心理学を始めとして,科学的なアプローチを重視してきた様々な学問分野の中で近年注目を集めるようになってきた研究の1 つに自由記述を対象とした分析がある.自由記述データは,その内に含まれる知見を得るために,質問紙調査の自由記述項目欄や,種々の質的研究法を用いて得られたデータを最終的にテキストとしてまとめ,その後の理論を構築するためにカテゴリ化を伴う際等に利用される.しかし現状では,知見の収集の達成の程度については客観的な指標が存在しない.そこで本研究では,得られた自由記述データについて,資源量推定の方法を用いて知見数と飽和度を示す捕獲率を推定する方法を提案した.分析には(株)日経BP コンサルティングが発表しているブランドジャパンの提供による,2 つの企業に対する2006 年から2010 年までの自由記述形式の印象調査の回答を用い,多くの知見数が集まるまでに必要な精読量を明らかにした.その結果,それぞれの精読に当てる全時間の20%,10%の精読量で,全ての知見の80%が収集できていることが示された.
近年では,自由記述データを対象とする分析が増えてきており,また記述的なデータを用いて量的なものに還元しにくい言語的・概念的分析を行う質的研究(qualitative research)は,これまで科学的なアプローチを重視してきた様々な学問分野で認知され,注目を集めるようになってきた.教育心理学の分野では,例えばグラウンデッド・セオリー・アプローチ(Glaser & Strauss, 1967)を通して,病院内学級の教育実践の特徴カテゴリーの抽出を行った谷口(2005) の研究や, 教師の発話分析を行った上村・石隈(2007),修正版グラウンデッド・セオリー・アプローチ(M-GTA)を用いて半構造化面接によるカテゴリー生成を行った田中(2010) の研究等,質的研究が盛んに見られるようになってきている.他にも加藤・大久保(2009) の中学校教師の面接調査や,大内・櫻井(2008) における遊び観察尺度の構成内容の検討等に質的研究が利用されている側面が見られる.また,2004 年には質的心理学会が設立され,その発展が期待されている現状にある(秋田・能智,2007).
様々な方法を通して集められた自由記述データを扱った研究では,その後の理論を構築するためにカテゴリ化を伴う知見を収集することがある.その具体例として豊田・前田(1994) では,大学入試方法の改善に関する進路指導担当教員からの自由記述意見の収集を行い,1332 枚の自由記述から,最終的に91 個の入試制度の改革案という知見を得ている.ところが最初の100 枚の自由記述意見を読んだ段階で,既に54 個の知見が得られており,真の知見数N が91 であると仮定すると,知見の収集率はこの時点で半数を超える54/91 = 0.59% であった.そして最初から300 枚までの自由記述をコーディングした段階で74 個の知見が得られていた.この時点での収集率は74/91 = 0.81% に達している.つまり新たな200 枚の自由記述からは新規の知見が20 個しか発見されず,最後の1032 枚の自由記述からは新規の知見が17 個しか得られていなかった.
このように知見の収集が進むにつれて新たな知見が得られにくくなることは,それだけ該当分野の把握が包括的に達成されている,すなわち知見の飽和に向かっていることを示しているために,自由記述データを扱う多くの研究者が体験するであろう現象といえる.しかしどの程度まで知見を収集し続ければ良いのかを示す客観的な基準は現状では存在せず,知見の収集を打ち切るタイミングを決定することは難しい.例えば確率論における“クーポン収集問題(coupon collector’sproblem)” では,“全部でN 種類の野球選手のカードの景品が付いた菓子は何個買うと収集が完了するか” に類する問題を解く.収集の初期には購入する度に新しいカードが手に入るが,そのうち既に持っているカードばかりが得られるような状態になる.既に収集は完了したかと思うと,たまに新しいカードが手に入る.このため購入を止めにくく,景品はマーケティング戦略としても有効であることが知られている.クーポン収集問題はN の増加に伴って,必要な菓子の数は相当に増えることを示している1.知見の収集の際にもこのように,収集が完全に達成されることは多くの場合に困難である.
知見の収集の程度(飽和度)に関する評価は主観的判断に依存しているため,新しい概念が登場しなくなったとしても知見の収集を続ける場合もあれば,いくつかの資料に新しい知見が登場しなくなった時点で知見の収集を打ち切る場合も存在し,知見収集に関する程度が研究者間で比較しにくい.また,査読者や読者は知見収集の程度に関する実感が研究者と同程度には得られないので,実質的に研究の評価に利用しづらいということが挙げられる.飽和度の客観的な推定値が示されれば,テキストを扱う研究の評価にとって有用な判断材料となることが期待される.
以上を受け,本研究では知見収集の最中に,総知見数N と飽和度(捕獲率Cr)を推定する方法を提案する.資源量推定(能勢・石井・清水, 1988) の方法を利用するため,飽和度を示す指標は,捕獲率と呼ぶ.この指標の利用方法としては,知見を収集し続け,大切な観点は出尽くしたと調査者が判断した一区切りの段階において,現在の知見収集状況から推定される総知見数と捕獲率を算出する用い方が想定される.ただし本手法は自由記述文を分析対象としているため,数理的側面から具体的な特定のデータ収集の手段には依らないこと,すなわち最終的にカテゴリ化を伴うテキストデータを分析対象とする研究であれば本手法が適用可能であり,そして各知見が独立に得られる場合,知見収集のどの段階でも推定が可能であることに留意されたい.
豊田・前田(1994) では,1332 枚の自由記述を読んでコーディングする作業時間は180 時間と報告しているので,比例配分すると100 枚で13 時間半であり,300 枚で40 時間半である.もし捕獲率を,知見の収集中に推定することが可能であれば,たとえば300 枚読んだ段階で飽和度約81%を確認し,40 時間半でコーディングを打ち切ることも可能であった.もちろん95%を目指すこともできた.具体的な目標が常に提示可能であることは,知見収集が飽和に達していると感じた時点で捕獲率が推定可能ということを意味しているため,データを収集している最中の研究者自身に対しても有益であろう.この利便性に加え,テキストが捕獲率によって分析を始めるにあたって内容的に十分収集されていると判断することができれば,データから導かれる理論や研究成果がより盤石な基盤をもっていたことを1 つの観点からの傍証として示すことができ,研究者だけでなく査読者や読者にもより安定的な結論を提示することが可能となる. よってこの指標は,査読者,研究者,読者の三者に有益な情報を与えることとなるだろう.
著名な確率論の教科書フェラー(1960, p.63) に以下のような「再捕獲の資料から動物の集団の数を推定する問題」がある.それは「湖で獲った1000 尾の魚に赤印をつけて,放すとする.しばらくの期間をおいて新たに1000 尾を捕獲したところ,その中に赤印のものが100 尾いた.この湖の魚の数についてどのような結論が得られるか.」である.ここでは魚の総数が,テキストに含まれる知見の総数(KJ 法におけるカードの枚数)である.
1. 捕獲回数(知見を得る機会の回数)I 回.添え字はi(i = 1, · · · , i, · · · , I) を使用.i 回目の捕獲にて
2. 印を標識(mark)と呼び,標識の付いた知見数(既知となった知見の数)はmi (m1 = 0)
3. 捕獲(capture)した知見数(既知,未知に関わらず,i 回目の捕獲において得られた知見の総数)はci
4. 再捕獲(recapture)された知見数(既に得られている知見の数)はri (r1 = 0)
5. 新しく(new)捕獲された知見数(これまでになかった未知であった知見の数)ni = ci − ri(n1 = 0,mi+1 = mi + ni)
6. 標識率(i 回目の捕獲において,既知となっている知見の割合)pi = ri/ci
また捕獲回数I は,研究者が限りある研究資源(時間や研究費)の中で捕獲率の計算を試みた時点での,手元のデータでの全捕獲回数を指している.
本手法を用いる目的は知見(資源・魚・カード)の総数N を推定することであり,それを利用して捕獲率(飽和度)Cr = mI/N を推定することである2.もしI 回目までにすべての知見が得られた場合,mI はI 回目までに得られた知見数であるため,mI = N からCr = 1となる. またもしI 回目までに1 つも知見が得られなかった場合mI = 0 から,Cr の範囲は0 ≤ Cr ≤ 1 となる.
誤差を考慮しない比例式N : mi = ci : ri を解けば
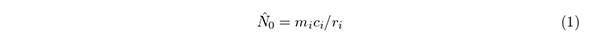
という式を得る.これはri = 0のとき(全部,新知見である好ましい捕獲のとき)定義されず,推定量として選ぶと分散が定義されない.そこで本研究では推定量として
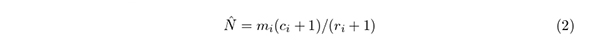
を用いる.これをPetersen の修正式といい(Schaefer 1951),分散は
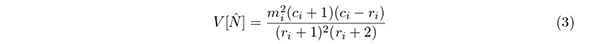
と導かれている(Schaefer 1951, Jones 1964).
ここでは相当多数回の捕獲(知見の収集)を行うので,それらを利用した知見数の推定量
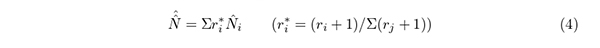
を利用する.複数回捕獲し,捕獲のたびに標識(既出の知見か否かの付記)をつけて,全頭放流する(重複する知見を許して再び知見を集める)方法を資源量推定の分野ではSchnabel 法(Schnabel,1938) といい,その際の推定量の1 つである.この推定量は,要するに捕獲数に比例した重みづけ平均であり,近似的に正規分布すると考えられる.ただし2 回目の捕獲からI 回目の捕獲まで,全てのデータを利用すると初期の偏りの影響を受け易く,安定しない.このため本論文ではバーンイン(初期のデータを捨てることを指す)してI 回目の捕獲から数回遡ったデータ(遡る回数をラグ回数と呼ぶ)を利用する.捕獲間の再捕獲数は互いに独立であり,その重み付き平均が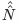 であるから,その分散は
であるから,その分散は
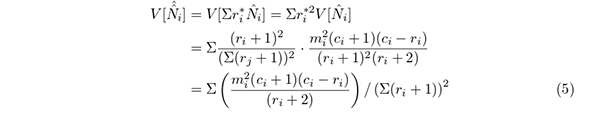
と求めることができた.
捕獲率Cr は研究者にとって高いほうが都合がよい指標であるから,本論文では控えめに,知見総数の95%信頼区間の上側限界を利用して
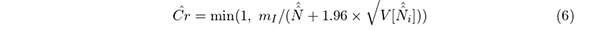
で推定することを提案する.
本論文では応用例として,ブランドジャパンの自由記述データを利用した.(株)日経BP コンサルティングが発表しているブランドジャパン3のBtoC に,毎年ランクインしているブランド「ブランドA(映画会社)」と「ブランドB(教育機関)」に関する自由記述意見から,「ブランドA」と「ブランドB」に関するブランドイメージの観点(知見)を収集した.「ブランドA」は2010 年の調査で211 名,2009 年の調査で210 名から自由記述が寄せられており,2 年分合計421 の自由記述を分析の対象とする.「ブランドB」は2010 年の調査で58 名,2009 年の調査で78 名,2008年の調査で145 名,2007 年の調査で154 名,2006 年の調査で83 名からの自由記述が寄せられており,5 年分合計518 の自由記述を分析の対象とした.
3.2. 加工方法自由記述× 知見マトリクスを作成する.
1. 自由記述を1 枚読むごとに,ブランドイメージとして取り上げるべき新出の知見があるか否かを判定する.新知見か否かの判断は,複数名の合議の下,全員が新知見であるとの意見が一致したものを新知見とする. 既出の場合は知見の列に1 を立て,新出の場合は列を新たに作って1 を立てる.
2. 50 枚の自由記述を読んだ段階で,知見のカテゴリの統廃合を行い,再びコード化する.
3. 100 枚の自由記述を読んだ段階で,知見のカテゴリの統廃合を行い,再びコード化する.
4. 自由記述を5 枚読むたびに,知見数と捕獲率を計算する.
3.3. 結果表1 が「ブランドA」と「ブランドB」について収集された83 個,84 個の知見である.
表2 が,「ブランドA」と「ブランドB」の最初と最後の50 枚の自由記述に書かれた観点を5 枚ずつまとめて示したものである.合計20 回の捕獲の結果である.ブランドA の場合,84 回の捕獲における標識数mi の変化はm = (0 8 14 18 21 27 29 36 37 40 45 47 48 50 52 55 56 57 59 62 64 65 65 66 68 70 70 70 71 71 71 72 73 73 73 73 73 73 73 74 75 76 76 76 76 76 76 76 76 77 77 78 78 79 79 79 80 80 80 80 81 81 81 81 81 81 81 81 81 82 82 82 82 83 83 83 83 83 83 83 83 83 83 83)となった.ブランドB の場合は,104 回の捕獲における標識数mi の変化がm = (0 8 15 17 21 26 32 37 41 45 45 46 49 49 51 51 52 53 54 54 55 57 59 60 61 62 62 64 65 66 66 66 66 66 67 68 68 71 72 72 73 75 75 76 76 76 76 76 76 76 76 76 76 78 78 78 78 78 79 79 79 80 80 80 80 80 81 82 82 82 82 82 82 82 82 83 83 83 83 83 83 83 83 83 83 83 83 83 83 83 83 84 84 84 84 84 84 84 84 84 84 84 84 84) となった.豊田・前田(1994) と同様に捕獲を続けると新しい知見は頭打ちになることが示されている.
捕獲数ci の変化は,ブランドA はc = (8 9 7 5 9 7 10 8 9 8 8 8 8 8 9 6 10 7 10 9 6 7 6 9 7 6 7 12 7 11 8 7 6 9 6 5 7 8 8 9 8 7 5 8 6 7 6 9 5 5 6 8 7 6 7 10 9 7 6 8 8 7 7 7 11 9 8 9 8 8 6 10 9 9 7 9 10 7 10 6 11 8 9 8),ブランドB は(8 9 6 8 9 9 10 11 9 5 7 7 9 8 8 8 9 7 7 9 8 8 6 9 8 12 10 10 9 7 7 9 8 8 9 7 9 8 10 8 7 6 10 8 9 8 8 6 8 9 8 11 10 8 6 8 6 7 10 7 7 9 7 9 6 8 9 9 6 7 8 7 11 8 9 8 8 7 7 8 10 7 10 7 8 9 9 7 7 6 8 7 9 4 10 8 8 7 7 8 6 8 7 4) となった.トレンドは観察されない.
再捕獲数ri の変化は,ブランドA の場合r = (0 3 3 2 3 5 3 7 6 3 6 7 6 6 6 5 9 5 7 7 5 7 5 7 5 6 7 11 7 11 7 6 6 9 6 5 7 8 7 8 7 7 5 8 6 7 6 9 4 5 5 8 6 6 7 9 9 7 6 7 8 7 7 7 11 9 8 9 7 8 6 10 8 9 7 9 10 7 10 6 11 8 9 8),ブランドB の場合(0 2 4 4 4 3 5 7 5 5 6 4 9 6 8 7 8 6 7 8 6 6 5 8 7 12 8 9 8 7 7 9 8 7 8 7 6 7 10 7 5 6 9 8 9 8 8 6 8 9 8 11 8 8 6 8 6 6 10 7 6 9 7 9 6 7 8 9 6 7 8 7 11 8 8 8 8 7 7 8 10 7 10 7 8 9 9 7 7 6 7 7 9 4 10 8 8 7 7 8 6 8 7 4) となった.標識率pi = ri/ci は上昇していることが伺われる.

新捕獲数ni の変化はブランドA の場合n = (0 6 4 3 6 2 7 1 3 5 2 1 2 2 3 1 1 2 3 2 1 0 1 2 2 0 0 1 0 0 1 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 1 0 1 0 1 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0) ブランドB の場合(0 7 2 4 5 6 5 4 4 0 1 3 0 2 0 1 1 1 0 1 2 2 1 1 1 0 2 1 1 0 0 0 0 1 1 0 3 1 0 1 2 0 1 0 0 0 0 0 0 0 0 0 2 0 0 0 0 1 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0) となった.捕獲が進むにつれて,急速に減少していく.
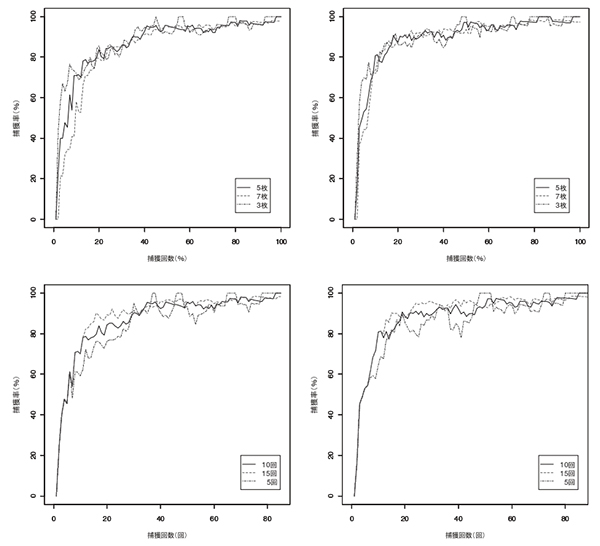
点推定値  の変化はブランドA の場合
の変化はブランドA の場合 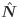 = (0.0 20.0 24.0 27.3 34.0 34.6 41.8 41.5 43.5 47.7 49.1 51.8 54.6 56.6 58.8 61.4 60.4 64.0 67.1 67.0 68.5 69.8 71.1 73.0 74.3 74.8 76.1 76.1 75.0 74.2 74.7 76.3 76.0 75.1 73.8 74.1 74.3 74.0 75.1 76.5 76.9 76.4 76.7 77.1 77.3 77.5 77.8 78.2 78.6 78.0 78.3 78.5 79.7 80.1 80.4 81.7 82.0 82.6 81.8 83.0 82.3 82.6 81.9 82.1 82.2 81.5 81.7 81.7 82.7 82.0 82.1 82.2 83.1 83.3 83.6 83.8 84.0 84.2 83.5 83.6 83.6 83.8 83.0 83.0),ブランドB の場合(0.0 26.7 23.1 26.0 30.4 36.7 41.4 44.6 48.0 47.6 48.1 51.4 53.5 56.3 56.7 56.3 56.3 56.8 55.6 56.9 58.6 58.9 61.0 61.5 63.4 63.8 65.7 66.7 68.4 69.1 68.7 68.0 67.8 68.4 69.0 69.9 71.5 72.5 72.4 73.8 76.2 77.4 79.3 79.4 79.5 80.2 78.4 78.1 78.7 78.2 76.7 76.7 77.6 77.8 78.0 78.2 78.5 79.5 79.8 80.1 81.4 82.0 80.6 80.8 81.0 82.2 83.4 82.8 83.2 83.5 82.8 83.0 83.2 83.4 84.4 83.8 83.1 83.2 83.3 83.4 83.5 83.6 83.7 83.8 83.0 83.0 83.0 83.0 83.0 83.0 84.0 84.0 84.2 84.3 84.4 84.5 84.6 84.7 84.8 84.9 84.0 84.0 84.0 84.0) となった.9 回の捕獲を遡って計算している.したがって捕獲数は10 回である.
= (0.0 20.0 24.0 27.3 34.0 34.6 41.8 41.5 43.5 47.7 49.1 51.8 54.6 56.6 58.8 61.4 60.4 64.0 67.1 67.0 68.5 69.8 71.1 73.0 74.3 74.8 76.1 76.1 75.0 74.2 74.7 76.3 76.0 75.1 73.8 74.1 74.3 74.0 75.1 76.5 76.9 76.4 76.7 77.1 77.3 77.5 77.8 78.2 78.6 78.0 78.3 78.5 79.7 80.1 80.4 81.7 82.0 82.6 81.8 83.0 82.3 82.6 81.9 82.1 82.2 81.5 81.7 81.7 82.7 82.0 82.1 82.2 83.1 83.3 83.6 83.8 84.0 84.2 83.5 83.6 83.6 83.8 83.0 83.0),ブランドB の場合(0.0 26.7 23.1 26.0 30.4 36.7 41.4 44.6 48.0 47.6 48.1 51.4 53.5 56.3 56.7 56.3 56.3 56.8 55.6 56.9 58.6 58.9 61.0 61.5 63.4 63.8 65.7 66.7 68.4 69.1 68.7 68.0 67.8 68.4 69.0 69.9 71.5 72.5 72.4 73.8 76.2 77.4 79.3 79.4 79.5 80.2 78.4 78.1 78.7 78.2 76.7 76.7 77.6 77.8 78.0 78.2 78.5 79.5 79.8 80.1 81.4 82.0 80.6 80.8 81.0 82.2 83.4 82.8 83.2 83.5 82.8 83.0 83.2 83.4 84.4 83.8 83.1 83.2 83.3 83.4 83.5 83.6 83.7 83.8 83.0 83.0 83.0 83.0 83.0 83.0 84.0 84.0 84.2 84.3 84.4 84.5 84.6 84.7 84.8 84.9 84.0 84.0 84.0 84.0) となった.9 回の捕獲を遡って計算している.したがって捕獲数は10 回である.
点推定値の標準誤差の変化は,ブランドA の場合(0.0 6.9 5.6 5.4 6.2 4.9 6.1 4.8 4.3 4.8 4.3 4.1 4.0 3.9 3.9 3.9 3.3 3.6 3.7 3.4 3.4 3.4 3.4 3.4 3.5 3.4 3.4 3.0 2.7 2.3 2.2 2.4 2.3 1.9 1.4 1.4 1.4 1.2 1.5 1.8 1.9 1.6 1.6 1.6 1.6 1.6 1.6 1.6 1.7 1.4 1.5 1.5 1.8 1.9 1.8 2.1 2.0 2.0 1.7 2.0 1.6 1.7 1.4 1.3 1.3 0.9 0.9 0.9 1.3 0.9 0.9 0.9 1.2 1.2 1.3 1.3 1.2 1.3 0.9 0.9 0.8 0.9 0.0 0.0),ブランドB の場合(0.0 11.2 5.1 4.5 4.7 5.6 5.4 4.9 4.8 4.2 3.7 3.9 3.6 3.6 3.3 2.9 2.6 2.5 2.0 2.1 2.3 2.2 2.4 2.3 2.4 2.2 2.4 2.3 2.4 2.4 2.1 1.8 1.7 1.7 1.7 1.8 2.2 2.2 2.1 2.2 2.6 2.7 2.8 2.7 2.5 2.5 1.9 1.8 1.8 1.6 0.8 0.8 1.2 1.2 1.3 1.3 1.3 1.6 1.5 1.6 1.8 1.9 1.3 1.3 1.3 1.6 1.9 1.6 1.6 1.6 1.3 1.4 1.3 1.3 1.6 1.3 0.9 0.9 0.9 0.9 0.9 0.9 0.9 0.9 0.0 0.0 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0) となった.収束に向 けてゆっくりと減少してゆく傾向が観察される.
点推定値の95%上側限界値の変化は,ブランドA の場合(0.0 33.6 35.0 37.8 46.2 44.1 53.8 50.8 51.9 57.1 57.6 59.7 62.5 64.2 66.3 69.0 66.8 71.0 74.4 73.6 75.2 76.4 77.7 79.7 81.2 81.4 82.7 82.0 80.2 78.6 79.1 81.0 80.5 78.8 76.6 76.9 77.2 76.4 78.0 80.1 80.6 79.5 79.8 80.3 80.5 80.7 81.0 81.3 81.9 80.8 81.2 81.4 83.2 83.7 84.0 85.8 85.9 86.6 85.2 86.8 85.5 85.9 84.6 84.7 84.7 83.3 83.5 83.5 85.2 83.7 83.9 83.9 85.6 85.7 86.1 86.3 86.4 86.7 85.2 85.3 85.3 85.5 83.0 83.0),ブランドB の場 合(0.0 48.5 33.1 34.8 39.6 47.7 52.1 54.1 57.3 55.8 55.4 59.1 60.5 63.4 63.1 62.0 61.4 61.6 59.6 60.9 63.0 63.2 65.7 65.9 68.2 68.1 70.4 71.3 73.2 73.7 72.9 71.6 71.0 71.8 72.4 73.5 75.8 76.9 76.5 78.2 81.4 82.7 84.8 84.7 84.5 85.2 82.2 81.6 82.2 81.2 78.3 78.3 80.0 80.2 80.5 80.7 81.0 82.6 82.8 83.2 85.0 85.7 83.3 83.4 83.6 85.4 87.0 85.8 86.4 86.7 85.4 85.7 85.7 86.0 87.5 86.3 84.9 85.1 85.1 85.2 85.2 85.3 85.5 85.6 83.0 83.0 83.0 83.0 83.0 83.0 85.8 85.9 86.1 86.2 86.3 86.4 86.6 86.7 86.8 86.8 84.0 84.0 84.0 84.0) となった.
以上の情報を用い捕獲率Cr の変化を示したのが図1 である4.
ブランドA の場合,8 割を超えるのは17 回目の捕獲である.85 枚の自由記述を読んだ時点で あり,精読に当てた全時間の20%である.9 割を超えるのは30 回目の捕獲である.150 枚の自由 記述を読んだ時点であり,精読に当てた時間の36%であった.ブランドB の場合は8 割を超える のは10 回目の捕獲である.50 枚の自由記述を読んだ時点であり,精読に当てた全時間の10%で ある.9 割を超えるのは19 回目の捕獲である.95 枚の自由記述を読んだ時点であり,精読に当 てた時間の18%であった.捕獲率Cr を参照すると,精読に要する時間を大幅に節約することが できることが示された.
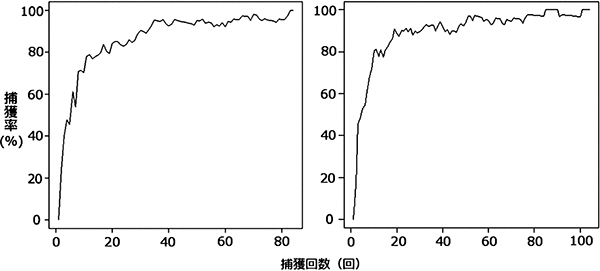
また今回の分析に関して,捕獲率の計算に利用したデータをまとめる回数と,ラグの回数を変 化させた結果を示したものが図2 である.図の左側がブランドA,右側がブランドB を示してお り,上段がそれぞれ5 枚,7 枚,3 枚読むたびに捕獲率を計算した結果である.データをまとめ る枚数によって捕獲回数が変化してしまうため,図の横軸を捕獲回数の割合で示し,揃えている. 下段はデータを遡って計算に用いる捕獲の回数(ラグの回数)を10 回,15 回,5 回として捕獲率 を計算した結果である.どちらのブランドについても,まとめる枚数が多い程,またラグの回数 が多い程捕獲率が速く高まって行き,かつ変化が安定していくことが伺える.しかし,本質的に これらの変化が異なる結論を導くわけではないことが確認された.
資源量推定の公式を自由記述の分析における飽和度の指標として用いる試みは,国内外の研究をみても筆者の知る限り皆無であり,その意味で本研究は端緒である.
本研究では,応用例としてブランドイメージに対する意見が既にテキストデータとしてまとめ られているものを例に挙げた.また自由記述数も421 枚,518 枚と多い.本論文の目的は総知見 数を推定する方法を提案することであったために,捕獲率の推定値が1.00 に収束する例を示す 必要があったためである.しかし,いつも1.00 に収束するわけではないだろう. たとえばインタ ビュー調査による10 人前後の捕獲では,あとからの面接では新規な話題は少なくなっていくだろ うが,その程度の人数ではゼロにはならないだろうから,Cr は1.00 にはならない可能性が高い.
複雑なテーマについて知見を収集する際には完全に飽和度が満たされることが本来難しく,要 求してもいけないということを認識する必要がある. 研究分野・資源・時間によってはCr = 0.8 や0.7 でもよい場合がないとは言えず,この値に関する妥当な数値については応用分野の研究事 例を待つ必要があるだろう.大切なことは集めようとしている知見が,すでに持っている知見でどの程度カバーされているかということを客観的に把握することである.
次に,本研究では知見数は自然数で数えられるものと仮定している.しかし厳密には,知見は 数を数えるように把握されるものではない.たとえば2 番目の知見である「好き・好み・気にいっ ている・ファン」は1 つと数えているが,実際には4 つだけでなく,無数の似たような知見を代 表している. また20 番目の知見と似ていなくもない.しかし,例えば質的研究におけるグラウン デッド・セオリー・アプローチの分野では,断片化というプロセスで知見を数えられるカテゴリ として扱う.本論文ではKJ 法における1 枚のカードに書く個々の情報を知見と呼ぶこととした.
またデータの収集と知見のコード化,再コード化は何度もなされる必要がある.佐藤(2008) はこれを「木を見て森を見る,森を見て木を見る」とか「インタラクティブ性」と呼んでいる. 本研究でも,100 枚読む段階,200 枚読む段階で,再コード化を行った.必要があれば,何度でも再コード化して最初からCr を計算し直すことが大切である.
知見の収集においては,まず捕獲率を気にせずに充分に知見の収集を行い,そろそろ新しい知 見はでなくなってきた,あるいは研究期間が残り少なくなってきたという段階になってから,すなわちmi の値が充分に大きくなった段階からCr を計算し始めるべきだろう.データ収集の初 期段階から数値を気にするのは生産的ではない.Crを計算し始める前のmi の増加の過程では,互いに独立とは限らないどのような知見の収集方法を用いても構わないため,展望的に本方法は カテゴリ化を伴うテキストデータを扱った如何なる流儀の質的研究にも適用可能である.このた め付加的な例として,質的研究法の一つとしてインタビューを行った際に得られたデータをテキ ストデータとしてまとめ,得られた知見についての捕獲率の検討を行う手順について,付録として巻末に提案する.
そして,本方法は「知見の収集の試行を完全には表現できていない」ということを述べておきた い. 多くのアンケート調査によって無作為抽出が厳密に守られていないように,知見の収集もま た無作為ではない.具体的には,出現しやすい意見(典型的意見)と出現しにくい意見(少数意見) があるのに意見の出現が等確率であることを本モデルでは仮定している.これは総知見数N を 少なく見積もるバイアスを生むだろう.知見の事前確率を導入したベイズモデル等の数理モデル への改良が考えられるが,本方法のような非繰り返し的推定量にはならないだろう.本方法のメ リットはその手軽さにある.
しかし本家の資源量推定の分野でも,個体の捕獲確率は一様ではない.逃げるのが上手い個体, 下手な個体の差は大きい.そもそも個体は地域に一様に分布していなくて,群れとして捕獲され ることが多いから,等確率でないばかりでなく,独立でもないことは明らかである.それでも資 源量推定は,実用的な意味で成果を上げていることを鑑みると,本方法は現時点でも実用的には 有望な数理的表現といえるのではないだろうか.
捕獲率は新たに捕獲を行ったとしても新知見が得られない場合,すなわち既出の知見が多く得 られた場合に高くなる性質を持っている.今回の適用例からは,ブランドB の方が8 割,9 割の 捕獲率となる捕獲回数が早かったため,ブランドB はブランドA より意見にまとまりがあり,早 い収束となったといえるだろう.一方,捕獲率は途中の捕獲回で新知見が多くみられた場合には, 値が下がる性質を持っている. このため捕獲率が順調に上がっていったものの,途中で大きく下 がる傾向が見られた場合には,それまでに収集した知見と内容的に大きく異なるテキストが得ら れたことを意味するために,そのテキストに本当に知りたい内容を含んだ自由記述が得られてい るかどうか,考察の対象とすることができるだろう. コーディングの段階で気付く可能性も十分考えられるものの,テキストの内容を吟味する上で,この意味でも捕獲率を計算することは有意 義であるといえる.
最後に,今回の適用例ではデータを遡って計算するラグの回数を“10 回”,データをまとめる回 数を“5 回” としており,(4) 式を利用する場合には推定値がこれらの回数によって若干値が変わ ることが図2 からも確認された.このため,これらの最適な回数については今後の課題として検 討したい.
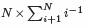 個のお菓子を買う必要があることが知られている.
個のお菓子を買う必要があることが知られている.本手法を質的研究の一つであるインタビュー調査に用いた計算例を示す.まず状況として,インタビューの結果聞き得た内容を録音し,テキストデータとした場合を考える.得られたテキストの中から研究に重要な知見1 個をカード1 個に記していき,できあがったカードの集合が1 捕獲分の知見となる.この集合1 つを得ることを1 捕獲という.
20 人から話を聞いて153 個のカード(153 個の知見)が得られ,そして研究者自身はインタビューの最後の数人からは,あまり新しいカードは作れなくなったと実感したとする.そこで知見収集の飽和度の目安として捕獲率を計算しようと考える.
21 人目の話から52 個のカード(52 個の知見)に相当する話が聞け,新しいカードは3 個だった場合,m1 = 153, c1 = 52,r1 = 49,n1 = 3 である.したがって総知見数の点推定値は.
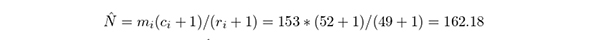
となる.I = 1 から, 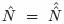 である.したがって点推定値を使った捕獲率は96.19% = (153 + 3)/162.18 となる.十分な高さと言えよう.標準誤差は
である.したがって点推定値を使った捕獲率は96.19% = (153 + 3)/162.18 となる.十分な高さと言えよう.標準誤差は
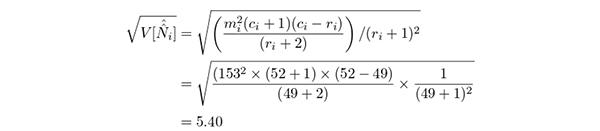
と計算される.95%信頼区間の上側限界を利用した捕獲率は90.30% = (153+3)/(162.18+5.40∗1.96) である.この値でも高いと言えるだろう.
念のため22 人目の人から話を聞き,63 個のカード(63 個の知見)に相当する話が聞けたとし,新しく作られたカードは1 個だったとする.m2 = 156,c2 = 63,r2 = 62,n2 = 1 である.したがって,この話からのみのデータで計算される点推定値は
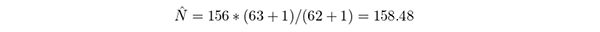
である.I = 2 であるため結果を統合する.再捕獲の合計は49 + 62 = 111 であるから,2 人の話の結果を統合した点推定値は

となる.ゆえに点推定値を使った捕獲率は98.06% = (156 + 1)/160.11 である.標準誤差は

なので,95%信頼区間の上側限界を利用した捕獲率は94.85% = (156+1)/(160.11+2.76 ∗ 1.96)と計算される.飽和度の目安としては十分な高さだろう.このように,決して「新しいカードが全くなくなるまでインタビューを続けなければいけない」という訳ではない.