[title in Japanese]
2023 Volume 21 Pages 63-87
Details
2023 Volume 21 Pages 63-87
中小企業の信用リスクを計測する信用リスクモデルは, 目的変数にデフォルトの有無, 説明変数として主に決算書の数値を用いたロジスティック回帰モデルが主流となっている. ただ, これから創業する企業は決算書がないため, 創業者に関する情報や業界・市場環境に関する情報といった決算書以外の情報から説明力のある変数を探して選択する必要がある. 創業者に関する情報のうち, 創業時の年齢と斯業経験年数は, 創業後のパフォーマンスとの関係が有意であるとする研究が複数あり, モデルの変数として有力な要因と考えられる.
先行研究をみると, 創業時の年齢は, 創業後の成功に対してマイナスの相関, 斯業経験年数はプラスの相関で有意とする分析結果が多いものの, 玄田(2001)は, 創業時の年齢の2乗と斯業経験年数の2乗が有意であることを示している. さらに, 学校を卒業してから20年くらい関連した経験を積んで40歳くらいで創業する場合に最も経済的成功を収めやすいという創業にベストなタイミング「旬」があると述べている. とすれば, 「旬」で創業した企業の信用リスクを評価する場合, 個別に創業時の年齢と斯業経験年数を評価すると過大評価する可能性があり, 「旬」についてもモデルの変数として有力な要因になると考えられる. ただ, 玄田(2001)は二つのデータをクロスした分析は行っておらず, 信用リスクモデルの構築や評価も行っていない.
創業企業向けの信用リスクモデルに関する先行研究として, 尾木・内海・枇々木(2017)は, 日本政策金融公庫(以下, 日本公庫)が融資した34,470件の創業企業の非財務情報から, デフォルトと関係がありそうな変数を「人的要因」「金融要因」「業種要因」の三つのカテゴリーに分けて分析し, 有意になった非財務変数を使ったモデルが実務で利用可能であることを示した. 人的要因では, 創業時の年齢の40歳未満ダミー変数と斯業経験年数の5年以内ダミー変数が有意であることを明らかにしているが, 非線形関数を使った定式化や二つの変数をクロスした詳細な分析は行っていない.
そこで, 本研究では, 「創業時の年齢」と「斯業経験年数」に着目し, 日本公庫が融資した約11万件の創業企業のデータを用いて, デフォルトとの関係を詳細に分析するとともに, 非線形関数を使った定式化を試みる. さらに, 二つの変数をクロスした創業の「旬」が存在するかどうかについて確認する. 本研究では, 創業時の年齢と斯業経験年数をクロスした部分の企業数が構成比で1%以上かつ100件以上存在し, デフォルト率の水準が全体もしくは業種平均のおおむね半分以下になるタイミングを創業にベストなタイミング「旬」と定義し, その存在の有無について, さまざまな角度から分析する. 最後に, これらの変数をモデルの新たな変数として採用して説明力があるかどうかを検証し, 同時に尾木ら(2017)のモデルに比べて精度が向上するかどうかも明らかにする.
分析の結果, 創業時の年齢は, 年齢別デフォルト率を4次関数で定式化でき, 斯業経験年数は, 年数別デフォルト率を2次関数もしくは区分線形関数で定式化できることがわかった. さらに, 筆者らの知る限りにおいて,信用リスク評価の観点からも創業の「旬」があることを初めて実証的に確認できたとともに, 「旬」で創業したかどうかを示すダミー変数が飲食店において統計的に有意となり, 信用リスクの過大評価を修正する効果が期待できることも明らかになった. これらをモデルの変数として投入すると, モデルの精度を示すAR値が, 尾木ら(2017)が示したモデルに比べて, インサンプルで5.6%ポイント, アウトオブサンプルで5.8~6.1%ポイント向上することを確認した.
中小企業の信用リスク計測には, 目的変数にデフォルトの有無, 説明変数として主に決算書の数値を用いたロジスティック回帰モデルが広く使われている. ただ, 創業企業1は決算書がないため, 創業企業向けのモデルは, 説明変数に非財務情報を用いる必要がある. 創業企業の非財務情報には, 創業者の年齢や経験といった人的要因, 創業者の保有資産やクレジットヒストリーといった金融要因, 市場の競争環境や参入障壁といった業種要因などが考えられる. これらの要因の中で, 本研究は人的要因, とりわけ, 創業時の年齢と斯業経験2年数に着目する. 創業者の資質は, 創業後の成功に大きな影響を与えることが多くの研究で示されており, 特に創業時の年齢と斯業経験年数は, 複数の研究で有意性が確認されていることから, モデルの変数として有力な要因になると考えたからである.
はじめに, 創業時の年齢および斯業経験年数と創業後のパフォーマンスとの関係を分析した研究に加え, われわれの知る限り国内唯一と思われる創業企業向けの信用リスクモデルに関する研究(尾木・内海・枇々木(2017))をサーベイする.
まず, 創業時の年齢については, 年齢が高いほど創業後のパフォーマンスが下がる, つまり, 年齢に対してマイナスに有意であるとする研究が多い. Hambrick and Mason(1984)は, 年齢が高くなるほど体力や精神力が衰え, 経営にマイナスの影響が出ると述べている. Le´vesque and Minniti(2006)は, 年齢が上がるとともに期待される報酬が低下するため, ある年齢を超えると創業は減少するとしている. 安田(2010)は, 創業のパターンを, 事業計画に十分に勝算がある者が創業を選択して実現後高いパフォーマンスを達成する「プル型モデル」と, 事業計画以前に創業にしか活路を見いだせない状況で創業を選択させられてしまい実現後のパフォーマンスは必ずしもよいものではない「プッシュ型モデル」に分け, 創業と創業後のパフォーマンスの関係を分析した.
分析の結果, 創業時の年齢については, 創業後のパフォーマンスに対してマイナスの相関があること, 創業時の年齢が20歳代の者は有意に黒字を達成する傾向がある反面, 40歳代の者は有意に赤字になる可能性が高いことを示した. この結果について, 40歳代以上の者は, 創業動機が「就職先がない」「年齢に関係なく働きたい」といった追い込まれた状況で創業している割合が若年層よりも高く, プッシュ型モデルが多いことを述べている. また, 国民生活金融公庫総合研究所(現:日本政策金融公庫総合研究所)『新規開業白書』(2006)でも, リストラ型創業の割合は30歳代が13.6%であるのに対し, 40歳代になると28.4%, 50歳代は38.0%に増えることを示している.
森・渡辺(2010)は, 2004年と2006年に横浜市で実施したアンケート調査を分析し, 創業時期の選定理由の1位が「年齢的に適当と判断したから」(回答比率60.9%)となっており, 創業時の年齢が創業の重要な要素になっていることを述べている. さらに, 『中小企業白書2003年版』のデータを引用して, 創業に失敗した人が再び創業しない理由の第1位が「高齢だから」が35. 1%を占めていることについて, 高齢者は, 年齢に伴う体力・気力的な問題だけではなく, 創業を準備して, それを安定的に運営し, 成果を獲得できるまでになるには相当の時間がかかるために, 創業に踏み切れないと解釈できると述べている. つまり, 年齢が高いことは, 創業にマイナスの影響があることを示すものといえる.
村上(2010)も, 日本公庫が実施した2010年度新規開業実態調査のデータ(2,907件)を用いて創業者の斯業経験と創業直後の業績について分析し, 創業時の年齢について, 年齢が高いほど目標月商達成率が低くなることを示した. 熊田(2010)も, 売上傾向(「1=増加」「0=横ばい, 減少」としたダミー変数)を目的変数として回帰分析した結果, 創業時の年齢は負で有意となり, 年齢が高くなるほどパフォーマンスが低下すると述べている. 松田・松尾(2013)は, 創業と人的資本(起業家の能力, 教育や過去の経験など)および社会関係資本(起業家の人的ネットワークから得られる情報や知識など)との関係についてwebアンケートを行い(有効回答数7,023人), 創業時の年齢について, 年齢が上がるほど利益を上げる確率が低くなることを述べている. Gielnik et al.(2018)は, 年齢が上がるほど, ビジネスチャンスに対する意識が低下すると指摘している.
一方, Blanchflower et al.(2001)は, 創業時の年齢は高いほど創業意欲が高く, Azoulay et al.(2020)は, 成功している新興企業の経営者は若者よりもミドル層の方が多いことを示しており, 年齢が高いほどパフォーマンスが上がる, つまり, 年齢に対してプラスに有意であるとしている. 創業時の年齢と創業後のパフォーマンスは非単調の関係にあるとする研究もある. 玄田(2001)は, 「月商」「付加価値」「所得・収入」を目的変数として「開業時の年齢」および「開業時の年齢の2乗」について回帰分析した結果, 年齢はプラスで有意, 年齢の2乗は, 月商は41歳, 付加価値は40歳, 所得・収支は37歳がピークで有意であることを示し, 創業時の年齢には最適な年齢が存在し, 40歳くらいが最も経済的成功を収める可能性が高いことを述べている. 逆に, Zhao et al.(2021)は年齢に対して創業後の成功は弱い正の線形関係を持っていることを示すとともに, 若い年齢層で負の関係, 高い年齢層で正の関係があり, U字型の関係の兆候があることを指摘している.
次に, 斯業経験年数については, 年数が長いほど創業後のパフォーマンスに対してプラスに有意であるとする研究が多い. Cooper et al.(1994)は, 業界固有のノウハウや経験はプラスの影響を与えるとしている. Shane and Venkataraman(2000)は, 過去の経験が豊富なほどビジネスチャンスに敏感であり, Krueger et al.(2000)も, 仕事を通じた経験が創業意識にプラスの影響を与えることを示した. また, Brush et al.(2008)は, 経験が創業後の成功確率を上げると述べている.
森・渡辺(2010)は, 前述のアンケートにおいて, 創業時期の選定理由の第2位は「技術的に適当と判断したから」(同32.8%)であることを示しており, 技術やノウハウが蓄積される斯業経験年数も創業にとって重要な要素であることを示唆している. 村上(2010)は, 斯業経験の有無と目標月商達成率の関係を分析し, 「斯業経験あり」の達成割合が高く, 斯業経験を積むことによって創業直後から良好な業績を得やすいと述べている. その理由として, 斯業経験は, 「いつかは会社や店をもちたい」といった経営者になることを意識して仕事をしながら, 「業界知識」「人脈」「技術力」「営業力」など, 経営に必要な能力を獲得できることにあるとしている.
鈴木(2012)は, わが国で創業した企業の廃業要因を, 「起業家要因」「企業・環境要因」「戦略要因」の三つの視点からロジット分析している. 分析の中で, デフォルトの定義に近いリスク管理債権に分類された非自発的廃業について, 斯業経験年数がマイナスで有意になったと述べている. 松田・松尾(2013)は, 前述の分析において創業分野での就業経験, すなわち, 斯業経験がわずかに利益に正の影響を与えることを確認している. D’Angelo and Presutti(2019)は, 業界固有の経験が成長にプラスの影響を与えることを示した.
一方, 熊田(2010)は, 斯業経験年数は創業後のパフォーマンスにマイナスに有意であることを述べている. ただ, 斯業経験が創業準備に影響を与えるのであれば, 一定の経験年数は必要であり, その前提があったうえで年数が長くなるほどパフォーマンスが悪くなると考えるのが妥当であることも説明している.
玄田(2001)は, 創業時の年齢と同様に斯業経験年数についても, 「斯業経験年数」と「斯業経験年数の2乗」で回帰分析し, 年数はプラスで有意, 年数の2乗は, 付加価値は21.1年, 所得・収支20.5年をピークで有意であり, ピークまではパフォーマンスが上がり, ピークを超えるとパフォーマンスが下がることを述べている.
最後に, 創業時の年齢と斯業経験年数をクロスした創業の「旬」に関する先行研究としては, 玄田(2001)がある. 創業時の年齢と斯業経験年数の2乗項が付加価値や所得などに対して有意なことから, 創業にはベストなタイミング「旬」があり, 学校を卒業してから20年くらい関連した経験を積み, 40歳くらいで創業するケースが経済的成功を収めやすいことを述べている. また, 2021年度に約2.6万件の創業企業(うち, 創業前の企業は約1.3万件)に対する融資を行った日本公庫の審査員の経験則に「若いころから経験を積みながら資金を貯め, 機が熟したタイミングで創業するパターンが成功しやすい」というものがある. つまり, 「旬」で創業する企業は, 安田(2010)が述べているように, 事業計画性が高く, 十分に勝算がある者が創業を選択して実現後高いパフォーマンスを達成する「プル型モデル」に該当すると考えられる.
以上を踏まえると, 創業にはベストなタイミング「旬」が存在し, 創業時の年齢と斯業経験年数で表現できる可能性がある. さらに, 「旬」で創業した企業は事業計画性が高く, 創業してから経済的に高いパフォーマンスを期待できることから, 「旬」で創業した企業の信用リスクは, 創業時の年齢と斯業経験年数を個別に評価すると過大評価する可能性がある. ただ, 創業の「旬」の存在や信用リスクモデルの変数としての有効性について, データを使って実証分析した研究は筆者らの知る限り存在しない.
創業企業の信用リスクモデルに関する先行研究としては, 尾木・内海・枇々木(2017)があり, われわれが知る限り国内唯一の研究である. 尾木ら(2017)は, 日本公庫が融資した34,470件の創業企業の非財務情報を用いて, 創業企業向け信用リスクモデルを構築した. 創業融資の審査は, 財務諸表に表れる過去の実績がないので, 「創業して事業を軌道に乗せられる能力はあるか」「貸したお金をきちんと返してくれる資金力があるか」といった創業者の能力や資金力の評価が重要になる. とりわけ, 創業者の能力と創業費用(総額)に占める自己資金の割合が重要視される. そこで, 説明変数の選択において, デフォルトと関係がありそうな変数を「人的要因」「金融要因」「業種要因」の三つのカテゴリーに分けて分析した.
分析の結果, 人的要因として「創業の計画性」「斯業経験年数」「創業時の年齢」といった経営に必要な知識や経験, 体力などが創業者に備わっているかどうかを示す変数が, 金融要因については「創業者個人のクレジットヒストリー」「自己資金額」といった創業者の資金調達力や返済力などを示す変数が, それぞれ有意になった. 業種要因については, 参入障壁が低いために競争が激しいことからデフォルト率が相対的に高い3つの業種グループと, 参入障壁が高いために競争が比較的緩やかでデフォルト率が相対的に低い4つの業種グループのダミー変数が有意になった. これらの説明変数を用いて, 1年後のデフォルトの有無を被説明変数とする二項ロジスティック回帰モデルを構築した結果, モデルの精度を示すAR値は57.1%となり, 実務で利用可能な水準であることがわかった.
この研究では, 人的要因として, 創業時の年齢の40歳未満ダミー変数と斯業経験年数の5年以内ダミー変数が有意であることを明らかにしているが, 非線形関数を使った定式化や二つの変数をクロスした詳細な分析は行っていない. そこで, 本研究では, 「創業時の年齢」と「斯業経験年数」に着目し, 日本公庫が融資した約11万件の創業企業のデータを用いて, デフォルトとの関係を詳細に分析するとともに, 非線形関数を使った定式化を試みる. さらに, 「創業時の年齢」と「斯業経験年数」をクロス分析して創業の「旬」が存在するかどうかについて確認する.
ここで本研究における「旬」の定義を確認する. 本研究では, 創業時の年齢と斯業経験年数をクロスした部分の企業数が構成比で1%以上かつ100件以上存在し, デフォルト率の水準が全体もしくは業種平均のおおむね半分以下になるタイミングを創業にベストなタイミング「旬」と定義する. このように想定した理由は2点ある. 1点目は, デフォルト率は数パーセントの水準になることが多く, 安定した結果を得るには分母となるデータ数を一定数以上確保する必要がある. 2点目は, 「旬」での創業が最も信用リスクが低くなりやすいと仮定すれば, 「旬」で創業した企業のデフォルト率の水準は, 創業時の年齢別デフォルト率や斯業経験年数別デフォルト率の最低水準よりもさらに低くなることが期待できる. そこで, 創業時の年齢別デフォルト率のボトムである35歳のデフォルト率の水準(平均の57%の水準), 並びに斯業経験年数別デフォルト率のボトムである13年~18年を平均したデフォルト率の水準(平均の51%の水準)をベースに, 「旬」のデフォルト率の水準は, これらのボトムとおおむね同水準かそれ以下であることが必要と考えられる.
最後に, 創業時の年齢と斯業経験年数, 創業の「旬」といった変数をモデルの新たな変数として採用し, 精度が向上するかどうかを検証することで, 変数に説明力があることを明らかにする.
本研究の主な結果は以下のとおりである.
本論文の構成は以下のとおりである. 第2章で分析の概要について述べ, 第3章では, 創業時の年齢および斯業経験年数, 創業の「旬」に関する分析と定式化を行い, 第4章で新モデルを構築し, モデルの精度を検証する. 第5章でまとめと今後の課題を述べる.
本研究の目的は2点ある. 1点目は, 「創業時の年齢」と「斯業経験年数」に着目し, 日本公庫が2011年度から2018年度に融資した創業企業108,718件のデータを用いて, デフォルトとの関係を分析するとともに, 分析結果に基づいて, 「創業時の年齢」ごとのデフォルト率の水準と「斯業経験年数」ごとのデフォルト率の水準について非線形関数を使って定式化した関数が, 信用リスクモデルにおける説明変数として有効かどうかを検証する. 2点目は, 創業の「旬」 に着目し, 「創業時の年齢」と「斯業経験年数」の二つの情報をクロスして分析を行う. クロスした部分のデフォルト率の水準が全体もしくは業種平均のおおむね半分以下になるタイミング, すなわち, 本研究で想定した創業の「旬」の存在が確認できれば, 何らかの形でモデルの新変数として採用し, 変数としての説明力があるかどうかを検証する.
検証のベンチマークとして, 創業企業向け信用リスクモデルのおそらく国内唯一の先行研究である尾木・内海・枇々木(2017)モデル(以下, OUHモデルという. )を用い, モデルの精度が向上するかどうかを確認することで変数としての説明力と有効性を検証する.
OUHモデルも創業時の年齢の40歳未満ダミー変数と斯業経験年数の5年以内ダミー変数が有意であることを明らかにしているが, 非線形関数で表せる連続変数を用いた定式化は行っていない. また, 創業の「旬」については分析していない. 一方, 先行研究を踏まえると, 創業時の年齢は高くなるほどデフォルト率が高く, 斯業経験年数は長くなるほどデフォルト率が低くなることが想定されるが, ある変数とデフォルトとの関係が単調な関数になるとは限らない. そこで, 本分析では特にこの点に注意して分析する. パラメータの推定は, SAS/STAT®を用いる.
2.2 モデルとデータの概要信用リスクモデルにはさまざまなタイプがある. なかでもロジスティック回帰モデル(ロジットモデル)は, 最も一般的に用いられており, CRD(Credit Risk Database)協会やRDB(日本リスク・データ・バンク㈱)といった代表的な中小企業向けモデルでも採用されている. ロジットモデルには, 複数の格付を直接推定する順序ロジットモデルと, デフォルトの有無を被説明変数としてデフォルト確率を推定する二項ロジットモデルがある. 本研究では, OUHモデルと同様に, 二項ロジットモデルを採用し, 算出されたデフォルト確率を概ね0~100点までのスコアに変換して使用する. また, 本研究におけるデフォルトの定義は, 融資した時点から2年以内(融資月から数えて24カ月以内)に破綻懸念先(3カ月以上延滞先)以下に遷移した企業であり, デフォルト率は, 融資した企業のうち, 2年以内にデフォルトした企業の割合である.
2.2.1 OUHモデルの概要OUHモデルを構築する際に用いられた変数は, 変数によって異なるデータベースを利用している. そこで, データベースごとに二つのモデルを構築し, それぞれの結果を統合するモデルを構築している. 具体的には, DB1(全数データ)を用いてモデル1を, DB2(業種と地域に比例して抽出したサンプルデータ)を使ってモデル2を構築し, モデル1とモデル2の各スコアを変数とする統合モデル(モデル3)を構築している.
OUHモデルの説明変数を表1, 統合モデルの標準化回帰係数を表2に示す. モデルの精度を示すAR値は, モデル1が51.2%, モデル2が27.9%となっている. 統合モデルは, DB2(1,718件)のデータを用いて構築し, AR値4は57.1%となっている.

表1 OUHモデルの説明変数

表2 OUHモデルの統合モデルの標準化回帰係数
本研究においても, 変数によってデータの蓄積開始時期が異なるため, 二つのデータベースが存在し, それぞれのデータベースの主な変数候補を表3に示す. DB2は2017年1月から蓄積を開始したDB1にはない新たな変数が格納されている. 本研究においても, OUHモデルと同様に, データベースごとに二つのモデルを構築し, それぞれの結果を統合する. ただし, 創業時の年齢と業種別デフォルト率, 業種別ダミーについては, 分析時にはDB1も用いるが, モデル構築時には, 斯業経験年数とクロスした変数や業種別の変数を用いる必要があり, DB2の範囲(期間2017年1月~2019年3月, n=33,550)のデータを使用する点には注意が必要である.

表3 主な変数候補
データ数をOUHモデルと比較すると, DB1が34,470件から108,718件に, DB2が1,718件から33,550件に増えている. また, OUHモデル構築時のDB2は, データの都合上, 全数が利用できないため, 業種と地域に比例して抽出した1,718件のサンプルデータであったが, 本研究では, 2017年以降に蓄積した全数のデータを使用する.
OUHモデルのAR値は先行研究時の結果であり, 本研究において比較検証する際は, 同じデータを用いてOUHモデルを変数選択から再推計する. ただし, 創業時の年齢は40歳未満ダミー変数, 斯業経験年数は5年以内ダミー変数を使用する.
2.2.3 本研究に使用するデータの業種構成とデフォルト水準表4に本研究に使用するデータの業種構成とデフォルト水準を示す. デフォルト率は融資先企業のうち, 融資から2年以内に破綻懸念先以下に遷移した企業の割合で, デフォルト水準とは全体のデフォルト率を「1」として指数化した値である. 業種
| (2.1) |
業種要因を用いるDB2で業種構成を見ると, 飲食店が最も多く, 全体の28.0%を占めている. 次に多いのは理・美容業で13.1%, 小売業の11.8%と続く. 業種別のデフォルト水準をみると, エステ業が1.60, 飲食店が1.46と全体(1.0)に比べて1.5倍前後と高くなっている. 一方, 不動産賃貸・管理業が0.09で最も低く, 医療業0.14, 士業(弁護士, 公認会計士, 税理士, 司法書士など)0.17, 理・美容業0.21となっている. DB1でみても同様の傾向がみられ、DB2と比べて構成比やデフォルト水準に大きな差はないことがわかる.

表4 業種構成
使用データにおいて考えられるサンプルバイアスは以下のとおりである.
「創業時の年齢」と「斯業経験年数」は, 創業後のパフォーマンスとの関係を分析した多くの先行研究を踏まえると, デフォルト水準と単調な関係になることが予想される. 一方で, 玄田(2001)の研究を踏まえると, いずれの変数もデフォルト水準に対して下に凸の曲線関係が予想される. そこで, 本研究では, 表3に示したDB2の33,550件のデータを用いて, 「創業時の年齢」と「斯業経験年数」について, それぞれデフォルトとの関係を詳細に分析し, 非線形関数を使った定式化を試みる. また, 創業にベストなタイミング「旬」があると言われていることから, 二つの変数をクロス分析することによって, 創業の「旬」の存在を確認する. 「旬」の存在が確認できれば, 何らかの形でモデルの新変数として採用し, 変数として説明力があるかどうかを検証する.
3.1 創業時の年齢別デフォルト水準の定式化先行研究からは, 創業時の年齢に対してデフォルト水準は, 単調増加が予想される一方, 玄田(2001)を踏まえると, 下に凸となることが予想される. 図1に創業時の年齢別デフォルト水準と年齢ごとの構成比を示す(20歳未満, 70歳超はグラフから除外している). なお, 斯業経験年数とクロス分析したり, モデル構築時に使用したりすることを踏まえて, ここではDB2を使用している.
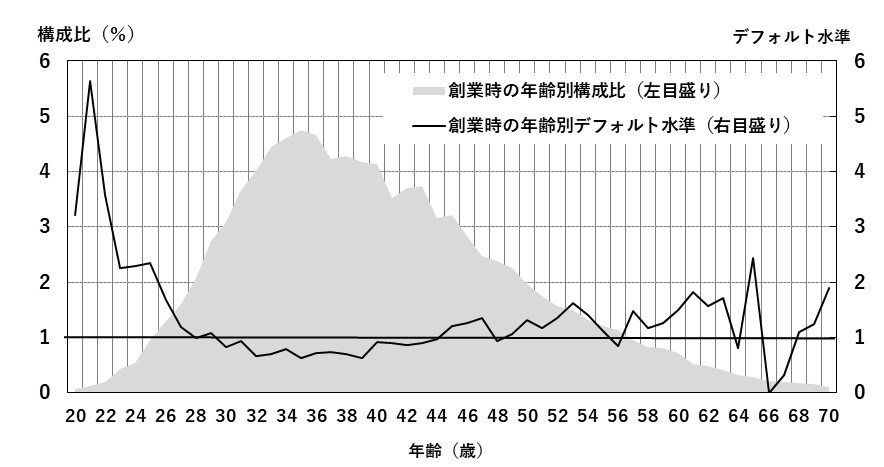
図1 創業時の年齢別デフォルト水準と年齢別構成比
図1をみると, デフォルト水準は35歳(デフォルト水準0.62)あたりまで低下(パフォーマンスは上昇)し, その後緩やかに上昇, 55歳以降は横ばいかやや低下している. 年齢が高くなるほど単調にパフォーマンスが低下(デフォルト水準は上昇)することを示す多くの先行研究とは異なる. 玄田(2001)が示したように, 一定の年齢までパフォーマンスが上昇, その後低下する傾向にあるが, 2次関数とも異なる形状をしている. また, OUHモデルでは, 40歳未満のダミー変数が正で有意(40歳未満はデフォルト水準が低い)としているが, グラフでは, 30歳未満はデフォルト水準が高くなっている. 創業時の年齢別デフォルト水準は, 業種別に異なる可能性がある. そこで, 業種別にみた創業時の年齢別デフォルト水準と年齢別構成比を図2に示す. ただ, DB2ではデータ数が少なく業種別にグラフ化して評価することが難しいためDB1を使用し, さらに比較的データ数が多い上位6業種の結果のみを示す.

注 各業種の年齢別のデフォルト水準は, 業種全体のデフォルト率を「1」として指数化した値
図2 業種別の創業時の年齢別デフォルト水準と年齢別構成比
飲食店を除くとデータ数が少ないため評価は難しいが, 飲食店, 小売業, その他サービス業は全体(図1)と同様に, 35歳近辺までデフォルト水準が低下し, その後上昇する傾向がみられる. 理・美容業はデフォルトデータが少ないためデフォルト水準の変動が大きいが, 若年層と高齢層でデフォルト水準が高く, 30歳代から40歳代はデフォルト水準が低い傾向がある. その他医療・福祉業は, 全体のように若年層でデフォルト水準が高い傾向は見られないものの, 35歳以降に年齢が高くなるほどデフォルト水準が高くなっている. 不動産賃貸・管理業は, 創業時の年齢とデフォルト水準に関係がみられず, 全体や他の業種とは傾向が異なる可能性が高い.
多くの業種では全体と同様の傾向がうかがえるが, 一部の業種では異なる動きもみられる. 業種別の定式化については今後の課題とし, データの蓄積を待って分析したい. 以降では, 全体の創業時の年齢別デフォルト水準について分析を進めることにする.
次に, 図1と先行研究を踏まえて, 創業時の年齢別デフォルト水準を多項式関数で定式化する. 式(3.1)のとおり, ロジスティック回帰モデルを用いて1次関数から5次関数のパラメータを推定する. ここで,
| (3.1) |
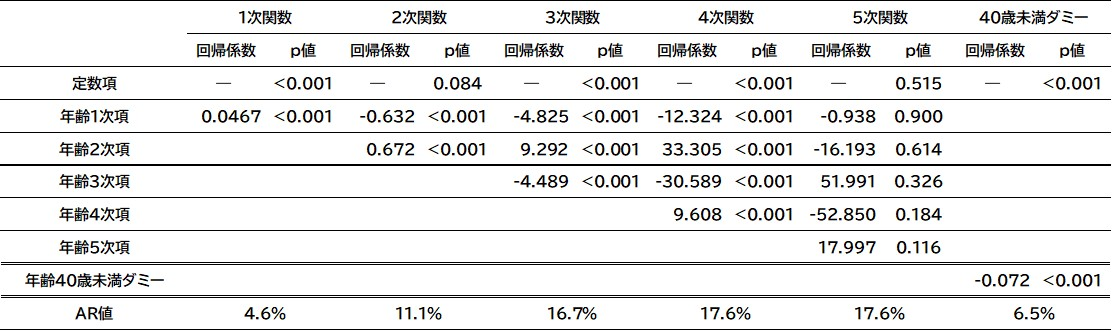
表5 創業時の年齢別デフォルト率の関数近似結果(標準化回帰係数およびp値)
4次関数を当てはめたグラフを図3に示す. これをみると, 32歳くらいまでデフォルト水準が低下している. 熊田(2010)は, 創業には一定の知識と経験があることが前提と述べており, 年齢が高くなるほど, この前提を満たした創業者の割合が徐々に増えるためと考えられる. 32歳から39歳くらいがボトムで横ばいとなり, 玄田(2001)が指摘した創業に適した年齢の40歳よりやや若くなっている. 40歳以降はデフォルト水準が上昇しており, 多くの先行研究が指摘しているように変化への対応力や体力の衰えが影響していると思われる. 55歳をピークにゆるやかにデフォルト水準が低下している. この点については, 森・渡辺(2010)が述べているように, 高齢になるほどリスクの高い創業に踏み切れない人の割合が増えるため, デフォルト水準が抑制されている可能性がある.
次に, 若年層(20歳代)と高齢層(60歳以降)の動きはデータ数が少ないことが影響している可能性がある. そこで, DB1を用いて2011年度から2018年度の8年間について, 年度別にデフォルト水準を算出し, その平均と標準偏差から変動係数を算出したグラフを図3に示す. これをみると, やはり20歳代前半と60歳代後半以降の変動係数がやや大きくなっている. この点には注意が必要であるが, その他の年齢についてはおおむね一定の範囲に収まっている. さらに, DB1とDB2を比較すると, データ数が少ない影響でDB2の変動が大きくなっているものの, 4次関数の多項式近似線をみると, かなり近い動きをしていることがわかる. そこで本研究では, 最もAR値が高く, 先行研究との関係も違和感が少ないことを踏まえ, 4次関数を採用する.
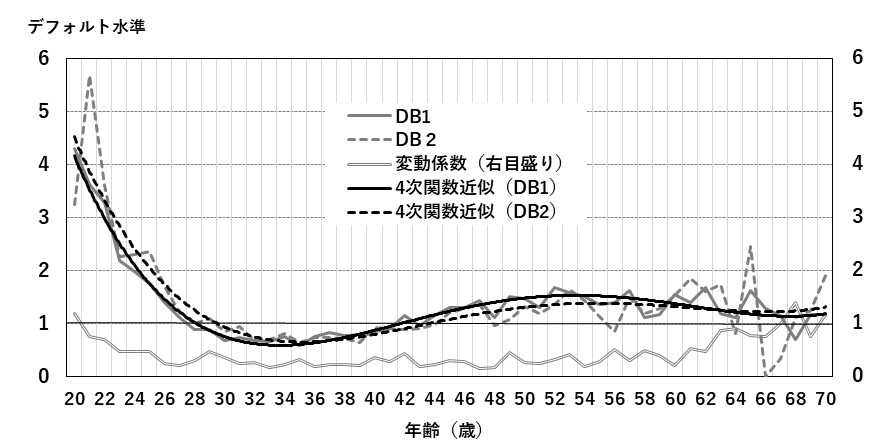
図3 DB1とDB2の創業時の年齢別デフォルト水準及び4次関数近似とDB1の変動係数
多くの先行研究を踏まえると, 単調減少することが予想されるものの, 玄田(2001)の研究をベースにすると, 斯業経験年数とデフォルトとの関係は下に凸となることも予想される. 斯業経験年数ごとのデフォルト水準とデータ構成比を示したものを図4に示す(36年超のデータ数は累積で1%以下であり, グラフから除外している).

図4 斯業経験年数別デフォルト水準と年数別構成比
まず, データの構成比をみると, 斯業経験年数1年以内で創業する企業が最も多く, 全体の20%近くを占めている. また, 26年超のデータ数は累積で5%以下であり, データのバラツキが大きくなる. 分析にあたっては, これらの点に注意する必要がある. 次に, デフォルト水準の動きをみると, 年数が長くなるにつれてデフォルト水準が低下し, 13~18年(デフォルト水準は平均0.51)あたりをボトムにその後上昇に転じるというU字型になっている. 斯業経験年数は長いほどパフォーマンスが上がるとする多くの先行研究と異なり, 玄田(2001)が指摘するように, ピークまでは上昇し, ピークを過ぎると低下するという結果に類似している.
また, 創業時の年齢と同様に, 斯業経験年数についても業種別に異なる可能性がある. ただし, 斯業経験年数は, データ数が少ないDB2に格納されている. 業種別にすると, 最もデータ数の多い飲食店で9,404件, 2番目に多い理・美容業になると4,403件しかなく, 飲食店を除くと業種別に分析することは難しい. この点についても, 創業時の年齢と同様に, 今後の検討課題とし, データの蓄積を待って分析することとしたい.
次に, 図4と先行研究などを踏まえて, 斯業経験年数別デフォルト水準を多項式関数で定式化する. 式(3.2)のとおり, ロジスティック回帰モデルを用いて1次関数から3次関数のパラメータを推定する. ここで,
| (3.2) |

表6 斯業経験年数別デフォルト率の関数近似結果(標準化回帰係数およびp値)
2次関数を当てはめたグラフを図5に示す. 上限36年(データの99%タイル点)のケースと上限26年(データの95%タイル点)のケースを表示している. どちらも斯業経験年数が長くなるにつれてデフォルト水準が低下しており, 年数が長くなるにつれて, 経験による学習効果もあり, デフォルト水準が低下するものと考えられる. ボトムは上限36年のとき18.51年, 26年のとき15.29年となった. 玄田(2001)が示した最適年数(月商33.8年, 付加価値21.1年, 収入・所得20.5年)よりも短い結果となった. ボトムを過ぎるとデフォルト水準は上昇に転じる. 安田(2010)が指摘しているように, 倒産やリストラなどで, やむを得ず創業する計画性が低い「プッシュ型」の割合が増えている可能性がある. 以上の分析結果を踏まえて, AR値が最も高く, 先行研究とも整合性のある2次関数を採用する. 上限値については, 差は小さいものの, 26年のAR値が36年より高いため, 26年を採用する.
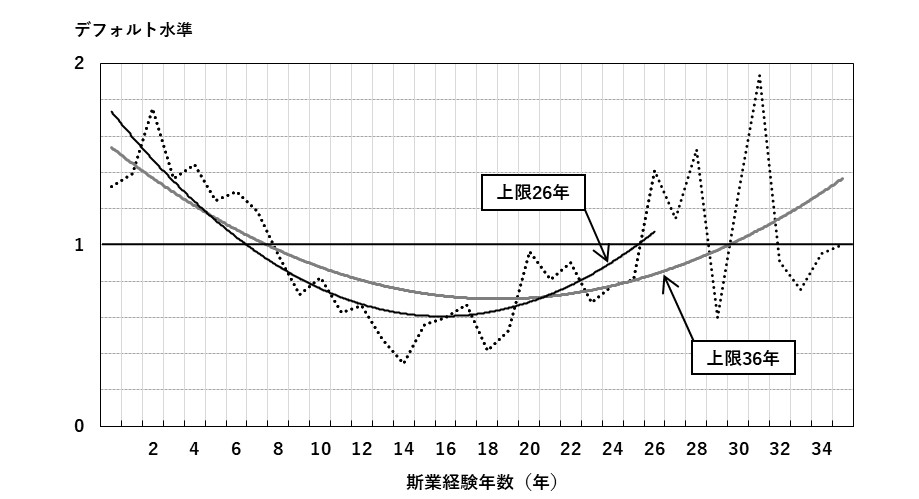
図5 斯業経験年数別デフォルト水準の2次関数近似
図5をみると, 10年から18年の実数値のグラフに対して近似曲線が二つとも上側に位置し, ボトム部分のフィッティングが良くないように見える. そこで, 図6のような区分線形関数を当てはめることを考えた. ある斯業経験年数までは, デフォルト水準が一定の割合で低下し, ボトムに達すると一定の割合で上昇するという関数である. 2次関数とは異なり, 左右非対称にできるという特徴がある.

図6 区分線形関数の当てはめ
図6のように, 区分線形関数は, デフォルト水準を
| (3.3) |
計算にあたって, まず, 上限値

表7 斯業経験年数別デフォルト率の区分線形関数近似結果(AR値)
以上のように, 本研究で分析した結果, 創業時の年齢は4次関数, 斯業経験年数は2次関数もしくは区分線形関数で近似できることがわかった. 先行研究の多くは, 創業時の年齢が高くなるほどパフォーマンスが下がり, 斯業経験年数は長くなるほどパフォーマンスが上がるという単調な関係が有意としていたが, これは, ほとんどの先行研究が線形の相関関係をベースに検証していることが原因と考えられる. しかし, 尾木・戸城・枇々木(2016)が業歴とデフォルト率との関係が3次関数で表せることを示したように, ある変数とデフォルトとの関係は線形であるという保証はない. 本研究では, この点に十分注意して分析を行った結果, 変数とデフォルトとの非線形の関係を明らかにすることができた.
3.3 「創業時の年齢」と「斯業経験年数」のクロス分析と「旬」の存在 3.3.1 「創業時の年齢」と「斯業経験年数」のクロス分析玄田(2001)や審査員の経験則を踏まえると, 創業には機が熟したベストなタイミング(以下, 「旬」という)が存在する可能性がある. そこで, DB2を用いて, 創業時の年齢と斯業経験年数をクロスした創業企業のデフォルト水準(行列5年中心化平均)を算出した結果を図7に示す. 前述したとおり, 本研究では, 「創業時の年齢」と「斯業経験年数」をクロスした部分の企業数が構成比で1%以上かつ100件以上存在し, デフォルト率の水準が全体もしくは業種平均のおおむね半分以下になるタイミングを創業の「旬」と想定した.
図7をみると, 創業時の年齢30歳から41歳と斯業経験年数12年から18年をクロスしたゾーン(黒の部分)のデフォルト水準は, 全体(1.0)の半分以下(0.5以下)となっており, 創業の「旬」が存在することがわかる. つまり, 玄田(2001)に従えば, 学校を卒業してから12年から18年ほど関連した経験を積み, 30歳から41歳に創業する場合に最も信用リスクが低くなりやすいということになる. たとえば, 高校を卒業して12年経験を積んで30歳で創業する場合や大学を卒業して18年経験を積んで40歳で創業する場合などが当てはまる.
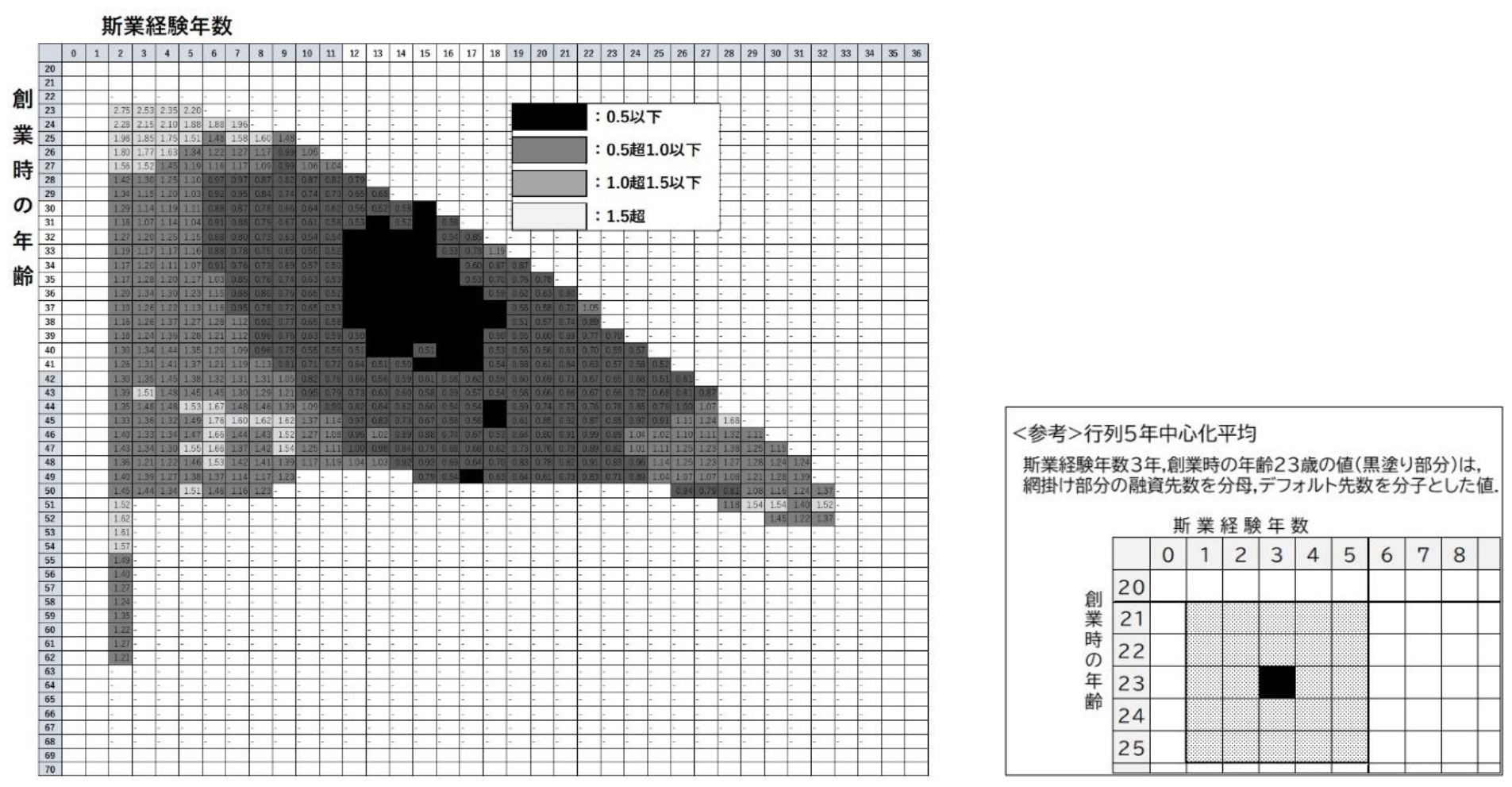
注 DB2(n=33,550)を使用. データ数が1%以上かつ100件以上となったセルのみ表示.
図7 創業時の年齢と斯業経験年数をクロスしたデフォルト水準(行列5年中心化平均)
創業にベストなタイミング「旬」は業種により異なると考えられる. そこで, 創業時の年齢と斯業経験年数の相関が高い2業種と相関が低い2業種について算出した結果を図8に示す. 相関が高い業種は, ①医療業(0.86), ②理・美容業(0.79)となっている. 相関が高い業種は, 二つともデフォルト水準の低い業種グループに属している(医療業0.13, 理・美容業0.25). いずれも事業を営むには資格が必要で, 創業するまでに一定の知識と経験が必要なことから, 必然的に相関が高くなっていると思われる. このような業種は, 資格取得を目指す時点で, 何年くらい経験を積み, 何歳くらいで創業するのかを具体的にイメージしており, 計画性が高く, そのための資金も蓄積してきた人が多いと考えられる.
一方で, 相関が低い業種は, ①不動産賃貸・管理業(0.09), ②その他サービス業(0.28)となっている. 不動産賃貸・管理業は, 斯業経験年数が重要ではないと思われるため相関が低いと考えられる. また, その他サービス業は, 斯業経験年数に関係なく創業している層と, 創業時の年齢と相関が高く一定の経験を積んでから創業している層に二極化しているため相関が低くなっていると考えられる. デフォルト水準をみると, 不動産賃貸・管理業は0.09と低く, その他サービス業は1.26とやや高くなっている.
ただし, 斯業経験年数と同様にDB2を使用しているため, 業種別にすると多くの業種でセルの企業数が100件未満となり, デフォルト水準を算出することが難しい. 「旬」の業種別分析についても, データの蓄積を待って分析することとしたい.
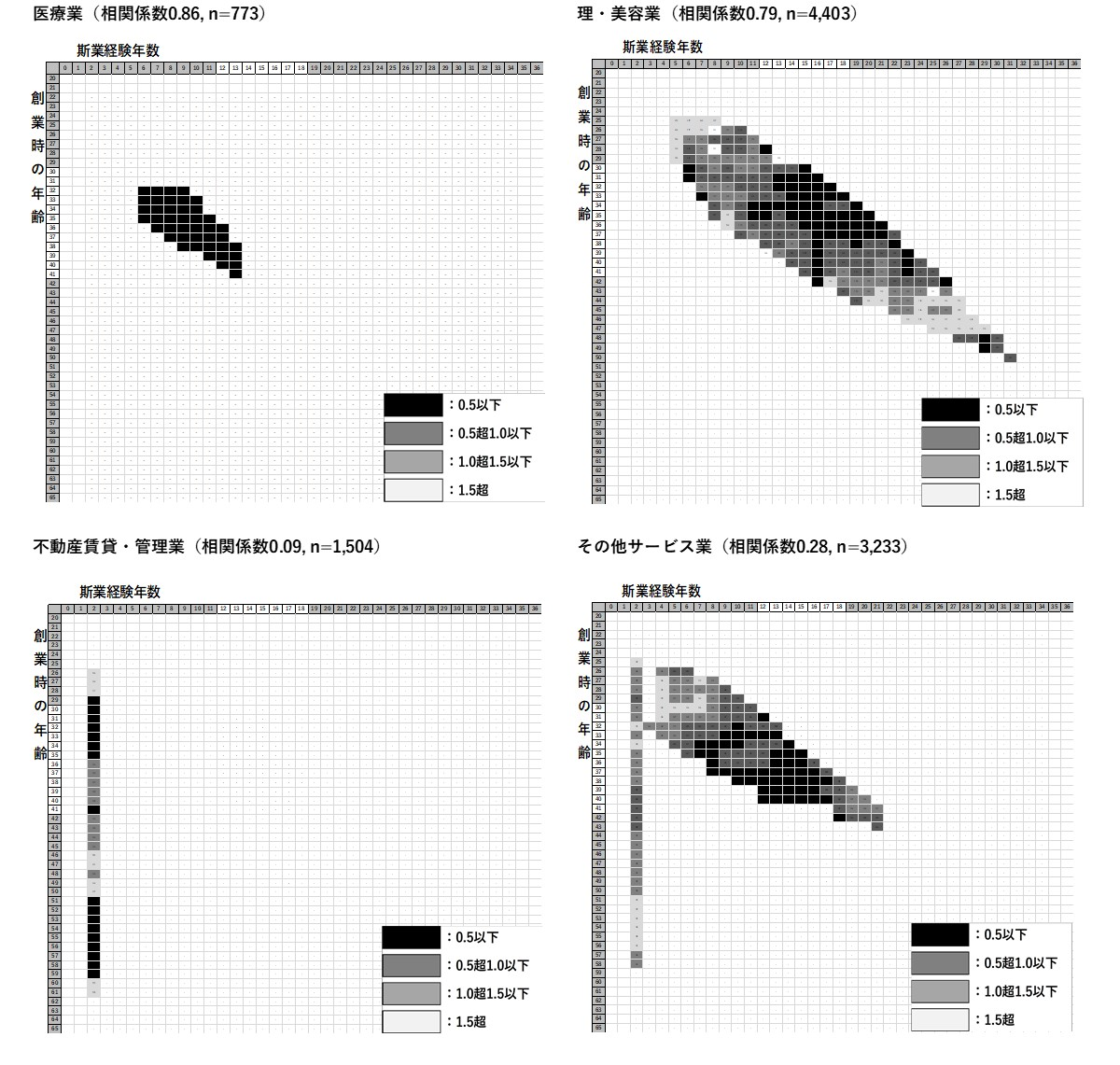
注1 カッコ内は相関係数および企業数.
注2 DB2を使用. データ数が1%以上かつ100件以上となったセルのみ表示.
図8 業種別創業時の年齢と斯業経験年数をクロスしたデフォルト水準(行列5年中心化平均)
(創業時の年齢と斯業経験年数の相関係数上位下位各2業種)
3.3.1項で示したとおり, 医療業や理・美容業といった資格が必要な業種の場合, 必然的にベストなタイミング「旬」で創業する人の割合が高くなり, その結果, デフォルト水準が低くなっていると考えられる. 一方で, 飲食店や小売業のように, 資格が必要ない, もしくは短期間で取得できる業種は, 参入障壁が低く競争が激しいため, 知識や経験が不十分なまま創業して, 激しい競争の中で脱落する企業の割合が高くなり, デフォルト水準も高くなる傾向にある.
ただ, 飲食店や小売業の中にも, 一定の経験を積んで暖簾分けのような形で創業する企業も一定割合存在し, そうした企業群はデフォルト水準が低い可能性がある. 玄田(2001)が指摘している独立開業は, まさに暖簾分けをイメージしていると思われる. 審査員の経験則にも「いつか自分の店を持ちたいという夢を持ちながら, 若い頃から腕を磨き, 店の切り盛りの仕方を覚え, 親方から一人前のお墨付きをもらってから暖簾分けするケースはうまくいく」という飲食店をイメージしたものがある. つまり, 創業を意識しながら必要な知識と経験を積み, 体力のあるうちに計画的に創業する企業は, デフォルト水準が低くなると想定される.
とりわけ, 飲食店は創業企業全体の3割近くを占めているうえ, デフォルト水準が1.56と高い. 創業時の年齢と斯業経験年数の相関は0.27と低い一方で, 暖簾分けによって計画的に創業する企業も多いと言われている. このような飲食店の創業企業は信用リスクが過大評価される可能性があり, 飲食店についてはより詳細な分析が必要と思われる. 創業時の年齢と斯業経験年数をクロスした創業企業のデフォルト水準(行列5年中心化平均)を算出した結果を図9に示す. 対角線上に濃くなっている部分がある. 対角線上の濃い部分にある企業は, 「旬」に創業している企業が多く含まれており, デフォルト水準が低く, 信用リスクが過大評価されている可能性がある.

図9 飲食店の創業時の年齢と斯業経験年数をクロスしたデフォルト水準(行列5年中心化平均)
そこで, デフォルト水準の高い業種グループと低い業種グループに分けて分析することにより, 対角線上にある企業と底辺上の企業とに分けることを考えた. まず, DB1に格納されている飲食店30,009件を12業種(「一般食堂」「日本料理店」「西洋料理店」「中華料理店」「その他の食堂, レストラン」「そば・うどん店」「すし店」「喫茶店」「その他の一般飲食店」「料亭」「バー, キャバレー, ナイトクラブ」「酒場, ビヤホール」)に分け, それぞれの業種別デフォルト水準を算出し, 飲食店全体のデフォルト率を「1.0」として, 「1.0」よりも高い業種に属する企業を「DF水準高」, 低い業種に属する企業を「DF水準低」とした. 次に, DB2の飲食店9,404件のデータを使ってクロス分析した. 結果を図10に示す. 左図はDF水準高, 右図はDF水準低である. 右図をみると, 対角線上が濃くなっており, 創業時の年齢と斯業経験年数との相関が高く, デフォルト水準の低いグループは, 「旬」で創業している企業が多く含まれていることがわかる.

図10 DF水準高低別飲食店の創業時の年齢と斯業経験年数をクロスしたデフォルト水準
(行列5年中心化平均)
次に, 表8のとおり, 飲食店について, 創業時の年齢と斯業経験年数をそれぞれ5年刻みにして飲食店全体のデフォルト率を「1.0」とした業種別デフォルト水準をみてみると, 創業時の年齢は30歳から50歳, 斯業経験年数は11年から25年のゾーンに, デフォルト水準の低い企業が集中していることがわかった.特に濃い網掛けの部分(創業時の年齢30歳~45歳, 斯業経験年数11年~25年)はデフォルト水準が0.5もしくは0.6で, 業種平均のおおむね半分程度の水準であることがわかる. まさに, ベストなタイミング「旬」が存在していることがわかる. つまり, 飲食店の場合は, 学校を卒業してから11年から25年くらい関連した経験を積み, 30歳代もしくは40歳代前半で創業する場合に最も信用リスクが低くなりやすいといえる.

表8 飲食店の「旬」と飲食店デフォルト水準
注1 数値が薄いセルは件数構成比が1%未満.
注2 数値が入っていないセルはNA.
さらに, 表8の網掛け部分を「旬」と定義し, 「旬」で創業しているかどうかのダミー変数の効果を検証する. 具体的には, 機械学習を使って「旬」変数の重要度を確認する. まず, DB2を用いて, 目的変数にデフォルトの有無, 説明変数に「旬」変数を含む89変数を投入してランダムフォレストと勾配ブースティング(XG Boost)により機械学習モデルを構築する. 次に, 変数の重要度を測るFeature Importanceというアルゴリズムを用いて「旬」変数の重要度を確認する. 推計にあたっては, Python scikit-learn を用いる. 結果を図11に示す. 「旬」変数ダミーはランダムフォレストでは67位であったが, 勾配ブースティングでは, 重要度が4位となった. 「旬」変数の重要性を示す結果といえる.
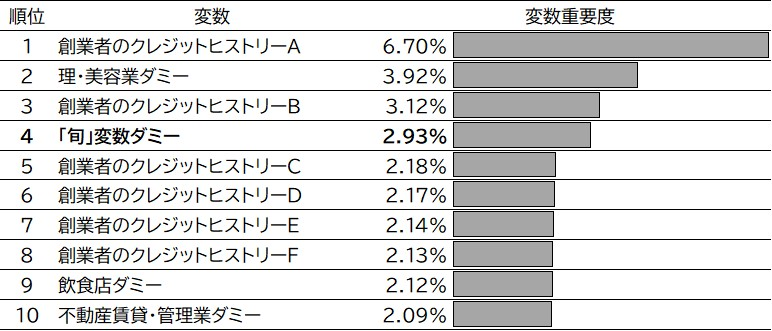
図11 勾配ブースティングにおける「旬」変数の重要度(上位10変数)
これまで見てきたとおり, 「創業時の年齢」は年齢別デフォルト水準を4次関数で定式化でき, 「斯業経験年数」は, 年数別デフォルト水準の2次関数もしくは区分線形関数で定式化できることを確認した. さらに, 創業時の年齢と斯業経験年数をクロスした創業の「旬」についても, 飲食店において, 変数として有効である可能性が高いことがわかった. 本章では, これらの変数を創業企業向け信用リスクモデルに投入し, モデルの変数として説明力があるかどうかを確認する. 同時に, モデルの序列性の精度を示すAR値を先行研究のOUHモデルと比べて, 精度が向上するかどうかを検証する.
4.1 新モデルの構築手順表3に示したとおり, 変数によって使用できるデータベースが異なる. そこで, OUHモデルと同様の手法で三つのモデルを構築する. ただし, 本研究では, 業種別のデータが格納されているDB2を用いて, 飲食店の創業時の年齢と斯業経験年数を利用した創業の「旬」変数の説明力を確認する. そのため, 表3の「モデル構築時に使用するデータ」に示したとおり, モデルの構築にあたっては, DB1に格納されている創業時の年齢と業種別デフォルト水準, 業種ダミーのデータをDB2に統合し, DB2の範囲(期間2017年1月~2019年3月, n=33,550)で使用する.
まず, DB1のクレジットヒストリーと不動産の所有の有無を用いてロジット分析を行い, 分析で有意になった変数を使ってモデル1を構築する. 次に, 創業時の年齢と業種別デフォルト水準, 業種ダミーのデータを加えたDB2を使ってロジット分析を行い, モデル2を構築する. 最後に, モデル1とモデル2の各スコアを変数とするモデル3(最終モデル)を構築する. 具体的には次のとおりそれぞれのモデルを構築する.
(モデル1)DB1が保有する創業企業
| (4.1) |
(モデル2)DB2が保有する創業企業
| (4.2) |
(モデル3)モデル1で算出した
| (4.3) |
それぞれのモデルにおいて推定されたパラメータを用いて計算された
| (4.4) |
ここで,
モデル1の標準化回帰係数とp値を表9に示す. モデル1の変数については, 実務で利用する際の影響を考えて具体的な変数を示すことができないが, 創業者個人の金融機関やクレジットカードなどの利用履歴を示す7つのクレジットヒストリー変数が有意になり, モデル1のAR値は38.2%となった. 2019年4月から9月までに融資した創業企業8,178件のデータを用いてアウトオブサンプルテストした結果は41.2%だった.

表9 モデル1の変数と標準化回帰係数およびp値
モデル2は, 斯業経験年数に2次関数を採用するケースと区分線形関数を採用するケースを示す. その前に区分線形関数のボトム(交点)の斯業経験年数
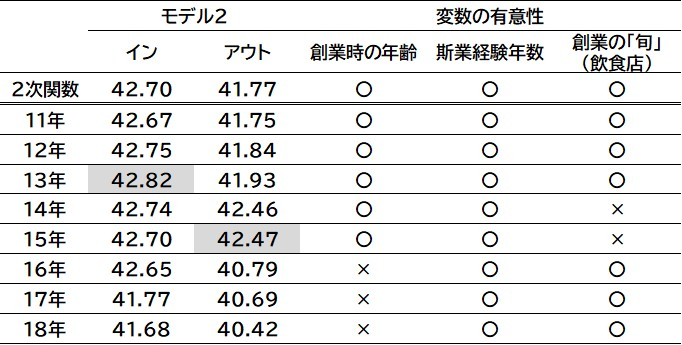
表10 2次関数および区分線形関数のAR値
注:網掛けは最大値.
結果をみると, 2次関数のAR値は, インサンプルが42.70%, アウトオブサンプルが41.77%となった. 次に, 区分線形関数のAR値をみると, ボトム
創業時の年齢と創業の「旬」(飲食店)ダミーの有意性をみると,
この点について, さらに詳しく分析するために, 2次関数, すべての変数が有意になった
2次関数と
以上のように, 斯業経験年数の区分線形関数は, ボトム(交点)

表11 モデル2の変数と標準化回帰係数およびp値, 統合モデルのAR値
注1 nglは, neglog変換.
注2 「-」は非有意.
統合モデルのパフォーマンスは, 表3のモデル構築時に使用するデータのDB2を用いて検証する. 具体的には, 33,550件のデータを用いてモデル1のスコアとモデル2のスコアを算出し, それぞれのスコアを変数として構築したロジスティック回帰モデル(モデル3:統合モデル)の標準化回帰係数と p値およびAR値を算出する. 結果を表12に示す. 統合モデルのAR値をみると, 2次関数のインサンプルが53.7%, アウトオブサンプルが54.4%となった. 区分線形関数は, インサンプルは
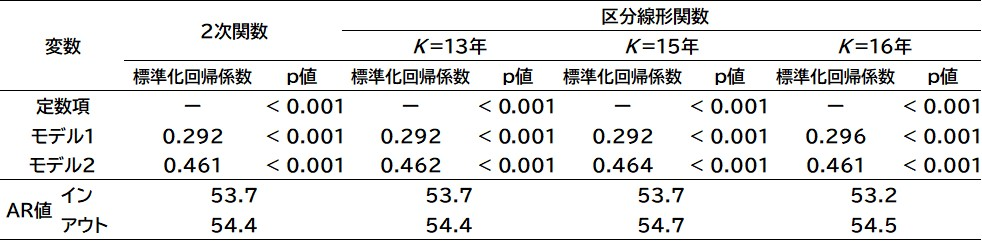
表12 統合モデルの標準化回帰係数とp値およびAR値

表13 OUHモデルとのAR値の比較
最後に, 「旬」変数の効果について確認する. 前述のとおり, 飲食店における創業の「旬」ダミーは, 斯業経験年数の区分線形関数のボトム

表14 創業の「旬」変数導入による飲食店のAR値(モデル2)
さらに, 「旬」変数を投入することによって飲食店の格付構成がどのように変化するのかを確認することでリスクの過大評価が修正されているかを検証する. まず, 飲食店のデータを用いて「旬」変数を投入したモデルを構築する. 次に, 「旬」変数を除いて信用スコアを算出し, スコアの高い順から25%ずつ1格から4格の4つに格付けし, 閾値となる信用スコアを算出する. 最後に, 「旬」変数を加えた信用スコアを算出し, 「旬」変数を除いた際の閾値をもとに格付けを振りなおす. これを, さきほどと同様に, 創業の「旬」が有意になった2次関数と区分線形関数(ボトム

表15 創業の「旬」変数の導入による飲食店の格付構成の変化
信用リスクの低い1格の構成比をみると, 2次関数では4.4%ポイント, 区分線形関数ではボトム
構成比の変化を比較すると, 区分線形関数に比べて2次関数の方が高くなっている. また, 創業の「旬」が非有意となった区分線形関数のボトム
本研究と国内の主な先行研究の違いをまとめると表16のとおりである. 本研究の特徴は, ①創業時の年齢と斯業経験年数について, 非線形の関係を分析している点, ②創業時の年齢と斯業経験年数をクロスした部分の企業数が構成比で1%以上かつ100件以上存在し, デフォルト率の水準が全体もしくは業種平均のおおむね半分以下になるタイミングを創業の「旬」と定義し, その存在について分析している点, ③創業時の年齢および斯業経験年数, 創業の「旬」について, 信用リスクモデルを構築して変数の説明力とパフォーマンスを評価している点にある.
創業時の年齢および斯業経験年数, 創業の「旬」と創業後のパフォーマンスの関係に関する国内の主な先行研究との比較における本研究の貢献は以下のとおりである.

表16 本研究と主な先行研究の分析結果の比較
本研究では, 創業時の年齢と斯業経験年数に着目し, 日本公庫が融資した約11万件の創業企業のデータを用いて, デフォルトとの関係を詳細に分析し, 非線形関数を使った定式化を試みた. さらに, 「創業時の年齢と斯業経験年数を用いて定義した創業の「旬」が存在するかどうかを確認するために, これらの変数をモデルに投入し, 変数の説明力の有無とモデルの精度向上について検証した. 分析の主な結果をまとめると以下のとおりである.
実務で利用するために, 詳細な説明変数を示すことはできなかったが, 創業時の年齢および斯業経験年数, 創業の「旬」については, 先行研究だけではなく審査員の経験則ともおおむね整合的な結果となり, 現場にも納得感のある説明変数でモデルが構築できた. 今後の課題として, 以下の4点について研究を進める予定である.
1 「創業」の同意語に「開業」や「起業」などがあるが, 混乱を避けるために, 本論文では可能な限り「創業」に統一している. 創業企業の定義は必ずしも明確ではないが, 本研究では中小企業庁「中小企業の新たな事業活動の促進に関する法律」に従い,「創業者とは新たに事業を開始する具体的な計画を有するもの」とし, 創業後の企業は含めず, 創業する前の企業と定義する.
2 斯業経験とは, 創業しようと考えている業種での経験で, 具体的には, 知識, 技術, ノウハウ, 人脈, マネジメントなど, 事業を軌道に乗せるために必要な経験を示す. 先行研究では, 「同じ仕事に従事した経験」「同業種での経験」など, さまざまな表記がされているが, 本研究ではそれらも斯業経験として扱っている.
3 AR値の概要については, 山下・三浦(2011)『信用リスクモデルの予測精度-AR値と評価指標-』(朝倉書店)を参照してほしい.
4 OUHモデルのデフォルト率は, t年度に融資した企業のうち, t+1年度中に破綻懸念先以下に遷移した企業の割合で, デフォルトの観測期間は融資後平均1.5年であるのに対して, 本研究の観測期間は融資後2年である. AR値は, 観測期間の短い方が高くなりやすい点に注意してほしい.
5 図6のように, ボトムがゼロに近くなければ,