Evolution of Generative AI and Emerging Content Economy
2023 Volume 7 Issue 1 Pages 25-51
Details
2023 Volume 7 Issue 1 Pages 25-51
生成AIの技術進化が2022年から急激に加速し、ユーザーを取り込んだ新たなコンテンツ経済圏が形成されようとしている。2014年に発明されたGAN(生成的敵対ネットワーク)という技術により、人が区別できないほど精巧な画像が自動生成されるようになった。さらに、2016年、データを高度に抽象化する深層学習技術、トランスフォーマーが登場した。これは「データを与えさえすれば機械が自動学習する」という教師なし学習の大きなブレークスルーとなった。そして2022年、ChatGPTに代表されるコンテンツを自動生成する技術が登場し、多様なメディアを対象として急速に進化しようとしている。深層学習の進化、音声や画像認識の実用化、そしてこれらの技術組み合わせることで、従来人間が行っていた文章の執筆、絵の描画、楽曲の制作、動画の撮影や編集といったクリエイティブな作業がAIによって置き換えられる時代が到来した。コンテンツ制作の主体がプロのクリエーターから一般の人々へと移行する可能性が出てきた。従来のクリエーター中心の視点から、ユーザー中心の視点へのコンテンツ経済圏のシフトが予見される。
AIが作成したコンテンツをAIGC(AI Generated Content)と呼ぶ。それがどのような経済圏を作るかを議論したい。脚本の生成や俳優の演技のデジタル複製・変更が簡単に行えるようになり、これが脚本家や俳優の役割や権利への影響をもたらすことが予想される。このような変化は、クリエーターとして知られる脚本家、アニメーター、俳優などの様々な分野の専門家たちの生態系に大きな変動を引き起こす可能性がある。日本には、ポケモンに代表されるキャラクターコンテンツを中心とした世界的に成功を収めているメディアフランチャイズ事業や、ユーザー主導でのコンテンツの流通を特徴とするコミュニケーションマーケットなどの独自の文化が存在する。その代表例として初音ミクを取り上げる。デジタル技術の進化、ユーザーの積極的な参加、ファンの熱狂、そして柔軟な著作権管理を組み合わせたビジネスモデルが、日本において生成AIを効果的にビジネスに取り入れるための良い土壌を形成している。今後、ソーシャルメディアと生成AIの組み合わせによって、ユーザー生成コンテンツ(UGC)がAIGCと一体化し、世界的に広がっていくことが期待される。一方で、生成AIの技術の利用には、著作権法の問題や倫理的な課題など、様々な問題が伴う。特に、人間の感性や独自性を持つコンテンツの生成に関しては、AIとのバランスをどのように取るかが重要となる。生成AI技術と人間のクリエーターが対立するのではなく、互いに共存し、新しい形のコンテンツを共に生み出すことが、今後のコンテンツ産業の発展の鍵となる。
The technological evolution of generative AI has accelerated rapidly since 2022, paving the way for a new content economy that engages users. The emergence of deep learning techniques in 2016, specifically the Transformer, heralded advancements in unsupervised learning where machines learn automatically when provided with data. Represented by the advent of ChatGPT in 2022, technologies that auto-generate new content are on the brink of rapid evolution across diverse media. The advancements in deep learning, practical applications of speech and image recognition, and the integration of these technologies signify an era where creative tasks traditionally performed by humans, such as writing, drawing, music composition, filming, and editing, are being replaced by AI. This shift suggests a potential transition in content creation from professional creators to the general public, foreseeing a shift in the content economy from a creator-centric to a user-centric perspective.
Content created by AI is termed AIGC (AI Generated Content). It's crucial to discuss the kind of ecosystem this will create. AIGC could potentially disrupt the ecosystems of professionals known as creators, including scriptwriters, animators, actors, and more. Japan boasts unique cultures, such as globally successful media franchises centered around character content like Pokémon and user-driven content distribution markets. Hatsune Miku serves as a prime example. The combination of digital technology advancements, active user participation, fan enthusiasm, and flexible copyright management has created a fertile ground for integrating generative AI effectively into Japanese businesses. It's anticipated that the fusion of social media and generative AI will lead to the integration of User Generated Content with AIGC, expanding globally. However, the use of generative AI technology comes with various challenges, including copyright issues and ethical dilemmas. Instead of generative AI technology and human creators being at odds, their coexistence and collaborative creation of new content forms will be key to the future growth of the content industry.
2023年初夏に始まった全米脚本家組合および映画およびテレビ俳優の労働組合のストライキ[1]は人工知能(AI)の進化によって変わる生態系の変化を象徴している。もちろん、これらのストライキは、生成AIの脅威に対抗することだけが主旨ではない。映画やテレビ業界は、近年のストリーミングサービスの利用を加速させている。映画やドラマの制作・配信方法が大きく変わり、脚本家や俳優の報酬体系や雇用の安定性に問題が生じている。特に、配信限定の作品は再放送やコンテンツ販売の利益を再配分しないため、脚本家、俳優たちの収入機会を損なっている可能性がある。そして、もう一つの視点として、AIによるコンテンツ制作の効率化が挙げられる。AIの進化により、脚本の生成や俳優の演技のデジタル複製・変更が可能となりつつある。これにより、脚本家や俳優の役割が脅かされ、その待遇や権利に対する懸念が高まっている。様々な娯楽やアートの分野で創作活動を行う人々を「クリエーター」と呼ぶことにする。クリエーターの仕事には、文章の執筆、絵の描画、楽曲の制作、動画の撮影や編集があるが、今後、数年内に、彼らの仕事内容が大きく変わらざるを得なくなるであろう。娯楽やアートの配信プラットフォームの変化[2]と、ソーシャルメディアとAIによる高品質なユーザー生成コンテンツ(UGC)[3]の登場によりクリエーターの生態系が大きく変化することになる。ここに生じる軋轢を社会が受容しながら、時間をかけて新しいコンテンツ経済圏が登場することになる。背景となるのは、2022年から始まった生成AI[4]の急速な進展だ。ChatGPT(チャットジーピーティー)[5]に代表される生成AIと呼ばれる、文章や画像を自動生成するAIにより作られるコンテンツをAIGC(AI Generated Content)と略す。生成AIにより、コンテンツ提供者が、高度に訓練されたクリエーターから、市井の人々(ユーザー)に変わりつつある。そのユーザー作成コンテンツはUGC(User Generated Content)と呼ばれ、AI時代はAIGCとUGCが同一化して見られている。そこに問われる創造性は、画才や演奏力などの従来の提供者側の視点ではなく、芸術を鑑賞する目利き力や、文章の表現力などのユーザー側の視点になる。ユーザー参加なしに、次のコンテンツはない。これまでの2年間で起きている技術環境変化とこれから2年間で起こりえる事業環境変化を、生成AIの技術発展(2章)、メディアフランチャイズと影響を受けるコンテンツ経済圏(3章)、AIGCの新経済圏と権利処理の解釈(4章)で見ていく。
生成AIは、2022年以降のAI技術の進化の中で特に注目されるようになった分野である。それまでのAIは、定型化された作業の自動化やデータの整理・分類を主な目的としていたが、生成AIはその枠組みを超え、データのパターンや関係を学習して新しいコンテンツを創出することが新しい。
深層学習(ディープニューラルネットワーク、DNN)は多層のニューラルネットワークを使用して複雑なタスクを学習する能力を持つようになった。図1に2010年以降の歴史を示す。最初の実用化は2011年ごろの音声認識である。それまでサイエンスフィクションに出ていた「コンピュータとの対話」が現実になったのはこの頃である。多層畳み込みネットワーク(多層CNN)の登場により、画像認識の精度が大幅に向上した[6]。今では空港で顔認証に使われている画像認識であるが、実用化になったのは数年前のことだ。CNNは、画像の局所的な特徴を捉える能力を持ち、多くの画像認識タスクで高い性能を示した。同じ時期2014年に、GAN(生成的敵対ネットワーク)が提案された[7]。GANは新しいデータを生成するための技術として登場している。これにより、高品質な画像や音声の生成が可能で、生成AIの幕開けとなった。一方、時系列データの処理には、LSTM[8]が使用されるようになった。これにより、音声やテキストのような連続的なデータの処理が向上した。加えて、Attention(注視機構)と呼ばれるデータ相関の重要度を動的に重み付けする技術との組み合わせが機械翻訳の本命技術とみなされるようになったのが2014年ごろである。Attentionは特に系列データの処理において、入力データの特定の部分に焦点を当てることで、モデルの性能を向上させることができる。Attentionは、元々機械翻訳タスクにおいて、ソース文とターゲット文の間の関連性を捉えるために導入された2。2016年、自然言語処理(NLP)は、Attentionの多層・多重的な組み合わせで大発展した。それがTransformer[9]である。これにより、機械翻訳の精度が大幅に向上することになる。Transformerの中心的な要素であるAttentionは、入力データの異なる部分に「注意」を向けるメカニズムである。具体的には、シーケンス内の各単語やトークン3が他の全てのトークンとどれだけ関連しているかを評価し、その関連性に基づいて新しい表現を生成する。例を挙げると、文章の中で「彼」という単語が出てきた場合、Attentionメカニズムは「彼」が指す実体や内容に関連する他の単語や情報に「注意」を向ける。これにより、文脈を考慮した情報の抽出や表現が可能となる。このAttentionの仕組みは、長文において、各トークン間の関連性や依存関係を捉えるのに非常に効果的である。Transformerは、このAttentionメカニズムを複数重ねることで、より複雑な関連性やパターンを捉えることができる。そして、それが事前学習(Pre-Training)という大発展につながる[10]。Pre-Training の手法は、大量のデータでモデルを事前学習し、特定のタスクに個別チューニングを行う方法の基礎として注目された。これにより、少ないデータで異なるタスクにも高い性能を達成することができるようになった。NLPにおける発展系がChatGPT[11]である。この大規模言語モデル(Large Language Model, LLM)が登場し、より自然な文章の生成や、高度な質問応答タスクが可能となり、さらに画像生成技術と結合することによりAIGC技術が急速に立ち上がった。技術の萌芽は2014年ごろであり、コンテンツ経済圏に影響をもたらす状況になったのは、2022年と言える。

AIGCの説明に入る前にまず、自然言語処理(NLP)を説明する。連続するN個のアイテム(通常は文字や単語)の列を表す統計モデルとしてN-Gram[12]がある。大規模言語モデルにより、文脈を反映して可能になったとはいえ、そもそも、言語モデルとは文字の連続から次の文字、あるいは欠落した文字を予測する確率過程を表したものである。テキストの生成や文章の補完などのタスクにも使用される。例えば、ユーザーが文章の途中まで入力すると、モデルはそれを元に文章を完成させる使い方は正しい。また翻訳に用いることも言語モデルの使い方として正しい。規模が大きくなったとはいえ、与えられた文章に対してもっともらしい文章を紡いでいく機械にすぎない。したがって、大規模言語モデルに問い合わせを入力して、その答えが合っていた、間違っていたというのは、見当違いな使い方だ。
ただ、Transformerという文字、単語、文章の相関関係をモデル化できる技術が登場したことにより飛躍的に予測効率が向上した。そのために膨大な文章を入力とすることから、知識ベースとしての機能が期待されるようになった。知識ベースとしての有用性が認められるようになったのがGPT-3だろう。GPT-3により、大規模言語モデルは、ユーザーの質問に答えるためのツールとして使用される。これにより、ユーザーは特定のトピックや情報に関する質問を簡単に行うことができる。企業や組織では、顧客サポートや質問・応答の自動生成などのタスクにも利用される。これにより、顧客の問い合わせに迅速に対応することができる。またプログラミングに利用できることも知られるようになった。
大規模言語モデルの解説論文として文献[13]を取り上げる。ここに引用されている大規模現モデルの中で代表的なモデルを
表1に示す。これらのモデルは、数十億から数兆のパラメータを持つことで知られている。オープンソースのライセンス条件に注目したい。Googleが開発したT5は、多言語タスクに対応したトランスフォーマーベースのモデルであり、Apache-2.0ライセンスで公開された。Galacticaは著作物再利用の促進を目的とした国際的非営利団体であるクリエイティブ・コモンズが定めるCC-BY-NC-4.04で公開されている。これは著作者情報を表示する必要があり、利用は非営利に限られる。
Llama[14]は2023年2月にMetaの研究機関がリリースした。パラメータ数は70億、130億、330億、650億のモデルが存在する。ソースコードが公開されているが、Llamaのライセンスは非商用利用に限定されている。理由は、InstructGPTのように人間のフィードバックによる訓練をされておらず、誤った回答や攻撃的なコンテンツを生成するリスクがあると言われている。Metaは、2023年7月に Llama2[15]を公開した。このモデルを基盤として、コードに特化したデータセットで追加訓練を行った結果、新たなモデル「Code Llama」も開発されている。Code Llamaは、Python、C++、Java、PHP、JavaScript、Typescript、C#、Bashなどの主要なプログラミング言語に対応している。提供されるモデルのサイズは3種類あり、1つのGPUで実行できる7B、13B、コーディング支援が可能な34Bのモデルがある。加えて、Pythonに特化した「Code Llama - Python」と、人間の自然言語入力に対する理解を深める「Code Llama - Instruct」の2つのファインチューニングモデルも提供されている。
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/7_25_10.png%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
GPT-3.5世代の言語モデルは、2022年11月以降に登場し、GPT-3を主なベンチマークにしているが、その開放性に関して、
大規模言語モデルの利用には以下の3形態が考えられる5。
上記の真のオープンな言語モデルは3の利用形態だろう。1と2の利用者にとっては、ソースコード非開放でも、1と2で得られたAI成果物が商用に利用できるかどうかが課題となる6。そこでは、商用利用の可否と利用条件及び制限事項に注意する必要がある。OpenAI社の利用規約によれば、サービスから得られる出力に関する知的財産権はユーザーに帰属し、商用利用を含むあらゆる目的での利用が許可されている。したがって、OpenAI社のサービス、例えばChatGPTの出力は、商用利用が認められている。利用規約には、サービスの使用に関する制限事項が明記されている。具体的には、他人の権利を侵害する方法でのサービス利用、モデルのソースコードの取得、出力を人間が作成したものとして表現することなどが禁止されている。また、個人データをサービスで処理する場合、ユーザーは法的に適切なプライバシー通知を提供し、データ処理に関する同意を取得し、関連する法規に従ってデータを処理していることをOpenAI社に通知する必要がある。このようなガイドラインは、他社の大規模言語モデルによるWebサービス提供者と共通するものである。
大規模言語モデル(LLM)の構築において、データの収集は極めて重要である。以下に、各データソースの特性とその応用、課題についてまとめる。
以上のデータソースは、LLMの一般的な言語モデリング能力と特定のタスク解決能力の両方を向上させるための基盤となっている。これにより、LLMは知識ベースとして、翻訳機として、プログラミング支援ツールとして動作する。GPT-3も当初は、Webページデータからなる対話システムであったが、GPT-4になりプログラミングにも利用されるようになっている[17] 。

これだけのデータを集める際に、訓練データとして使用されるテキストには、二次利用を許さないとするコンテンツ、個人情報や機密情報、公序良俗に反するコンテンツの混入が避けられない[18]。したがって、データの収集と前処理の段階で、プライバシーに関する厳格なガイドラインとフィルタリングプロセスを適用することが不可欠となる。
図3にChatGPTのチューニング構造8を示す。OpenAIの言語モデル、GPT-3からGPT-3.5、そしてその後のChatGPTへの急速な進化は、特に人のフィードバックからの強化学習(RLHF)[19]によるモデルのトレーニング手法の進歩によって支えられている。2022年1月には、OpenAIはGPT-3.5としても知られるInstructGPTを導入した。この上で、2022年11月には、短期間で驚異的なユーザーベースを築いた対話中心のモデル、ChatGPTが外部提供された。文章の生成モデルを対話モデルに大転換させることに成功したのは、人間がモデル出力を教導するRLHFの適用である。さらにRLHFは対話性能を向上させるばかりか、厳格なガイドラインに従い、有害または不適切なコンテンツを生成するリスクを減少させる。RLHFの導入はNLP分野で2022年の最大貢献の一つと言えよう。

画像認識は自然言語処理と独立した研究分野として、ここ50年進化してきたが、2015年ごろから、急速に統合処理の研究対象となるようになった。図4に画像認識(CV)、自然言語処理(NLP)、画像言語処理(VL)から見た生成AIの歴史[5]を示す。
画像認識[20]は、画像処理の中で、画像の意味を理解することを目標とした研究分野である。猫の画像をコンピュータに入力して、「猫」という言葉を出力させる技術を開発することであるが、GAN[7]の登場から、「猫」という言葉から猫の画像を生成する画像生成という研究分野と統合されて研究されるようになった。GANは、生成器と判定器の2つの部分から成り立っている。生成器は、実例から虚例を生成することを試み、判定器は、入力が実例かどうかを判断する。異なる深層学習の2つのモデルで、片方が騙す、片方が真贋を見極めるという競争により、画像を生成するというもので、その印象的な結果のために、生成AIのマイルストーンとなった10。Progressive GAN[21]やStyleGAN[22]などのGANの後継技術は、さらに性能を向上させている。
GANに加えて画像生成AIの主要構成画像処理技術として変分オートエンコーダ(VAE)[23]と拡散モデル[24]がある。
VAEは、データを低次元の確率的な分布に反映させ、元の入力に近い再構成を学習する試みとして提案された生成モデルである。VAEの発展として、DiffuseVAE[25]のような統合モデルが、VAEの能力をさらに拡張するための技術として提案されている。拡散モデルにはDenoising Diffusion Generative Model(DDPM)[26]がある。DDPMはノイズを徐々に追加し、その後徐々に除去するというプロセスを使用しているが、考え方は、データ分布の勾配を直接推定して、あるべき画像を自動生成するというスコアベースの生成モデル[24]と考え方は同じである。

さて、ここで、画像生成モデルに大きな飛躍をもたらせたのは、画像言語処理(VL:Vision and Language)という画像と言語の情報を同時に扱う研究分野であり、2019年を境に急速な進展が見られる。この背景には、上記のVAEと拡散モデルの登場、そして、NLPに革新をもたらしたTransformerの画像分野への適応である。
以下にVLの代表的な事例を列挙する。

生成AIの内部で何が起きているのかを直観的に理解するために、機械翻訳のアナロジーを使う。図5は、機械翻訳の理想を示すために1960年代に書かれた三角形のモデル[30]である。これを用いて、2020年前後に起きたことを説明したい。左下の入力“Language is a means of communication.”を日本語に翻訳する際、Transformer 出現以前は、単語を分割し、対応する日本語に変換し並び替えるという表象的な言葉区切りの対応関係を統計的に行なっていた。Transformer出現以降は、深層学習により意味に相当する特徴ベクトルに変換され、意味から文章が生成され、翻訳されるようになった。三角形上位にある文章や意味は深層学習の特徴ベクトルとして表現される。BERTや2016年の機械翻訳は一文の特徴ベクトルの対応レベルであるが、GPT-3以降は文脈を反映していることから最上位の意味の特徴レベルに近づいた抽象化が行われている(図5中の赤い経路)。ChatGPTでは日本語の問い合わせに英語や中国語で応答することができるが、これは、知識処理が各言語で行われて、翻訳されているのではなく、抽象化された知識で翻案されたものが、必要な言語で具象化されているにすぎない11。
同様に、画像生成ではVAEが画像の抽象化を行っており、VisualBERTやCLIPが行なっているのは、文章+画像の同時抽象化である。画像生成では、抽象化された特徴ベクトルにノイズ付加するなどの学習処理の汎化に工夫が必要となるが、本質的に抽象化と具象化を扱うフレームワークは同じである。AIのモデルは図5の特徴ベクトルから学習される重みづけで構成されるが、そこには原文、原画像の直接的な表現はない。AIが古典的なk近傍法[31]を使わない限りは、元データがモデルに含まれることはない。2016年頃では機械翻訳で英語から日本語への変換レベルだったAI技術が、2023年頃に文章から画像への変換、文章から楽音への変換を行うようになったと言える。
2.3.AIGC技術生成AIの産業化はMcKinseyのレポート[32]によれば小売と消費財産業、創薬、医療製品産業、銀行におけるマーケティング、R&D、基幹システムの置換に数%の効率化インパクトがあると述べられている。一方で、大企業から市井の人々まで、生成AIを手に入れたことより、プ2022年以降に急速にプロフェッショナル生成コンテンツ(PGC)とユーザー生成コンテンツ(UGC)がAIGCで占められるようになっている[33]。これには、AIによる絵画、AIによる執筆、AIによる音楽作曲、AIによるビデオ生成、AIによる音声合成、AIによるプログラミングなどが含まれている。前記した生成AIの技術により、デジタルコンテンツの新しい形態の生成とインタラクションを生み出している。市場調査会社Precedence Researchのデータによれば、2022年の全世界のAIGC市場の規模は16兆円であり、2030年までに106兆円に達すると予想されている12。

文献[5]に登場するAIGCを開発者、サービス名(モデル名)、応用分野を図6に整理した。主要開発者が米国に集中していることがわかる13。
これらの技術の中で、MidjourneyとStable Diffusionを代表サービスとして比較した(表2)。MidjourneyはWebサービスとして提供されていて、ソースコード、生成モデルのデータは公開されていない。最新版の利用規約14によれば、生成した画像の商用利用は可能である。ただし、有料会員でない場合の画像はCC BY-NC 4.015となり商用利用できない。また、年間100万ドル以上の収入のある企業による商用利用は、高額プランに加入する必要がある。非常に微妙な権利処理となっている。想定ユーザーは画像生成を趣味とする一般ユーザーと予想される。
一方で Stable Diffusionを見てみよう。開発者であるStable.aiは自ら、dream studioというWebサービスを提供しているが、そのサービスの元になった画像生成AI技術をオープンソースで公開している。そのモデルも公開しており、急速にその派生技術が進化している。Stable Diffusionの商用利用16についての制約が、後述のAIGCがもたらす新経済圏を象徴していて興味深い。まず、Stable DiffusionはCreativeML OpenRAILライセンス17で提供されている。生成した画像に対する開発者の権利は主張されず、ユーザーが自由に使用できる。ただし、法律に違反する内容や人に危害を与える内容など、ライセンスで定められた規定に反する使用は禁止されている。商用利用が認められているが、以下の2つのケースでは商用利用が制約されている。
LoRAはLow-Rank Adaptationの略でStable Diffusionモデルの最も重要な部分であるクロスアテンション層に微小な変更を適用することで動作する。この部分は、画像とプロンプトが交差する部分であり、このセクションの微調整が優れたトレーニング結果をもたらす[35]。 LoRAモデルは、Civitai18やHuggingFace19などの様々な場所で見つけることができる。特にCivitaiはLoRAモデルの大規模コレクションとして、キャラクターLoRA、スタイルLoRA、コンセプトLoRA、ポーズLoRA、衣服LoRA、オブジェクトLoRAなどがあり、学習済みモデルへの差分ファイルとしてダウンロードできる。
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/7_25_11.png%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
Stable Diffusionは50億以上の画像とテキストのペアを含む「LAION-5B」というデータセットを使用している。LAION-5Bは、ドイツの非営利団体Large-scale Artificial Intelligence Open Network(LAION)20によって2022年3月に研究用としてリリースされた。このデータセットは、58億5000万の画像とテキストのペアで構成されており、多言語のデータが含まれている。LAIONは、インターネット上のデータを解析し、前述したCLIPを用いて類似性の高い画像とテキストのペアを抽出している。このデータには原著者から著作権が主張されるものと個人情報が含まれている可能性がある。Stable Diffusionはオープンソースである、元の配布された画像生成モデルに個人、個社で追加学習を行うことができる。その上で、LoRAモデルという軽量な追加学習モデルが加わるので、強力な画像生成経済圏が構築されている。Civitaiのサイトを訪れればそれが確認できる。以上のデータの流れを図7に整理した。
Stable Diffusion は、生データをLAION-5B、学習用データをStable.aiが用いたデータ、学習用プログラムをStable Diffusionの学習器、学習済みモデルを流通しているCheckpoint21、楕円内学習済みモデルをLoRA、AI直接生成物をLoRAで作成された画像として理解すると良い。これは開発者側から見れば、楽園のような世界だ。一般的にAIの開発は、商用可能なライセンス条件の下で、ソースコードの公開だけでなく相互運用可能なモデルが流通することが理想となる。Stable Diffusionの世界ではそれが実現されている。一方で、大規模言語モデルでは、Stable Diffusionのような開発者から見た理想郷は実現されていない。倫理的ガバナンスが必要であること、技術的には、学習、推論時の計算資源が膨大で図6に登場する巨大プラットフォーマーしか追加学習ができないことが原因である22。
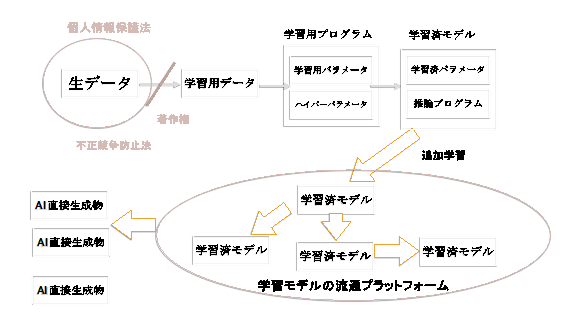
AIGCの技術進展が2022年以降、急速に加速したことを前章で説明した。本章では、それによって影響を受けるコンテンツ経済圏に話を移す。既存のメディアフランチャイズ23の経済圏にどうAIGCがインパクトを与えるかを見ていこう。メディアフランチャイズは小説、映画、マンガ、アニメ、コンピュータゲームなどのエンターテインメント分野において、ある商業作品が市場を持つ際に、その作品から派生した商品を多数の娯楽メディアを通じて製作する手法として知られている。この手法は、キャラクターや著作権といった知的財産(IP)を中心に、様々なメディアや企業を超えて活用する特性を持つため、「IPコンテンツ」や「IPもの」と業界用語で呼ばれることもある。この分野で日本は健闘している。次に、そのゆりかごとしてのコミックマーケットのゆるい権利処理について述べる。そして、技術とゆるい権利処理の組合せによる成功例として初音ミクを議論する。
3.1.日本のメディア・フランチャイズ日本は数多くのメディアフランチャイズを生み出してきた国である。これらのフランチャイズは、アニメ、マンガ、ビデオゲーム、映画、そしてその他のメディアフォーマットを含む幅広いカテゴリーに跨るものである。特に、ポケットモンスターやモンスターストライクのようなフランチャイズは、国内外での成功を収めており、それらは商品販売やゲームの売り上げなど、多岐にわたる収益源からの利益を上げている。日本のメディアフランチャイズは、その独自の文化とクリエイティブなアイディアにより、世界中の多くのファンを魅了してきた。
ウィキペディア24にあるメディアフランチャイズの2023年8月における累積売り上げを図8のグラフにした。ディズニーはミッキーマウス、プーさん、スター・ウォーズ、ディズニープリンセス、ライオンキングなどのフランチャイズによる強力な存在感はあるが、総売上のトップフランチャイズはポケモンであり為替レートで上下するが1.5兆円を超える。それにハローキティ、マリオ、アンパンマン、ドラコンボール、トランスフォーマー、ガンダムが上位に入っている。フランチャイズの収益は長寿であることと、地域でヒットし、グローバルに展開することが重要である。主なソースは、商品販売、興行収入、ビデオゲームの売上、ホームエンターテインメントの組み合わせとなっている。

コミックマーケット(通称コミケ)は、1975年に始まった世界最大の同人誌即売会である。年2回、夏と冬に開催され、出展者や参加者の数は年々増加している。このイベントは、多くの出展者が経済的利益を追求するのではなく、自分の作品を表現・共有する場として存在している。
コミケは、二次創作の最大の市場として知られる。その会場において、オリジナルの作品と二次創作が頒布される中、約7〜8割の出店者が二次創作に従事しているとの報告がある[36]。コミケの人気が増大するにつれ、著作権の問題が焦点となってきた。特に、既存作品をベースにした同人誌の販売は、翻案権や同一性保持権のような著作権を侵害するリスクが指摘されている。翻案権は、オリジナル作品のアレンジを行う権利で、原著作者のみがその権利を持っている。一方、同一性保持権は、作品のキャラクターやストーリーを変更することを制限する著作権の一部として存在する。これらの権利が侵された場合、原著作者は該当の同人誌の販売停止を要求できる。
著作権侵害に関して、二次創作は親告罪の対象となるため、被害者が告訴しない限り、法的手段が取られることは少ない。事実、多くの二次創作が市場に出回っており、特に悪質と判断されるケース以外では、多くの著作権者がこれを容認しているとされる。コミケは、表現の自由の場としての役割を果たし続けており、原著作者が少数の売り上げを得るクリエーターを訴えることは稀である。メディアフランチャイズの視点から見れば、コミケにおける二次創作の黙認は、ファン層の拡大や商品の売上げ向上の機会として捉えられている。「コミケは我が国が世界に誇るコンテンツのゆりかごの役割を果たしている」、「作品の受け手が送り手に容易に変わり得る、それが入れ替わり続けることで多様性と創作の再生産を可能にしている」という指摘[37]がある。
コミケの位置付けは、日本の特有な二次創作文化として重要であり、これは新しい技術、例えば画像生成AIによるUGCという文化との親和性が高い。
3.3.初音ミクに見る経済圏の構成要素初音ミク(Hatsune Miku)は、クリプトン・フューチャー・メディアが(CFM)発売しているバーチャル・シンガーソフトウェアのキャラクターであり、"電子の歌姫"として知られている。彼女は「ボカロ」という文化・ジャンルを築き上げ、ネット上の文化や音楽シーンに大きな影響を与えた。日本史の教材では、初音ミクは「現代のIT技術が生み出した新たな文化の象徴的存在」として評価されている。初音ミクは音声合成ソフトを超えて多くのクリエーターによって様々な創作活動が行われ、"初音ミク現象"として知られるムーブメントを起こしている。3DCGライブ、ゲーム、フィギュアなどでメディアフランチャイズ事業が成立している。初音ミクはUGCによって成立していると言え、CFMが発行したライセンスに基づいて無償の二次創作活動が許可されている。
これまでの議論を元に、ユーザー生成コンテンツとメディアフランチャイズの関係を図9に整理した。これの構成要素を以下に列挙することで初音ミクを理解したい。
初音ミクは、情報処理技術の進歩により、これまでの肉声でなければ歌手ではないという常識を破り、伝統的なキャラクタービジネスのセオリーを覆し、ユーザー主導のクリエイティブな活動を促進することで、独自のビジネスモデルを築き上げた。コミケに代表される日本のUGC文化と、図9の技術側面である作成ツールと配信プラットフォームの進化により、第2、第3の初音ミクが誕生する可能性を示唆している。

生成AIという新たな破壊的イノベーションが舞台に登場し、AIGCによって、コンテンツ産業全体が進化する機会が訪れている。しかしながら、この新技術の進化速度にガイドライン、社会の受容性、法制度が追いつけず、多くの問題点が浮上している。AIGCによって生まれる新たなビジネスモデルを次節で紹介し、その後、権利処理を考慮して、クリエーターの生態系に現れている課題を概観する。
4.1.AIGCによる事業機会多くのWebサイト25に画像生成AIで対価を得る手法が紹介されている。その中で、今後の技術進化を見て拡大しそうな事業候補を以下に示す。
以上を俯瞰すると、AIGCはまずゲーム、映画、アニメの世界はコミケに参加している少人数グループレベルから大規模制作会社まで広い範囲でコンテンツ制作の効率化に貢献する。建築、ファッションやeコマースの分野では、企業の内部利用と対顧客のマスカスタマイゼーション[43]と呼ばれる個人向け価値提案を行う利用が増えていくだろう。そして最後は個人事業としてできるコンテンツ、ノウハウ販売だ。AIでイラストを作成する者の総称として「AI絵師」という言葉があり、それが職業として成立しようとしている。生成AIのプロの利用は洋の東西を問わず、大企業では内部で静かに進むだろう。UGCではどうか。日本は先頭を走ることが可能だ。是非は別として3.2.で述べた二次創作について権利意識が厳格でないコミケ文化がある。さらに3.3.で述べた初音ミクのように新しい技術とキャラクターを組み合わせるユーザーがいる。
4.2.AIGCの課題AIGCを作るために何が必要か。言語から画像を生成するためには画像と同時に学習した言語モデルが必要だ。Stable Diffusionに議論を絞ろう。Stable Diffusionが使用するデータセットは、不適切な内容を含む可能性が指摘されており、商用利用には不向きであるとの警告がなされている。それにもかかわらず、一部の企業はこのデータセットを商用ライセンス下で公開し、収益化している。Stable Diffusionの組成で前述した"LAION-5B"は、インターネットから収集した画像とキャプションを大量に含むものである。このデータセットのリリースにより多言語大規模トレーニングと視覚言語モデル研究の可能性が広がった。
米国では、画像生成AIを巡り、Stability AI、Midjourney、DeviantArtの3社に対して集団訴訟が提起されている29。これらのAIはアーティストやクリエーターの著作権を侵害する形で製品化されたとされる。特に、Stable Diffusionは多くの著作権で保護された画像を訓練データとして使用し、アーティストの許可や報酬なしに画像がダウンロードされて使用されているとの指摘がある。米国のフェアユースの概念には曖昧性があり、LAION-5Bデータセットを用いたAI画像生成利用企業は、その曖昧性によるリスクを抱えている。原告の主張によれば、研究目的で収集されたデータを商用に利用する行為は、フェアユースの原則に反する可能性がある。この問題は、AI技術の商用展開において、新たな法的規範やガイドラインの確立が必要であることを示している。フェアユースは米国の著作権法における例外的な概念で、特定の条件の下で、著作権によって保護される作品を許可なく使用することを許容する。この原則の存在理由は、著作権の保護と公共の利益との間のバランスを取るためで使用の目的や性質、使用される作品の性質、使用の量や範囲、そして使用による潜在的な市場や価値への影響という4つの要因が考慮される。これらの要因は、具体的なケースごとに検討され、一つの要因だけでフェアユースが決定されるわけではない。裁判結果が出るのはこれからである。
一方で日本はどうか。2019年1月に発布された著作権法第30条の4[44]というAI学習に寛容な画期的な法律がある30。
この著作権法第30条の4に基づくと、AIの開発に関しては「AI開発・学習段階」と「生成・利用段階」の二つの段階に分けて考慮される。AIの「開発・学習段階」では、著作物に表現された思想や感情を目的としない利用行為として、著作権者の許諾なしに著作物を利用することが可能とされている。しかし、これは「著作権者の利益を不当に害することとなる場合」を除くとされている。学習用データとしての著作物の収集・複製や、AI学習目的でのデータベースの著作物の複製は、著作権者の利益を不当に害することがない限り、許される。これは米国のフェアユースが判例なしに認められていることに等しい。一方、AIの「生成・利用段階」では、通常の著作権侵害の規定が適用される。AIを用いても、特別な扱いはされず、AIによって生成されたコンテンツが著作物に「依拠性」と「類似性」が共に認められない場合は著作権侵害とならない。
結論として、AIの「開発・学習段階」では、一定の条件下で著作物を無許可で利用できるが、「生成・利用段階」では、通常の著作権の規定が適用されることとなる。深層学習により巨大パラメータ数の中に拡散してしまったデータを使うことに、依拠性があるかどうかは判断が分かれるが、AIGCの一作品が、明らかに他の著作物に類似していなければ、そのAIGC作品の使用は著作権侵害とはされない。
このような現状に対して、クリエーター団体から以下の提言が出ている[45]。
1と2の実現には現行著作権法の法改正が必要になる。裏返せば、現行法の開発者への寛容度は、世界的に見て稀有な位置付けになっている。3については、現時点で、AIGCに著作権を与えるべきでないとの意見が大勢に見える。一方で、生成AIを用いたとしても、人が思想・感情を表現しようとする創作意図があり、創作的寄与と認めるに足る行為を行い、生成物が思想感情の創作的表現として評価される場合は、著作権が与えられる可能性がある[46]。生成AIの利用が一般的になった社会では、判断が変わるかもしれない。4と5は社会倫理設計の重要な課題になる。
4.3.AIGCの課題に対する考察Stable Diffusionの流通モデル(図7)を振り返ると、現行法では公開されている生データから学習済みモデルは著作者の同意なく作成することができる。おそらく米国もフェアユースの概念で認められることになると予測する。Stable Diffusionでは追加学習がユーザー側で自由に行えることから、「低賃金労働で作られ、個人情報を含み、違法に取得されたデータ」が含まれる倫理的・法的問題があったとしてもそれを検査することが非常に難しい。つまり、データ利用の倫理が保証されないことが課題になる。一方で、図3のChatGPTのチューニング構造は、RLHF31という訓練された人の教導が生成AIの制御機構として組み込まれており、さらにその上に、倫理的に許されるコンテンツのみを出力するというフィルタリング機構が構築されている。Stable Diffusionのオープンソース・オープンデータのモデル流通システムは、開発者にとって理想だが、一方でChatGPTの管理されたクローズドシステムの良さも評価する必要がある。
インターネット上の偽造コンテンツを自動発見するツール開発[47-49]は必須だろう。しかし、矛と盾の逆説と同じように、偽造コンテンツ生成と摘発の能力は拮抗していく。いずれは合法・違法、倫理的是非に関係なくAIGCは広まっていく。オープンソース化したStable Diffusionの拡張技術の発展は目覚ましい。例えばControlNet[50]は画像中の人物、物体の姿勢を反映した動画像を半自動で生成することができる。まだまだ、生成AIによる動画像生成は発展途上だが、数年内にはストーリーと一致した違和感のない動画像自動生成が可能になるだろう。
AIによる文章、動画、楽曲のゴーストライティングが広まる可能性がある。それはまるで2000年に起きたナップスター事件を超えるコンテンツ経済圏の変化をもたらすことになるかも知れない。ナップスター[51]は1999年に創業し、音楽コンテンツを自由にダウンロードできるようにした。友達が1枚のコンパクトディスク(CD)を買えば、友人が全て共有できる仕組みだ。創業から2001年にかけて、Napsterの存在によりCDの売上が毎年10%以上減少した。1999年を境に、全世界のCD売上は5年で半減している。しかし、違法性を経営陣が認識していたことからナップスターは2002年に操業停止となっている。
それからどうなったか。コンテンツ収入はCDからAppleのiTunes、 Spotifyと言った音楽配信サービスに移行し、音楽家たちの収入はライブ市場に移って行った。同時に配信サービス音楽コンテンツのグローバル化を促すこととなった32。MP3の違法ダンロードをアナロジーとして考えると、AIゴーストライターによるUGCの拡散が、これまでの著作権ビジネスを破壊しそうな状況を作り、そこから生成AIを使いこなすプロフェッショナルクリエーター、熱烈なユーザークリエーター、配信システム、ソーシャルメディアを巻き込んで、新たなコンテンツ経済圏が生まれるだろう。
コンテンツ生成における新たな可能性が拓かれつつある。AIによる文章生成、映像制作、音楽作成など、多岐にわたる領域での活用が進められている。本稿では、2章で生成AIの技術進化が急加速していることを報告した。そして3章でメディアフランチャイズのコンテンツ経済圏を俯瞰し、4章でユーザー主導のAIGCによる新経済圏の想定を述べた。本稿執筆時点(2023年夏)の生成AI関連の引用文献の多くは2022年から2023年の新技術である。生成AIの技術進化は目覚ましく、来年に引用すべき文献は一変しているだろう。生成AIの技術開発について日本は米国、中国に大きく劣後している。一方で、日本企業はキャラクターと呼ばれるIPコンテンツを軸としてメディアフランチャイズの事業化に成功している。映像媒体、ゲーム、イベント、商品化などの多様な展開を通じて、海外でのIP価値を高めている。この理由として、戦略的なオーディエンスチャネルの構築、アニメの広範な配信、現地企業との柔軟なIPライセンス契約があるが、強調したいのはファンコミュニティ活動の促進である。コミックマーケットという二次創作に寛容な文化的背景があるからこそ、画像生成AIの日本での活用が見えてくる。
日本のコンテンツ産業は米国や中国と異なり、コンテンツ産業とメディア・テクノロジー産業との統合が進んでいないように見える。統合することが伸び代になる。初音ミクに見られるように、作成ツール、配信プラットフォームの利用、クリエーター育成にユーザーを巻き込んでいくことにより、新たなIPコンテンツを中心とした多元的経済圏の形成が可能になる。日本には生成AIの利用によりコンテンツ産業が発展する素地ができている。
現時点で、AIによるコンテンツ生成は、効率的で一貫性のある出力を得ることができる一方、人間の感性や独自性を持つコンテンツを生み出すことは難しい。逆に、人間のクリエーターはその独自の視点や感性を活かしたコンテンツを生み出すことができるが、生産性やコスト面での課題が存在する。このような背景から、新たな経済圏と古い経済圏が対立するだけでは共倒れが危惧される。創造的コンテンツの供給として生成AIを使いこなすクリエーターが必要である。具体的には、AIを活用した効率的なコンテンツ生成と、人間の感性や独自性を活かしたコンテンツ制作を組み合わせることで、より質の高いコンテンツを生み出すことが可能となる。また、AI技術の進化をクリエーターたちが積極的に取り入れることで、新しい表現方法やコンテンツの形態が生まれる可能性もある。AI技術と人間のクリエーターが単なる対立軸として捉えられるのではなく、共存共栄の関係を築くことが、コンテンツ産業の未来を拓く鍵となる。
1 大阪大学先導的学際研究機構教授
2 例えばソース文は英語であり、ターゲット文は翻訳された日本語となる。
3 ニューラルネットの設計によって異なる、単語・文字を表現するデータ単位。
4 https://creativecommons.org/licenses/by-nc/4.0/
5 後述する画像生成も同じ分類ができる。
6 https://blog.brainpad.co.jp/entry/2023/05/16/153000 にChatGPT利用の注意点が明記されている。
7 https://commoncrawl.org/
8 https://lifearchitect.ai/chatgpt/
9 https://lifearchitect.ai/chatgpt/
10 後の章で説明する著作権法第30条4項が成立する2019年1月の前である。
11 https://blog.modernmt.com/making-generative-ai-multilingual-at-scale/
12 https://www.chinadaily.com.cn/a/202306/14/WS64898027a31033ad3f7bc3b0.html
13 Stability.aiは英国、Avia Techはルクセンブルク登記である。
14 https://docs.midjourney.com/docs/terms-of-service
15 https://creativecommons.org/licenses/by-nc/4.0/deed.ja
16 https://yuryoweb.com/stable-diffusion-commercial-use/
17 https://github.com/CompVis/stable-diffusion/blob/main/LICENSE
18 https://civitai.com/
19 https://huggingface.co/
20 https://laion.ai/
21 Checkpointとは、Stable Diffusionの学習済みモデルを保存したファイルのことを示す。
22 機械翻訳では、SYSTRAN社の機械翻訳言語モデルのマーケットプレイスがある。https://www.systran.net/marketplace-catalog/
23 日本では和製英語でメディアミックスと呼ばれる。
24 https://en.wikipedia.org/wiki/List_of_highest-grossing_media_franchises
25 例えば https://ambcrypto.com/blog/how-to-make-money-with-midjourney-15-easy-ways-to-check-out/
26 https://fashionchallenge.ai/ja
27 https://sozomuseum.com/entry/
28 日本の大手出版社がグラビア作成を断念したという事例がある。https://www.itmedia.co.jp/news/articles/2306/07/news150.html
29 https://gigazine.net/news/20230116-stable-diffusion-midjourney-litigation/
30 動画解説が理解しやすい。https://www.youtube.com/watch?v=eYkwTKfxyGY
31 人間からのフィードバックを用いた強化学習という直訳どおり、人が介在するというファクターが重要である。
32 https://news.yahoo.co.jp/expert/articles/6688469800a4d8acf7f40370070297e86c8e432f