3. Results
3.1 Number of tropical cyclones and tracks
Meteorological services observed a global total of 24 TCs during the 40-day DYAMOND period, whereas the models simulated between 12 and 31 TCs, i.e., 50–140 % of the observed value (Fig. 1). Most of the models simulated fewer TCs than observed; specifically, six of the nine models (ARPEGE, FV3, ICON, IFS, MPAS, and SAM) simulated less than 24 TCs (Figs. 1b, c, e–g, i), and only NICAM and UM simulated more TCs than observed (Figs. 1h, j). GEOS simulated exactly 24 TCs (Fig. 1d), however, considering the limited sample size and the likelihood that a different tracker may have yielded slightly different numbers, we do not wish to emphasize the exact number of TCs each model produced.

According to the observations, the Western Pacific was the most active basin during the DYAMOND time period, followed by the Eastern Pacific, Atlantic, and Indian Oceans. All models agreed that the Western Pacific was going to be the most active basin, and the simulated tracks were generally oriented from south to north as in the observations (Fig. 1). However, the models were not as successful in the other basins. For example, in the Eastern Pacific, all models, except MPAS (Fig. 1g), simulated fewer TCs than observed, and in most models there was less agreement between the orientation of the observed and simulated tracks. FV3 seems to have done best in terms of tracks in this basin (Fig. 1c). TC activity in the Atlantic proved to be particularly difficult to capture, and some models simulated a very active basin while others simulated a very quiet one. Specifically, NICAM produced 11 Atlantic TCs (Fig. 1h), whereas FV3 and IFS only produced one (Figs. 1c, f).
TC formation events during the DYAMOND period were not spread out uniformly over time but occurred in more or less well-defined periods (Fig. 2, black dots). The models simulated the temporal modulation of activity in rough agreement with the observations. For example, in the Western Pacific, most models correctly simulated a greater number of formation events before 22 August than after that date (Fig. 2a). In the Eastern Pacific, the models missed some of the formation events in early August, but they agreed with the observations on a second round of activity in late August/early September (Fig. 2b). In the Atlantic, about half of the models suggested a relatively active period in mid/late August, around the same time four formation events were observed (Fig. 2c). By contrast, the models struggled with capturing the timing of TC formation in the Indian Ocean (Fig. 2d); however, with only two observed events, this basin is likely not representative.

At this point we can only speculate why the models were able to capture the temporal modulation of activity beyond the typical predictability limit of weather prediction, which is around two weeks. One possible reason is that the models were able to capture the modulating effect of intraseasonal variability as previously demonstrated by Nakano et al. (2015). Another possible reason is that the prescribed sea-surface temperatures artificially impart longer predictability on the atmosphere.
Perhaps most importantly, Fig. 2 demonstrates that no model suffered from a climate drift; that is, no model showed the number of TC formation events to unrealistically increase or decrease over the 40-day period. This highlights the quality of the DYAMOND models, which were not tuned for the experiment.
As a final remark, we note that UM produced a three member mini-ensemble instead of a single simulation. The differences in TC numbers and tracks within this ensemble were as large as (or at times larger) than inter-model differences (not shown). This indicates that more simulations and ensemble runs are required to properly assess the predictive skill of each model beyond the broad statements made earlier.
3.2 Tropical cyclone intensity
Time series of vmax in Fig. 3 provide a broad overview of the intensity of the TCs and allow for a cursory model evaluation. Some biases are evident; for example, ICON and SAM produced storms that were generally too weak (Figs. 3e, i), whereas ARPEGE produced a few storms that were much too strong. In fact, ARPEGE produced storms with unrealistically high vmax of > 100 m s−1 (Fig. 3b), most likely because the evaporation coefficient was set to a wrong value (Stevens et al. 2019).

According to the observations, the TCs during the first 2 weeks of August remained relatively weak with only two storms reaching hurricane intensity (vmax ≥ 33 m s−1; Fig. 3a). By contrast, some of the TCs that formed in the second half of August became quite intense, with four storms reaching major hurricane intensity (vmax ≥ 50 m s−1). Most models had issues with capturing this pattern. Specifically, a number of models simulated storms in the first half of August that were too intense (ARPEGE, GEOS, NICAM, UM; Figs. 3b, d, h, j). From all models, MPAS seems to have best captured the overall pattern (Fig. 3g).
To evaluate the models regarding intensity in more depth, we compared the observed and modeled frequency distributions of vmax (Fig. 4) and pmin (Fig. 5). We chose to compare frequency distributions instead of computing vmax and pmin errors, because the models did not simulate all observed TCs, and not all simulated TCs were observed. We present the frequency distributions by way of kernel density estimates (Silverman 2018); this method yields smooth curves that make a comparison easier. The kernel density estimates were implemented using the Python Seaborn library.
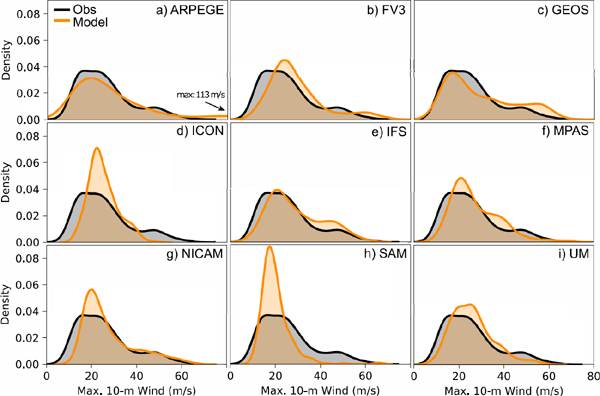
The observed vmax distribution has a broad primary peak centered near 20 m s−1, a secondary peak near 50 m s−1, and a fat tail toward higher values (Fig. 4). All models were able to produce this bi-modal distribution to some degree, but certain models deviated more from the observations than others. ICON and SAM deviated most dramatically: Both models produced a narrow primary peak, mainly because they were not able to simulate high intensities (Figs. 4d, h). FV3 and GEOS shifted the secondary peak to higher values (Figs. 4b, c), whereas IFS and MPAS shifted it to lower values (Figs. 4e, f). ARPEGE produced a very broad distribution, partly related to its over-intensification issue (Fig. 4a). NICAM reproduced the observed distribution for vmax > 25 m s−1 better than the other models, but missed some of the weaker intensities with vmax < 20 m s−1 (Fig. 4g).
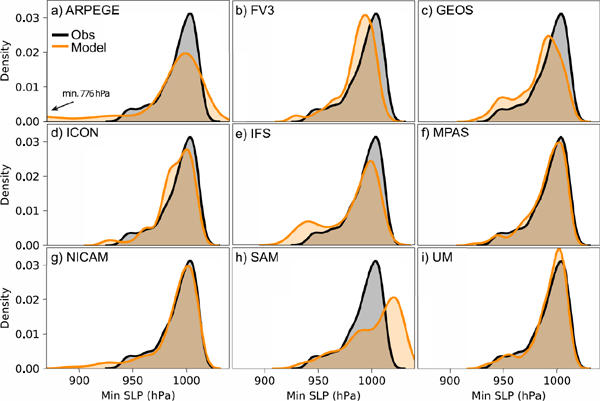
The observed pmin distribution has a well-defined primary peak around 1000 hPa, and a fat tail extending toward lower pressures with a hint of a secondary maximum near 950 hPa (Fig. 5). All models captured the general shape of the observed distribution, with MPAS and UM matching the observations best (Figs. 5f, i). Most of the other models produced storms that were too deep, although in different ways. In FV3, the distribution had the same shape as the observation but shifted to deeper values (Figs. 5b); in IFS, the secondary maximum was much more pronounced than in the observations (Figs. 5f); and GEOS was somewhere between FV3 and IFS (Figs. 5c). In ARPEGE and NICAM, some storms were much deeper than the observations, causing the tail to stretch too far to the left (Figs. 5a, g). SAM is unique in that the main peak was shifted to much higher values. We shall note here that SAM's pmin values are ambiguous, because SAM uses the anelastic equations and pressure can only be determined to within a function proportional to the base-state density field with arbitrary amplitude (Bannon et al. 2006).
Lastly, we evaluated the overall TC activity by means of accumulated cyclone energy (ACE), a quantity that estimates the wind energy produced by one or multiple TCs over their lifetime. It is computed according to ACE = 10−4  , where vmax is in units of knots (1 knot = 0.51 m s−1). In the context of this study, “ACE” refers to the combined ACE of all storms during the DYAMOND period. Concretely, for each model and the observations, we squared all 6-hourly vmax values, summed them up, and multiplied them by 10−4. According to the observations, the ACE during the DYAMOND period was 169 (Fig. 6). Since the wind speed enters the ACE calculation as a squared value, ACE is quite sensitive to uncertainty in the analyzed vmax values. We therefore estimated a lower and upper bound by assuming that all observed vmax records have an error of ±5 m s−1, an estimate based on Torn and Snyder (2012) and Landsea and Franklin (2013). This assumption yielded a lower bound of 118 ACE units and an upper bound of 230 ACE units. Most models were within or slightly above these uncertainty bounds, indicating that the DYAMOND models produced realistic amounts of ACE, even without tuning. Only three models were clearly outside the uncertainty bounds: GEOS overestimated ACE, whereas ICON and SAM produced less ACE than observed.
, where vmax is in units of knots (1 knot = 0.51 m s−1). In the context of this study, “ACE” refers to the combined ACE of all storms during the DYAMOND period. Concretely, for each model and the observations, we squared all 6-hourly vmax values, summed them up, and multiplied them by 10−4. According to the observations, the ACE during the DYAMOND period was 169 (Fig. 6). Since the wind speed enters the ACE calculation as a squared value, ACE is quite sensitive to uncertainty in the analyzed vmax values. We therefore estimated a lower and upper bound by assuming that all observed vmax records have an error of ±5 m s−1, an estimate based on Torn and Snyder (2012) and Landsea and Franklin (2013). This assumption yielded a lower bound of 118 ACE units and an upper bound of 230 ACE units. Most models were within or slightly above these uncertainty bounds, indicating that the DYAMOND models produced realistic amounts of ACE, even without tuning. Only three models were clearly outside the uncertainty bounds: GEOS overestimated ACE, whereas ICON and SAM produced less ACE than observed.

The three members of the UM mini-ensemble offer a glimpse at the intra-model spread. It seems that the intra-model spread is in the range of the observational uncertainty, but slightly less than the inter-model spread (as far as the limited numbers of ensemble members can tell).
Finally, we emphasize that none of the DYAMOND models featured ocean coupling. Consequently, the simulations did not account for the effect of storm-generated ocean cold wakes—which is to induce some weakening. In an otherwise unbiased model, TC intensity should therefore be somewhat higher than observed; in other words, the models that reproduce the observed TC intensities/ACE may actually under-estimate TC intensity/ACE.
3.3 Tropical cyclone size
Size is an important TC parameter because it correlates with the risk for storm surge, but it is infrequently used for model validations. We examined the radius of gale-force winds (r17) and here present the median of all r17 records as our metric of choice (Fig. 7). Results for r25 and r32 were qualitatively similar (not shown), indicating that the results are not sensitive to a particular wind speed threshold. The observational error bars were computed by increasing/decreasing each r17 record by 50 % before determining the median value (Landsea and Franklin 2013).
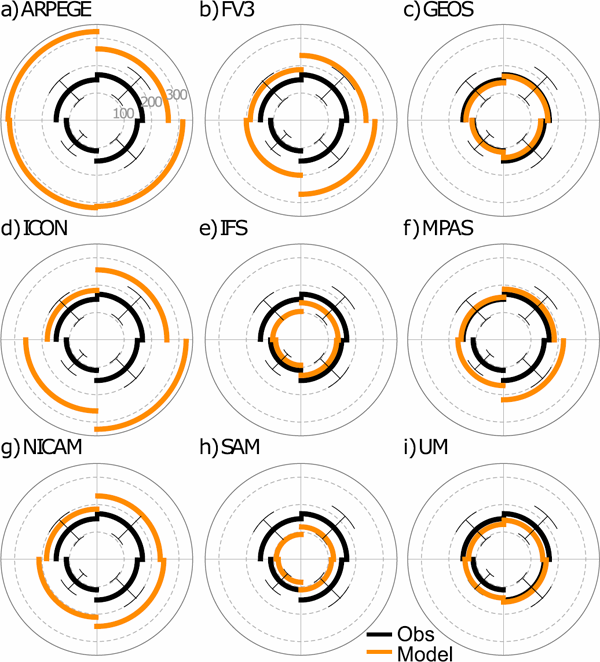
In general, the models overestimated TC size. TCs in ARPEGE, FV3, ICON, and NICAM were substantially larger than observed (Figs. 7a, b, d, g). In fact, ARPEGE and ICON produced very expansive wind fields, and their median r17 reached radially outward to 300 km (more than double the observations). In contrast, the median size of TCs in GEOS matched the observations remarkably well (Fig. 7c), and UM came in as a clear second (Fig. 7i). Storms in IFS and SAM were somewhat smaller than observed, but still within the uncertainty estimates (Figs. 7e, h). A common bias in the models was associated with the asymmetry of the wind field. Concretely, the observed median r17 was largest in the northeast quadrant, but in FV3, ICON, MPAS, and NICAM, it was largest in the southeast quadrant (Figs. 7b, d, f, g). This result suggests that the models are deficient in their representation of TC structure, the prospect of which is examined in the next section.
3.4 Tropical cyclone structure
The TC wind-pressure relationship, i.e., the function that relates pmin to vmax, is often used to inform whether models simulate TC structure realistically. The DYAMOND models produced a variety of wind pressure relationships, with some models being closer to the observation than others (Fig. 8). FV3 and GEOS stand out for reproducing the observed relationship remarkably well (Figs. 8b, c). Most other models have a tendency to produce a relationship that drops off too fast, or in other words, for a given pmin, the vmax is too low. This behavior was most pronounced in ICON (Fig. 8d), and less noticeable in ARPEGE and MPAS (Figs. 8a, f). A possible explanation for this behavior is discussed in Section 4. SAM was unique and had an unrealistic wind-pressure relationship that bended upward (Fig. 8h). This phenomenon was not due to a single outlier but likely related to the surface pressure field being an ambiguous quantity in this model (see also Section 3.2).

Since the 10-m winds in a TC and therefore vmax are strongly affected by the surface layer parameterization, we also investigated the relationship between pmin and 850-hPa vmax. The graphs were qualitatively similar to Fig. 8 (not shown), indicating that the wind-pressure relationships in Fig. 8 are not merely a product of each model's boundary layer and surface layer parameterizations, but they stem from differences in the overall model implementation including the dynamical cores.
Snapshots of 10-m wind speed demonstrate the diversity of the models in simulating the surface wind field (Fig. 9). There were striking differences in eyewall shape, size, and symmetry, as well as in the radial extent of the wind field. Some models produced unrealistic wind fields, either too large and too strong (ARPEGE; Fig. 9a), or too faint and with peculiar waviness (SAM; Fig. 9h). The wind fields of FV3, GEOS, and MPAS were arguably most similar to that of a canonical intense TC, with a distinct eyewall that contained multiple convective- and mesoscale asymmetries (Figs. 9b, c, f).

The ICON example was unique in that it did not reveal a distinct eyewall with sharp gradients; its wind field was rather diffuse and spread out over a large area (Fig. 9d). In contrast, the IFS example was a very small TC with a radially constrained wind field (Fig. 9e). The NICAM example, Fig. 9g, had an even larger hurricane-force (wind speed ≥ 33 m s−1) wind field than ICON, but it also had a distinct eyewall like most other models—albeit somewhat smoother than the eyewalls in FV3, GEOS, and MPAS. The wind field from the UM example exhibited the smoothest structure, the widest eyewall, and the clearest imprint of the model mesh—all consistent with UM being the model with the lowest resolution (Fig. 9i).
A closer look at the kinematic and thermodynamic structure of the simulated TCs was made possible by creation of composite means of the azimuthally-averaged tangential wind, vertical wind, boundary layer inflow, and temperature anomaly (Figs. 10–12). Each composite mean comprised all instances (“snapshots”) where a storm's vmax is ≥ 33 m s−1. This means that each panel reflects the aggregate information from 10–100 s of individual snapshots (as noted in Fig. 10), a number that should be large enough to obtain at least a somewhat robust analysis, even if the number of TCs is limited. The data of the composite means are available for download (Judt et al. 2020).

Broadly speaking, all models produced a typical kinematic structure, that is, a well-defined primary circulation with a tangential wind maximum in the lower troposphere near the storm center and a well-defined secondary circulation manifested by strong radial inflow in the boundary layer, rising motion in the eyewall region, and radial outflow in the middle to upper troposphere (Fig. 10). Despite the overall agreement, there were noteworthy differences between the models, which will be discussed in the next few paragraphs.
The differences in the overall tangential wind structure can be elucidated by comparing the size of the radius of maximum tangential wind, the compactness of the wind maximum (specifically, the radial extent of the 35 m s−1 isotach), and the decay of the tangential wind in the radial and vertical direction. The composite storms had radii of maximum tangential wind roughly between 30 km and 70 km, with ARPEGE and IFS on the lower end (Figs. 10a, e) and ICON on the upper end (Fig. 10d). In FV3 and MPAS, the wind maximum was comparatively narrow and confined, and the radial extent of the 35 m s−1 isotach was less than 20 km (Figs. 10b, f). Contrarily, in ICON and NICAM, the wind maximum was rather broad, and the radial extent of the 35 m s−1 isotach was greater than 50 km (Figs. 10d, g). Differences in the radial and vertical decay rates mirror the previous discussion of storm size, that is, models in which the tangential wind decayed more slowly, such as in ICON and NICAM, were the ones that produced comparatively larger storms. Given the lack of an equivalent observational dataset, it is difficult to assess which model produced a particularly realistic tangential wind structure. The observational composites of Gao et al. (2019, their Fig. 5c) and Komaromi and Doyle (2017, their Fig. 7a) at least suggest that no model produced a particularly unrealistic structure.
As for the vertical motion, ARPEGE and IFS had the steepest eyewall slopes (Figs. 10a, e). The other extreme was UM, which had the most pronounced eyewall tilt (Fig. 10i). In ICON and NICAM, the eyewall updraft was spread out and diffuse (Figs. 10d, g), but in IFS and MPAS it was relatively narrow and confined (Figs. 10e, f). Besides these differences in the eyewall region, there were other differences in the rainband region. Specifically, the vertical motion between r = 100 and r = 250 km was noticeably stronger in ICON, MPAS, and NICAM than in GEOS, IFS, and SAM (Figs. 10d, f, g versus Figs. 10c, e, h). This difference may be a reflection of more or stronger rainbands in the former models.
Again, it is difficult to say which models produced a particularly realistic structure because no equivalent observational dataset exists for the TCs observed during the DYAMOND period. Stern and Nolan (2009) demonstrated that the slope of the eyewall depends on the size of the radius of maximum wind, which would explain why the eyewall updraft in IFS had a steeper slope than in UM. However, The Stern and Nolan study cannot explain the differences between models with similarly sized radii of maximum wind, such as MPAS and UM.
The upper-tropospheric outflow also differed between the models, especially with regard to the altitude of the outflow maximum and the depth of the outflow layer. For instance, the outflow was comparatively deep in FV3 (Fig. 10b) and comparatively shallow in IFS (Fig. 10e). In ARPEGE and ICON, the outflow maximum occurred at a height of 15 km (Figs. 10a, d), but in most of the other models, it occurred mostly below 15 km.
One particularly noteworthy feature, produced somewhat more prominently by FV3, GEOS, and IFS, is the descending flow above the outflow layer that merges with the ascending outflow from below (Figs. 10b, c, e). We are not aware of either observational or modeling studies that demonstrate such a feature in TCs; on the contrary, there is reasonable evidence to suggest that at least in intense TCs, it may be common to have a shallow layer of weak inflow atop the upper-level outflow layer (e.g., Kieu et al. 2016; Komaromi and Doyle 2017; Heng et al. 2017; Duran and Molinari 2018).
Inter-model differences in the boundary layer inflow were mostly in the form of variations of inflow layer depth and strength (Fig. 11). Specifically, IFS and SAM produced comparatively shallow inflow layers that did not extend much above 1 km height (Figs. 11e, h). In GEOS and ICON, the inflow layer had a maximum depth of 1.5 km (Figs. 11c, d), and in the other models, its maximum depth extended slightly above 1.5 km. The observational composite of Zhang et al. (2011, their Fig. 5b) indicates that the inflow layer depth increases from 900 m at the radius of maximum wind to 1.5 km roughly 200 km from the center, which is in broad agreement with most of the models.
From basic TC dynamics, one would expect that the inflow strength correlates with the average intensity of the TCs simulated by the models. However, this was not the case. For example, ICON, which simulated mostly weak TCs, produced stronger inflow than FV3, MPAS, and NICAM, which simulated much stronger TCs (Fig. 11d vs. Figs. 11b, f, g). In fact, with inflow magnitudes of 9 m s−1, the inflow in FV3, MPAS, and NICAM was relatively weak, compared not only to the other models, but also to observations, which show an inflow magnitude of 20 m s−1 (Zhang et al. 2011).
Besides the kinematic structure, we also explored the thermodynamic TC structure in our set of global storm-resolving simulations. To this end, we examined the TC warm core, here represented by the temperature anomaly with respect to the mean temperature between r = 300 km and 700 km (Fig. 12). All models produced a warm core and agreed on the general core structure (expansive in the upper levels, radially confined below). Differences emerged mostly in the vertical structure of the warming inside the TC eye, and in the upper and lower level temperature anomalies outside the eye.
Most models agreed that the warm anomaly peaks at a height of just less than 10 km. More pronounced differences between the models appeared in the vertical structure of the warm core, which ranged from a single, vertically confined maximum in FV3 and GEOS (Figs. 12b, c), to an extended vertical column in NICAM (Fig. 12g), to a clear double maximum of anomalously warm air in UM (Fig. 12i). The other models fell somewhere among these three distinct cases. Most observational studies indicate that the warm core is maximized in the upper troposphere (Frank 1977; Brammer and Thorncroft 2017; Komaromi and Doyle 2017), in agreement with most of the DYAMOND models. However, Stern and Nolan (2012) claimed that the maximum warming should be between 4 km and 8 km, with a potential secondary maximum at higher altitudes. Kieu et al. (2016) also claimed that a double-warm core structure is the norm rather than the exception. If one were to believe the Stern and Nolan and Kieu et al. studies, then UM had a particularly realistic thermodynamic structure, even though it was an outlier among the DYAMOND models.
Compared to the model differences in terms of the warm core, the differences above the outflow layer were equally if not more striking. Above 15-km height, the models did not even agree on the sign of the temperature anomaly. In particular, IFS and ARPEGE produced a strong cool anomaly (< −3 K; incidentally, IFS and ARPEGE were the only spectral models), whereas NICAM, SAM, and UM produced a warm anomaly. FV3, GEOS, ICON, and MPAS were somewhere between the extremes and produced a weak cool anomaly (> −1 K). Observational composites generally show a weak cold anomaly above the outflow layer (Frank 1977; Komaromi and Doyle 2017), although instantaneous snapshots of intense TCs may also show strong cold anomalies (Komaromi and Doyle 2017).
Temperature differences were also found in the boundary layer, although less dramatic: NICAM was anomalously cool (Fig. 12g), and IFS was anomalously warm (Fig. 12e). The other models had weak cool anomalies or no clear signal. Note that IFS and NICAM were polar opposites of each other (NICAM: warm in the upper levels, cool in the lower levels; IFS: vice versa).
3.5 Sensitivity of tropical cyclone formation and intensity to model resolution and parameterized deep convection
In addition to the primary high-resolution simulation, some DYAMOND models produced sensitivity runs with lower resolution. For example, ICON produced six simulations with mesh spacings of 2.5, 5, 10, 20, 40, and 80 km, all without parameterized convection (hereafter referred to as ICON no-conv), and an additional three simulations with mesh spacings of 20, 40, and 80 km with parameterized convection (ICON conv). These nine simulations provided an opportunity to investigate the sensitivity to model resolution and parameterized convection in a controlled manner (Figs. 13, 14) .


As for sensitivity to resolution, there was a clear inverse relationship, as the number of simulated TCs increased when resolution was decreased (Fig. 13, left column). Concretely, the highest resolution run produced the fewest TCs (15; Fig. 13a), and the lowest resolution run produced the most TCs (50; Fig. 13h). In the simulations with intermediate resolution, the number of TCs was relatively constant (around 20). The sensitivity to resolution seemed to be basin dependent. Specifically, in the Atlantic and Eastern Pacific, the 80-km ICON produced five to six times as many TCs as the 2.5-km ICON (Figs. 13a, h), but in the Western Pacific, the 80-km ICON produced only two times as many TCs as the 2.5-km ICON. As a consequence, the fractional ratio of storm numbers among the ocean basins relative to the global total number was much better in the higher resolution runs than in the lower resolution runs. In the Indian Ocean, the number of events seemed to be insensitive to resolution, and each run produced either one or two TCs.
As for sensitivity to parameterized convection, the model produced dramatically fewer TCs once the parameterization was turned on (Fig. 13, left vs. right column). This effect was most pronounced at lower resolution. Specifically, the number of TCs dropped from 23 to 17 in the 20-km runs (Figs. 13d, e), from 21 to 14 in the 40-km runs (Figs. 13f, g), and from 50 to a mere 9 in the 80-km runs (Figs. 13h, i).
The runs with parameterized convection also featured substantially lower ACE (Fig. 14). Again, the effect was most dramatic at lower resolution, but even for an intermediate resolution of 20 km, the ACE was reduced by 65 %. In fact, at least for the 20-km runs, the reduction in ACE is more dramatic than the reduction in TC number, which suggests that convection parameterization not only reduces the number of TCs but also makes TCs weaker and/or shortens their lifetime.
Notably, the ICON no-conv runs produced more or less the same amount of ACE at all resolutions (Fig. 14). Evidently, the lack of intense storms in the lower-resolution runs was compensated by a larger number of weak storms. An interesting follow-up question would be whether this compensation was pure luck or whether the amount of background available potential energy that is converted into kinetic energy by TCs is resolution-independent, such as mean precipitation (Hohenegger et al. 2020).