Synopsis:
Accurate estimation of the standard production time in steel plate mills is crucial for
making successful production plans. Due to the complicated and stochastic processes of the
steel plate mills, it is challenging and time-consuming to build precise mechanistic
models which enable the estimation of the precise production time. To overcome this
limitation, we propose a method to estimate the accurate standard production time from the
historical process data instead of mechanistic models. In our method, decision trees are
employed to identify the process flow for each order. Then the probability distribution of
the process time for each process is computed by means of the maximum likelihood
estimation. These probability distributions are combined into one probability distribution
of the total production time in accordance with the predicted process flow. Finally, the
standard production time is defined as the corresponding time with cumulative density
function of the probability distribution at the specified confidence level. Real world
steel production process data have been used to examine the effectiveness of the proposed
approach. The results demonstrate that the new standard production time can increase the
rate of production completion no later than the deadlines as well as shorten the average
production time one to three days.
1. 緒言
厚板の製造プロセスは,他の鉄鋼品種と異なり圧延以降の精整工程が長い(工程数が多い)ことが特徴であり,近年増加している難製造材の製造比率に応じて,1枚当たりの通過工程数も増加している。このため,精整工程の負荷が全体として増加傾向にあり,注文の品種構成によっては,1つの精整工程に負荷が集中してしまい,工場全体のスループットが低下してしまうこともある。一方,厚板の需要家は船舶や産業機械・橋梁などを製造するメーカーであり,変化の速いマーケットに追従するため,短納期の要求が強くなってきている。厚板はサイズ・強度・耐食性など需要家の細かな要求に合わせた受注生産方式を取っているため,短納期の要求を満足させるためには,短工期で製造しなければならず,そのためには,注文毎の製造負荷を下げることは勿論のこと,精整工程の負荷を平準化させ,1つの工程に負荷を集中させないように生産管理することも重要となる。
しかしながら,鉄鋼業は他の組立産業と異なり,原料のばらつきが大きいこと,高温・大重量物を取り扱うことから製造のばらつきも大きく,製造工期に対する不確実性が大きい産業である。厚板の場合(薄板や鋼管も同様であるが),精整工程の数が多いだけでなく,手入や矯正など製造後に通過有無が決定される発生工程も考慮して生産管理を行わなければならない。このため,注文毎に製造工期と製造負荷を正確に予測しなければならないが,厚板製品はサイズや強度・靭性・耐候性・耐摩耗性・溶接性など製造仕様のバリエーションが豊富であり,その仕様に応じて工程の通過頻度が変わるため,製造工期や製造負荷を正確に予測することは容易ではない。
もし,製造プロセスに仕掛待ちが存在せず,製造工期が各プロセスの処理時間と移動時間の合計値で求まるような場合は,製造工期の予測はそれほど難しくない1)。しかし,厚板プロセスでは,各工程の前に仕掛山が存在し,処理時間より仕掛待ち時間の方が圧倒的に長い特徴がある。このため,製造工期は各工程前の仕掛待ち時間の合計と考えても良い。製造工期や製造負荷を予測する方法の1つは,対象とするプロセスを模擬するシミュレータを造ることである。対象とするプロセスが比較的簡単であり,不確実性も少ない場合には,シミュレータを作成するアプローチが取られることも多い2,3)。各製品の処理時間や移動機の搬送時間をシミュレータに設定し,物流を模擬するシミュレータを造ることで,各製品の製造工期や各プロセスの仕掛状況など詳しい情報が得られる。本研究で対象とする厚板プロセスでも過去にシミュレータの作成を試みたことがある。しかし,厚板プロセスは大規模複雑であり,かつ,製品の種類も無数に存在するため,シミュレータの製作にはかなりの時間とコストが掛ること,確率的に通過有無が決まる発生工程も存在するため,確率現象を模擬するシミュレータとしなければならず,異なる乱数系列で何度もシミュレーションを繰り返す必要があるため,かなりの計算時間も掛ること,シミュレーションの初期状態を得るためには,すべての製品の詳細な位置情報やプロセスの稼働状況までも必要となるなどの理由で,実業務で使用できるレベルのシミュレータを完成させることができなかった。
本研究では,このように,大規模複雑・不確実性の大きい製造プロセス,特に厚板プロセスを対象として,製造工期の標準値(以下,標準工期と記載)の算出方法と,そのために必要となるばらつきも考慮した製造工期の予測方法に関して考える。ばらつきも考慮する必要がある理由は,標準工期は注文の製造に必要とされる標準的な日数として定義され,受注可否判断や製造着手日の算出に使われる基準値のため,標準工期はばらつきを考慮して定めなければならないからである。製造工期のばらつきには,発生工程の通過有無,工程毎の仕掛量,日常的なトラブル,工事やメンテナンスなど,様々な要因がある。本研究では,これらのうち,計画的に行われる工事やメンテナンス以外を全て確率現象と仮定して製造工期の確率分布を予測する。なぜなら,本研究の目的は,注文それぞれの製造工期を予測することが目的ではなく,営業活動にも使用する製造工期の標準値を算出することが目的であり,注文の引き合い段階でこれらは明確ではないからである。このため,本研究では標準的な操業状態における製造工期を予測する。従って,使用する実績データからは工事やメンテナンス期間を除外する。また,標準的な操業状態も経済状況や注文構成変化により変わるため,定期的に直近の実績データを用いて予測モデルを造り直すことでその変化に追従させる。
製造工期を予測する手法として,Nishiokaら4)は待ち行列理論を基づいた手法を提案している。この方法は,各工程の平均到着率や平均処理時間などから各工程の所要時間(処理待ち時間を含む所要時間)を予測し,注文が通過するすべての工程の所要時間を積算することで全体の製造工期を予測する手法である。本研究でも基本的なアプローチはこの方法と同じであり,各工程の所要時間を予測して,それらを注文の通過工程に合わせて積算している。しかし,先行研究では工程毎に平均到着率や平均処理時間などの細かなパラメータが判っている必要があるが,すべての工程で正確に判っているとは限らないため,本研究では工程のパラメータは未知として,実績データから工程の所要時間に関わるパラメータを推定している。ただし,必ずしもすべての工程の所要時間を推定する必要はなく,平均到着率や平均処理時間などが正確に判っている工程に関しては,先行研究の手法により所要時間を求め,それ以外の工程を本研究の手法を用いても良い。
さて,製造工期を予測する方法として,機械学習のような予測手法を用い,注文の製造仕様を説明変数として製造工期を目的変数とする予測モデルを構築することもできる。しかし,このような予測モデルとすると,予測値の説明性に乏しいため,新たな品種の追加や工程能力の変化に対して弱く,また,製造負荷予測との一貫性がない予測モデルとなってしまう。そこで,精整工程の通過パターン(通過有無の組合せ)と製造工期との間に相関があることを利用し,製造仕様から精整工程の通過パターンを予測した後,この通過パターンに大括り品種を表す分類コードを付加した文字列(製造品種と呼ぶ)を1つのまとまりとし,この製造品種ごとに製造工期の確率密度関数を予測する方法とした。本稿では,厚板製造プロセスの概要と製造工期の確率密度関数に関して考察した後,通過パターンを予測するモデルと,製造工期の予測モデルに関する検討結果を述べ,最後に,本手法に基づき生産管理を行った場合の効果を示す。
2. 厚板製造プロセスと製造工期
2・1 厚板製造プロセス
厚板製造における圧延以降の主要工程をFig.1に示す。加熱炉で約1200°Cまで加熱されたスラブは,粗圧延機と仕上圧延機で所定のサイズまで成形される。次に,冷却精度の安定化のため形状が整えられ,所定の結晶組織が得られるよう加速冷却装置にて水冷された後,冷却床にて自然放冷される。加熱炉から冷却床までを圧延工程と呼び,全ての鋼板が通過する。これ以降を精整工程と呼び,Fig.1に示されているのは代表的な設備のみであるが,熱処理,ガス切断,矯正,UST(超音波探傷装置),塗装など数多くの工程が存在する。注文の通過工程は,注文の製造仕様に応じて決定される仕様工程(熱処理,塗装など)と,製造途中で通過有無が決まる発生工程とがある。Fig.1において,実線で囲まれた工程は仕様工程,波線が発生工程であり,USTは両方の側面を持つ工程である。本稿において,製造工期とは仕上圧延日から出荷準備が整うまでの時間を意味し,厚板工場内に滞在している時間とほぼ同じである。ただし,立会日は需要家のスケジュールにより左右されることから,立会に要した時間は製造工期から除外し,純粋に製造に要した時間を製造工期と定義する。
精整工程の数は工場毎に異なり,約12~22工程が存在する。通過工程のパターンの数(通過有無の組合せ数)は,汎用鋼のみ製造している工場では300通り程度であるが,特殊鋼も製造している工場では1,000通りにもなる。製造工期はそれぞれの通過パターン毎に異なり,多くの工程を通過すると製造工期は長くなり,少ない工程の場合には短くなる傾向にある。
2・2 製造工期
次に,製造工期の分布形状に関して考察する。ある期間にある工場で製造された約20万枚のプレートの実績通過パターンを集計し,そのうち2,000枚以上通過した12通りの通過パターンの製造工期の平均値と標準偏差をTable
1に示す。ここで,通過パターンの各ビットは1つの精整工程に対応し,その工程の通過有無(0:非通過,1:通過)を表す。また,製造工期の値は,全プレートの標準工期の平均値が1となるように規格化している。このように,通過パターン毎に製造工期の平均と標準偏差は大きく異なる。
Table 1.
Production time of process flow.
| No. |
Process flow |
The number of plates |
Production time |
| Average |
Standard deviation |
| 1 |
0000000000000000000 |
104,836 |
0.02 |
0.09 |
| 2 |
0000000001000000000 |
22,311 |
0.06 |
0.12 |
| 3 |
0000010100000000000 |
13,485 |
0.33 |
0.35 |
| 4 |
0000100000000000000 |
8,234 |
0.06 |
0.14 |
| 5 |
0000000101000000000 |
7,287 |
0.36 |
0.33 |
| 6 |
0001000000000000000 |
4,370 |
0.34 |
0.31 |
| 7 |
0001100000000000000 |
4,289 |
0.34 |
0.31 |
| 8 |
0000010101000000000 |
4,110 |
0.37 |
0.35 |
| 9 |
0000100001000000000 |
2,777 |
0.10 |
0.16 |
| 10 |
0000010000000000000 |
2,744 |
0.08 |
0.19 |
| 11 |
0100010100000000000 |
2,712 |
2.03 |
0.94 |
| 12 |
0000000100000000000 |
2,556 |
0.26 |
0.29 |
|
..... |
..... |
..... |
..... |
| Total |
0.19 |
0.43 |
Table
1の通過パターンのうち,No.2,No.5,No.11の通過パターン(ガス切断,UST,焼入,冷間矯正の工程を含む)の製造工期のヒストグラムをFig.2に示す。このように,製造工期は右裾の長い左右非対称の分布となっている。さて,工程が1つのみで,ランダムに製品が到着するのであれば,製造工期は指数分布となり,同じ能力の工程が複数台直列につながって,製品がすべての工程を通過するのであれば,製造工期はアーラン分布となることが知られている12)。ただし,厚板製造プロセスでは,それぞれの工程能力は異なり,かつ,通過パターンもさまざまであるため,アーラン分布にはならない。そこで,右裾の長い代表的な分布として,アーラン分布を一般化させたガンマ分布と,対数正規分布の2つを対象として,厚板の製造工期との差異を検討した。フィッティング方法としては,Table 1の製造工期tの平均値aと標準偏差sが,対数正規分布f(t, μ,
σ)およびガンマ分布f(t, k,
θ)の平均値と標準偏差と等しくなるように,それぞれのパラメータを式(1)と式(2)のように決定した。通過パターンNo.2,No.5,No.11の製造工期のヒストグラムと,対数正規分布,ガンマ分布を重ねて描画したグラフをFig.3に示す。Fig.3のように,対数正規分布もガンマ分布も製造工期の分布を良くフィッティングしているが,対数正規分布の方が実際の製造工期に合っているようである(特に(b)参照)。
|
μ
=
ln
(
a
)
−
σ
2
/
2
,
σ
2
=
ln
(
1
+
(
s
/
a
)
2
)
| (1) |
|
k
=
(
a
/
s
)
2
,
θ
=
s
2
/
a
| (2) |
他の通過パターンでも確認するため,同期間で100枚以上通過した50種類の通過パターンに対して,それぞれ平均対数尤度を式(3)より計算した結果をTable
2に示す(Nはある通過パターンのプレート数,tnは各プレートの製造工期の実績値)。Table 2のように,大きな差はないが,厚板の製造工期は対数正規分布の方が合うことが判った。
|
Average
log
likelihood
=
∑
n
=
1
N
ln
(
P
(
t
n
)
)
/
N
| (3) |
Table 2.
Average log likelihood of process flow.
| No. |
Process flow |
The number of plates |
Average log likelihood |
| Log normal |
Gamma |
diff. |
| 1 |
0000000000000000000 |
104,836 |
–0.71 |
–0.69 |
–0.02 |
| 2 |
0000000001000000000 |
22,311 |
–1.33 |
–1.45 |
0.11 |
| 3 |
0000010100000000000 |
13,485 |
–2.66 |
–2.72 |
0.06 |
| 4 |
0000100000000000000 |
8,234 |
–1.18 |
–1.14 |
–0.05 |
| 5 |
0000000101000000000 |
7,287 |
–2.63 |
–2.72 |
0.09 |
| 6 |
0001000000000000000 |
4,370 |
–2.61 |
–2.67 |
0.05 |
| 7 |
0001100000000000000 |
4,289 |
–2.60 |
–2.67 |
0.07 |
| 8 |
0000010101000000000 |
4,110 |
–2.69 |
–2.77 |
0.08 |
| 9 |
0000100001000000000 |
2,777 |
–1.64 |
–1.74 |
0.10 |
| 10 |
0000010000000000000 |
2,744 |
–1.49 |
–1.73 |
0.24 |
| 11 |
0100010100000000000 |
2,712 |
–4.19 |
–4.11 |
–0.08 |
| 12 |
0000000100000000000 |
2,556 |
–2.39 |
–2.50 |
0.11 |
|
..... |
..... |
..... |
..... |
..... |
| Total |
–1.48 |
–1.51 |
0.02 |
ただし,Table
2のように,必ずしも対数正規分布の方が合っている訳ではなく,ガンマ分布の方が合っている場合もある。その傾向を掴むため,前記50種類の通過パターンに対して,製造工期の平均値と平均対数尤度の差異との関係を表す散布図を描くとFig.4のようになった。この図のように,製造工期が短いときには対数正規分布の方が比較的当てはまり易いが,製造工期が長くなるにつれ,ガンマ分布の方が当はまるようである。対数正規分布は設備の故障頻度などで使われる分布,ガンマ分布は待ち行列などで使われる分布であるが,仕掛が少なく短期間で通過する工程を通過する場合には,各工程の軽度のトラブルに製造工期が支配され,製造工期が長い場合には,仕掛待ち時間に製造工期が支配されるのではないかと推測される。いずれにせよ,大きな差ではないため,以下では製造工期は対数正規分布に従うとする。
2・3 現状の製造標準工期
標準工期とは注文の製造仕様に基づいて決定される値であり,その注文をほぼ確実に製造できる時間である。従来の標準工期はFig.5のような構成のテーブルで管理されており,ベース工期,精整工期,規格余裕,検査余裕,需要家余裕に大別され,さらにそれらが細かく分類されていた。そして,注文仕様から各テーブルの値を参照し,それらを式(4)のように合計し,標準工期を計算していた。ただし,精整工期は,注文仕様から判断可能な仕様工程の工期のみ考慮しており,発生工程の工期は規格余裕などに組み入れていた。
|
Old
standard
production
time
=
Base
time
+
∑
Process
time
+
Some
margins
| (4) |
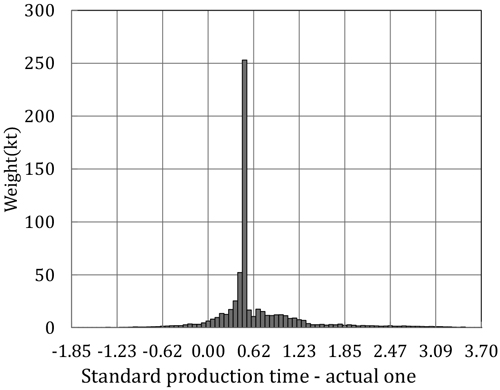
テーブルの各数値は,納期遅れ等のトラブル発生時に多少の見直しはされているが,製鉄所の操業実態と合っていないことが問題となっていた。例えば,ある製鉄所では実績製造工期(以下,実績工期と記載)の平均値は0.34であり,標準工期の平均値(=1)と比べると,十分に余裕があるような印象を受けるが,余裕日数(標準工期−実績工期)のヒストグラムはFig.6のようになっており,納期以内に製造完了した割合(「標準工期≧実績工期」の割合)である荷揃達成率は91.5%に留まっていた。ここで,納期は製造完了の目標日時であるため,荷揃達成率を100%にする必要はないが,計画通りに製造できなかった割合を示す数値であるため,高い方が望ましい。
単純に標準工期を長くすれば,荷揃達成率を向上させることが出来るが,需要家に対して現状より長い工期を提示することになり,競争力の低下を招いてしまう。また,倉庫の在庫量も増加するため,倉庫ネックになってスループットが低下することも懸念される。従って,荷揃達成率の維持向上と,短工期化を両立させるためには,標準工期の精度を向上させ,Fig.6のヒストグラムを鋭く尖った形状にする必要がある。
3. 新しい製造工期予測モデルと製造標準工期
3・1 新しい製造工期予測モデルの構成と製造標準工期の算出方法
標準工期の精度を向上させるためには,実績データを分析し,注文毎の製造工期の確率密度関数P(t|製造仕様)を正確に予測する必要がある。注文の製造仕様のバリエーションが少なく,同一仕様で製造されるプレート枚数(標本数)が多ければ,同一仕様で製造されたプレートをひとまとまりとして,それらの実績工期のヒストグラムを対数正規分布等の確率密度関数で近似すれば良いが,厚板は多品種小ロット生産のため,少ないロットの製造工期は正確に予測することができない。また,製造仕様から製造工期を直接予測するアプローチも考えられるが,予測モデルがブラックボックスとなってしまうため,設備更新時の製造工期への影響が予測できないモデルとなってしまう。例えば,手入工程の所要時間を10%短縮させたときに,製造工期の改善代を見積もる際にも使用可能な予測モデルが望ましい。
そこで,Fig.3のように,精整工程の通過パターン毎に製造工期の分布形状が異なることを活用し,Fig.7で示す(a)~(c)の3つのステップで標準工期を算出することを考案した5)。
(a)精整工程の通過パターンを予測し,注文品種(注文の分野や用途で分類したクラス)と組み合わせて,製造品種ciとする(iは製造品種番号)。
(b)製造品種毎ciに製造工期P(t|ci)を予測する。
(c)指定した荷揃達成率目標値piを満たす時間を製造工期P(t|ci)から算出して標準工期
t
^
i
とする。
ここで,製造品種は注文品種に通過パターンの予測値を付加したコードあるが,注文品種と通過パターン毎に製造工期を予測した理由は,同じ通過パターンでも注文品種毎に発生工程の通過頻度(発生率)が異なることで,製造工期が異なるケースがあること,同じ通過パターンでも注文品種毎に荷揃達成率の目標値を変更可能とするためである。このように,新しい標準工期の算出アルゴリズムを,通過パターン予測と工期分布予測の2段階予測とすることで,完全なブラックボックスではなく,予測メカニズムを利用者が理解し易い構造とした。また,製造品種をキーとして標準工期をテーブル管理できる利点もある。以下,Fig.7の(a)~(c)の計算方法に関して説明する。
3・2 通過パターン予測モデルと製造品種
厚板製品の製造では,手入やガス切断,矯正など,注文仕様では通過有無が未定であり,圧延後に通過有無が決まる発生工程が存在するため,注文の製造仕様から単純なロジックで精整工程の通過パターンを算出することはできない。そこで,実績データから木構造のIF-THENルールを自動構築する汎用的手法である決定木(Decision
tree)6)を用いて,注文品種毎の通過パターン予測モデルを構築した。決定木を用いた理由は,製造仕様には規格や冷却パターンなど,記号で表されるデータがあり,決定木は数値と記号の混在したデータを扱うことができるからである。
決定木を用いて注文品種毎の通過パターンを予測する方法として,Fig.8の(a)と(b)の2つの手法を比較検討した。(a)は注文品種毎に通過パターン(0/1の並び)を予測する決定木を用いる方法(注文品種別決定木),(b)は工程毎に通過有無(0/1)を予測する決定木を用い,工程毎の通過有無の予測値を一列に並べて通過パターンとする方法(工程別決定木)である。注文品種別決定木では,通過パターンの予測精度が最も高くなるように決定木を学習するため,通過パターンの精度が高い予測モデルが得られるが,通過パターン数の多い注文品種の場合には,決定木が複雑となり,理解し辛くなってしまう欠点がある。一方,工程別決定木の場合には,決定木は1つの工程の通過有無(0/1)を予測するのみであるため,理解し易い単純な決定木となる利点がある。しかし,通過パターンの予測精度を考慮して各決定木が作成される訳ではないため,必ずしも通過パターンの予測精度が高くなる保証はなく,特に,各工程が独立でない場合には精度が悪化することが懸念される。そこで,注文品種別決定木と工程別決定木の予測精度を,ある製鉄所の実績データを用いて比較した。なお,決定木はC5.0(C4.57)の改良版)アルゴリズムを用いた。

Table
3の1行目は,ある期間の実績データを用いて学習した決定木の予測精度を,次の期間の実績データを用いて評価した値であり,2つの決定木の予測精度(Accuracy)はほぼ等しいという結果が得られた。これは厚板製造プロセスでは,各工程は独立と考えても構わないことを意味している。また,Table
3のロバスト性(Robustness)は,前期間の実績データを用いて学習した決定木と,次期間の実績データを用いて学習した決定木の予測値の差異を評価した結果である。それぞれの決定木に,ある期間の同じ注文データを入力し,予測された通過パターンの差異を評価した。その結果,Table
3のように,通過パターンの予測値と実績値の全ビットが完全に一致した割合は,注文品種別決定木の方が優っているが,両者の差は僅かであり,しかも,1ビットエラー以内,2ビットエラー以内の割合を比較すると,工程別決定木の方が優れている結果が得られた。従って,工程別決定木の方が異なる期間の実績データを用いて学習し直しても通過パターン(製造品種)が大きく変わらず,ロバスト性の優れた分類器であることが判った。また,各々の方式で設計した標準工期を比較した結果,Table
4のように,荷揃達成率は同等でありながら,工程別決定木の方が注文品種別決定木より標準工期の平均値が0.10(12.0%)短い結果が得られた。これは,工程別決定木の方が製造品種の数が多く,製造工期の似通った注文をひとまとまりにしていることを表している。なお,工程別決定木の各決定木の正解率は最低81.2%,平均93.8%であった。
Table 3.
Prediction accuracy of process flow.
|
(a) Decision tree of each order
class |
(b) Decision tree of each
process |
| Accuracy |
54.9% |
55.8% |
| Robust-ness |
No error |
86.1% |
85.0% |
| One bit error |
92.0% |
95.8% |
| Two bits error |
96.9% |
99.4% |
| Complexity |
complex |
simple |
Table 4.
Comparison of standard production time.
|
(a) Decision tree of each order
class |
(b) Decision tree of each
process |
| Average standard production time |
0.82 |
0.72 |
| Percentage of finished products |
95.6% |
95.4% |
| The number of production class |
44 |
72 |
以上より,標準工期を算出する際の通過パターンの予測方式としては,Fig.8(b)の工程別決定木の方が予測精度と可読性・ロバスト性の面で優れていることが判った。
3・3 製造品種毎の製造工期予測モデル
3・3・1 予測モデルの構成
製造品種毎の製造工期P(t|ci)を求める際には,実績データから同じ製造品種のプレートを抽出し,それらの製造工期のヒスグラムを工期分布とする方法が単純である。しかし,稀にしか製造されない製造品種も存在し,このようなプレート数(母数)の少ない製造品種の製造工期は,信頼性が低くなってしまう。例えば,ある製造品種のプレート数が20枚程度しかなく,そのうち,1枚だけが何らかの原因で長い製造工期が掛ってしまった場合,その1枚の影響で裾野の長い製造工期となってしまう。そこで,Fig.9のように,各通過パターンfjの製造工期P(t|fj)を求め(jは通過パターン番号),それらを製造品種毎の通過パターンの構成比率P(fj|ci)で按分することで,製造品種毎の製造工期を求めることとした。これは,通過パターン毎の製造工期は全ての製造品種で変わらないと仮定して,製造品種毎の製造工期P(t|ci)を式(5)の近似式で算出することを意味している。このように近似することで,製造品種の製造工期P(t|ci)は,通過パターンの製造工期P(t|fj)の按分として算出されるため,製造頻度の少ない製造品種でも,通過パターン毎の製造工期P(t|fj)が信頼できれば,極端に裾野の長い製造工期が算出されることを抑制することができる。
|
P
(
t
|
c
i
)
=
∑
j
=
1
L
P
(
t
|
f
j
,
c
i
)
P
(
f
j
|
c
i
)
≈
∑
j
=
1
L
P
(
t
|
f
j
)
P
(
f
j
|
c
i
)
| (5) |
通過パターン毎の製造工期P(fj|ci)の算出では,Fig.3のように,実績データから同じ通過パターンのプレートを抽出し,それらの製造工期を対数正規分布で近似する方法が一番簡単である。高頻度で発生する通過パターンであれば,信頼性の高い製造工期が得られる。しかし,低頻度の通過パターンでは,このような方法で求めた製造工期の信頼性は低くなってしまうという課題があった。例えば,1つの工程のみ通過する通過パターン(ex.01000)の製造工期よりも,その工程を含む3つの工程を通過する通過パターン(ex.01011)の製造工期の方が短く算出されてしまう逆転現象が発生する問題があった。そこで,Fig.10のように実績データから工程毎の所要時間を予測し,通過工程(ビットが1の工程)の所要時間を積算することで,通過パターン毎の製造工期を予測する方法とした5)。Fig.10は冷間矯正(CL),UST,手入(CDT)を通る通過パターンの製造工期を,それぞれの工程の所要時間を積算して求めることを意味している。
各工程の所要時間を算出する際には,各精整工程の通過時刻の履歴を用いることが望ましい。しかし,現実の工場では通過時刻が記録されていない工程や,通過時刻に空白や間違いが多く含まれている工程もある(工程の前を素通りする場合でも時刻が記録されてしまう工程等もある)。そこで,各工程の通過時刻は利用せず,通過パターンの製造工期分布が実績値と合うように,最尤推定法(Maximum
Likelihood Estimation)8)を用いて,各工程の所要時間を予測する方法を開発した。
最尤推定法とは,確率密度関数のパラメータを推定する際に一般的に用いられる手法であり,実績データに最も良く当てはまるように(実績データの発生確率が最も高くなるように),確率分布のパラメータを決定する。本稿では,各工程の所要時間を正規分布と仮定し,そのパラメータである平均μ=(μ1,μ2,…,μM)と分散v=(v1,v2,…,vM)を最尤推定法で決定した。Mは工程数であるが,精整工程に加えて,すべてのプレートが必ず通過する倉庫を工程として加えている。この倉庫工程は通過パターンの全体の製造工期を増減させるオフセットの役割を持つ。
n番目のプレートの実績通過パターンを
f
˜
n
=(
f
˜
n
1
,
f
˜
n
2
,…,
f
˜
nM
)と表すと(
f
˜
nm
はm番目の工程の通過有無を表す01整数),各工程の所要時間が独立ならば,通過パターン
f
˜
n
の製造工期の発生確率は式(6)のように表される。
|
P
(
t
|
f
˜
n
)
=
N
(
t
|
μ
˜
n
,
v
˜
n
)
=
1
2
π
v
˜
n
exp
{
−
(
t
−
μ
˜
n
)
2
2
v
˜
n
}
| (6) |
|
μ
˜
n
=
f
˜
n
μ
T
,
v
˜
n
=
f
˜
n
v
T
| (7) |
|
μ
=
(
μ
1
,
μ
2
,
⋯
,
μ
M
)
,
v
=
(
v
1
,
v
2
,
⋯
,
v
M
)
,
μ
m
≥
0
,
v
m
≥
0
| (8) |
ここで,各工程の所要時間は対数正規分布やガンマ分布など,非負領域で定義される確率密度関数とすべきであるが,正規分布以外にすると,通過パターンの製造工期は単純な積上げでは計算できず,複雑な畳み込み積分が必要となる。そこで,各工程の所要時間は正規分布と仮定して各通過パターンの製造工期の平均と分散を計算した後,式(1)を用いて対数正規分布に変換することにした。精度確認のため,各工程の所要時間を同じ平均・分散を有する対数正規分布として通過パターンの製造工期分布を計算し,累積確率95%の工期を正規分布の場合と比較したところ,両者の相関係数は0.99となり,前記のように各工程の所要時間を正規分布としても実用上問題ないと判断した。なお,ガンマ分布も尺度母数θを共通にすれば再生性を有するため,畳み込み積分せずに通過パターンの製造工期を求めることができるが,各工程の平均と標準偏差を独立して決めることができないため精度が悪くなってしまう。
さて,プレートnの実績工期がtnであったとき,その発生確率は式(6)より,P(tn│
f
˜
n
)となる。従って,全てのプレートの実績通過パターンを
F
˜
={
f
˜
nm
}と表すと,実績工期t=(t1,t2,…,tN)が得られる確率(尤度)は式(9)となる。
|
P
(
t
|
F
˜
)
=
∏
n
=
1
N
N
(
t
n
|
μ
˜
n
,
v
˜
n
)
=
∏
n
=
1
N
1
2
π
v
˜
n
exp
{
−
(
t
n
−
μ
˜
n
)
2
2
v
˜
n
}
| (9) |
式(9)の両辺の対数(対数尤度)をとると,式(10)のようになる。
|
ln
P
(
t
|
F
˜
)
=
∑
n
=
1
N
ln
[
1
2
π
v
˜
n
exp
{
−
(
t
n
−
μ
˜
n
)
2
2
v
˜
n
}
]
=
−
1
2
∑
n
=
1
N
[
ln
(
2
π
)
+
ln
(
v
˜
n
)
+
(
t
n
−
μ
˜
n
)
2
v
˜
n
]
| (10) |
式(9)の尤度関数を最も高くするためには,式(10)の右辺の括弧内を最小化すれば良い。すなわち,次の式(11)式の最適化問題を解けば,各工程の所要時間のパラメータである平均μと分散vを定めることができる。
|
J
=
∑
n
=
1
N
[
ln
(
v
˜
n
)
+
(
t
n
−
μ
˜
n
)
2
v
˜
n
]
→
min
| (11) |
上記の最尤推定法は重回帰手法を一般化した手法であり,重回帰が平均値を推定する手法であるのに対して,最尤推定法は平均と分散のように,確率分布のパラメータを同時に推定する手法である。平均値のみ推定するのであれば,式(6)の
v
˜
n
は定数として扱い,J=ΣNn=1(tn−
μ
˜
n
)2→minの最適化問題を解くことになる。これは,実績工期tnと予測平均工期
μ
˜
n
との二乗誤差を最小化することであり,通常の重回帰手法と一致する。また,通過パターン毎の製造工期を予測するのみであれば,一般化線形回帰モデル11)や分位点回帰モデル13)を用いて,工程通過有無
f
˜
nm
を説明変数として,実績工期tnを予測するモデルを構築しても良い。
さて,式(11)のNは学習データのプレート数を表し,ほぼすべての品種が製造される半年から一年間のプレートから計算することが望ましく,Nの値は数十万にもなり,式(11)は大規模な最適化問題となってしまう。しかし,通過パターンの種類数をL(数百個),各通過パターンをfj=(fj1,fj2,…,fjM),通過パターンfjに属するプレート数をRj通過パターン毎の製造工期の平均値を
μ
^
j
,分散を
v
^
j
,実績工期の平方和をSj,実績工期の和をTjとすると,式(11)の右辺第1項は式(12),右辺第2項は式(13)のように書き表せ,評価関数は式(14)のように,L個の要素数の和の形式に書き直すことができる。ここで,
∑
{
n
|
f
˜
n
=
f
j
}
(・)は実績通過パターン
f
˜
n
が通過パターンfjと等しいプレートのみ集計するという意味である。式(14)の係数Rj,Sj,Tjは最適化計算前に求めることができる定数であるため,各工程の所要時間の平均μmと分散vmは,式(15)式(8)の制約式の下で,式(14)を最小化するように決定すれば良く,高速(数秒)に計算することが可能となる。
|
∑
n
=
1
N
ln
(
v
˜
n
)
=
∑
j
=
1
L
∑
{
n
|
f
˜
n
=
f
j
}
N
ln
(
v
^
j
)
=
∑
j
=
1
L
ln
(
v
^
j
)
∑
{
n
|
f
˜
n
=
f
j
}
N
1
=
∑
j
=
1
L
R
j
ln
(
v
^
j
)
| (12) |
|
∑
n
=
1
N
(
t
n
−
μ
˜
n
)
2
v
˜
n
=
∑
n
=
1
N
t
n
2
−
2
t
n
μ
˜
n
+
μ
˜
n
2
v
˜
n
=
∑
j
=
1
L
∑
{
n
|
f
˜
n
=
f
j
}
N
t
n
2
−
2
t
n
μ
^
j
+
μ
^
j
2
v ^
j
=
∑
j
=
1
L
(
1
v ^
j
∑
{
n
|
f
˜
n
=
f
j
}
N
t
n
2
−
2
μ
^
j
v ^
j
∑
{
n
|
f
˜
n
=
f
j
}
N
t
n
+
μ
^
j
2
v ^
j
∑
{
n
|
f
˜
n
=
f
j
}
N
1
)
=
∑
j
=
1
L
(
1
v ^
j
S
j
−
2
μ
^
j
v ^
j
T
j
+
μ
^
j
2
v ^
j
R
j
)
| (13) |
|
J
=
∑
j
=
1
L
[
R
j
ln
(
v ^
j
)
+
1
v ^
j
S
j
−
2
μ
^
j
v ^
j
T
j
+
μ
^
j
2
v ^
j
R
j
]
→
min
| (14) |
|
μ
^
j
=
f
j
μ
T
,
v ^
j
=
f
j
v
T
| (15) |
|
R
j
=
∑
{
n
|
f ˜
n
=
f
j
}
N
1
,
S
j
=
∑
{
n
|
f ˜
n
=
f
j
}
N
t
n
2
,
T
j
=
∑
{
n|
f ˜
n
=
f
j
}
N
t
n
| (16) |
このように各工程の所要時間の平均μmと分散vmを推定した後,各通過パターンfjの平均
μ ^
j
と分散
v ^
j
を式(15)より算出し,式(1)を用いて対数正規分布のパラメータを求め,その対数正規分布を通過パターンfjの製造工期P(t|fj)とする。通過パターン別製造工期P(t|fj)を求めることができれば,製造品種毎の製造工期P(t|ci)は,式(5)(Fig.9)のように,通過パターン別製造工期P(t|fj)と通過パターンの構成比率(発生確率)P(fj|ci)から算出できる。なお,通過パターンの構成比率P(fj|ci)は実績データより式(17)のように,製造品種ciの全プレートに含まれる通過パターンfjの割合として計算できる。
|
P
(
f
j
|
c
i
)
=
The
number
of
c
i
&
f
j
plates
The
number
of
c
i
plates
| (17) |
標準工期は注文がほぼ確実に製造可能な工期であるため,製造品種毎に目標とする荷揃達成率pi(例えば95%)を定め,式(18)のように,製造工期分布P(t|ci)の累積分布関数の逆関数F−1(pi|ci)より標準工期
t ^
i
を計算することができる。
|
t ^
i
=
F
−
1
(
p
i
|
c
i
)
| (18) |
ある製鉄所のある期間に製造された20万枚のプレートの実績データを用いて計算した工程所要時間の一例をFig.11に示す。なお,式(14)の評価関数を最小化する非線形最適化計算においては,局所最適解に陥り難くするため,滑降シンプレックス法9)にて探索範囲を狭めた後,準ニュートン法10)で詳細な最適解を求めた。各工程の所要時間は正規分布を仮定して計算しているが,マイナスの工期はあり得ないため,プラス側のみ表示している。工程Cや工程Gはマイナス側の確率が10%以下であるが,工程Aと工程Dはそれぞれ38%,43%存在し,正規分布の仮定に無理のある工程も存在する。ただし,工程Aは所要時間が短い工程であり,全体の製造工期に与える影響は少ない。また,工程Dは製造頻度の少なくばらつきの大きい工程のため,一様分布のように推定されてしまったが,このような工程を通過する頻度は少ないため全体の製造工期への影響は少ない。このように,正規分布の仮定から外れた影響が誤差要因して存在するが,各工程の平均工期やばらつきの程度は概ね実態と合っていることを確認している。
次に,Fig.11に一例を示した工程毎の所要時間を用いて推定した通過パターンの製造工期と,別の期間に製造された18万枚のプレートの実績工期との比較をFig.12に示す。左3つは通常厚みの製品の通過パターンであり,比較的頻度の高い工程から成る通過パターン,右3つは極厚製品の通過パターンであり,低頻度工程を含む予測し難い通過パターンの製造工期である。このように,工程毎の所要時間を積み上げて計算した製造工期は,実績の工期分布から大きく外れることなく,概ね良好に予測できていることを確認した。
さて,通過パターン別製造工期P(t|fj)は最尤推定法を用いなくても,同じ通過パターンのプレートを実績データから抽出し,その実績工期の平均値aと標準偏差sから式(1)を用いて直接対数正規分布のパラメータを求めることもできる。このように直接求めた通過パターン別製造工期を用いる手法(a)と,最尤推定法で求めた通過パターン別製造工期を用いる手法(b)とを,標準工期の長さで比較した。なお,目標荷揃達成率piは95%とした。
その結果,Table
5のように,平均標準工期や荷揃達成率の面では両者にほとんど差がないことが判った。これより,発生頻度の高い製造品種に関しては,(a)直接手法と(b)最尤推定手法は同等の精度を有していると言える。
Table 5.
Comparison between the direct method and the maximum likelihood estimation
(MLE) method.
|
(a) Direct method |
(b) MLE method |
| Average of standard production
time |
0.72 |
0.73 |
| Percentage of finished
products |
95.4% |
95.5% |
| Robustness |
0.63 |
0.80 |
Decision tree: Decision tree of each process. Robustness: R2 (see Fig.13)
次に,ある期間の実績データを用いて算出した標準工期と,次の期間の実績データを用いて算出した標準工期を製造品種毎に比較するとFig.13のようになった。Table
5のロバスト性とは,両期間の製造品種毎の標準工期の相関度(決定係数)であり,数値の高い最尤推定法の方が,標準工期の変化が少ないことを表している。実績工期を直接用いた場合,製造頻度の少ない製造品種では,期間が変わると実績工期が大きく変わる場合があり,標準工期の信頼性が低くなってしまう。それに比べて,最尤推定法を用いた場合は,標準工期の値が変わり難く,信頼性の高い標準工期を算出することができることが確認できた。
4. 新しい標準工期導入効果
ある期間の実績データより最尤推定法を用いて算出した標準工期と,それとは別のFig.6と同じ期間の実績工期との差(新標準工期−実績工期)のヒストグラムはFig.14のようになった。Fig.6と比較すると,Fig.14のヒストグラムは高いピークの存在する急峻なグラフとなった。新標準工期の平均値は0.98となり,標準工期の長さはほとんど変わらないが,荷揃達成率は3.2%改善(91.5→94.7%)させることができた(Table
5の平均標準工期と異なるのは,機械試験工期を標準工期に含めたためである)。なお,新標準工期の値は設定荷揃達成率に依存して変化し,荷揃達成率が従来と等しい条件で標準工期を設計すると,新標準工期は平均10.5%短縮する。
現在,注文毎に工程別決定木で製造品種を求め,最尤推定法で算出した新標準工期を用いて,注文の製造着手日を決定する注文投入システム(Order entry
system)が稼働中である。この注文投入システムはさらに,受注した注文に対して各精整工程の負荷を実績データから算出し,各精整工程の負荷の時系列推移を管理できる仕組みになっているため,製鉄所の混雑状況を確認しながら,適切なタイミングで製造指示を掛けることができる。また,受注構成の変化や製造方法の変更に適応するため,決定木および標準工期は直近の実績データを用いて毎年更新している。これにより,各製鉄所の荷揃達成率が高位安定化し,標準工期が約1日~3日短縮する効果が得られた。
5. 結言
本稿では,厚板の製造工期の予測方法と標準工期の設計方法に関して述べた。本稿の製造工期予測方法は,(a)注文品種を精整工程の通過パターンで細分化したクラスである製造品種ciを求めた後,(b)製造品種毎に製造工期P(t|ci)を予測し,(c)その製造工期から指定した目標荷揃達成率を満たす時間を算出して標準工期とする方法である。前者の通過パターン予測には決定木を用いており,通過パターンを予測する決定木と,工程毎に通過有無を予測する決定木の予測値を組み合わせる方法を検討し,工程毎に決定木を作成した方が,構造が単純で判り易い決定木となり,かつ,精度も高いことが判った。また,後者の製造工期予測では,製造頻度の少ない通過パターンの製造工期でも高精度に予測することが課題であったが,工程毎の所要時間を最尤推定法で予測し,それらを工程通過有無に応じて積上げる方式を新たに考案し,信頼性の高い製造工期を予測する技術を作り上げた。本稿の製造工期予測技術は,受注した注文の製造指示を行う注文投入システムで稼働中であり,各製鉄所の荷揃達成率が高位安定化し,標準工期が約1日~3日短縮する効果が得られた。
本稿では,厚板の製造工期の予測に限定して記載したが,製造工期の予測が難しいことは,厚板に限ったことではなく,薄板や鋼管はさらに難しい。短工期生産体制の実現は全ての品種の共通課題であり,今後は本稿の予測技術を薄板や鋼管など他の品種へ応用する予定である。
文献
- 1) J.
Ashayeri,
R.J.M.
Heuts,
H.G.L.
Lansdaal and
L.W.G.
Strijbosch:
Int. J. Prod. Economics,
103(2006), 715.
- 2) T.
Umeda and
S.
Ishii: Kobe
Steel Eng. Rep., 56(2006),
2.
- 3) M.
Shioya,
Y.
Yaji,
S.
Nagata,
T.
Uragami and
H.
Inokuchi:
CAMP-ISIJ,
22(2009), 139,
CD-ROM.
- 4) K.
Nishioka,
Y.
Mizutani,
H.
Ueno,
H.
Kawasaki and
Y.
Baba:
Synthesiology,
5(2012), 98.
- 5) M.
Shioya,
J.
Mori,
K.
Ito,
Y.
Mizutani and
K.
Torikai:
CAMP-ISIJ,
26(2013), 238,
CD-ROM.
- 6) R.
Kohavi and
J.R.
Quinlan: Handbook of data mining and
knowledge discovery, Oxford University Press, Oxford, (2002),
267.
- 7) J.R.
Quinlan: C4.5:programs for machine
learning, Morgan Kaufmann Publishers, San Francisco, (1993),
17.
- 8) C.M.
Bishop著,元田浩,栗田多喜夫,樋口知之,松本裕治,村田昇訳:パターン認識と機械学習,シュプリンガー・ジャパン,東京,(2007),
138.
- 9) 丹慶勝市他訳:NUMERICAL RECIPES IN C
[日本語版],技術評論社,東京,(2000), 295.
- 10) 玉置久:システム最適化,オーム社,東京,(2005), 63.
- 11) A.J.
Dobson著,田中豊,森川敏彦,山中竹春,富田誠訳:一般化線形モデル入門
原著第2版,共立出版,東京,(2008), 195.
- 12) 吉岡良雄:待ち行列と確率分布−情報システム解析への応用,森北出版,東京,(2004), 9.
- 13) B.S.
Cade and
B.R.
Noon:
Frontiers in Ecology and the
Environment, 1(2003),
412.