまり書き込みが行われにくいため分析対象とされてこなかったが,キリン午後の紅茶パンジェンシーについてのTwitter 上での書き込みは多数行われており,飲料などの一般消費財を対象とした本研究の目的に即しているといえる.以上が,キリン午後の紅茶パンジェンシーを分析対象とした理由である.
キリン午後の紅茶パンジェンシーについての書き込み件数は期間中12,503 件あり,週ごとの推移は図1 の通りである(データ取得期間は2011 年8 月25 日から2012 年5 月19 日).当該製品についての書き込み件数は,発売週(発売日2011 年9 月13 日)に急激に増加(1,720 件)し,発売週の翌週をピーク(2,151 件)として,翌々週まではある程度の書き込み件数(1,492 件)がみられるが,翌々週以降では減少している.翌々週以降では発売週から3 週間後の10 月3 日から10 月9日の週が最も書き込みが多いが785 件で発売週の半数以下となっている.それ以降は多少の変動はあるものの右肩下がりに減少していっている.飲料などの一般消費財はブログなどではあまり書き込みが多く行われなかったが,Twitter では書き込み内容を分類するのに十分な書き込みが行われているといえる.
関東エリア,関西エリア,名古屋エリアの3 エリアを合計した週次の世帯GRP(データ取得期間は2011 年9 月12 日の週から2012 年3 月26 日の週)を見ると,GRP は発売週が最も高く(CM 開始9 月13 日8),翌週まではある程度高い値を示しているがそれ以降は急激に低下している(図1).なお,GRP(Gross Rating Point)とは「延べ視聴率」のことを指し,対象期間におけるテレビCM の出稿量を示す指標として広く用いられている.データ取得開始の8 月25 日から製品発売前までの時期ではそれほど件数は多くないが書き込みが行われている.8 月3 日に新製品発売のニュースリリースがされており9,ニュースリリースと関連した書き込みが行われていると考えられる.その後,9 月13 日の発売開始による店頭での認知,同時に開始されたCM やその他のメディア露出により認知率が向上することでトライアル購買が発生し,それにともなってTwitter への書き込み件数が増加していると推測できる.一方,発売から一定期間が経過すると新製品についてのトライアル購買が収束するため,Twitter への書き込みも減少していると推察される.書き込み件数と世帯GRP の推移を比較すると,GRP に対して1 週間ほど遅れて書き込み件数が推移しているように見えるが,両者はある程度連動していると考えられる(相関係数の値は0.794 であり1%水準で有意となっている).以上から,取得データにおいてはGRP と連動しながら,新製品発売のニュースリリースや発売以降の製品が認知される時期,トライアル購買が発生している時期,トライアル購買からリピート購買へと変化する時期といった製品がおかれている状況の変化により書き込み件数が変化していると考えられる.そして,この量的な変化と同様に,製品時系列にそって消費者の製品認知の状況,トライアルやリピート購買といった消費者行動が変化することにあわせて書き込みの質も変化していると推察される.
3. 分析
当該製品について取集したTwitter 上の書き込みデータにおける文章を形態素解析により単語と品詞に分解し,その後,解釈の行いやすい名詞や形容詞,動詞のみを抽出した10.抽出された単語は16,116 単語であり,それぞれの内訳は名詞13,687 単語,形容詞364 単語,動詞2,065 単語となっている.抽出されたすべての単語を用いて,書き込み× 単語のデータ行列を作成して分析を実行することが本来望ましいが,抽出されたすべての単語からなる書き込み× 単語のデータ行列は非常に大規模かつスパースなデータとなるため分析を実行することは難しい.また,分析を実行できたとしてもその結果の解釈が容易ではないことも想定される.したがって,製品時系列に沿った質的なトピックの変化をとらえるのに効果的な単語を抽出された単語の中から絞り込む必要がある.一般的には出現頻度上位の単語を対象とすることが多いが,これでは頻度の大きい一般的な単語のみが抽出され,書き込み× 単語のデータ行列を分析した際に一般的な話題のみが抽出される可能性が高い.したがって,全体での出現頻度は小さいが特定の期間において登場するような単語からなるトピックが抽出できない可能性がある.そこで,本分析では各週で登場する単語の違いを反映させた上で単語を絞り込むことが,特定の期間において登場するトピックを抽出するためには重要であると考え,各週(属性)での特徴語を抽出するための方法である補完類似度(Sawaki & Hagita, 1996) により,上述の抽出された単語の中から分析対象とする単語を絞り込むこととした11.

図1
週ごとのキリン午後の紅茶パンジェンシーについての書き込み件数推移と当該週でのGRP の推移
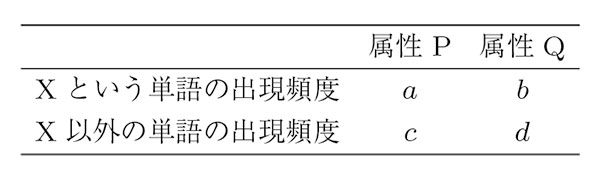
表2
X という単語の属性P とQ における出現頻度データ例
補完類似度とは,単語の出現頻度をもとに対象となる単語の全体での出現頻度とその属性における出現確率を考慮した特徴指標値である.また,外れ値により中心傾向が影響されることが少なくロバストな手法で,情報処理問題で多く利用されている(服部, 2010).表2 のようなX という単語の属性P とQ における出現頻度のデータが与えられているとき,補完類似度Sc は以下のように計算できる(Sawaki & Hagita, 1996).
補完類似度とともに,広く利用される特徴指標値であるカイ2 乗値χ2 は

で計算される.なお,N = a+b+c+d である.両方の指標とも,ある週に特徴的に登場している単語を抽出することが可能である.ただし,カイ2 乗値は出現頻度が小さい単語が重視されやすい傾向があり,単語の出現頻度に大きな開きがあるようなデータの場合にはカイ2 乗値を利用すると,出現頻度が小さい単語を取り上げすぎてしまう危険性がある.本研究で対象とするデータでは特定の単語の出現頻度とすべての単語の出現頻度との差が数百倍あることも想定されるため,特徴語抽出にはカイ2 乗値ではなく補完類似度を指標として用いるのが妥当と考えた.なお,補完類似度においてもある週1 週のみに1 回だけ登場した単語のように,総出現頻度の少ない単語であっても特定の週のみで出現していれば,特徴指標値が最大となり特徴語として抽出されてしまう.極端に出現頻度の少ない単語が特徴語として抽出されることを防ぐため,総出現頻度7回以上の単語を分析対象とした.総出現頻度7 回以上とした理由は,本分析では週単位で特徴語を抽出しており,特定の週において特徴語であれば1 日に1 回程度は登場して欲しいと考えたためである.各週から全期間での総頻度が7 以上の単語のうち,補完類似度が上位20 以内の単語を同順位も含めて抽出すると793 単語が抽出された.複数の週で重複して抽出されている単語も存在するので,実際には351 単語が分析対象単語として抽出される.それに対して,全期間での総頻度が7 以上の単語で,各週から出現頻度が上位20 以内の単語を同順位の単語を含めて抽出すると,1,038 単語抽出される.同順位の単語が多いため補完類似度よりも多くの単語が抽出されているが,複数の週で重複して抽出されている単語もあるので実際には256 単語が抽出される.出現頻度を基準として抽出すると補完類似度と比べて抽出される単語の数は少なくなり,抽出される単語の多様性は低くなってしまっている.補完類似度により抽出されている単語群は頻度情報を用いたものよりも多様な単語が抽出され,各週で取り上げられる単語の違いを反映させた単語を抽出することができると考えられる.なお,製品名をキーワードとしてTwitter 上での書き込みのデータを抽出しているため,製品名についての単語は分析対象から除外している.
また,上述のように当該製品についての書き込み件数は,発売週に急激に上昇し,発売週の翌週をピークとして翌々週まではある程度の書き込み件数があるが,翌々週以降では急激に減少する.また,GRP などとも連動しながら,新製品発売のニュースリリースから発売以降の製品が認知される時期と,トライアル購買が発生している時期,トライアル購買からリピート購買へと変化する時期といった製品がおかれている状況の変化により,書き込み件数が変化していると考えられる.さらに,日本広告主協会Web 広告研究会(2005) で指摘されているように,製品時系列により書き込み件数だけではなく書き込みの質も変化していると推察される.よって,本研究では製品時系列に沿って書き込みの質が変化していると考え,その製品時系列ごとに書き込みにおける話題を抽出するために書き込み件数の量的な変化から製品時系列が変化していると考えられる以下の3 つの期間にデータを分割することとした.
• 期間1:2011 年8 月25 日から発売週(8 月25 日から9 月18 日.発売日は2011 年9 月13 日)
• 期間2:発売週の翌週と翌々週(2011 年9 月19 日から10 月2 日)
• 期間3:発売週の翌々週以降(2011 年10 月3 日から2012 年5 月19 日)
それぞれの期間ごとにデータ分析することで,各期間の分析結果から製品時系列に沿った書き込みの質的な変化を読み取ることができると考える.期間1 では,新製品発表や新製品発売を報告するようなニュース型の書き込みが発生し,また店頭での認知やCM が開始されたことによる広告と関連した書き込み,店頭やCM で製品を認知することによる製品の購入や購入意向についての書き込みが行われると推察される.期間2 では,新製品発売からの時間の経過にともないニュース型の書き込みは減少し,トライアル購買が発生することにより,製品自体についての書き込みが増えると考えられる.期間3 では,発売から一定期間が経過することにより,トライアル購買からリピート購買の時期へと移行することで,製品への愛着のような書き込みが行われるようになると予想される.そして,広告関連の書き込みは広告出稿量の低下とともに減少すると考えられる.製品時系列に沿った質的な話題の変化を把握し,書き込みの質的な変化かから,消費者の製品認知の状況やトライアル購買,リピート購買の発生といった消費者行動をとらえることができれば,各状況に即したプル型の書き込みを促すような製品の情報提供が可能となり,企業のコミュニケーション戦略における重要な情報をえることができると考える.なお,データをまとめて分析することも可能であるが,3 期間にデータを分割して分析することとしたのは,データをまとめて分析した場合,各期間で共通のトピックが得られるが,3 期間のデータを個別に分析することで,各期間での書き込みの特徴がより反映されるような各期間で多様性のあるトピックを抽出したいと考えたためである.なぜならば,本研究では新製品が発売されてからの消費者の製品の認知率の変化,トライアル購買やリピート購買といった消費者行動の変化とともに書き込みの質も変化していると考えており,各期間で共通のトピックを想定するよりも各期間での書き込みの特徴がより反映されるようなトピックが抽出された方が望ましいと考えたからである.
また,期間3 のみが他の期間に比べデータ期間が長くなっているが,期間3 で把握しようとしている製品時系列の状況は,市場に製品が浸透してトライアル購買からリピート購買が発生し製品への愛着が発生するような状況である.本研究においては,製品への愛着が醸成されるような十分な期間を分析対象としたいと考え,データ取得期間すべてを分析対象期間としたため,期間3のデータ期間が他と比べて長くなっている.期間1 と2 については,設定の短期間において製品時系列が変化していることがTwitter 上の書き込み件数の推移から類推されるため期間3 よりも短い期間の設定とし,期間2 が最も短い期間となっている.小川(2007) によれば飲料の主力販売業態の1 つであるコンビニエンスストアでは,毎週の販売時実績に基づき商品の改廃を行うため,多くの新製品が「数週」で姿を消すとされている.このため製造業はその事態を避け新製品が売り場から撤去されることのないように,発売直後の短期間に集中的に広告を投下する.そのため発売直後はそれ以降の期間とは異なる状態にあるため,期間2 は比較的短い期間に設定した.
3 つの期間にデータを分割することで,当該期間に登場しない単語については除外し,また抽出した単語が登場していない書き込みについても除外して分析を行った.その結果,期間1 では258 単語,1,312 件の書き込みを,期間2 では304 単語,2,589 件の書き込みを,期間3 では349単語,5,344 件の書き込みを分析対象とした.そして,分割した3 期間のデータそれぞれから書き込み× 単語のデータ行列を作成し,非負行列因子分解(Non-Negative Matrix Factorization,NMF; Lee & Seung, 2000) により分析した.
NMF では,非負のn × m 行列V を非負のn × r 行列Wと非負のr × m 行列H に
と分解し,V とWHの差が最小となるように反復的にWとHを改善していく.ここで,Wの要素をwij,H の要素をhjk とすると,wij はi 番目の単語がトピックj に属する度合(関連度),hjk はk 番目の文書がトピックj に属する度合を表す.このとき,r がもとのデータを縮約する軸の数(トピックス数)となる.つまり,NMF では,抽出するトピック数を分析前に指定しておく必要がある.本分析では当該製品のTwitter 上のトピックの概要の把握,解釈の容易性の2 点を考慮してトピック数を設定した.実際には,まず各3 期間の分析において,トピック数を4 から10 の7 パターンで分析した.そして,トピックの概要の把握と解釈のしやすさから,それぞれの期間においてトピックの数を6 として設定した結果を解として採用した.なお,分析にはR のNMF のパッケージで提供されている関数NMF () のユークリッド距離に基づいたモデルであるlee を用い,初期値をランダムに発生させて分析を行った.NMF では,分析に使用しているデータとの適合度が最も良くなるように(残差が最小となるように),その初期値を反復的に改善しながら解を求める必要がある.したがって,初期値に解が依存し,局所最適解に陥る可能性がある.初期値をランダムに発生させて分析している場合には,100 回から200 回程度の分析を繰り返し行い,最も残差が小さい結果を解として採用することが局所最適解に陥ることを防ぐ上で望ましい.そこで,本研究では各3 期間ともにそれぞれ150 回分析を繰り返し行い,最も残差が小さい結果を解として採用した.
4. 分析結果と考察
4.1. NMF によるトピックの分類結果
NMF では,縮約後の各軸をトピックと考え,その軸へ射影した値が単語とトピックとの関連度を表す.データ期間1(2011 年8 月25 日から発売週),期間2(発売週の翌週と翌々週),期間3(発売週の翌々週以降)における各トピックでの関連度上位10 以内の単語とその関連度はそれぞれ表3~表5 のとおりである(表中の各単語の後の()内の数字が関連度を示す).
各トピックと単語の関連度から,各トピックには関連の強い単語が1 つもしくは2 つ程度存在し,その単語をハブとしてトピックが形成されていることが分かる(表3 から表5).トピックのハブとなっている関連度の高い単語が1 つもしくは2 つ程度となっているのは,Twitter の書き込みには140 字という文字数制限があるため少ない文字数で簡潔に内容を伝達する必要があり,関連度の高い単語が他の単語とのハブとなって書き込みが行われているためと考えられる.例えば,期間1 において,トピックと単語の関連度から対象製品を実際に飲んでみた上で味についての感想を書き込んでいるようなトピック(使用経験・感想型の味についてのトピック)と考えられるトピック1 では,美味しいという単語の関連度が0.512 と高くなっているが,他の単語では関連度が高いもので10 分の1 程度の値となっている(表3).よって,キリン午後の紅茶パンジェンシーを飲んでみて感じた,美味しいという共通のコアな感想を他の関連度の比較的高い単語ともに伝えているような書き込みがトピックとしてまとめられていると考えられる.実際に,以下のトピック1 と関連度の高い関連度上位3 件の書き込みを見てみると,共通して美味しい(おいしー)という表現が含まれているが,その他の単語についての共通性は薄くなっている(ただし,1番目の書き込みは2 番目の書き込みに対しての非公式リツイート(コメントを付けてリツイートをすることを意味)となっている).
NMF では各トピックと各書き込みの関連度が得られるので,関連度が最も高いトピックをその書き込みが所属するトピックと考えると各トピックの構成比を算出することができる.期間ごとの各トピックのタイプとその構成比は図2 のように整理することができる.
各トピックと単語の関連度から,期間1 から3 の各トピックは,使用経験・感想型,専門的・説明型,ニュース型,アフィリエイト型,その他に分類することができる12.さらに,使用経験・感想型のトピックは味,購入意向,試飲感想,感覚,製品購入,製品全般の6 つのトピックに分類

表3
期間1(2011 年8 月25 日から発売週)での各トピックの関連度上位10 以内の単語

表4
期間2(発売週の翌週と翌々週)での各トピックの関連度上位10 以内の単語

表5
期間3(発売週の翌々週以降)での各トピックの関連度上位10 以内の単語
することができる.使用経験・感想型のトピックは期間1 のトピック1 から3,期間2 のすべてのトピック,期間3 のトピック2 から5 が該当する.期間1 においては,使用経験・感想型の味,購入意向,試飲感想についてのトピック,専門的・説明型,ニュース型についてのトピックが存在している.新製品発売に向けてのTV 広告が行われたことや店頭での認知により,製品についての認知率が向上し,また,その製品の特徴である紅茶の評価用語「パンジェンシー」についての関心も高まったことにより新製品発売と関連した書き込みが行われていると考えられる.期間2 では期間1 よりもキリン午後の紅茶パンジェンシー製品自体についてのトピックが多くなっている.これは,発売週の翌週と翌々週では製品認知の段階からトライアル購買の段階へと製品時系列が

図2
期間ごとの各トピックの構成比
変化したことにより,書き込みの質も変化し,製品自体についての書き込みが行われるようになったと考えられる.期間3 では.使用経験・感想型でも特にキリン午後の紅茶パンジェンシーの味について好意的な印象が書き込まれているトピックが増えており,製品へのファン的な要素を示しているトピック4 の構成比が42.2%と最も大きい(図2).期間3 においては製品時系列の変化により書き込みの質が変化し好意的なファンのような書き込みが多く行われるようになっていると推察される.このように使用経験・感想型のトピックが多く登場しているのは,対象を一般消費財としたため,製品情報についての専門性や製品について説明する必要性は低く,実際に飲んでみての経験や感想などの書き込みが多く行われているためと考えられる.また,専門的・説明型やニュース型のトピックが期間1 のみに登場しているのは,新製品の発売やCM の開始によって製品に対する認知が高まるとともに,これらのトピックと関連した書き込みが行われ,ある程度の製品の認知の広がりとともに書き込みが行われなくなったためといえる.専門的・説明型の期間1 のトピック5 は構成比が29.4%と期間1 で2 番目にサイズが大きい(図2).今回分析対象とした専門性の低い一般消費財である飲料において専門的・説明型のトピックが登場しているのは,製品名にもなっている当該製品の特徴である紅茶の評価用語「パンジェンシー」の意味の専門性が高かったためだと考えられる.そして,アフィリエイト型のトピックが期間3 において登場しているが,これは発売から期間が経過することで上昇した消費者の認知率を利用したアフィリエイトなどの書き込みが行われるようになったためと考えられる.ただし,そのサイズは6.7%と小さく,多数のアフィリエイト型の書き込みが行われているわけではない(図2).また期間1 のトピック4 の構成比は10.1%,期間3 のトピック1 の構成比は12.1% とそのサイズはあまり大きくはないが,キリン午後の紅茶パンジェンシーとは直接関係のない紅茶の評価用語「パンジェンシー」と関連した記事についてのトピックも存在する(図2).それぞれのトピックの構成比はあまり大きくないが,テキスト情報を抽出する際のキーワード設定については十分留意する必要がある.設定したキーワードによりどのようなテキスト情報が抽出されうるのかという想定が正しくない場合には,意図しないデータを分析してしまう危険性が存在するので注意が必要である.
4.2. 各トピックの期間を通じた共通点と各期間での相違点
本節では,数多く登場した使用経験・感想型のトピックの特徴について,図2 に基づいて,各トピックの期間を通じた共通点と各期間での相違点という観点に基づいて説明する.味についてのトピックは,サイズは異なるものの全3 期間において登場し,全期間共通のトピックと考えられる.また,期間2 においては書き込みの特徴の異なる2 つの味についてのトピックが登場し,そのサイズも2 つのトピックを合わせると他の期間よりも大きい.発売からの時間の経過とともに製品についての認知率が向上することでトライアル購買が発生し,その結果,味についての書き込みが期間2 では多くされていると推察される.
購入意向についてのトピック2 は期間1 でのみで登場し,その構成比は31.9%と期間1 で最も
サイズが大きくなっている.購入意向についてのトピックは新製品が発売された直後の特徴的な
トピックと考えられる.新製品が発売され,CM などの広告に触れることによって,その製品に
対するトライアル意向が高まり,購入意向に類するような書き込みがされていると推測できる.
試飲感想についてのトピックである期間1 のトピック3,期間2 の製品購入についてのトピックであるトピック3 と製品全般についてのトピックであるトピック5 はそれぞれ当該製品の広告と関連付けながら書き込みが行われている.期間1 のトピック3 の構成比はそれほど大きくないが,同様の傾向を示す期間2 のトピック3 の構成比は当該期間において最も大きい30.2% ,トピック5 の構成比は次いで大きい20.8%となっている.期間2 では製品購入や製品全般についての書き込みが当該製品の広告と関連付けながら多数行われていると考えられる.期間3 ではトピック5の関連度の10 番目にCM という単語が存在するのみで広告やCM と関連付けた書き込みは減少しているといえる.GRP も発売週が最も高く,翌週まではある程度高い値を示しているがそれ以降は急激に低下しており製品の広告と関連付けられた書き込みの増加減少傾向はGRP と関連していると考えられる.
感覚についてのトピックは,期間2 以降に登場し,期間2 においては書き込みの特徴の異なる2つの感覚についてのトピックが存在している.2 つのトピックを合わせると期間2 において2 番目に大きい構成比となる.発売からの時間の経過とともに製品についての認知率が向上し,トライアル購買が発生することで製品の特徴である紅茶の評価用語の「パンジェンシー」という感覚を感じるかどうかという書き込みが多く行われていると考えられる.これは,味の書き込みが期間2 において増加しているのと同じような傾向といえる.
期間2 と3 において製品全般についての書き込みが行われているトピックが存在しているが,期間が経過するにつれて,CM などについての書き込みは減少し,味そのものについての書き込みやその特徴(紅茶の評価用語であるパンジェンシー)など製品自体の書き込みが行われるように書き込みの質も変化していると考えられる.
期間3 においては,トピック2 では美味しいという単語の関連度が最も高く,トピック4 では「うまい」「好き」「良い」という各単語の関連度が比較的高く,トピック5 においても「うまい」という単語の関連度が高くなっている.製品時系列が変化するにつれて書き込みの質が変化し,午後の紅茶パンジェンシーの味について好意的な印象が書き込まれているトピックが増えているといえよう.また,製品へのファン的な要素を示しているトピックであるトピック4 の構成比が42.2%と最も大きく,期間3 においては好意的なファンのような書き込みが多く行われていると推察できる.
4.3. 各期間での製品時系列に沿った書き込みの質の変化
各期間での製品時系列に沿った書き込みの質の変化について考察する.期間1(2011 年8 月25日から発売週)において,購入意向についてのトピックであるトピック2 では午後ティーという表現を軸に,新製品が発売され,CM などの広告に触れることによって,その製品に対するトライアル意向が高まり,購入意向に類するような書き込みがなされている.また,構成比も31.9%と最も大きく(図2),購入意向についてのトピックは新製品が発売された際の特徴的なトピックと考えられる.期間1 の専門的・説明型のトピックであるパンジェンシーの意味について説明しているトピック5 は構成比が29.4%と2 番目にサイズが大きい(図2).これは,新製品発売とCM開始により新製品についての認知が高まり,またその製品の特徴である紅茶の評価用語「パンジェンシー」の意味についての興味・関心が高まったことで,その意味を説明する書き込みが多数行われたためと考えられる.ただし,製品の認知の高まりとともに,パンジェンシーの意味についての話題性も低下し,期間2 以降では専門的・説明型のトピックは存在しなくなっている.なお,一般消費財のようなあまり専門性の高くない製品において専門的・説明型のトピックが存在しているのは紅茶の評価用語「パンジェンシー」の意味の専門性が高く,話題性があったためと考えられる.以上から,期間1 においては新製品発売に向けてのTV 広告が行われたことや店頭での認知により,製品についての認知率が向上し,またその製品の特徴である紅茶の評価用語「パンジェンシー」についての関心も高まり,それらと関連した書き込みが多く行われている.そして,製品が発売されてからは,認知率の向上により製品についてのトライアル意向が高まり,トライアルした上での感想についての書き込みが行われていると考えられる.よって,この時期においては新製品についての広告を目にしての投稿や新製品が発売されトライアルしたことを報告するような書き込みが多く行われていると推察できる.したがって,企業が自社製品をTwitter 上に取り上げてもらうためのコミュニケーション戦略としては,TV 広告や屋外広告などにより認知を広げ,トライアルを促すような戦略が効果的といえよう.
期間2(発売週の翌週と翌々週)は,すべて使用経験・感想型のトピックとなっており,期間1よりもキリン午後の紅茶パンジェンシー製品自体についてのトピックが多くなっている.これは,発売週の翌週と翌々週ではトライアル購買が促進し,キリン午後の紅茶パンジェンシー製品自体についての書き込みが行われる機会が増えているためと考えられる.GRP の値は発売週が最も高く,翌週まではある程度高い値を示しているがそれ以降は急激に低下している.期間1 ではGRPと連動した形で,製品を購入して飲んでみた感想と視聴したCM とを関連付けながら書き込みが行われているようなトピックが存在していたが,その構成比はあまり大きくなかった.一方,期間2 においては発売週と翌週に多くのCM を投下したことにより,認知率の向上とトライアル購買が発生し,製品の購買や紅茶をキーワードとした書き込みがCM と関連付けながら行われ,その割合も増加している.また,新製品発売からの時間の経過にともない専門的・説明型やニュース型のトピックが登場しなくなっている.よって,トライアル購買の経験を踏まえての書き込みが多く行われていることから,トライアル購買によりどのような感覚を消費者が有しているのかを各トピック内容から読みとり,それぞれに適したコミュニケーション戦略を選択することが企業には求められる.例えば,パンジェンシーの香りや渋み,味わいを好んでいると考えられる消費者に対しては,パンジェンシーをより深く体感し楽しむにはどのような方法があるのかというような情報を公式サイト(Webpage やFacebook など)で提供することでよりコアなファンとなるように促すといったことが考えられよう.また,パンジェンシーの味は美味しいと評価しているがパンジェンシーそのものを感じることができないと書き込んでいるような消費者に対しては,どのようにするとパンジェンシーを感じることができるのかというような情報提供をすることで,リピート購買を促し,Twitter 上で話題として取り上げてもらうように工夫することなどが考えられる.
期間3(発売週の翌々週以降)では,期間2 と同様に使用経験・感想型の製品全般についての書き込みが行われているトピックが存在していたが,期間が経過するにつれて,CM などについての書き込みは減少し,味そのものについての書き込みやその特徴(紅茶の評価用語であるパンジェンシー)についての書き込みなどキリン午後の紅茶パンジェンシー製品自体の書き込みへと内容が変化していた.また,使用経験・感想型のトピック2 では美味しいという単語の関連度が最も高く,トピック4 では「うまい」「好き」「良い」という各単語の関連度が比較的高くなっており,トピック5 においても「うまい」という単語の関連度が高くなっている.このように,午後の紅茶パンジェンシーの味について好意的な印象が書き込まれているトピックが増えていることが分かる.そして,製品へのファン的な要素を示しているトピック4 の構成比が42.2%と最も大きい(図2).期間3 においては好意的なファンのような書き込みが多く行われていると推察できる.そして,期間1 から期間2 になるにつれて,発売週と翌週に多くのCM を投下したことにより,製品の認知率が向上し,またトライアル購買が発生したことで,CM と関連付けた製品の購買や紅茶をキーワードとした書き込みが増加していたが,期間3 においては広告やCM と関連付けた書き込みは急激に減少している.これは,キリン午後の紅茶パンジェンシーの週次での世帯GRP の推移と一致しており,書き込みの質の変化がTV 広告の投入と連動しているものと推測できる.したがって,期間3 においては,新製品販売から時間の経過とともに製品時系列が変化し,Twitterに書き込まれる内容は,その製品に対する好意的な要素を含むものが多くなっていると考えられる.つまり,トライアル購買とリピート購買を繰り返すことで当該製品に対して好意的なファンとなった消費者が増えていると推測できる.そのような消費者がさらにコアなファンとなるような,例えば,ファンとなった消費者からパンジェンシーをより美味しく味わうために行っている工夫を投稿してもらうなどブランドコミュニティの形成を促すようなFacebook などの他のソーシャルメディアなどとも連動させたコミュニケーション戦略が企業にとってはこの時期において大切といえよう.
以上から,Twitter 上の書き込みの質は,製品時系列とともに変化し,その変化の仕方は日本広告主協会Web 広告研究会(2005) において示されているブログ記事の質の変化と同様の傾向を示していると考えられる.
5. まとめ
分析結果から,Twitter における書き込みのタイプは,使用経験・感想型,専門的・説明型,ニュース型,アフィリエイト型,その他に分類することができることが分かった.この結果は,日本広告主協会Web 広告研究会(2005) において示されたブログの記事内容の4 分類であるニュース,広告,体験・感動,日記,中山他(2008) でのブログの記事内容の分類結果である日記型,アフィリエイト型,使用経験・感想型,専門的・説明型,ニュース型と類似した結果となっている.以上からTwitter においてもブログと同様の書き込みが行われていると推察される.そして,各期間での製品時系列に沿ったTwitter 上の書き込みの質の変化は,日本広告主協会Web 広告研究会(2005) において示されているブログ記事の質の変化と同様の傾向であることが示された.ただし,Twitter とブログという媒体の違いにより,消費者の利用形態は異なる点もあると考えられるため,その利用形態の相違が書き込み内容やその内容の製品時系列にそった質的な変化に影響することが予想される.したがって,Twitter とブログという媒体の違いによる書き込み内容やその内容の製品時系列にそった質的な変化の違いについての比較・検討は今後の課題としたい.
本研究における成果から,GRP と連動しながら,製品時系列にそって書き込み件数やその内容の質が変化していることも確認された.つまり,広告とツイートの間に関連性があり,TV 広告は自社の製品をソーシャルメディア上に取り上げてもらうためのトリガーとなりえると考えられる.よって,TV 広告とTwitter の書き込み件数やその書き込み内容の質とどのように連動しているのか,広告の効果をTwitter のデータからどう評価するのかということも重要な課題といえ,今後より詳細に検証する必要があると考える13.
また,本研究では,製品時系列に沿った話題の質の変化をとらえることのできる効果的な単語を選択するには,各週で登場する単語の違いを反映させた上で単語を絞り込むことが重要であると考え補完類似度により分析に利用する単語の絞り込みを行った.その結果,補完類似度により抽出されている単語群は頻度情報を用いたものよりも多様な単語が抽出され,分析で用いるデータには各週で取り上げられる単語の違いを反映させることができた.しかし,今後の課題として,分析に利用する単語の絞り込みについてはより詳細な比較・検討も必要であると考えられるため,その点については今後の課題としたい.そして,各期間の分析結果の関連度上位10 以内の単語の表中には,同じような意味合いの単語が含まれていたり,本研究では,Twitter での書き込みの1 つの特徴である顔文字や記号も分析データに含めているため記号が含まれていたりしているが,トピック解釈の際にはうまく活用できていないなどコーディングにおける課題が存在する.今後より正確な分析を実現するためにはコーディングの段階での精緻化の必要があると考える.また,NMF の分析結果により得られている情報の図示化や指標化が可能となればより汎用性が高まると考えられ,これらの点についても今後の課題といえる.
最後に,本論文で活用したテキストマイニングの手法により明らかとなる示唆はきめ細かな顧客の声を抽出している反面,分析結果にどれほどの意味があるのかということが問題となる.Twitter 上に現れる各種商品・広告に関するつぶやきは,実際に消費者が発信している膨大な口コミや評価の一部であり,本論文から得られた示唆をより普遍化・一般化するためには,調査票を活用した量的調査を実施するなど,より詳細な分析が必要であると考える.この点についても今後の課題としたい.
脚 注
5 Twitter のID はすべてXXX に連番を加えたものにマスクして掲載している.以降も同様.
6 表
1 の書き込みの文章を形態素解析した上で後述する非負行列因子分解(Non-Negative Matrix Factorization,NMF;
Lee & Seung, 2000) により分析すると,書き込みは2 件ずつ5 つのグループに分類できる.
10 Text Mining Studio3.1 を分析に用い,前処理のオプションにある「分かち書き」を選択して形態素解析を実行した.「分かち書き」を選択すると形態素解析のみが実行される.
11 分析にはText Mining Studio3.1 の「特徴語抽出」を用いて分析を行った.
12 各トピックの特徴を解釈する際には,各トピックと単語の関連度に基づいて行った上で,原文にもどりその解釈が正しいかどうかを確認している.各トピックの特徴の詳細や各トピックに所属する書き込みの原文の例については付録を参照のこと.
13 なお,広告の効果をTwitter のデータからどう評価するのかということの研究についてはその成果の一部を
鶴見・増田・中山(2013) で報告しているので,その研究内容の詳細についてそちらを参照のこと.
付録
各トピックの特徴の詳細について,トピックの期間を通じた共通点と各期間での相違点という観点に基づいて説明する.
使用経験・感想型の味についてのトピックは期間1 のトピック1,期間2 のトピック2 と6,期間3 のトピック2 に登場している(図2).期間1 でのトピック1 の特徴については「4.1. NMF によるトピックの分類結果」で示した通りであるが,構成比は6.7%と小さく発売週までは味自体についての書き込みはまだ少ないと考えられる(図2).期間2 のトピック2 と6 もパンジェンシーの味についてのトピックと考えられ,味について肯定的な書き込み(うまい,美味しい)が行われている.期間2 のトピック2 の特徴としてはキリン午後の紅茶の略称である午後ティーが書き込みの際に用いられている点が挙げられる.トピック2 では「ティー」という単語(表4 の関連度上位の書き込みにみられるように午後ティーという単語が午後とティーという単語に分割されたもの)の関連度が高く,「ティー」という表現を軸として,パンジェンシーの味(うまい)についての感想が書き込まれているようなトピックであると考えられる.期間2 のトピック2 における関連度上位3 件の書き込みは以下の通りである.

トピック6 では,「美味しい」という単語の関連度が最も高く,「美味しい」という味についての感想についてのトピックであると考えられる(表4).このトピックは期間1 でのトピック1 と同様の傾向を示していると考えられ,実際の書き込みも同じような書き込みがされている.ただし,トピック6 では「分かる.ない(分からない)」という単語の関連度も比較的高い値(表4)となっており,トピック6 は美味しいという味についての感想を軸に,パンジェンシーという感覚についての書き込みも行われているようなトピックといえる.なお,構成比はトピック2 が17.7%,トピック6 は4.4% とトピック2 の方が構成比は大きく(図2),期間2 における味についての書き込みはキリン午後の紅茶の略称である午後ティーという単語をハブとしたトピック2 のような書き込みの方が多く行われていると考えられる.期間3 のトピック2 も「美味しい」という単語の関連度が最も高く(表5),味に対して肯定的な書き込みがされており,パンジェンシーの味を美味しいと感じているようなファン的な書き込みがされているトピックと考えられる.このトピックは期間1 や期間2 の味についてのトピックと同様に飲んだ上での味に対するトピックの傾向を示していると考えられ,実際の書き込みも同じような書き込みがされている.美味しいという味についての感想を軸に,飲んだ上での味に対する肯定的な書き込みが行われている点は期間2 のトピック6 と同じであるが,構成は11.2%とトピック6 よりもサイズは大きくなっている.以上のように,使用経験・感想型の味についてのトピックは,サイズは異なるものの全3 期間において登場し,全期間共通のトピックであると考えられる.また,期間2 においては書き込みの特徴の異なる2 つの使用経験・感想型の味についてのトピックが登場し,そのサイズも2 つのトピックを合わせると他の期間よりも大きい.発売からの時間の経過とともに製品についての認知率が向上することでトライアル購買が発生し,その結果,味についての書き込みが期間2 では多く行われるようになったと推察される.
使用経験・感想型の購入意向についてのトピックである期間1 のトピック2 では以下の関連度上位3 件の書き込みにみられるように,キリン午後の紅茶の略称である午後ティーという表現が書き込みの際に用いられているため「ティー」という単語の関連度が高く,また,「買う」「広告」「気」「うまい」「飲みたい(飲む. したい)」といった単語の関連度も比較的高い(表3).午後ティーという表現を軸に,新製品が発売され,CM などの広告に触れることによって,その製品に対する購入意向が高まり,それと関連した書き込みが行われていると考えられる.期間1 のトピック2 は構成比が31.9% と最もサイズの大きいトピックであり(図2),使用経験・感想型の購入意向についてのトピックは新製品が発売された直後の特徴的なトピックと考えられよう.期間1 のトピック2 における関連度上位3 件の書き込みは以下の通りである.
使用経験・感想型のトピックにおいて当該製品の広告と関連したトピックには期間1 のトピック3 や期間2 のトピック3 と5 が該当する.ただし,これらのトピックにおいてはトピックを特徴づけるハブとなる単語が存在し,その単語が当該製品の広告と関連付けながら書き込まれている.期間1 のトピック3 は,「飲む」という単語の関連度が最も高く,CM に出演しているタレントの名前である「蒼井優」という単語の関連度が比較的高くなっている(表3).期間1 のトピック3 では以下の関連度上位3 件の書き込みにみられるように,製品を購入して試飲した感想を,視聴した当該製品のTV 広告と関連付けながら書き込みが行われていると考えられる.構成比は13.5%とそれほど大きくはないが(図2),発売直前にCM が開始されたことにより,そのCM と関連づけながら試飲した感想についての書き込みが行われていると考えられる.
また,トピックと単語の関連度から,期間2 のトピック3 は製品購入について,トピック5 は「紅茶」をキーワードとした製品全般についてのトピックと考えられる.ただし,期間1 のトピック3 と同様に当該製品の広告と関連付けながら書き込みが行われている.トピック3 は「買う」という単語の関連度が高く,また,「CM」や「蒼井優」という広告に関連した単語の関連度も比較的高くなっている(表4).製品購買についての書き込みが広告と関連づけられながら製品を購買しての感想が書き込まれていると類推できる.トピック3 における関連度上位3 件の書き込みは以下の通りである.
一方で,トピック5 では,「紅茶」という単語の関連度が高くなっており,また,「CM」「チンパンジー」という単語の関連度も比較的高い(表4).以下のトピック5 における関連度上位3 件の書き込みにあるように,キリン午後の紅茶パンジェンシーの特徴である紅茶の評価用語「パンジェンシー」の意味についての説明や製品の味,CM についてなど製品全般についての書き込みが行われていると考えられる.発売から期間が経過することにより,パンジェンシーの意味についてだけではなく,トライアル購買をしたことやCM を視聴したことで書き込み内容に多様性が増加していると考えられる(期間1 での専門的・説明型のトピックに近いトピックとも考えられる).
当該製品の広告と関連付けられたトピックである期間1 のトピック3 の構成比はそれほど大きくはなかったが,同様の傾向を示す期間2 のトピック3 の構成比は最も大きい30.2% ,トピック5 の構成比は次いで大きい20.8%となっている(図2).期間2 では当該製品の広告と関連付けながら製品購入や製品全般についての書き込みが多く行われていると考えられる.期間3 においては広告と関連した単語はトピック5 の関連度上位10 番目にCM という単語が存在するのみとなっており(表5),広告やCM と関連付けた書き込みは急激に減少していると考えられる.製品の広告と関連付けられた書き込みの増加減少傾向はGRP の推移とも関連がみられる.GRP は発売週が最も高く,翌週まではある程度高い値を示しているがそれ以降は急激に低下している.期間1 ではGRP と連動した形で,製品を購入した上での飲んでみた感想と視聴したCM とを関連付けながら書き込みが行われるようなトピック(トピック3)が存在していたが,そのサイズはあまり大きくなかった.期間2 においては発売週と翌週に多くのCM を投下したことにより,認知率の向上とトライアル購買が発生したことにより,製品の購買や紅茶をキーワードとした書き込みが当該製品のCM と関連付けながら行われ,その割合も増加していると考えられる.そして,期間3 ではGRP の低下とともに広告と関連した書き込みは減少したと推察される.
使用経験・感想型の感覚についてのトピックは期間2 のトピック1 と4,期間3 のトピック3で登場している.期間2 のトピック1 では,「http」という単語の関連度が最も高く(表4),Webページへのリンク(画像)を張りながらパンジェンシーという感覚について書き込みが行われているのが特徴である(表4).また期間2 のトピック4 では「飲む」という単語の関連度が最も高く,「分からない(分かる. ない)」の関連度が比較的高い値となっている(表4).よって,トピック4 は飲んだ上で,パンジェンシーが感じられないというような書き込みがまとめられていると考えられる.トピック1 の構成比は12.0%,トピック4 の構成比は14.9% と両者のサイズにはあまり違いはない(図2).トピック1 における関連度上位3 件の書き込みは以下の通りである.
また,トピック4 における関連度上位3 件の書き込みは以下の通りである.
期間3 のトピック3 では,「飲む」という単語の関連度が最も高く,次いで,「分からない(分かる. ない)」「7 秒後」などの単語の関連度が高くなっている(表5).期間2 に引き続き七秒後に感じるという紅茶の評価用語の「パンジェンシー」という感覚が飲んでみて分かるかどうかというような書き込みが行われていると考えら,実際の書き込み文章を確認すると期間2 のトピック2 や4 で見られたようなパンジェンシーという感覚が飲んでみて分かるかどうかというような書き込みとなっている.ただし,構成比は12.8%とあまり大きくはない(図2).
使用経験・感想型の感覚についてのトピックは,期間2 以降に登場し,期間2 においては書き込みの特徴の異なる2 つの使用経験・感想型の感覚についてのトピックが存在している.2 つのトピックを合わせると期間2 において2 番目に大きい構成比となる.発売からの時間の経過とともに製品についての認知率が向上し,トライアル購買が発生することで製品の特徴である紅茶の評価用語の「パンジェンシー」という感覚を感じるかどうかという書き込みが多く行われていると考えられる.これは,使用経験・感想型の味の書き込みが期間2 において増加しているのと同じような傾向といえる.
使用経験・感想型の製品全般についてのトピックは,期間2 と3 のトピック5 で登場している.製品の広告と関連したトピックの説明の際に述べたように,期間2 のトピック5 では,発売から期間が経過することにより,紅茶の評価用語の「パンジェンシー」の意味についてだけではなく,トライアル購買をしたことやCM を視聴したことにより書き込み内容に多様性が増していると考えられる.一方,期間3 のトピック5 では,「紅茶」という単語の関連度が最も高く,次いで,「うまい」「買う」「キリン」「渋み」「味わい」「良い」「好き」などの関連度が高い(表5).以下の関連度上位3 件の書き込みにあるように,トピック5 は紅茶をキーワードとして,紅茶の評価用語である「パンジェンシー」についての書き込み(渋み,味わい)や肯定的書き込み(うまい,良い,好き),購買についての書き込み(買う)など製品全般についての書き込みがまとめられているトピックと
いえる.
このように,期間2 と3 において製品全般についての書き込みが行われているトピックが登場するようになっている.期間が経過するにつれて,CM などについての書き込みは減少し,味そのものやその特徴(紅茶の評価用語であるパンジェンシー)についての書き込みなど製品自体の書き込みが行われるように製品時系列にそって書き込みの質が変化しているといえよう.
使用経験・感想型のトピックにおいてパンジェンシーについてのファン的なトピックといえる期間3 のトピック4 では「ティー」という単語(関連度上位の書き込みにみられるように午後ティーという単語が午後とティーという単語に分割されたもの)の関連度が高く,次いで「買う」「うまい」「好き」「良い」などの好意的な単語の関連度が高くなっている(表5).以下の関連度上位3 件の書き込みのように「ティー」という表現を軸として,好意的なファンのような書き込みが行われていると考えられる.期間3 において構成比が42.2%と最も大きい(図2).なお,以下の関連度上位3 番目の書き込みは今回の分析データは共起情報を活用していることによる誤分類と考えられる.
その他にも期間3 のトピック2 では美味しいという単語の関連度が最も高く,トピック5 においても「うまい」という単語の関連度が高くなっている(表5).このように,製品時系列が変化するにつれて,午後の紅茶パンジェンシーの味について好意的な印象が書き込まれているトピックが増えている.製品へのファン的な要素を示しているトピックであるトピック4 の構成比が42.2%と最も大きいことからも(図2),期間3 においては好意的なファンのような書き込みが多く行われていると推察できる.
専門的・説明型のトピックには期間1 においてパンジェンシーの意味について説明しているトピック5 がある.キリンの公式サイト(http://pungency.jp/about/index.html) では,パンジェンシーについて『紅茶を褒めるときに使う最上級の表現であり,とても簡単にいうと「心地よい渋み」をあらわす言葉である.紅茶にとって「渋み」とは,きわめて大切な香味であり,「パンジェンシーがある紅茶」とは,口に含むとまず,さわやかな香りと繊細でエレガントな渋みが広がり,心地のよい余韻がしばらく続く』と説明されている.期間1 のトピック5 では「紅茶」という単語の関連度が最も高く,次いで「渋み」の関連度が高くなっている(表3).パンジェンシーとは端的にいうと紅茶の「心地よい渋み」をあらわす言葉であることから,トピック5 では製品の特徴である紅茶の評価用語「パンジェンシー」の意味についての書き込みがまとめられていると考えられる.期間1 のトピック5 は構成比が29.4% と期間1 で2 番目にサイズが大きい(図2).つまり,新製品発売とCM 開始により新製品についての認知が高まり,その製品の特徴である紅茶の評価用語「パンジェンシー」の意味についての興味・関心が高まったことで,一般的とはいえないその紅茶の評価用語の意味を説明する書き込みが多数行われたと考えられる.ただし,期間2 以降では専門的・説明型のトピックは登場していない.それは紅茶の評価用語「パンジェンシー」についての認知が高まるとともに,その用語の意味を説明する必要性が低下し,その意味を説明するような書き込みも減少しているためといえる.なお,トピック5 における関連度上位3 件の書き込みは以下の通りである.

ニュース型のトピックには,製品が新発売されたことを報告(ニュースリリースをリピート)している期間1 のトピック6 が該当する.トピック6 では,「茶葉二倍」という単語の関連度が最も高く,次いで「ミルクティー」「入れる」「手」「生まれ変わる」「新発売」などの関連度が高くなっている(表3).これらの単語は午後の紅茶パンジェンシープロジェクトで用いられたキャッチコピー「午後の紅茶パンジェンシープロジェクト第2 弾!あの茶葉2 倍ミルクティーが,パンジェンシーを手に入れて,生まれ変わる」に登場する単語であり,これらに関連した書き込みが行われていたと考えられる14.したがって,期間1 のトピック6 の構成比は8.4% でさほど大きくはないが(図2),新製品が発売され,CM が開始されたことにより,その製品が発売されたことを報告するニュース型の書き込みが行われていると考えられる.トピック6 における関連度上位3 件の書き込みは以下の通りである.
以上のように専門的・説明型やニュース型のトピックが期間1 のみに登場しているのは,新製品の発売やCM の開始によって製品に対する認知が高まったことで,これらのトピックと関連した書き込みが行われ,ある程度の製品の認知の広がりとともに書き込みが行われなくなったためと考えられる.逆に,期間3 においては消費者の認知の拡大にともなってアフィリエイ型のトピックが登場している.期間3 のトピック6 では「ミルクティー」の関連度が高く,次いで「茶葉二倍」「チェック」「460ml.24 本」「Amazon」といった単語の関連度が高くなっている(表5).トピック6 は特定の時間に自動ツイートするbot を用いたようなアフィリエイト型のトピックと考えられる.アフィリエイト型のトピックが期間3 において登場するようになったのは,発売から時間が経過することにより,消費者の製品認知が拡大し,それを利用したアフィリエイトなどの書き込みが行われるようになったためと類推される.ただし,そのサイズは6.7%と小さい.トピック6における関連度上位3 件の書き込みは以下の通りである.
以上のように期間ごとの各トピックの特徴を整理すると,発売からの期間の経過にともなって対象製品の製品時系列が変化することで,Twitter での書き込みの質も変化していることが分かる.
また,期間1 のトピック4 と期間3 のトピック1 では,キリン午後の紅茶パンジェンシー自体とは関係のない適度な心地よい渋みを表現する紅茶の評価用語「パンジェンシー」と関連したトピックが抽出されている.これらのトピックでは「http」という単語の関連度が最も高く,情報提供サイトである「All About」に関連した単語の関連度も高くなっている(表3,5).紅茶の評価用語「パンジェンシー」と関連した書き込み(紅茶の香りやホテルでのアフタヌーンティの紹介記事など)がリリースされたことにより,このページを紹介するためにリンクを張った書き込みが行われていると考えられる.期間1 でのトピック4 と関連度の高い関連度上位3 件の書き込みは以下のようなものになっており,紅茶の評価用語「パンジェンシー」と関連した記事についての書き込みとなっている.なお,期間3 のトピック1 の書き込みも同じようなものとなっている.
期間1 のトピック4 構成比は10.1%,期間3 のトピック1 の構成比は12.1%とそのサイズはあまり大きくはないが(図2),テキスト情報を抽出する際のキーワード設定についても十分留意する必要があるといえよう.設定したキーワードによりどのようなテキスト情報が抽出されうるのかという想定が正しくない場合には,意図しないデータを分析してしまう危険性が存在するので注意が必要である.
謝 辞
本稿をまとめるにあたっては有益で建設的なご助言を賜りました査読者の方に感謝申し上げます.また,本研究は公益財団法人吉田秀雄記念事業財団の平成23 年度第45 次研究助成,科研費若手研究(B)(課題番号:25730019)の助成を受けて実施いたしました.ここに記して感謝の意を表します.そして,テレビ広告出稿データをご提供いただきました株式会社ビデオリサーチの関係の皆様方に深謝申し上げます.
References
- Deerwester, S., Dumais, S., Furnas, G. W., Landauer, T. K., & Harshman, R. (1990). Indexing by Latent Semantic Analysis. Journal of the American Society for Information Science, 41 (6), 391407.
- Ding, C., Li, T., & Peng, W. (2006). Nonnegative Matrix Factorization and Probabilistic Latent Semantic Indexing: Equivalence, Chi-Square Statistic, and a Hybrid Method. Proceedings of the 21st National Conference on Artificial Intelligence and the 18th Innovative Applications of Artificial Intelligence Conference (AAAI '06), 342-347.
- 服部兼敏 (2010). テキストマイニングで広がる看護の世界.ナカニシヤ出版.
- Hofmann, T. (1999a). Probabilistic Latent Semantic Analysis. Proceedings of the 15th Conference on Uncertainty in Artificial Intelligence, 289-296.
- Hofmann, T. (1999b). Probabilistic Latent Semantic Indexing. Proceedings of the 22nd International Conference on Research and Development in Information Retrieval, 50-57.
- Lee, D.D., & Seung, H.S. (2000). Algorithms for Non-Negative Matrix Factorization. In K. T. Leen, T. G. Dietterich, & V. Tresp (Eds.), Advances in Neural Information Processing Systems (vol. 13, 556-562). MIT Press.
- 中山厚穂・竹内光悦・酒折文武・鶴見裕之・横山暁・増田純也 (2008). CGMサイトにおけるバズ・マーケティングの効果測定とその検証.吉田秀雄記念事業財団助成研究論文,吉田秀雄記念事業財団.
- 日本広告主協会Web広告研究会 (2005).ブログ書き込み調査.https://www.wab.ne.jp/wabsites/uploaders/663/download.
- 小川 進 (2007). 複線化する製品開発.國民經濟雜誌 195 (4), 53-68.
- Rosen, E. (2000). The Anatomy of Buzz. Currency: NY. (濱岡豊(訳)クチコミはこうしてつくられる— おもしろさが伝わるバズ・マーケティング.日本経済新聞社.).
- Sawaki, M., & Hagita, N. (1996). Recognition of Degraded Machine-Printed Characters Using a Complementary Similarity Measure and Error-Correction Learning. IEICE Transactions on Information and Systems, E79-D (5), 491-497.
- 新納浩幸 (2007). Rで学ぶクラスタ解析.オーム社.
- 田村直樹 (2006). インターネットマーケティングの基礎と現状.オペレーションズ・リサーチ,51 (12), 723-728.
- 柘植覚・獅々堀正幹・北研二 (2001). Non-negative Matrix Factorization を用いた情報検索,情報処理学会研究報告,142 (1), 1-6.
- 鶴見裕之・増田純也・中山厚穂 (2013). 商品に関するTwitter上のコミュニケーションと販売実績の関連性分析.オペレーションズ・リサーチ,58 (8), 436-441.
- 鶴見裕之・中山厚穂・増田純也 (2013). 商品の販売実績に与える消費者生成型メディア上におけるコミュニケーションの影響に関する研究.吉田秀雄記念事業財団助成研究論文, 吉田秀雄記念事業財団.













