Automated Landslide Mapping in Japan using the Segformer Model: Enhancing Accuracy and Efficiency in Disaster Management
2023 Volume 4 Issue 2 Pages 75-86
Details
2023 Volume 4 Issue 2 Pages 75-86
Japan is known for its landslide susceptibility due to its steep topography, high seismic activity, and heavy rainfall patterns. These landslides have resulted in significant loss of life and infrastructure damage. To effectively manage landslide risks, accurate mapping of landslide-prone areas is essential. This research focuses on enhancing landslide mapping in Japan using an automated system based on the Segformer model, which combines Transformers and MLP decoders for semantic segmentation. A dataset of aerial images from various regions in Japan was used to train and evaluate the model. The Segformer model achieved a Mean Accuracy of 0.85, a Mean IoU of 0.80, loss value of 0.13 with a recall and precision value of 0.92, respectively, demonstrating its effectiveness in identifying regions prone to landslides. By leveraging advanced algorithms and data analysis techniques, the automated system improves the efficiency and accuracy of landslide mapping efforts. The research findings significantly impact proactive disaster management and mitigation strategies in Japan.
Japan is known for its landslide susceptibility due to its steep topography, high seismic activity, and heavy rainfall patterns. Landslides have significantly impacted the nation, leading to loss of life and damage to infrastructure. According to a report by CNN, research by the Japanese government in 2020 revealed that there had been an average of 1,500 landslides per year in Japan over the past decade1). Fig. 1 identifies some of the notable locations where these landslide has occurred frequently in Japan. Some notable occurrences include the landslide in Atami Shizuoka Prefecture of Japan, which left 2 people dead and over 20 people missing at the time of incidence; the landslide instantly swept away 130 houses, adversely affecting up to 300 houses. In the southwestern region of Kyushu, Japan, at least 50 individuals lost their lives in 2019 due to torrential rains that resulted in mudslides and flooding2).

Similarly, in 2018, Kyushu witnessed the demise of over 114 individuals due to the same natural calamities. Furthermore, landslides, notably in Hiroshima prefecture, resulted in the loss of 87 lives3)4). In 2016, Aso, Kumamoto prefecture, also experienced a fatal landslide occurrence; it is understood that the combination of seismic activity and rainfall weakened slopes leading to a landslide.
While landslide occurrences in Japan are significant, landslides are a global phenomenon with severe consequences. In India, for example, there were 3,656 significant landslides reported in the past five years alone5). According to reports from the BBC, a series of devastating landslides occurred in Quito, Ecuador, leading to the collapse of nine residential properties and the unfortunate loss of 24 lives. Additionally, 47 individuals sustained injuries, while 9 people remain missing. These tragic events were attributed to intense rainfall between January 31 and February 1, 2022. The heavy rainfall, coupled with the geographical characteristics of the region, likely contributed to the destabilization of slopes and triggered the landslides. Durban, South Africa, faced severe flooding and landslides in April 2022, causing significant loss of life and displacement of thousands of individuals due to excessive rainfall6).
Typhoon Morakot, which struck Taiwan in 2009, is another significant landslide occurrence. The typhoon triggered catastrophic flooding and landslides. The downstream settlements suffered extensive damage, destroying numerous structures, while the loss of approximately 450 villagers’ lives further emphasized the severity of the disaster. Similarly, Uttarakhand, India, faced a severe landslide catastrophe in June 2013, causing widespread devastation across more than 1500 villages. The disaster claimed the lives of 4000 people, destroyed numerous bridges and caused immeasurable additional damage7).
A well-documented claim is that landslides and mass displacements have affected approximately 5 million individuals globally within the last 3 decades8). These landslides are a stark reminder of the urgent requirement to establish a robust disaster management system equipped with practical strategies to mitigate and counteract the hazards such natural calamities pose, one way is through landslide mapping.
Monitoring and detecting landslide-prone areas and generating accurate maps for government planning represent a crucial approach. Achieving high levels of accuracy and speed in landslide prediction is paramount in this endeavour8) 9) Such capabilities facilitate practical assessment of damages and enable the development of comprehensive management plans to minimise losses to the bare minimum.
Japan employs various measures in its continuous endeavours to manage landslide risks. These measures include hazard assessment, early warning systems, slope stabilization techniques, and meticulous mapping procedures. The Geospatial Information Authority of Japan (GSI) utilizes aerial photographs to generate maps of landslide-prone regions to surmount the difficulties and dangers of visiting sites affected by landslides. This methodology facilitates a thorough comprehension of the circumstances without necessitating physical presence at the location. GSI disseminates these aerial photographs to regional administrations and other entities, rendering them accessible to the general public via their website. Through aerial imagery, regional administrations and institutions can estimate the extent of the destruction, assess disasters, and undertake recovery and reconstruction efforts in affected regions. By means of scrutinizing aerial photographs taken before and after the incident, it is feasible to discern regions that have undergone impairment. These areas can then be preserved as Geo-JSON files. Notably, the manual mapping process, which necessitates the visual surveillance of regions susceptible to landslides, is resource-intensive and time-consuming.
The utilization of a manual approach impedes the effectiveness of evaluating the extent of harm and does not ensure the highest degree of precision11). Indeed, implementing automated systems, specifically machine learning methods, holds tremendous potential for enhancing the mapping process of landslideprone areas and yielding more accurate outcomes.
Machine learning models can efficiently evaluate aerial photos, satellite data, and other relevant geospatial information to detect and define landslideprone zones with better precision properly. This is made possible by utilising modern algorithms and data processing techniques. These algorithms can learn from vast datasets and extract relevant patterns and features connected with landslides. This allows for the identification and mapping of hazardous locations to be carried out in a more efficient and accurate manner. In addition, machine learning algorithms may be taught to continually improve their performance and adapt to changing environmental conditions. This improves the accuracy of landslide mapping efforts as well as their dependability. Utilizing automated techniques such as machine learning is a big step forward in landslide mapping. It adds to developing more comprehensive and proactive strategies for managing landslide hazards12).
Effective landslide disaster planning necessitates continuous monitoring of regions prone to landslide before and after potential occurrences. The insights garnered from this monitoring are indispensable for making informed planning decisions. Conventionally, obtaining such information has involved physically venturing into landslide-prone areas to gather data and subsequently create landslide maps for damage assessment. However, this approach poses significant risks, and the manual mapping process is prone to human errors and time-consuming. This research seeks to address these challenges by exploring the feasibility of integrating the Segformer model into detecting landslide-prone regions using aerial photographs. While our study focuses on the potential of the Segformer model in image-based landslide detection, its success could catalyze further in-depth research and enhance the efficiency of preand post-disaster mapping in landslide-prone regions.
Machine learning and artificial intelligence have gained considerable prominence, garnering attention across various academic disciplines. Recently, researchers have increasingly utilized machine learning techniques, including image recognition and computer vision approaches, to address engineering and asset management challenges. This has extended to landslide-related investigations, where numerous studies have proposed diverse machine learning and deep learning methodologies for constructing robust landslide detection models. These endeavours aim to develop a precise, sustainable, and resource-efficient methodology that ensures the highest accuracy in detecting and monitoring landslides from aerial photographs13).
Before this research, the authors’ infrastructure and asset management research group previously used machine learning, including deep learning, to identify concrete fractures.14)15) detected damage in asphalt16)17), assess corrosion of steel beams18), estimated the durability of corroded steel19) and classified bridge damage. These previous efforts yielded significant findings. Wang 20) utilized deep learning techniques to identify natural-terrain landslides in Lantau, Hong Kong. Geodatabases integrating topographic, geological, and rainfall-related data: RecLD, RelLD, and JLD were established. Logistic regression (LR), support vector machine (SVM), random forest (RF), boosting methods, and convolutional neural network (CNN) algorithms were evaluated. CNN achieved 92.5% accuracy in identifying RecLD, outperforming other algorithms in feature extraction and multi-dimensional data processing. Boosting techniques ranked second in accuracy, followed by RF, LR, and SVM.
This study provides insights for accurate landslide detection using deep learning techniques. Kyrkou21) further highlighted that deep learning algorithms could potentially enhance the remote sensing capabilities of unmanned aerial vehicles (UAVs) for emergency response and disaster management applications. His research showed that UAVs with camera sensors could analyze images in remote disasterstricken areas and detect various calamities in realtime. Still, the computational demands of deep learning hinder real-time deployment. Ado12), conducted a comprehensive survey of machine learning (ML) models used for landslide susceptibility mapping. His work highlighted the growing interest and positive outcome, stressing the need for researchers to explore various ways to improve landslide mapping using Deep-learning and hybrid models. Kazuki’s22) study, was a direct dive into applying deep learning semantic segmentation to detect landslides from ariel photography; his method earned a 0.65 F-Score, making it appropriate for machine learning procedures. But upon visualization, the method partially matched the ground truth. Researchers have also suggested combining multiple deep-learning models to help predict landslide regions from multiple image systems, such as infrared mapping and serial images.
Kimura23) proposed various techniques for identifying landslides and assessed the efficacy of several deep neural networks (DNN) approaches using labelled and unlabeled data. As mentioned earlier, the circumstance arose due to difficulty annotating data during an urgent situation
(24) Extensively assessed the performance of diverse neural networks and ensemble frameworks, including AdaBoost, Bagging, Multi-Boost, Rotation Forest, and Random Subspace. It aimed to evaluate the effectiveness and efficiency of these models in managing complex datasets. The results offer valuable insights into their relative performance, aiding researchers and practitioners in choosing suitable models for specific applications. Huang et al25), introduced L-UNet, a hybrid model combining U-Net with a multi-scale feature-fusion (MFF) module. L-UNet outperformed the baseline U-Net in accuracy, recall, MIoU, and F1 by margins of 4.15%, 2.65%, 4.82%, and 3.37%, respectively, improving landslide forecasting and disaster management.
In landslide mapping, the ultimate goal is to enhance the mapping process in regions prone to landslides, aiming to minimize human errors and facilitate effective management of landslide-related disasters. Various approaches can be employed to achieve this goal, including utilising a singular deep learning model, machine learning techniques, or hybrid models that combine different methodologies. When researching Machine Learning and Artificial Intelligence, it is crucial to consider critical variables such as prediction accuracy, computational requirements, and execution speed. These considerations ensure the development of an efficient and robust system that can effectively address the challenges associated with landslide mapping. This study carefully selected the Segformer model after meticulously evaluating these various factors. By weighing the importance of prediction accuracy, computational efficiency, and overall performance, the Segformer model emerged as the suitable choice to achieve the intended outcome. Its unique architecture and capabilities make it wellsuited for accurately identifying and delineating landslide-prone areas in Japan, contributing to improving landslide mapping efforts.

(1) Data Collection
Fig. 2 summarizes the flow of this research, while Table 1 lists aerial photographs with a resolution of 256 × 256 and the locations it was collected from in Japan,

(2) Data Preparation
The images were annotated using an online data annotation platform called Roboflow: Roboflow provides a significant advantage in annotation for computer vision tasks. Its annotation capabilities enable efficient annotation datasets; this streamlines the annotation process, saving valuable time and effort.
The aforementioned table reveals a constraint within the dataset, prompting the implementation of data augmentation to enhance its quality. According to academic research, using data augmentation techniques has enhanced a model’s predictive accuracy by a minimum of 5%26). The present study employs the rotation technique as the chosen augmentation method, as illustrated in Fig. 3.

After applying the rotation augmentation technique, the overall dataset was augmented to 2443 images, with a distribution as presented in Table 2. The data was inputted into the model that was utilized for this study.

(3) Segformer Model
The choice model for this research is the semantic segmentation model, which Enze Xie27) introduced in 2021, called the Segformer model. SegFormer is a semantic segmentation framework integrating Transformers with lightweight Multilayer Perceptron (MLP) decoders. It is characterized by its simplicity, efficiency, and robustness. The SegFormer model comprises a newly developed Transformer encoder structured hierarchically and generates features at multiple scales. Its structure makes the utilization of positional encoding unnecessary, as it may result in the interpolation of positional codes, ultimately leading to a reduction in performance when the resolution of testing varies from that of training. The SegFormer model circumvents the use of intricate decoders27); the MLP decoder in the model gathers data from many layers, combining local and global attention to provide effective representations; this helps increase its efficiency. The Backbone Network that Segformer utilises is a conventional Convolutional Neural Network (CNN), similar to ResNet Field28) or Efficient-Net29), which handles the input image and extracts hierarchical features at varying scales. The aforementioned characteristics can capture both intricate particulars and broad semantic concepts.
The Segformer model offers a range of compelling advantages that underscore its suitability for image segmentation tasks:
i. High Accuracy: SegFormer excelled on benchmark datasets like Cityscapes, ADE20K, and COCO-Stuff, showcasing exceptional performance.
ii. Efficient Architecture: SegFormer adopts an efficient design that allows faster inference time without compromising accuracy.
iii. Scalability: The architecture of Seg-Former allows for easy scalability to handle high-resolution images. It is designed to process input images of varying sizes and adapt to different requirements, making it suitable for real-time and high-resolution applications.
iv. Contextual Understanding: SegFormer utilizes Transformer self-attention to capture global context, enhancing object relationships and pixel classification.
v. Flexibility and Generalization: SegFormer applies to diverse semantic segmentation tasks (scene parsing, object segmentation, instance segmentation) with strong generalization capabilities.
vi. End-to-End Training: SegFormer supports end-to-end training, eliminating the need for extensive post-processing.
vii. Adaptability to Limited Data: SegFormer benefits from the Transformer architecture’s ability to learn from limited labelled data effectively.
The multitude of advantages offered by Segformer prompted our pursuit of its application in the challenging domain of landslide mapping. These distinct strengths collectively fueled our curiosity and drove us to explore the potential of this model in addressing the complex and critical task of mapping landslides.
As depicted in Fig. 4, and aforementioned, Seg-Former consists of two main modules: A hierarchical Transformer encoder to generate high-resolution coarse features and low-resolution fine features; and a lightweight All-MLP decoder to fuse these multilevel features to produce the final semantic segmentation mask27).

a) How it works
The hierarchical Transformer encoder comprises Mix Transformer Encoders MiT-B0 to MiT-B5, which draw inspiration from Dosovitskiy’s Vision Transformer (ViT)(30). The Mix transformers vary in size, with MiT-B5 being the largest.
b) Transformer Encoder
When the given image is fed to the Segformer model, in our case, that of landslides, the model divides into patch sizes; the patch size is 4 × 4, unlike the ViT model, which uses a patch size of 16 × 16, the image is divided into patches. These patches are inputted into the hierarchical Transformer encoder to obtain multi-level features at {1/4, 1/8, 1/16, 1/32} of the original image resolution. The multi-level features are inputted into the All-MLP decoder to predict the segmentation mask at a resolution of ;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/4.2_75_M01.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09) 𝑁cls resolution, where 𝑁cls represents the number of categories, which is 3.
𝑁cls resolution, where 𝑁cls represents the number of categories, which is 3.
The transformer block comprises three sub-modules: Efficient Self-Attention, Mixed-FFN (Mixed Feed Forward Network), and Overlapping Patch Merging. The initial module, Efficient Self-Attention, serves as the primary computational bottleneck within the encoder layer of the Segformer model. The modified multi-head self-attention in the transformer operates similarly to the original version but incorporates a sequence reduction technique to decrease computational complexity. Eq. 1 presents the original multi-head self-attention process; the dimensions of each head Q, K, and V are N × C, where N represents the sequence length and is calculated as H × W. The self-attention is subsequently computed as:

The original multi-head self-attention module has a complex computational process, which limits its applicability to large image resolutions. This process is denoted as 𝑂(𝑁2); To address this issue, the Segformer model incorporates a sequence reduction process to simplify the computational process. This process employs a reduction ratio, denoted as R31), to decrease the length of the sequence as follows:

K is the sequence to be reduced, Reshape(;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/4.2_75_M02.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09) , 𝐶 ∙ 𝑅)(𝐾) refers to reshape K to the one with shape of × (C · R), and Linear(𝐶in, 𝐶out)(∙) refers to a linear layer taking a 𝐶in -dimensional tensor as input and generating a 𝐶out -dimensional tensor as output. Therefore, the new K has dimensions × 𝐶 . This process reduces the the computational complexity from 𝑂(𝑁2) → (𝑂
, 𝐶 ∙ 𝑅)(𝐾) refers to reshape K to the one with shape of × (C · R), and Linear(𝐶in, 𝐶out)(∙) refers to a linear layer taking a 𝐶in -dimensional tensor as input and generating a 𝐶out -dimensional tensor as output. Therefore, the new K has dimensions × 𝐶 . This process reduces the the computational complexity from 𝑂(𝑁2) → (𝑂;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/4.2_75_M03.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09) )
)
The next block which is the Mix Feed-Forward Network (Mix-FFN).It is employed to address the fixed resolution problem by replacing fixed-sized positional encoding layers of convolution with datadriven positional encoding implemented through MLP (multi-layer perceptron). The feed-forward network (FFN) in Mix-FFN employs a 3 × 3 convolutional layer. The formulation of Mix-FFN is as follows:
76

where 𝑋in is the feature from the self-attention module. Mix-FFN mixes a 3 × 3 convolution and an MLP into each FFN.
The final module in the encoder section is the Overlapping Patch Merging block. This block serves the purpose of reducing the size of the feature map. By observing the figure depicting the feature size, we can observe that as the feature map progresses through this module, its size decreases in the higher levels of the network.
The developers of Segformer initially chose to incorporate a patch merging process from the Vision Transformer (ViT) architecture. However, this approach had a limitation in that it did not preserve local continuity around the patches. To address this issue, Segformer introduced an overlapping patch merging process. This process is defined by three parameters which control the overlapping patch merging process.: K, S, and P :
· K represents the patch size, usually set to 7 for image patches and 3 for feature patches in their experiments.
· S represents the stride between two adjacent patches, set to 4 for image patches and 2 for feature patches.
· P represents the padding size, set to 3 for image patches and 1 for feature patches in their experiments.
It’s important to note that the specific values of these parameters can be adjusted based on the application’s requirements or the characteristics of the dataset being used.
Segformer performs the overlapping patch merging process on our landslide image dataset using these patches with specific patch sizes, strides, and padding. This approach enables the preservation of local continuity and facilitates the creation of hierarchical feature maps. The hierarchical features can be progressively reduced from an initial size of 𝐹1 ( 𝐶1)F1 to a smaller size of 𝐹1 (;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/4.2_75_M04.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09) 𝐶2), and the process can be iterated for other feature maps in the hierarchy. Therefore, Segformer leverages the overlapping patch merging technique to extract hierarchical features while preserving local continuity around the patches.
𝐶2), and the process can be iterated for other feature maps in the hierarchy. Therefore, Segformer leverages the overlapping patch merging technique to extract hierarchical features while preserving local continuity around the patches.
c) Transformer Decoder
The decoder part is simple compared to the modules in the encoder in the encoder part, we see that there are different features of different sizes in each layer the MLP layer in the decoder it’s a full MLP and this takes the features from the encoder and fuse them together. This All-MLP decoder is composed of four main steps:
Step 1
Features from the encoder it’s fed into the multi-layer perceptron layer to unify in the channel dimension

Step 2
The features are upsampled to 1X 4 of its size and are concatenated together.

Step 3
An MLP layer is adopted to fuse the concatenated features.

Step 4
Another MLP layer takes the fused feature to predict the segmentation mask M with a Ncls resolution, where Ncls is the number of categories.

(4) SegFormer Model Training and parameters
The input image dimensions were reduced from 256 × 256 to 128 × 128 by the feature_extractor to conform to the SegForemer model. The employed feature extractor is the Seg-FormerFeatureExtractor, derived from the pretrained Nvidia-segformer model. The instance of segformer_finetuner serves as a comprehensive encapsulation of the training and evaluation procedures. The SegformerFinetuner class is specifically developed to do fine-tuning on a Segformer model, with the objective of improving its performance in the task of semantic segmentation. The process starts by initializing the model, establishing data loaders for training, validation, and testing, and specifying the procedures for executing training and assessment processes. Significantly, the technique used involves the utilization of bilinear interpolation to increase the resolution of the model’s output to align with the resolution of the segmentation masks; this phase is crucial to verify that the predicted segmentation map accurately corresponds with the masks that represent the ground truth. The total number of trainable parameters amounted to 3.7 million. The batch size was intentionally set to 20 to introduce additional randomness during the training process as a means to address the presence of noisy gradients. This deliberate choice aimed to improve the model’s performance and generalization capabilities while mitigating the risk of overfitting.
This research evaluates the feasibility of implementing the Segformer model for landslide mapping in Japan, with the goals of reducing the amount of human error that occurs and increasing the amount of time that may be saved. We assessed the model by looking at its Precision, Recall, Mean Accuracy, and Average IoU.
The mathematical representation of these metrics is seen from Eq. 9 through Eq. 12.

Fig. 5. provides a clear explanation of the algebraic representations (TP, TN, FN, and FP) used in the mathematical formulas of the metrics employed to assess the performance of our models in landslide mapping using aerial photographs.

Model accuracy is crucial in evaluating machine learning, deep learning, and artificial intelligence models. Accuracy is the measure of correctly identified pixels for each class. The accuracy metric evaluates the accuracy of pixel identification for each class. Accuracy is determined by dividing the number of correctly classified pixels in a specific class by the total number of pixels in that class, as determined by the ground truth. Eq. 9 represents the mathematical relationship.
Precision is a metric that evaluates the capacity of a model to generate precise positive predictions. It addresses the inquiry regarding the proportion of accurately predicted positive instances among all instances predicted as positive. High precision indicates accurate predictions of the positive class by the model. Precision is of utmost importance in situations where false positives are expensive or undesirable. The primary objective is to minimize false positive errors. This mathematical relationship is represented by Eq.10.
Recall assesses a model’s ability to identify all positive cases out of total positive instances correctly. It replies, "Of all the actual positive cases, how many did the model correctly predict as positive?" High recall indicates the model captures the most positive examples, which is critical when missing one is costly. Eq.11 represents the mathematical expression.
The Intersection over Union (IoU), also known as the Jaccard similarity coefficient, is a commonly used metric. The IoU metric is commonly used to evaluate statistical accuracy, specifically penalizing false positives. The IoU is a metric for assessing pixel classification accuracy in individual classes. The calculation is represented by Eq. 1232).
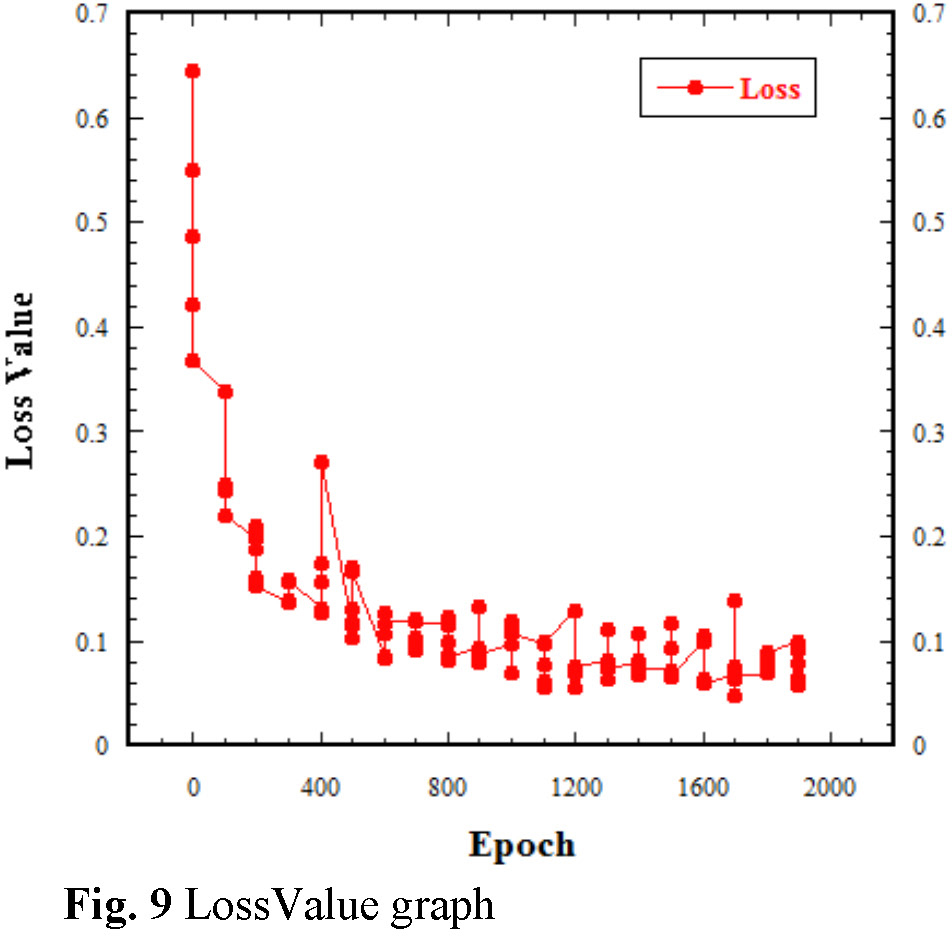
Table 3 displays the values of the Segfromer’s performance on our landslide dataset; also included is the Loss value of our model. Loss measures the deviation between a model’s prediction and the actual value. It quantifies prediction accuracy, with lower values indicating better performance. During training, the goal is to find optimal weights and biases that minimize the average loss across the dataset. The graphical representation of changes in these metrics is presented in Fig. 6 through Fig 9.




(1) Test Images Visualization
Fig.10 presents some instances of the prediction outputs generated by the Segformer model, which indicate its effectiveness in accurately identifying masks or annotations. The results demonstrate good outcomes, albeit with slight variations. Fig. 11 and 12 depict the model’s ability to delineate landslide-prone areas based on the provided photos. The randomly picked outputs exhibited substantial potential.



(2) Discussion
The results obtained through implementing the Segformer model for landslide mapping is noteworthy as all metrics are of high values, which indicates that the model will be suitable for detecting and mapping out landslide. The Accuracy and IoU values of 0.85 and 0.80, respectively, signify a commendable level of accuracy in pixel classification. These values are particularly significant, as they indicate the model’s capacity to identify landslide-prone areas, correctly reducing false positives and negatives. Precision at 0.92 underscores the model’s ability to make precise positive predictions. Recall, also at 0.92, implies that the model effectively captures most positive examples, minimizing human error in the manual process of identifying these regions and therefore increasing efficiency. Furthermore, the Loss value of 0.13 indicates the model’s ability to minimize the deviation between predictions and actual values.
Upon visualization, the models showed that it can detect these zones no matter how little the area on the image is, and it does that precisely, as seen in Fig. 12.
With the model performing well across all tests, the Segformer model can become another alternative model to be used in the segmentation process of landslide and landslide mapping.
This research has explored the application of the Segformer model for landslide mapping in Japan, a country prone to landslides due to its steep topography, seismic activity, and heavy rainfall patterns. The model performance was evaluated using metrics such as Mean Accuracy, Mean IoU, Precision, Recall, and Loss, we have observed promising results. The Segformer model demonstrated high accuracy (0.85) and mean IoU (0.80), indicating its effectiveness in pixel classification and precise identification of landslideprone areas. The model also exhibited high precision (0.91) and recall (0.91), signifying its ability to minimize false positives and negatives. Implementing the Segformer model provides several advantages, including its efficiency, scalability, contextual understanding, flexibility, and adaptability to limited data. It is well-suited for high-resolution image processing and can effectively capture both intricate details and broad semantic concepts. The model’s end-to-end training also eliminates the need for extensive post-processing steps, simplifying the landslide mapping process. Comparing the Segformer model’s performance to previous models such as CNNs and UNet, the Segformer model has shown competitive results. While CNNs have been widely used in image segmentation tasks, the Segformer model’s unique architecture and attention mechanisms contribute to its improved accuracy and efficiency. The Segformer model’s scalability and adaptability to different scenarios make it a valuable alternative and can aid more efficient mapping which also will support key decision-making processes. Future research should prioritize expanding the dataset to enhance the diversity and coverage of various regions besides Japan.
Without their assistance, this research would not have been possible. Also, thank Mrs Yukio Fumoto for her support during this work. No form of funding was received for this research.