Abstract
Due to the complicated characteristics of modeling data in industrial blast furnaces (e.g., nonlinearity, non-Gaussian, and uneven distribution), the development of accurate data-driven models for the silicon content prediction is not easy. Instead of using a fixed model, an ensemble non-Gaussian local regression (ENLR) method is developed using a simple just-in-time-learning way. The independent component analysis is utilized to handle the non-Gaussian information in the selected similar data. Then, a local probabilistic prediction model is built using the Gaussian process regression. Moreover, without cumbersome efforts for model selection, the probabilistic information is adopted as an efficient criterion for the final prediction. Consequently, more accurate prediction performance of ENLR can be obtained. The advantages of the proposed method is validated on the online silicon content prediction, compared with other just-in-time-learning models.
1. Introduction
The main purpose of industrial blast furnaces is to chemically reduce and physically convert iron oxides into liquid iron called the hot metal. With the increasing need for iron and steel, modeling and controlling the silicon content to increase productivity and reduce potential cost have been widely researched. As an important index of the thermal state, the silicon content in hot metal must be controlled in an appropriate level. However, the silicon content is difficult to be measured online. Additionally, because of complex chemical reactions and transfer phenomena, an accurate first-principles model is still not available for industrial applications.1,2,3,4,5,6)
Alternatively, using the easy-to-measure variables, data-driven empirical models (also called soft sensors or inferential sensors) have been applied to online predict the silicon content.7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29) Without deep process knowledge, data-driven soft sensors for the silicon content prediction can be established quickly. Among them, neural networks (NN) and support vector regression (SVR) are commonly utilized in chemical processes due to their good nonlinear fitting performance.30) However, the structure/parameter selection of NN and SVR is not easy. Additionally, both of them are deterministic methods. Recently, Gaussian process regression (GPR) have attracted more attention in chemical processes.31,32,33) Compared with NN and SVR, GPR can be trained much easier. Additionally, the probabilistic information can be obtained along with its predictions.31,32,33) This property can be utilized as an evaluation criterion for prediction when the actual value is not available. To our best knowledge, there is still not a probabilistic soft sensor applied to blast furnaces. To this end, this work aims to develop a GPR-based probabilistic soft sensor for the silicon content prediction.
Many soft sensor models are assumed that secondary variables are known by process knowledge. However, without process or expert knowledge, it is difficult to choose suitable secondary variables for industrial processes. Additionally, secondary variables should be preprocessing suitably mainly because they often show co-linearity from the partial redundancy in the sensor arrangement and they are combined with process noise.30) Actually, industrial processes are usually driven by a few essential variables which may not be measured. And the measured process variables may be combinations of these independent latent variables. The principal component analysis (PCA) approach is adopted to select the most suitable secondary variables as the inputs of a soft sensor.34) However, PCA can only extract the Gaussian information. Instead of transforming uncorrelated components, independent component analysis (ICA) attempts to achieve statistically independent components in the transformed vectors.35,36) ICA, originally developed for blind source separation, can handle the non-Gaussian information in process data.35,36) Recently, ICA has been applied to non-Gaussian chemical process monitoring and shown better performance than PCA.37)
The issue of efficient selection and analysis of secondary variables was less developed for industrial ironmaking processes. Additionally, in practice, it is more suitable to use multiple local models than only using a fixed one. For these two aims, an ensemble non-Gaussian local regression (ENLR) method is developed using a just-in-time-learning (JITL) way. For online prediction of each query sample, the ICA-based feature extraction method is adopted to suitably select secondary variables in the similar set. Several candidate GPR-based local prediction models are built. Moreover, without a cumbersome parameter selection process, the probabilistic information is adopted as an evaluation criterion for final prediction. These properties make the ENLR method suitable for a relatively long-term utilization.
The remainder of this work is briefly organized. The GPR soft sensing method is described in Section 2. In Section 3, with ICA-based feature extraction, detailed implements of the ENLR online modeling and prediction method are proposed. In Section 4, ENLR is applied to online silicon content prediction and compared with other JITL methods. Finally, a conclusion is drawn in Section 5.
2. GPR-based Soft Sensor Model
The GPR-based soft sensor modeling method is to approximate a data set {X,y}, where
{
X∈
R
N×D
}=
{
x
i
}
i=1
N
and
{
y∈
R
N×1
}=
{
y
i
}
i=1
N
are the D-dimensional input and the single-output datasets with N samples, respectively. GPR can predict the output variable for an input data through Bayesian inference. For a single output variable of y = (y1,...,yN)T, GPR is the regression function with a Gaussian prior distribution and zero mean, or in a discrete form31)
|
y=
(
y
1
,…,
y
N
)
T
~G(
0,C
)
| (1) |
where
C is the
N×
N covariance matrix with the
ij-th element
Cij =
C(
xi,
xj) defined by the covariance function below
31)
|
C(
x
i
,
x
j
)=
a
0
+
a
1
∑
d=1
D
x
id
x
jd
+
v
0
exp(
-
∑
d=1
D
w
d
(
x
id
-
x
jd
)
2
)
+
δ
ij
b
| (2) |
where
xid is the
dth component of the vector
xi.
δij = 1 if
i =
j; otherwise, it is equal to zero.
θ = [
a0,
a1,
v0,
w1,···,
wD,
b]
T are the model parameters. As shown in
Eq. (2), GPR can model both of linear and nonlinear processes.
31)
Using a Bayesian method to train the GPR model, the parameters θ can be estimated. Detailed algorithmic implementations can be found in the literature.31) Finally, for a test sample xt, the predicted output of yt is also Gaussian with mean (
y
ˆ
t
) and variance (
σ
y
ˆ
t
2
), calculated below:31)
|
σ
y
ˆ
t
2
=
k
t
-
k
t
T
C
-1
k
t
| (4) |
where
kt = [
C(
xt,
x1),
C(
xt,
x2),···,
C(
xt,
xN)]
T is the covariance vector between the new input and the training data, and
kt =
C(
xt,
xt) is the covariance of the new input. The vector
k
t
T
C
-1
is a smoothing term which weights the training outputs to provide a prediction (
Eq. (3)) for the new input data
xt. Additionally,
Eq. (4) provides a confidence level on the prediction. This appealing property makes it different from traditional NN and SVR soft sensor models.
3. ENLR-based Online Prediction Method
3.1. Feature Extraction for JITL-based Local Models
There are two main advantages by using suitable local models than only a global/fixed model. First, it is not easy to construct a global/fixed model with suitable structure for complicated processes. Second, for some processes with complex characteristics and changing dynamics, a fixed model may not be reliable for the long-term utilization. Alternatively, JITL-based local models for nonlinear process modeling are more flexible.33,38,39,40,41,42)
Take the JITL-based GPR (simply denoted as JGPR) modeling method for example. For a query sample xq, there are three steps to construct a JGPR model.33) First, choose a similar set Sq from the historical database S using some defined similarity criteria. Second, build a JGPR model fJGPR (xq) using the similar dataset Sq. Third, online predict the output
y
ˆ
q
for xq and then discard the current JGPR model fJGPR (xq).
However, the input data for construction of a JGPR model may not be Gaussian distribution. The ICA method is adopted to handle this problem. ICA, originally for solving blind source separation problem, is a statistical and computational method for revealing hidden factors that underlie sets of random variables, measurements or signals.35,36) Assume that the kth sample with D measured variables xk = [xk1,···,xkD]T can be expressed as linear combinations of d(≤D) unknown independent components [s1,···,sd]T. Then, for the whitened data matrix Xsim = [x1,...,xn]∈RD×n selected from the historical database using the JITL way, it can be represented as35,36)
where
n is the number of measured samples;
A∈
RD×d is the mixing matrix;
I∈
Rd×n is the independent component matrix; and
E∈
RD×n is the residual matrix. Basically, ICA is to estimate the original component
I and the mixing matrix
A from
Xsim. Consequently, the objective of ICA is to calculate a separating matrix
W so that the components of the reconstructed data matrix
I
ˆ
becomes as independent of each other as possible, given as
35,36)
An efficient method, known as FastICA,35,36) is adopted to obtain all the independent components. Hyvarinen and Oja validated that the FastICA algorithm is computationally efficient compared to other competitive ICA algorithms.36) Consequently, applying ICA to the whitened data Xsim, the reconstructed data matrix
I
ˆ
with some new extracted variables can be obtained.
3.2. Ensemble Strategy for Local Probabilistic Models
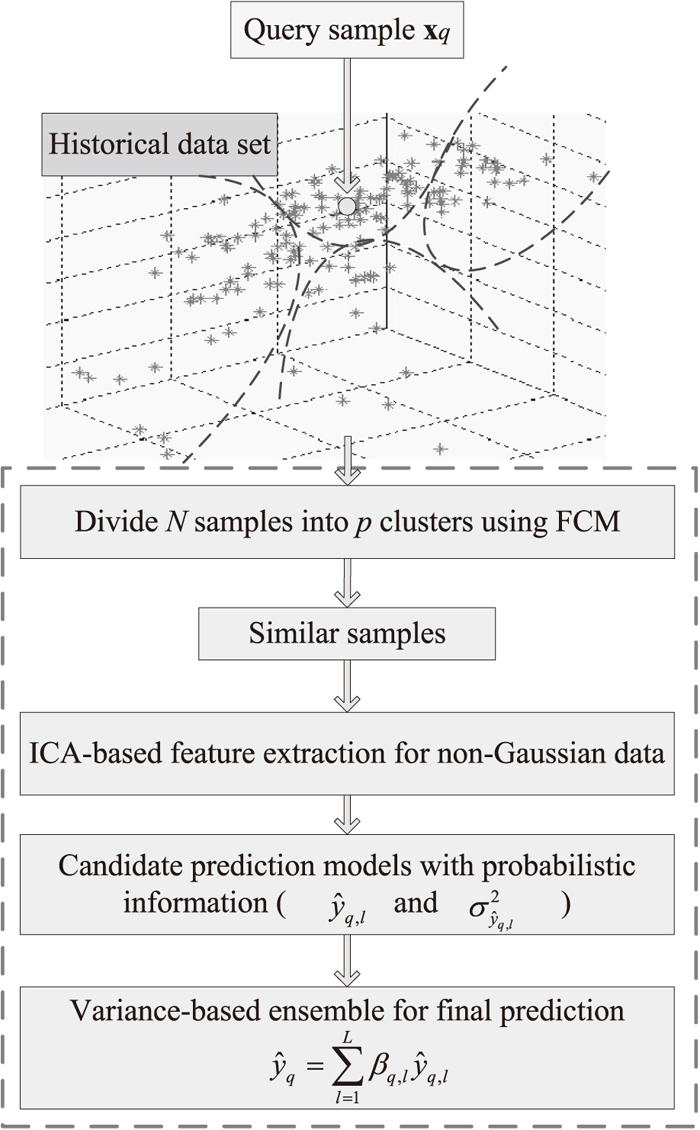
Different from traditional JITL-based modeling methods in searching similar samples, a simple clustering approach is integrated into the proposed online modeling method. The fuzzy c-means (FCM) clustering algorithm divides N samples into p clusters such that samples within a given cluster have a higher degree of similarity, whereas samples belonging to different clusters are dissimilar.43) It has been widely applied to many clustering problems and has shown superiority to the classic k-means method. For a query sample xq, it is probably that the samples in the same cluster are its similar samples. Consequently, the relevant data can be simply obtained using the FCM clustering method.
There are two user-defined parameters (p,d) in determining an ENLR model. The first one is the number of clusters p (2 ≤ p ≤ 6 for this application case). The second one is the number of ICA-based extracted variables d (2 ≤ d ≤ D, D is the number of input variables and here D = 7). Consequently, there are altogether 30 pairs of candidate parameters (pl,dl),l = 1,···,30. The traditionally cross-validation method is time-consuming. Additionally, only using a model may be overfitting for some regions. Alternatively, ensemble learning methods are attractive in the machine learning area. For several regression applications, the ensemble models have shown better performance than a single regression one.44,45,46,47) Here, using the probabilistic information, a simple ensemble strategy is formulated for the final prediction of ENLR.
For online prediction of a new sample xq, with different modeling samples and parameters (pl,dl),l = 1,···,L, each local model can show its individual prediction performance. Suppose there are altogether L candidate models, each with a prediction
y
ˆ
q,l
and its predicted variance
σ
y
ˆ
q,l
2
. The actual value of yq is unknown before it is analyzed offline. Interestingly, evaluation of the uncertainty of candidate models is straightforward. This is because a smaller predicted variance indicates a more reliable prediction, and vice versa. That is to say, if a model has a larger predicted variance, the weight on this model should be relatively smaller. In such a situation, this model has less positive effects on the final prediction. Based on the analysis, the related weights βq,l for these candidate models can be formulated as:
|
β
q,l
=
(
σ
y
ˆ
q,l
2
∑
l=1
L
1
σ
y
ˆ
q,l
2
)
-1
| (7) |
It can be indicated that 0<βq,l<1,l = 1,···,L. Finally, the final prediction using the ENLR model can be obtained.
|
y
ˆ
q
=
∑
l=1
L
β
q,l
y
ˆ
q,l
| (8) |
Based on the aforementioned modeling strategies, for a query sample xq, the step-by-step procedures of the proposed ENLR-based online modeling method are summarized as follows.
ENLR Step 1: Collect the process input and output data samples as the historical database, i.e. S = {X,Y}.
ENLR Step 2: For an input measurement in the test set, i.e. xq, first add it into X. Then, the FCM clustering method is adopted to partition {X,xq} into p clusters. Find out the samples with the same cluster with xq. They can be formed as the relevant dataset Ssim = {Xsim,Ysim}. Apply ICA to the whitened data Xsim to obtain the reconstructed data matrix
I
ˆ
with d new extracted variables.
ENLR Step 3: For a set of candidate parameters (pl,dl),l = 1,···,L, construct several candidate JGPR-based local models. The related weights βq,l for these candidate models can be obtained in Eq. (7). Finally, using an ensemble learning method, make an online prediction
y
ˆ
q
using Eq. (8).
ENLR Step 4: Go to Step 2 and Step 3 and implement the same procedures for online prediction of the next new input.
The main modeling and prediction implementations of ENLR are summarized in Fig. 1. Compared with traditional JITL-based soft sensors, there are two main advantages of ENLR. One is that the variables extraction is integrated into the online prediction framework. The new extracted variables are independent with each other by removing the correlation among the process variables. The other is that the ensemble strategy makes the ENLR method more reliable and efficient when it is implemented in a relative long-term utilization for the silicon content prediction.
4. Silicon Content Prediction: Results and Discussion
The proposed ENLR probabilistic modeling method is applied to online silicon content prediction in an industrial blast furnace in China. There are seven input variables (i.e., D = 7) related to the silicon content, including the blast temperature, the blast volume, the gas permeability, the top pressure, the top temperature, the ore/coke ratio, and the pulverized coal injection.19,20,22) The silicon content is analyzed offline and infrequently. Consequently, the soft sensor is constructed using the online measured variables. After simple removing obvious outliers using the 3-sigma criterion, a set of 340 data samples is investigated. About two thirds of the data (about 230) are treated as the historical set. And the rest data (about 110) are for testing. It should be noted that the noisy data still contain some inconspicuous outliers. As illustrated in Fig. 2, several input variables are nonlinear correlated. And the data in different operating areas are distributed irregularly.

To evaluate the prediction performance, three indices of the root-mean-square error (RMSE), relative RMSE (simply noted as RE), and the hit rate (HR)19,20,21,22,23,24,25,26) are utilized and defined below, respectively.
|
RMSE=
∑
q=1
N
tst
(
y
q
-
y
ˆ
q
N
tst
)
2
| (9) |
|
RE=
∑
q=1
N
tst
(
y
q
-
y
ˆ
q
y
q
)
2
/
N
tst
| (10) |
|
{
HR=
∑
q=1
N
tst
H
q
N
tst
×100%
where
H
q
={
1, |
y
ˆ
q
-
y
q
|<0.1
0, else
| (11) |
where
yq and
y
ˆ
q
are the actual value and the predicted value, respectively. And
Ntst is the number of test data.
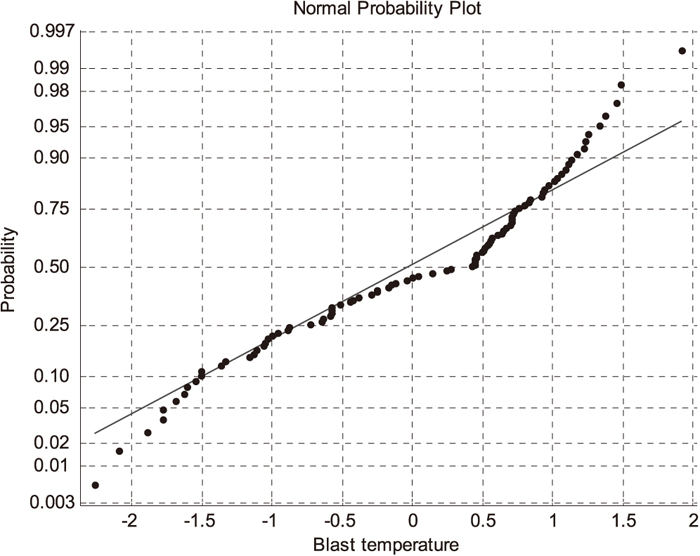
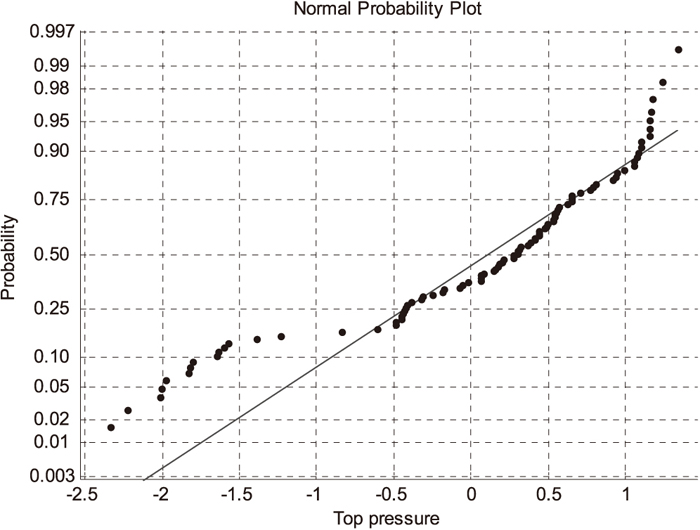
First, for online prediction of a query sample xq, the selected similar samples are analyzed. The normal probability of two input variables, including the blast temperature and the top pressure, is shown in Figs. 3(a) and 3(b), respectively. The distribution results indicate that the process variables violate the Gaussian distribution denoted by the blue dash line in Figs. 3(a) and 3(b), respectively. For most query samples, their similar data sets are non-Gaussian distribution. Consequently, the ICA-based feature extraction algorithm should be applied to preprocess the similar data before construction of a local model.
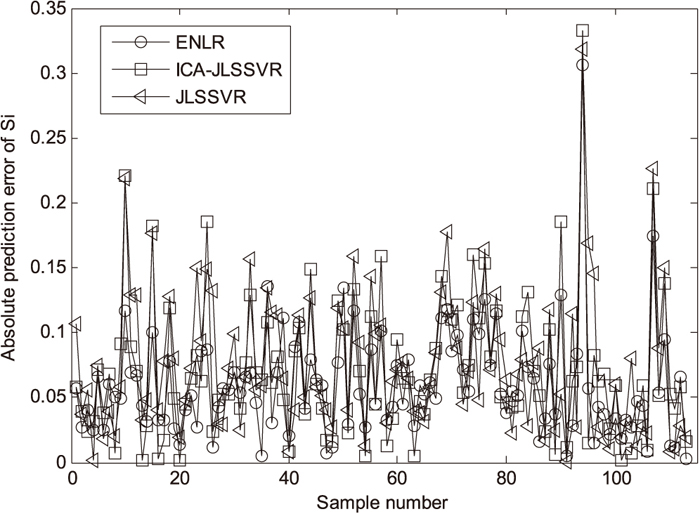
To show the advantage of ENLR, it is compared with three local soft sensors, including JLSSVR (just-in-time least squares SVR),41) ICA-JLSSVR, and JGPR.33) The JLSSVR-based soft sensor applied to silicon content prediction has shown better prediction performance than only using an LSSVR model.41) The ICA and JLSSVR is combined as an ICA-JLSSVR prediction method, with a cross-validation strategy for selecting the model parameters. JGPR, as a probabilistic local modeling method, was previously applied to polymerization processes.33) For the test data, the online prediction values and corresponding absolute prediction errors (|yq−
y
ˆ
q
|) of ENLR, ICA-JLSSVR, and JLSSVR methods are shown in Figs. 4 and 5, respectively. For online construction of a good local model, similar samples should be preprocessing by removing the unwanted noise and the correlation among the process variables. Additionally, the variable selection and online prediction should be integrated into a modeling framework. Consequently, the prediction results shown in Figs. 4 and 5 indicate that ENLR is superior to two other methods.

To make the results more reasonable, the above test procedures are implemented for 30 times, each time with a different arrangement of the training data and the test data. The average prediction comparisons of the ENLR, ICA-JLSSVR, JLSSVR, and JGPR methods are listed in Table 1. It shows that the ENLR method achieves the best prediction performance. Additionally, local models with suitable feature extraction are generally more accurate than the ones without feature extraction. For this case study, the prediction accuracy of JGPR is almost the same with JLSSVR and thus the results are not plotted in Figs. 4 and 5.
Table 1. Average comparison results of online silicon content prediction using four different models for 30 times.
| Soft sensor model | Brief description | RMSE | RE (%) | HR (%) | Average prediction variance
(
∑
q=1
N
tst
|
σ
y
ˆ
q
|
N
tst
)
|
|---|
| Feature extraction | Model selection |
|---|
| ENLR | Yes | Probabilistic information-based ensemble learning | 0.077 | 12.63 | 82.3 | 0.08 |
| ICA-JLSSVR | Yes | Cross validation | 0.093 | 14.48 | 73.5 | No |
| JLSSVR41) | No | Cross validation | 0.098 | 15.31 | 69.0 | No |
| JGPR33) | No | Cumulative similarity factor33) | 0.097 | 15.22 | 69.9 | 0.13 |
The main characteristics of four modeling methods are also described briefly in Table 1. It should be noted that ENLR and JGPR are probabilistic modeling methods, while ICA-JLSSVR and JLSSVR are deterministic modeling methods. That is to say, ENLR and JGPR can provide the prediction variance information. This is important for soft sensors because the operators/engineers can know whether the prediction is good or bad before the lab analysis results are available. Moreover, for the average prediction variance of all test data, ENLR is much smaller than JGPR. Consequently, ENLR is more reliable and useful than JGPR. In our opinion, it is unnecessary to further analyze those samples with a very small prediction variance value. In such a situation, human effort can be saved on analyzing data in industrial ironmaking processes. Therefore, from all the prediction results, more accurate prediction and efficient implementations of ENLR can be obtained.
5. Conclusion
This work has proposed an ENLR soft sensor modeling method for the silicon content prediction when the nonlinear modeling data are non-Gaussian and uneven distributed. Its main distinguished characteristics are briefly summarized. First, the variables extraction and soft sensor are integrated into the online prediction framework. Second, the probabilistic information-based ensemble learning can be efficiently implemented for the final prediction. The superiority of ENLR is demonstrated and compared with other JITL-based methods in terms of the online silicon content prediction in an industrial blast furnace. How to automatically detect and reconcile both input and output measurement biases and misalignments with novel strategies is one of our future directions. It is also interesting to develop probabilistic model-based controller to increase productivity and reduce potential cost.
Acknowledgment
The authors would like to gratefully acknowledge the National Natural Science Foundation of China (Grant No. 61640312) and Foundation of Key Laboratory of Advanced Process Control for Light Industry (Jiangnan University), Ministry of Education, China (Grant No. APCLI1603) for the financial support.
Abbreviations
ENLR = ensemble non-Gaussian local regression
FCM = fuzzy c-means
GPR = Gaussian process regression
HR = hit rate
ICA = independent component analysis
ICA-JLSSVR = independent component analysis-just-in-time least squares support vector regression
JITL = just-in-time-learning
JGPR = just-in-time Gaussian process regression
JLSSVR = just-in-time least squares support vector regression
LSSVR = least squares support vector regression
NN = neural networks
PCA = principal component analysis
RE = relative root-mean-square error
RMSE = root-mean-square error
SVR = support vector regression
References
- 1) X. G. Bi, K. Torrssel and O. Wijk: ISIJ Int., 32 (1992), 481.
- 2) K. Sugawara, K. Morimoto, T. Sugawara and J. S. Dranoff: AIChE J., 45 (1999), 574.
- 3) V. R. Radhakrishnan and K. M. Ram: J. Process Control., 11 (2001), 565.
- 4) H. Nogami, M. S. Chu and J. Yaji: Comput. Chem. Eng., 29 (2005), 2438.
- 5) K. Nishioka, T. Maeda and M. Shimizu: ISIJ Int., 45 (2005), 669.
- 6) S. Ueda, S. Natsui, H. Nogami, J. I. Yagi and T. Ariyama: ISIJ Int., 50 (2010), 914.
- 7) V. R. Radhakrishnan and A. R. Mohamed: J. Process Control., 10 (2000), 509.
- 8) J. Jimenez, J. Mochon, J. S. de Ayalai and F. Obeso: ISIJ Int., 44 (2004), 573.
- 9) H. Saxen and F. Pettersson: ISIJ Int., 47 (2007), 1732.
- 10) F. Pettersson, N. Chakraborti and H. Saxén: Appl. Soft Comput., 7 (2007), 387.
- 11) A. Nurkkala, F. Pettersson and H. Saxen: Ind. Eng. Chem. Res., 50 (2011), 9236.
- 12) X. J. Hao, F. M. Shen, G. Du, Y. S. Shen and Z. Xie: Steel Res. Int., 76 (2005), 694.
- 13) T. Bhattacharya: ISIJ Int., 45 (2005), 1943.
- 14) R. D. Martin, F. Obeso, J. Mochon, R. Barea and J. Jimenez: Ironmaking Steelmaking, 34 (2007), 241.
- 15) M. Waller and H. Saxen: Ind. Eng. Chem. Res., 39 (2000), 982.
- 16) C. H. Gao, Z. M. Zhou and J. M. Chen: Ind. Eng. Chem. Res., 47 (2008), 3037.
- 17) M. Waller and H. Saxen: ISIJ Int., 42 (2002), 316.
- 18) T. Miyano, S. Kimoto, H. Shibuta, K. Nakashima, Y. Ikenaga and K. Aihara: Phys. D, 135 (2000), 305.
- 19) J. S. Zeng and C. H. Gao: J. Process Control., 19 (2009), 1519.
- 20) L. Jian, C. H. Gao and Z. Q. Xia: Steel Res. Int., 82 (2011), 169.
- 21) C. H. Gao, J. S. Zeng and S. H. Luo: IEEE Trans. Ind. Electron., 59 (2012), 1134.
- 22) L. Jian, S. Q. Shen and Y. Q. Song: J. Appl. Math., (2012), Article ID 949654, DOI:10.1155/2012/949654.
- 23) C. H. Gao, J. M. Chen, J. S. Zeng, X. Y. Liu and Y. X. Sun: AIChE J., 55 (2009), 947.
- 24) C. H. Gao, J. S. Zeng and Z. M. Zhou: AIChE J., 57 (2011), 3448.
- 25) Y. X. Chu and C. H. Gao: AIChE J., 60 (2014), 2197.
- 26) S. H. Luo, C. H. Gao, J. S. Zeng and J. Huang: Asian J. Control, 15 (2013), 553.
- 27) A. Nurkkala, F. Pettersson and H. Saxen: ISIJ Int., 52 (2012), 1763.
- 28) H. Saxen, C. H. Gao and Z. W. Gao: IEEE Trans. Ind. Inform., 9 (2013), 2213.
- 29) M. Kano and Y. Nakagawa: Comput. Chem. Eng., 32 (2008), 12.
- 30) P. Kadlec, B. Gabrys and S. Strandt: Comput. Chem. Eng., 33 (2009), 795.
- 31) C. E. Rasmussen and C. K. I. Williams: Gaussian Processes for Machine Learning. MIT Press, Cambridge, MA, (2006).
- 32) T. Chen and J. H. Ren: Neurocomputing, 72 (2009), 1605.
- 33) Y. Liu, T. Chen and J. Chen: Ind. Eng. Chem. Res., 54 (2015), 5037.
- 34) E. Zamprogna, M. Barolo and D. E. Seborg: J. Process Control., 15 (2005), 39.
- 35) A. Hyvarinen: Neural Comput., 9 (1997), 1483.
- 36) A. Hyvarinen and E. Oja: Neural Netw., 13 (2000), 411.
- 37) Z. Ge, Z. Song and F. R. Gao: Ind. Eng. Chem. Res., 52 (2013), 3543.
- 38) Y. Liu and J. Chen: J. Process Contr., 23 (2013), 793.
- 39) C. Cheng and M. S. Chiu: Chem. Eng. Sci., 59 (2004), 2801.
- 40) K. Fujiwara, M. Kano, S. Hasebe and A. Takinami: AIChE J., 55 (2009), 1754.
- 41) Y. Liu and Z. L. Gao: Ironmaking Steelmaking, 42 (2015), 321.
- 42) K. Chen and Y. Liu: ISIJ Int., 57 (2017), 107.
- 43) S. Miyamoto, H. Ichihashi and K. Honda: Algorithms for Fuzzy Clustering, Methods in c-Means Clustering with Applications, Springer, New York, (2008).
- 44) Z. H. Zhou, J. X. Wu and W. Tang: Artif. Intell., 137 (2002), 239.
- 45) H. C. Kim, S. N. Pang, H. M. Je, D. J. Kim and S. Y. Bang: Pattern Recognit., 36 (2003), 2757.
- 46) Y. Liu, Z. J. Zhang and J. Chen: Chem. Eng. Sci., 137 (2015), 140.
- 47) Y. Liu, Y. Fan, L. C. Zhou, F. J. Jin and Z. L. Gao: Chem. Eng. Technol., 39 (2016), 1804.