Delineating Landslide and Debris Flow Detection in Japan through Aerial Photography: A YOLO v8 Approach to Disaster Management
2024 Volume 5 Issue 1 Pages 111-123
Details
2024 Volume 5 Issue 1 Pages 111-123
This study delves into the escalating challenge of landslides and debris flows in Japan, prompted by its unique topography and climatic conditions that render it vulnerable to geological hazards. Recognizing the pressing need for innovative solutions, the research focuses on the application of the YOLO v8 computer vision model. With a dataset comprising 1,352 aerial images from disaster sites, the study employs YOLO v8 for hazard detection and segmentation. The model exhibits a precision of 0.49 for detection and 0.76 for segmentation, reflecting its accuracy in positive predictions. Noteworthy recall values of 0.42 for detection and 0.54 for segmentation underscore the model’s proficiency in capturing positive cases. The mAP50, a comprehensive accuracy measure, stands at 0.39 for detection and 0.52 for segmentation, underscoring the model’s efficacy in hazard detection. The research emphasizes the instrumental role of AI in disaster management and advocates for the continuous exploration of innovative methodologies.
Japan, a country characterized by its geological dynamism, is well acquainted with the devastating impact of debris flows and landslides. Situated in a region characterized by steep terrains, frequent seismic activity, and intense rainfall, Japan is exposed to a heightened vulnerability to these natural hazards.
A debris flow is a dynamic mixture of unconsolidated materials such as mud, sand, soil, rock, water, and air that descends a slope due to the force of gravity. To qualify as a debris flow, the material in motion must possess a loose consistency and be capable of fluid-like movement. Additionally, at least 50% of the material must consist of particles that are the size of sand or bigger. Landslides are geological events characterized by the downward movement of rock, soil, or a mixture of both, caused by the gravitational force. Landslides can manifest in several forms, such as rockfalls, rockslides, rotational slides, and translational slides, each distinguished by distinct mechanics of movement1),2).
Table 1 outlines several distinguishing features of Debris and Landslides, while Fig 1 and 2 provide schematic illustrations elucidating the concepts of Debris flow and Landslides, respectively.



Both natural disasters pose significant threats to human settlements, infrastructure, and the environment and understanding and managing these geological hazards are of utmost importance for safeguarding lives and mitigating the impact of these natural disasters in Japan.
According to recent research, there has been a persistent upward trend in the occurrence of landslides in Japan. In 2020, approximately 1,500 landslides were reported, representing a notable 50% increase compared to the frequency observed in the previous decade3). Japan has experienced an increase in debris flows, which can be attributed to an increase in heavy precipitation events. The presence of mountains and forests, which make up about 70% of Japan’s land, is a significant factor contributing to this concern. Following extensive debris flows in certain areas of Hiroshima Prefecture in 2014 and 2018, researchers have observed a recurring pattern wherein debris flows typically initiate at a small scale before manifesting repeatedly, resulting in substantial destruction 2). Another fatal incident of debris flow occurred on the morning of July 3, 2021, at the Aizome River in the Izusan district of Atami, Shizuoka Prefecture. The debris flow caused extensive damage, causing the death of 26 people, leaving one person missing, and damaging 128 houses 4),5).
Leveraging topographical and geological datasets, Japan is presently engaged in a comprehensive research initiative aimed at identifying potential debris flow sites. Notably, endeavours are underway to deploy advanced sensors capable of detecting the nascent stages of debris flows. The data harvested by these sensors assumes a pivotal role in expediting the evacuation process for residents, contributing to a proactive approach to disaster management. This program represents a pioneering effort in presenting state-of-the-art research focused on mitigating the impact of debris flows, with a primary emphasis on enhancing public safety and minimizing the loss of human life. Concurrently, Japanese researchers are immersed in endeavors to refine methodologies employed in landslide mapping. This undertaking places a distinct emphasis on advancing techniques geared towards the production of highly precise landslide maps while concurrently minimizing the occurrence of inaccuracies. The overarching goal of this research is to augment the efficacy of disaster management protocols through the utilization of improved and meticulously crafted maps, thereby fortifying the nation’s resilience in the face of landslide-related challenges5).
Researchers in the field of environmental engineering and disaster management are progressively adopting the use of Artificial Intelligence (AI) and machine learning methodologies on a worldwide level. The motivation behind this adoption stems from their continuous endeavour to find efficient solutions to pressing environmental issues. The effective implementation of these techniques can mitigate human mistakes and streamline processing time. This current study uses photographs to utilise a computer vision model known as YOLO (You Only Look Once) version 86) to detect fallen trees, stones, debris flow patterns, and landslide zones.
The confluence of Japan’s challenging topography and climatic conditions heightens the likelihood of geological hazards, necessitating innovative solutions. In response, a pivotal study utilizes AI, particularly the YOLO computer vision model, and aerial photographs to enhance the probability of accurate and rapid hazard detection. The primary objective is to facilitate the creation of detailed maps pinpointing areas where these disasters are likely to have occurred. This forward-thinking approach addresses uncertainties and emphasizes a strategic stance in post-disaster management and risk management planning for the mitigation of the impact of geological hazards on human lives and critical infrastructure in Japan.
With rapid advancements in Machine Learning, Artificial Intelligence (AI), and Computer Vision, scholars have actively explored effective applications of these technologies in civil, environmental, and asset management fields. Notably, Opara7) employed YOLO V3, an advanced object detection algorithm, to address the challenge of identifying structural flaws, such as cracks and potholes, on asphalt pavement surfaces. This approach was implemented using images from Japan’s National Route 4, obtained via the Road Space Information Management System (RIM) survey vehicle. The results demonstrated a high precision value of 0.7, signifying accurate detection and classification of pavement defects, including longitudinal, transverse, alligator cracks, and potholes. The average Intersection over Union (IoU) measure, a vital object detection metric, reached 50.39%, affirming the methodology’s effectiveness in problem identification. This study underscores the potential of leveraging Machine Learning, AI, and Computer Vision techniques in the aforementioned domains.
Chun and colleagues have also achieved notable advancements in these fields by utilizing AI and machine learning techniques. The team has previously utilized deep learning and machine learning to detect cracks in concrete. They categorised bridge damage, assessed steel beam corrosion, and evaluated the durability of corroded steel8)9)10).
In the area of landslide mapping, detection, and analysis, scholars have made significant strides in adopting AI and machine learning models. Phong employed various artificial intelligence techniques, including support vector machines (SVM), artificial neural networks (ANN), logistic regression (LR), and reduced error-pruning tree (REPT), to construct a landslide susceptibility map for Vietnam’s Muong Lay district. The study evaluated these models using data from 217 landslide sites in the study area. The results favoured the Support Vector Machine (SVM) model, demonstrating superior performance. The study recommends adopting SVM for landslide susceptibility models, emphasizing its efficacy in this and other regions. However, it’s crucial to note that model effectiveness hinges on selecting appropriate parameters for dataset learning11).
In a study undertaken by Ado12) an extensive investigation was carried out to examine the various machine learning (ML) models utilized in the context of landslide susceptibility mapping. The author’s research emphasized the increasing attention and favourable results, underscoring the need for scholars to investigate diverse methodologies for enhancing landslide mapping through the utilization of Deep- learning and hybrid models.
Zhang employed machine learning techniques to create a susceptibility map for debris flows in the Shigatse region of Tibet, China, following an evaluation of the primary factors that cause debris flows. This study employs five machine learning methods, namely back propagation neural network (BPNN), one-dimensional convolutional neural network (1D-CNN), decision tree (DT), random forest (RF), and extreme gradient boosting (XGBoost), to analyze and model the relationship between debris flow triggering factors and occurrence. Additionally, the weight of each triggering factor is evaluated. The DFS maps have been validated using five evaluation metrics: Precision, Recall, F1 score, Accuracy, and area under the curve (AUC). The XGBoost model outperformed the BPNN, DT, and RF models in terms of mean accuracy (0.924) on ten-fold cross-validation. Its performance was significantly better than the other models, which achieved accuracies of 0.871, 0.816, and 0.901, respectively. The performance of XGBoost did not significantly differ from that of the 1D-CNN (0.914). The author highlighted the importance of using the XGBoost model in debris flow mapping to improve decision-making in disaster management13).
In the context of our study area, Japan, Kazuki’s research in 2021 shed light on the practices of the Geospatial Information Authority of Japan (GSI) in generating maps of areas affected by landslides or debris flows for damage assessment purposes. Kazuki noted that the existing process employed by GSI is not highly efficient and requires considerable time for technical experts to manually interpret the collapsed areas. He proposed an approach for the identification of landslides through the utilization of Semantic Segmentation, employing deep learning techniques on aerial images and compared the results of detection with different training data to improve the efficiency of locating landslides14). proposed that employing machine learning techniques has significant potential for evaluating damages caused by natural disasters, which can aid in effective disaster management planning. The author recommended exploring multiple techniques, particularly in Japan, to enhance the accuracy of damage assessment. This study aims to address this recommendation.
(1) Study Area and Data Collection
1,352 aerial images were collected from the regions specified in Fig. 3, documenting instances of landslides and debris flows.
Table 2 presents the locations and the quantity of aerial photographs utilized in this study, which were collected in Japan.


(2) Data Preparation
The images were annotated using an online data annotation platform called Roboflow: Roboflow provides a significant advantage in annotation for computer vision tasks. Its annotation capabilities enable efficient annotation datasets; this streamlines the annotation process, saving valuable time and effort.
The aforementioned table reveals a constraint within the dataset, prompting the implementation of data augmentation to enhance its quality. According to academic research, using data augmentation techniques has enhanced a model’s predictive accuracy by a minimum of 5% 15). The present study employs the rotation technique as the chosen augmentation method, as illustrated in Fig. 4.

Upon implementing the rotation augmentation technique, the whole dataset was expanded to 2736 pictures, with a distribution outlined in Table 3. The data was entered into the model that was used for this study.

(3) Model
The research employs YOLOv8, a computer vision model recently developed by Ultralytics, the same inventors of YOLOv5. The YOLO v8 model provides inherent capabilities for applications such as object identification, categorization, and segmentation. The functionality may be accessible either through a Python package or a command line interface 16), this versatility aligns with the specific requirements of our research.
The concept of YOLO was initially proposed by Redmon in 201517). YOLO employs a single neural network to directly predict bounding boxes and class probabilities from complete images in a single evaluation. The entire detection pipeline is a unified network, enabling direct optimization of YOLO for detection performance. The YOLO architecture demonstrated exceptional speed, achieving real-time image processing at a rate of 45 frames per second18).
Over the years YOLO has undergone several iterations and adaptations, including YOLOv1, YOLOv2 , YOLOv3, .......YOLOv8. These versions of YOLO have integrated various improvements and optimizations, such as enhanced accuracy, improved computational efficiency, and expanded object detection capabilities. The enhancements to the YOLO models in object detection were accomplished by making changes to the network design, training procedures, and utilizing different object detection backbones. Hussain19), discussed these significant changes in these versions and their performance in defect detection.
1) YOLO V8 Features
YOLOv8’s key features and improvements:
1. Anchor-Free Detection: YOLOv8 utilizes anchor-free detection by directly predicting bounding boxes and class probabilities from the grid cells of the input image, eliminating the need for predefined anchor boxes. This approach decreases hyperparameters and enhances the model’s capacity to detect objects of different sizes.
2. New Convolutional Layer (CSPDarknet53): YOLOv8 introduces a new convolutional layer structure called CSPDarknet53, which enhances the model’s feature extraction capabilities while maintaining computational efficiency.
3. C2F Block: The C2F block is a novel component that replaces the traditional YOLO neck architecture. It serves as a feature fusion and upsampling module, effectively combining features from different backbone layers and upscaling them to appropriate resolutions for object detection.
4. SPPF Block: YOLOv8 employs an enhanced version of the Spatial Pyramid Pooling (SPP) block, called the SPPF (Spatial Pyramid Pooling Fast) block. This block effectively generates a fixed-size feature representation of objects of varying sizes, enabling robust object detection across a wide range of scales.
5. Improved Loss Function: YOLOv8 utilizes a modified version of the CIoU (Complete Intersection over Union) loss function, which provides better handling of small objects and improves overall detection accuracy.
The aforementioned features influenced our decision to adopt YOLO v8 for our research due to its ability to perform both detection and segmentation tasks.
2) YOLO V8 Architecture
The YOLO architecture comprises three main components: the backbone, neck, and head. The backbone is a deep learning architecture responsible for feature extraction, while the neck integrates features from different layers of the backbone. The output of the object detection model includes predicted classes and bounding box regions.
A comprehensive understanding of the YOLO v8 architecture requires familiarity with its key components, namely the Convolutional, C2F, SPPF, and Detect blocks.
The convolutional block depicted in Fig. 5 is the most commonly used in YOLO v8. It comprises a 2D convolutional layer, a 2D batch normalization layer, and a SILU activation function. The combination of these elements results in a coherent convolutional block.

The fundamental parameters of a convolutional block include the kernel, stride, and padding.
1. Kernel: The kernel is a 2D array known as a feature detector. The feature detectors’ weights are updated during training. The input image is convolved with a kernel, resulting in a feature map (F-map) Fig 6.

2. Stride: Stride is the displacement distance during the convolution process. A smaller resulting output corresponds to a larger stride. In convolution with a stride of one, each step of the kernel is demonstrated in Fig. 7

3. Padding: Padding involves adding values to the outermost elements of the image. In PyTorch, there are different types of padding. The default is Zeros padding, where the padded pixels have a value of zero. Replication padding is another type, where the padded pixels assume the same value as the nearest real pixel, and the padded corners mirror the values of the real corners, Fig. 8 illustrates this.


The next block in the YOLO v8 architecture is the C2F block, as shown in Fig. 10 This block includes a convolutional block, and the resulting F-maps are then split in this block. One branch routes the features to the bottleneck block, while the other branch directly inputs them into the concat block. The C2F block can consist of several bottleneck blocks, followed by an additional convolutional block. The bottleneck block consists of a sequence of convolutional blocks that resemble a ResNet block. The main difference is the absence of a shortcut in the presence of a bottom neck, as shown in Fig. 10.

Next is the SPPF block, a significant component in the YOLO v8 architecture, depicted in Fig. 11, SPPF stands for spatial pyramid pooling fast, which is an enhanced version of spatial pyramid pooling that offers improved speed. Within the SPPF block, there are convolutional blocks at the start, followed by a 32d max pooling layer. Notably, each resulting F-map is concatenated just before the conclusion of the SPPF block, which concludes with a convolutional block.

The final essential element in the YOLO v8 design is the Detect block, located in the Head section where the system carries out its detection procedure. YOLO v8, in contrast to previous versions, utilizes an anchor-free model and modifies its prediction technique to work inside individual grid cells. The Detect block, seen in Fig. 12, consists of two tracks: the first track is dedicated to predicting the bounding box, while the second track is focused on predicting the class. Both tracks adhere to the same sequence, comprising of two convolutional blocks followed by a solitary 2D convolutional layer. This design specifically incorporates the distinctive predictive process that is characteristic of YOLO v8.

In Fig 13, the structural organization of the entire YOLO v8 code is illustrated. It can be observed that each block within the model is designated with a numerical identifier. The numerical labels are associated with the architecture file, yolo.yl, and start from the initial Convolutional (Conv.) Block in the Backbone section indicated as zero(0), and extend until the final c2f block represents the paths and sequence of the connection.

In the YOLO v8 variant, there exist three parameters that define its characteristics. These parameters include depth_multiple (d), width_multiple(w), and Max_channels (mc). The depth_multiple parameters are responsible for determining the number of bottom neck blocks present in the c2f block. The output channel is determined by the width_multiple and Max_channels.
In the YOLO v8 model, the input image typically consists of three channels. This image is then fed into the backbone section, which is composed of multiple convolution layers. These convolution layers are responsible for extracting specific features at different resolutions. Commencing with two convolutional blocks as illustrated and employing the subsequent parameters: kernel size = 3, stride = 2, and padding =1. Is important to note that when the stride value is set to 2, the output resolution that will be passed to the next block is halved. In this case, if the input resolution in the first convolution of the block is 640 × 640, the output resolution will be 320 × 320. The output resolution post-processing will be 320 × 320.
Equation 1 represents the formula for obtaining the output channel (OC) computation of output channel values as derived from the YOLO v8 code.

For the specific case of the first convolutional block in the YOLO v8 variant with a width multiple of 1 and a maximum channel limit of 512, and given a base output channel of 64, the calculation is as follows:

64 is the output channel in the first convolution block in the YOLO v8 model.T his same process is applied to the second convolutional block and the the output is passed to the next block which is the c2f block.
Moving on to the c2f block, housing parameters like shortcut and N. The shortcut parameter is "True," indicating the utilization of the shortcut on the bottleneck block. N determines the number of bottleneck blocks and is calculated by multiplying the depth multiple (d) value by three.
Subsequently, another convolutional block follows with a kernel = 3, stride = 2, and padding =1. The c2f block ensues with shortcut parameters "True" and N = 6 × depth_multiple (d). The output of this block is connected to the neck. Similar convolutional blocks and c2f blocks follow, maintaining the "True" shortcut parameters and N parameters = 6 × depth_multiple(d). Afterwards, a c2f block with shortcut parameters "True" and N = 3× depth_multiple(d), is connected to the SPPF block. SPPF, employed after the last convolutional layer on the backbone, aims to generate a fixed feature representation of objects of various sizes in an image without resizing or introducing information loss.
Subsequently, the output is transmitted to the neck section blocks of the model. The initial component is an upsampling layer located in the neck region. This layer increases the resolution of the F-map in the SPPF to match the resolution of the corresponding c2f block. The upsampled F-map is concatenated with the features from this c2f block using the YOLO v8 variant’s concatenation approach. If the output of this c2f block is denoted as 40 × 40 × 512 and the upsampled output is 40 × 40 × 512, the resulting concatenation is 40 × 40 ×1024.
The output weights are then directed to the subsequent block in the neck section, which is another c2f block. These c2f blocks do not utilize shortcuts and imply the shortcut parameter is set as "False", with the value of N being 3 × depth_multiple(d). The resolution of the c2f block F- map is upsampled to match the resolution of the F-map of the preceding c2f block in the backbone, before the last c2f block that was concatenated. Using concatenation, the upsampled F-map is combined with the F-map from this c2f block and fed into the next c2f block. This block reduces the channel size of the F-map, which is then utilized as an input for the first detect block in the head. This detect block specializes in detecting small objects, and its output is also employed as an input to the subsequent convolutional block in the neck. This convolutional block uses a kernel = 3, stride = 2, and padding =1, resulting in a halved resolution due to the stride value.
Continuing, concatenation is applied to combine the F-map from this convolutional block with the F- map from the initial c2f block in the neck section. The output is then directed to another c2f block, reducing the channel size of the F-map. The F-map of this block serves as an input for the next detect block in the head, specializing in detecting medium-sized objects. The output of this block is also employed as input for the convolutional block in the neck, using a kernel = 3, stride = 2, and padding =1. Concatenation is applied to combine the F-map from this convolutional block with the F-map from the SPPF block.
Finally, there is another c2f block, and its F-map is utilized as an input for the final detect block. This detect block is tailored for detecting large objects.
3) Training parameters
The YOLO v8 model was trained using images with a resolution of 640 x640. The total number of trainable parameters was 71,752,774. Additional key parameters can be found in Table 4.

The objective is to utilize the YOLO v8 model to detect and predict landslides and debris flow based on aerial images obtained from disaster sites in Japan. The primary objective is to minimize human error in the replication of disaster area maps, as it is currently done, to optimize efficiency, save time, and reduce costs.
The selection of YOLO v8 for this study is driven by its demonstrated effectiveness in both segmentation and detection tasks, underscoring its suitability for our research objectives. To assess the performance of the YOLO v8 model, Mean Average Precision (mAP) is employed as the evaluative metric. mAP serves as a comprehensive metric for object detection models, including Fast R-CNN, YOLO, Mask -RCNN, among others. This metric involves calculating the mean of Average Precision (AP) values across recall values ranging from 0 to 1. The mAP formula is based on key sub-metrics, including Confusion Matrix, Intersection over Union (IoU), Recall, and Precision. We also evaluated the Dice Coefficients known as the F1-score. The mathematical representation of these metrics is elegantly expressed through Equations 2 to 6.



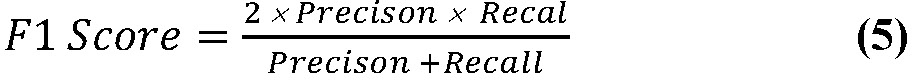

Fig. 14. provides a clear explanation of the algebraic representations (TP, TN, FN, and FP) used in the mathematical formulas of the metrics employed to assess the performance of YOLO v8 model in landslide and debris flow mapping using aerial photographs.

Precision is a metric that evaluates the capacity of a model to generate precise positive predictions. It addresses the inquiry regarding the proportion of accurately predicted positive instances among all instances predicted as positive. High precision indicates accurate predictions of the positive class by the model. Precision is of utmost importance in situations where false positives are expensive or undesirable. The primary objective is to minimize false positive errors. This mathematical relationship is represented by Eq. 2.
Recall assesses a model’s ability to identify all positive cases out of total positive instances correctly. It replies, "Of all the actual positive cases, how many did the model correctly predict as positive?" High recall indicates the model captures the most positive examples, which is critical when missing one is costly. Eq. 3 represents the mathematical expression. The Intersection over Union (IoU), also known as the Jaccard similarity coefficient, is a commonly used metric. The IoU metric is commonly used to evaluate statistical accuracy, specifically penalizing false positives. The IoU is a metric for assessing pixel classification accuracy in individual classes. The calculation is represented by Eq. 422). For YOLO v8, IoU serves as a parameter that is utilized to assess the model’s performance during training and to determine the optimal boxes during inference.
Eq. 5 represents F1- score, F1- score is a machine learning evaluation metric that measures a model’s accuracy. It combines the precision and recall scores of a model.
The equation for mAP is presented as Eq. 6, where AP represents the average precision. AP is calculated as the weighted mean of precisions at each threshold, with the weight determined by the increase in recall from the prior threshold and N here represents 23)
YOLO v8 excels in both detection and segmentation tasks, outperforming other machine learning models by providing not only bounding boxes around areas of interest but also detailed masks that accurately outline the exact region and shape of the target area. Additionally, YOLO v8 goes beyond mere detection by classifying objects with confidence scores, offering valuable insights into the model’s certainty in its predictions.
Table 3 summarizes the performance metrics of YOLO v8 on our dataset, highlighting its strengths in both detection and segmentation.

The graphical depiction of the variations in these metrics is illustrated in Fig. 6 through 9.




(1) Test Images Visualization Discussion



Fig.19 presents some instances of the prediction outputs generated by our YOLO v8 model for landslide predictions, Fig.20 presents some instances of debris flow, while Fig.21 presents instances where the model was able to differentiate between landslide and debris flow although the confidence score wasn’t promising, the potential shows that if more data is trained the model could have a better precision in detecting these disasters from aerial photographs which indicate The randomly picked outputs exhibited substantial potential.
The YOLO v8 model exhibited promising performance in detecting landslides and debris flows from aerial photographs, achieving satisfactory precision, recall, mAP50, and F1_Score values. The model’s precision, indicating the proportion of accurate positive predictions, was 0.49 for detection and 0.76 for segmentation. This suggests that the model correctly identified landslides and debris flows in 49% of detection instances and 76% of segmentation instances. The recall, representing the model’s ability to capture all positive cases, was 0.42 for detection and 0.54 for segmentation. This implies that the model detected or segmented 42% of landslides and debris flows in detection tasks and 54% in segmentation tasks. The mAP50, a comprehensive measure of accuracy, reached 0.39 for detection and 0.52 for segmentation. While the detection mAP50 was lower, the segmentation mAP50 was higher, indicating the model’s superior ability in segmentation compared to detection. The F1_Score, a balance between precision and recall, was 0.44 for detection and 0.56 for segmentation. The lower detection F1_Score is understandable given the inherent difficulty of detection tasks compared to segmentation. Overall, the YOLO v8 model demonstrated satisfactory performance in detecting and segmenting landslides and debris flows from aerial photographs. The model’s strengths lie in its segmentation capabilities, achieving higher precision, recall, and mAP50 scores compared to detection.
This study delves into the application of the YOLO v8 model for detecting landslides and debris flows in aerial photographs captured in Japan. The model’s performance, assessed through key metrics, presents promising potential. To further enhance the YOLO v8 model, it is suggested to augment the dataset with diverse debris images, a measure anticipated to boost its overall effectiveness. Moreover, ensuring equitable datasets for all classes could contribute to refining the model’s precision. This proposed approach not only strengthens hazard detection capabilities but also aligns with a proactive disaster management strategy, essential for safeguarding lives and critical infrastructure in Japan.
I thank Kazuki Kanai for facilitating the data collection and annotation process. Without their assistance, this research would not have been possible. Also, thank Mrs Yukio Fumoto for her support during this work. No form of funding was received for this research.