ABSTRACT
Glycyrrhiza uralensis and G. glabra, members of the Fabaceae, are medicinally important species that are native to Asia and Europe. Extracts from these plants are widely used as natural sweeteners because of their much greater sweetness than sucrose. In this study, the three complete chloroplast genomes and five 45S nuclear ribosomal (nr)DNA sequences of these two licorice species and an interspecific hybrid are presented. The chloroplast genomes of G. glabra, G. uralensis and G. glabra × G. uralensis were 127,895 bp, 127,716 bp and 127,939 bp, respectively. The three chloroplast genomes harbored 110 annotated genes, including 76 protein-coding genes, 30 tRNA genes and 4 rRNA genes. The 45S nrDNA sequences were either 5,947 or 5,948 bp in length. Glycyrrhiza glabra and G. glabra × G. uralensis showed two types of nrDNA, while G. uralensis contained a single type. The complete 45S nrDNA sequence unit contains 18S rRNA, ITS1, 5.8S rRNA, ITS2 and 26S rRNA. We identified simple sequence repeat and tandem repeat sequences. We also developed four reliable markers for analysis of Glycyrrhiza diversity authentication.
INTRODUCTION
Licorice is a perennial herb belonging to the family Fabaceae. The genus Glycyrrhiza includes about 18 species in Asia, Europe and the Americas. Glycyrrhiza uralensis Fisch. occurs from Central Asia to the northeastern part of China, whereas G. glabra L. is distributed from southern Europe to the northwestern part of China. The roots and stolons of G. uralensis and G. glabra produce some of the most important crude drugs in the world (Gibson, 1978), mainly glycyrrhizin, an oleanane-type triterpene saponin. Glycyrrhiza plants have been used traditionally as anti-inflammatory (Finney and Somers, 1958; Kroes et al., 1997), antiviral (Fiore et al., 2008), antiallergy (Park et al., 2004) and antiulcer treatments (He et al., 2001). Because licorice extracts are approximately 150 times sweeter than sucrose (Kitagawa, 2002), they are also widely used in the world as a natural sweetener, with an annual value of over US $42 million (Parker, 2006). As a medicinal plant, correct authentication of licorice plant ingredients ensures their safe use.
Chloroplast (CP) genome sequences are of central importance to tracing plant taxonomy and authentication because they are highly conserved across plant species. The CP genome is composed of a large single-copy region, a small single-copy region and two inverted repeats (IRs) (Gary et al., 1984; Shinozaki et al., 1986; Leseberg and Duvall, 2009). Interestingly, licorice species belong to the inverted repeat-lacking clade (IRLC) (Wojciechowski et al., 2004) of papilionoid legumes, characterized by the loss of one copy of the IR. To date, only the CP genome of G. glabra has been sequenced among the Glycyrrhiza species (Sabir et al., 2014).
The sequence of the 45S nuclear ribosomal DNA (nrDNA), bearing the 18S-5.8S-26S ribosomal RNA genes, also provides additional information that can be very useful in plant taxonomy and DNA barcoding (Chen et al., 2014; Techen et al., 2014; Mishra et al., 2016). In particular, internal transcribed spacer (ITS1 and ITS2) sequences in nrDNA are potential barcodes (Álvarez and Wendel, 2003; Yao et al., 2010). Although these sequences are valuable for medicinal identification, there is little information about their comparison and polymorphism between Glycyrrhiza species.
In the current study, we analyzed the complete sequences of the CP and nrDNA of two Glycyrrhiza species. In addition, we identified 160 polymorphic sites in the CP genome and 10 polymorphic sites in the nrDNA that are valuable for the identification and authentication of G. glabra and G. uralensis as well as G. glabra × G. uralensis interspecific hybrids. Despite their useful applications as medicinal ingredients and food resources, there is limited information regarding the complete chloroplast genomes and the nrDNA sequences of Glycyrrhiza species. The results of this study provide an insight into the genetic relationships among the various species in the genus Glycyrrhiza.
MATERIALS AND METHODS
Plant materials and DNA extraction
European licorice (G. glabra; the female parent) and Chinese licorice (G. uralensis; the male parent) were planted in the greenhouse and artificially crossed in May 2007. In June 2008, stolons were separated from F1 (G. glabra × G. uralensis) licorice seedlings and cultivated, resulting in 32 clonal lines of interspecific hybrids. The aerial parts of the two Glycyrrhiza species were collected from Eumseong (36°56′ 38.68″N, 127°45′ 17.60″E), and identified by J.-H. L. Voucher specimens (G. glabra: MPS000350-1, G. uralensis: MPS004535, G. glabra × G. uralensis F1: MPS002499) are deposited at the Korea Medicinal Resources Herbarium, Eumseong, Korea. Total DNA was extracted from young and fully expanded leaves of Glycyrrhiza species using the modified cetyltrimethylammonium bromide method (Allen et al., 2006). DNA purity and concentration were checked by electrophoresis on a 1.2% agarose gel and by DropSense96 Spectrophotometer (Trinean, Gentbrugge, Belgium). High-quality DNA (concentration > 100 ng/μl; A260/A230 > 1.7; A260/A280 = 1.8 − 2.0) was used for further analysis.
Illumina sequencing and de novo assembly of CP and nrDNA
Paired-end (PE) libraries were constructed with insert sizes ranging from 280 to 430 bp and following the manufacturer’s specified protocols for the TruSeq PE Cluster Kit (Illumina, San Diego, CA, USA). The PE libraries were sequenced using the Illumina genome analyzer (HiSeq 1000, Illumina) platform at our in-house facility (Genomics Division, National Institute of Agricultural Sciences, Korea). CP genome and nrDNA de novo assembly was accomplished using approaches described in Kim et al. (2015). In short, sequences of low quality were trimmed to below Phred scores of 20 using CLC quality trim software. The remaining high-quality sequences were assembled into contigs, using CLC genome assembler beta 4.06 (CLC, Aarhus, Denmark) with a minimum of 150–500 bp autonomously controlled overlap size, at Phyzen (Seongnam, South Korea). The obtained CP genome sequences were assembled using the G. glabra (KF201590) genome as a reference sequence. The assembled nrDNA contigs fully covered the 45S nrDNA cistron unit and partially covered the intergenic spacer sequences.
Gene annotation, SNP genotyping and repeat sequence analysis
CP sequences were annotated using DOGMA (http://dogma.ccbb.utexas.edu) (Wyman et al., 2004) and BLAST searches. tRNA genes were identified using DOGMA and tRNAscan-SE (http://lowelab.ucsc.edu/tRNAscan-SE/) (Schattner et al., 2005). The circular CP genome map was constructed using OGDraw software (http://ogdraw.mpimp-golm.mpg.de/) (Lohse et al., 2007). Repeats in the CP sequences of the Glycyrrhiza species were investigated using Tandem Repeats Finder, version 4.0 (http://tandem.bu.edu/trf/trf.html) (Benson, 1999), with 100% similarity and a minimum size of 10 bp. Simple sequence repeat (SSR) motifs with a minimum size 10 bp were identified using MISA (http://pgrc.ipk-gatersleben.de/misa/).
Sequence divergence analysis
The CP genome sequence of G. glabra (KF201590) was downloaded from the NCBI database and aligned with newly determined sequences using MAFFT version 7 (http://mafft.cbrc.jp/alignment/server/). Comparison of the four CP genomes among G. glabra (KU891817), G. uralensis (KU862308), G. glabra × G. uralensis (KU862307) and G. glabra (KF201590) was performed using the mVISTA program in Shuffle-LAGAN mod (Frazer et al., 2004).
Identification of polymorphisms that can distinguish Glycyrrhiza species
Four PCR primers (Supplementary Table S1) were designed based on CP InDels and nrDNA-specific sequence regions among Glycyrrhiza species. These primers were used to distinguish G. glabra and G. uralensis as well as G. glabra × G. uralensis. The PCR conditions were 4 min at 94 ℃ followed by 38 cycles of 94 ℃ for 30 s, 60 ℃ for 30 s and 72 ℃ for 15 s, followed by a final extension at 72 ℃ for 1 min. Gel electrophoresis was performed using a 1% agarose gel, and amplified fragments were stained with a fluorescent dye.
RESULTS AND DISCUSSION
After sequencing, we employed a combination of de novo assembly and reference-guided strategies using Illumina PE reads ranging from 587 to 741 Mbp, which represents approximately 226- to 400-fold CP genome coverage. The complete CP genomes of G. glabra, G. uralensis and G. glabra × G. uralensis were circles of 127,895 bp, 127,716 bp and 127,939 bp, respectively (Table 1). The complete CP gene content and order were identical among the Glycyrrhiza species (Fig. 1). These three CP genomes belong to the IRLC (Wojciechowski et al., 2004) of papilionoid legumes, where the loss of one copy of the IR has occurred. The Glycyrrhiza CP genomes harbor 110 annotated genes: 76 protein-coding genes, 30 tRNA genes and 4 rRNA genes (Table 2). Among these, nine protein-coding and six tRNA genes contain a single intron, while one gene (ycf3) contains two introns. infA, rpl22 and rps16 were absent in Glycyrrhiza species. Two of these genes, infA and rpl22, are also missing from the CP genomes of other legumes (Doyle et al., 1995) but are present in the nucleus (Gantt et al., 1991), and the loss of rps16 from CP DNA in Medicago and Populus has been reported (Ueda et al., 2008). Whole-genome alignments of Glycyrrhiza species with the annotation of G. glabra (KF201590) (Sabir et al., 2014) as a reference using mVISTA revealed their sequence variation (Fig. 2). The whole CP genome alignments showed that the coding regions are more highly conserved than the intergenic regions, as is the case in most angiosperms. Analysis of sequence variation between G. glabra (KF201590) and G. glabra (KU891817) showed 30 single-nucleotide polymorphisms (SNPs) and 24 insertions-deletions (InDels). These SNPs and InDels may provide valuable information for authenticating Glycyrrhiza species. The CP genome of G. glabra × G. uralensis shared 99.98 and 99.85% nucleotide sequence identity with G. glabra and G. uralensis, respectively, indicating that Glycyrrhiza species also follow the mode of maternal plastid inheritance (Hagemann et al., 2004).
Table 1. Summary statistics of CP genome and nrDNA sequencing and assembly for three
Glycyrrhiza species
| Scientific name | Amount (Mbp) | CP genome | nrDNA |
|---|
| Length (bp) | Coverage (fold) | GenBank Acc. No. | Length (bp) | Coverage (fold) | GenBank Acc. No. |
|---|
| G. glabra | 741.68 | 127,895 | 367.81 | KU891817 | Type 1 | 5,947 | 616.43 | KX530462 |
| Type 2 | 5,947 | 600.79 | KX530463 |
| G. uralensis | 721.47 | 127,716 | 225.95 | KU862308 | Type 1 | 5,948 | 1259.83 | KX530461 |
| G. glabra x | 587.42 | 127,939 | 399.91 | KU862307 | Type 1 | 5,948 | 739.21 | KX530459 |
| G. uralensis | Type 2 | 5,947 | 684.44 | KX530460 |
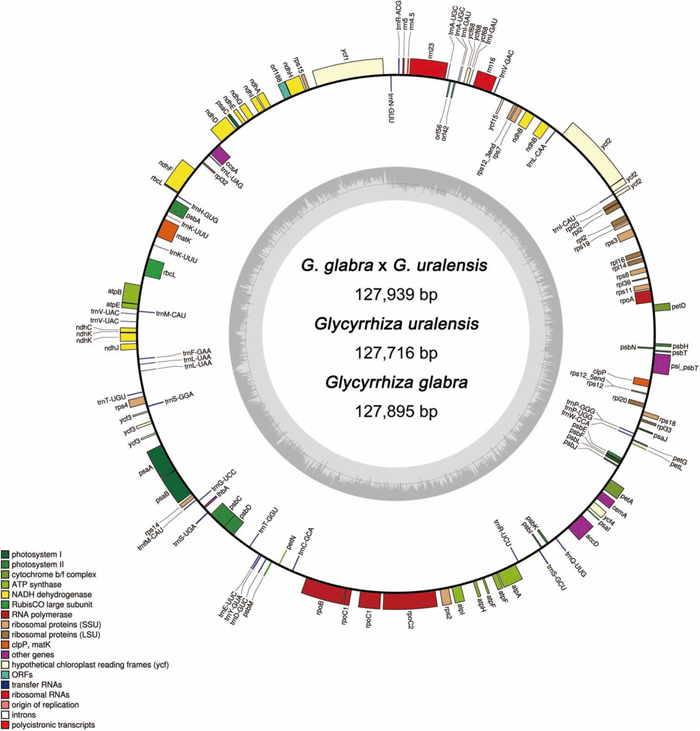
Table 2. Gene composition in
Glycyrrhiza CP genomes
| Category of gene group | Group of genes | Names of genes |
|---|
| Self-replication | Ribosomal RNAs | 16S (rrn16), 23S (rrn23)
4.5S (rrn4.5), 5S (rrn5) |
| Transfer RNAs | trnA-UGC †, trnC-GCA, trnD-GUC, trnE-UUC, trnF-GAA, trnfM-CAU, trnG-GCC, trnG-UCC †, trnH-GUG, trnl-CAU, trnI-GAU †, trnK-UUU †, trnL-UAA †, trnL-UAG, trnL-CAA, trnM-CAU, trnM-GUU, trnP-UGG, trnQ-UUG, trnR-ACG, trnR-UCU, trnS-GCU, trnS-GGA, trnS-UGA, trnT-GGU, trnT-UGU, trnV-UAC †, trnV-GAC, trnW-CCA, trnY-GUA |
| Small subunit of ribosome | rps2, rps3, rps4, rps7, rps8, rps11, rps12 †, rps14, rps15, rps18, rps19 |
| Large subunit of ribosome | rpl2 †, rpl14, rpl16 †, rpl20, rpl23, rpl32, rpl33, rpl36 |
| RNA polymerase | rpoA, rpoB, rpoC1 †, rpoC2 |
| Photosynthesis | NADH-dehydrogenase | ndhA †, ndhB †, ndhC, ndhD, ndhE
ndhF, ndhG, ndhH, ndhI, ndhJ, ndhK |
| Photosystem I | psaA, psaB, psaC, psaI, psaJ, ycf3 # |
| Photosystem II | psbA, psbB, psbC, psbD, psbE, psbF
psbH, psbI, psbJ, psbK, psbL, psbM
psbN, psbT, psbZ |
| Cytochrome b6/f | petA, petB †, petD †, petG, petL, petN |
| ATP synthase | atpA, atpB, atpE, atpF †, atpH, atpI |
| Rubisco | rbcL |
| Other genes | | accD, ccsA, cemA, clpP, matK |
| Unknown function | ORFs ¥ | ycf1, ycf2, ycf4 |
† indicates the existence of a single intron in the corresponding genes;
# indicates the existence of two introns in the corresponding gene;
¥ indicates open reading frames.

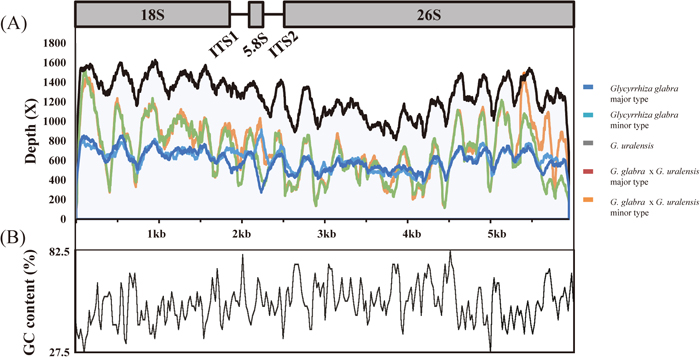
The nrDNA sequences were assembled into single contigs that were either 5,947 bp or 5,948 bp in length. Glycyrrhiza glabra and G. glabra × G. uralensis showed two types of nrDNA, while G. uralensis contained a single type of nrDNA (Table 1). The complete nrDNA sequence unit contains 18S rRNA, ITS1, 5.8S rRNA, ITS2 and 26S rRNA (Fig. 3). The average GC content ranged between 53.86 and 53.91%, which is almost identical among the five nrDNAs (Fig. 3).
Repeat sequences in the CP genomes of G. glabra, G. uralensis and G. glabra × G. uralensis were analyzed using Tandem Repeats Finder, version 4.0. A total of 20 unique sequences of tandem repeats were detected in the Glycyrrhiza CP genomes (Supplementary Table S2). The lengths of tandem repeats in the CP genomes ranged from 11 to 39 bp, and most of the tandem repeats appear in two copies. As in Bupleurum falcatum (Shin et al., 2016), most of the tandem repeat sequences were in non-coding regions, with only three genic regions (rps11, rpl20 and ycf1) containing tandem repeat sequences. Tandem repeat sizes identified in Glycyrrhiza CP genomes were invariably less than 40 bp, which is sufficient for illegitimate recombination (Sherman-Broyles et al., 2014). SSRs, also known as microsatellites, frequently occur in CP genomes. In this study, mononucleotide SSRs were excluded. We identified 350, 349 and 352 SSRs with a length of at least 10 bp in G. glabra, G. uralensis and G. glabra × G. uralensis, respectively (Fig. 4). Among the SSRs, the pentanucleotide SSRs were the most abundant in the CP genomes, accounting for 84% of total SSRs. Di-, tri- and tetranucleotide repeats were composed of A or T at a higher level, which reflects AT richness in the CP genomes (Zhang et al., 2011; Yi and Kim, 2012). These SSRs may further serve as genetic markers for phylogenetic and medicinal plant authentication studies (Zhang et al., 2016).

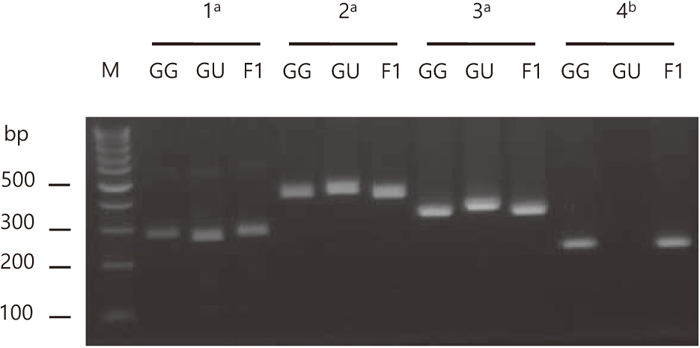
We detected 160 and 10 SNPs from the Glycyrrhiza CP genomes and nrDNAs, respectively (Supplementary Table S3 and S4). Like SSRs, most SNPs in chloroplast DNA are located in non-coding regions, whereas SNPs in nrDNA were detected in ITS1, ITS2 and 26S. Furthermore, we identified 83 InDels in the Glycyrrhiza CP genomes. PCR primers were designed based on InDels and specific sequence regions (Supplementary Table S1). We successfully amplified four PCR products that can distinguish between G. glabra and G. uralensis species (Fig. 5). The primer pairs ycf3F01/ycf3R01, atpHF01/atpHR01 and ycf2F01/ycf2R01 amplified PCR products in all three Glycyrrhiza CP genomes. On the other hand, the 5.8SF01/5.8SR01 primer pair amplified a PCR product only in G. glabra and G. glabra × G. uralensis, in nrDNA. These primers will be used as Glycyrrhiza authentication markers.
In this study, the complete Glycyrrhiza CP genomes and nrDNA have been sequenced. These genomes belong to the IRLC of papilionoid legumes, which is characterized by the loss of one copy of the IR. The complete CP genomes of G. glabra, G. uralensis and G. glabra × G. uralensis were 127,895 bp, 127,716 bp, and 127,939 bp, respectively. The nrDNA sequences were either 5,947 bp or 5,948 bp. Glycyrrhiza glabra and G. glabra × G. uralensis showed two types of nrDNA, while G. uralensis contained a single type of nrDNA. We developed four reliable markers for the analysis of Glycyrrhiza diversity authentication. This study will open up further avenues of research to develop a better understanding of the molecular ecology and molecular phylogeny within Glycyrrhiza species.
ACKNOWLEDGMENTS
The authors thank the National Institute of Agricultural Sciences Genome Sequencing Core facility for their services. This work was carried out with the support of the National Institute of Agricultural Sciences (Project No. PJ010889), Republic of Korea.
REFERENCES
- Allen, G. C., Flores-Vergara, M. A., Krasynanski, S., Kumar, S., and Thompson, W. F. (2006) A modified protocol for rapid DNA isolation from plant tissues using cetyltrimethyl-ammonium bromide. Nat. Protoc. 1, 2320–2325.
- Álvarez, I., and Wendel, J. F. (2003) Ribosomal ITS sequences and plant phylogenetic inference. Mol. Phylogenet. Evol. 29, 417–434.
- Benson, G. (1999) Tandem repeats finder: a program to analyze DNA sequences. Nucleic Acids Res. 27, 573–580.
- Chen, S., Pang, X., Song, J., Shi, L., Yao, H., Han, J., and Leon, C. (2014) A renaissance in herbal medicine identification: from morphology to DNA. Biotechnology Adv. 32, 1237–1244.
- Doyle, J. J., Doyle, J. L., and Palmer, J. D. (1995) Multiple independent losses of two genes and one intron from legume chloroplast genomes. Syst. Bot. 20, 272–294.
- Finney, R. S. H., and Somers, G. F. (1958) The anti-inflammatory activity of glycyrrhetinic acid and derivatives. J. Pharm. Pharmacol. 10, 613–620.
- Fiore, C., Eisenhut, M., Krausse, R., Ragazzi, E., Pellati, D., Armanini, D., and Bielenberg, J. (2008) Antiviral effects of Glycyrrhiza species. Phytother. Res. 22, 141–148.
- Frazer, K. A., Pachter, L., Poliakov, A., Rubin, E. M., and Dubchak, I. (2004) VISTA: computational tools for comparative genomics. Nucleic Acids Res. 32, W273–W279.
- Gantt, J. S., Baldauf, S. L., Calie, P. J., Weeden, N. F., and Palmer, J. D. (1991) Transfer of rpl22 to the nucleus greatly preceded its loss from the chloroplast and involved the gain of an intron. EMBO J. 10, 3073–3078.
- Gary, M. W., Sankoff, D., and Cedergren, R. J. (1984) On the evolutionary descent of organisms and organelles: a global phylogeny based on a highly conserved structural core in small subunit ribosomal RNA. Nucleic Acids Res. 12, 5837–5852.
- Gibson, M. R. (1978) Glycyrrhiza in old and new perspectives. Lloydia 41, 348–354.
- Hagemann, R. (2004) The sexual inheritance of plant organelles. In: Molecular Biology and Biotechnology of Plant Organelles. (eds.: Daniell, H., and Chase, C.), pp. 99–113. Springer, Heidelberg.
- He, J. X., Akao, T., Nishino, T., and Tani, T. (2001) The influence of commonly prescribed synthetic drugs for peptic ulcer on the pharmacokinetic fate of glycyrrhizin from Shaoyao-Gancao-tang. Biol. Pharm. Bull. 24, 1395–1399.
- Kim, K., Lee, S. C., Lee, J., Yu, Y., Yang, K., Choi, B. S., Koh, H. J., Waminal, N. E., Choi, H. I., Kim, N. H., et al. (2015) Complete chloroplast and ribosomal sequences for 30 accessions elucidate evolution of Oryza AA genome species. Sci. Rep. 28, 15655.
- Kitagawa, I. (2002) Licorice root. A natural sweetener and an important ingredient in Chinese medicine. Pure Appl. Chem. 74, 1189–1198.
- Kroes, B. H., Beukelman, C. J., van den Berg, A. J. J., Wolbink, G. J., van Dijk, H., and Labadie, R. P. (1997) Inhibition of human complement by β-glycyrrhetinic acid. Immunology 90, 115–120.
- Leseberg, C. H., and Duvall, M. R. (2009) The complete chloroplast genome of coix lacryma-jobi and a comparative molecular evolutionary analysis of plastomes in cereals. J. Mol. Evol. 69, 311–318.
- Lohse, M., Drechsel, O., and Bock, R. (2007) OrganellarGenomeDRAW (OGDRAW): a tool for the easy generation of high-quality custom graphical maps of plastid and mitochondrial genomes. Curr. Genet. 52, 267–274.
- Mishra, P., Kumar, A., Nagireddy, A., Mani, D. N., Shukla, A. K., Tiwari, R., and Sundaresan, V. (2016) DNA barcoding: and efficient tool to overcome authentication challenges in the herbal market. Plant Biotechnol. J. 14, 8–21.
- Park, H. Y., Park, S. H., Yoon, H. K., Han, M. J., and Kim, D. H. (2004) Anti-allergic activity of 18β-glycyrrhetinic acid-3-O-β-D-glucuronide. Arch. Pharm. Res. 27, 57–60.
- Parker, P. M. (2006) The World Market for Licorice Roots: A 2007 Global Trade Perspective. ICON Group International Inc, San Diego.
- Sabir, J., Schwarz, E., Ellison, N., Zhang, J., Baeshen, N. A., Mutwakil, M., Jansen, R., and Ruhlman, T. (2014) Evolutionary and biotechnology implications of plastid genome variation in the inverted-repeat-lacking clade of legumes. Plant Biotechnol. J. 12, 743–754.
- Schattner, P., Brooks, A. N., and Lowe, T. M. (2005) The tRNAscan-SE, snoscan and snoGPS web servers for the detection of tRNAs and snoRNAs. Nucleic Acid Res. 33, W686–W689.
- Sherman-Broyles, S., Bombarely, A., Grimwood, J., Schmutz, J., and Doyle, J. (2014) Complete plastome sequences from Glycine syndetika and six additional perennial wild relatives of soybean. G3(Bethesda) 4, 2023–2033.
- Shin, D. H., Lee, J. H., Kang, S. H., Ahn, B. O., and Kim, C. K. (2016) The complete chloroplast genome of the Hare’s root, Bupleurum falcatum: its molecular features. Genes(Basel) 7, pii E20 doi:10.3390/genes7050020.
- Shinozaki, K., Ohme, M., Tanaka, M., Wakasugi, T., Hayashida, N., Matsubayashi, T., Zaita, N., Chunwongse, J., Obokata, J., Yamaguchi-Shinozaki, K., et al. (1986) The complete nucleotide sequence of the tobacco chloroplast genome: its gene organization and expression. EMBO J. 5, 2043–2049.
- Techen, N., Parveen, I., Pan, Z., and Khan, I. A. (2014) DNA barcoding of medicinal plant material for identification. Curr. Opin. Biotechnol. 25, 103–110.
- Ueda, M., Nishikawa, T., Fujimoto, M., Takanashi, H., Arimura, S., Tsutsumi, N., and Kadowaki, K. (2008) Substitution of the gene for chloroplast RPS16 was assisted by generation of a dual targeting signal. Mol. Biol. Evol. 25, 1566–1575.
- Wojciechowski, M. F., Lavin, M., and Sanderson, M. J. (2004) A phylogeny of legumes (Leguminosae) based on analysis of the plastid matK gene resolves many well-supported subclades within the family. Am. J. Bot. 91, 1846–1862.
- Wyman, S. K., Jansen, R. K., and Boore, J. L. (2004) Automatic annotation of organellar genomes with DOGMA. Bioinformatics 20, 3252–3255.
- Yao, H., Song, J., Liu, C., Luo, K., Han, J., Li, Y., Pang, X., Xu, H., Zhu, Y., Xiao, P., et al. (2010) Use of ITS2 region as the universal DNA barcode for plants and animals. PLoS One 5, e13102.
- Yi, D. K., and Kim, K. J. (2012) Complete chloroplast genome sequences of important oilseed crop Sesamum indicum L. PLoS One 7, e35872.
- Zhang, Y., Du, L., Liu, A., Chen, J., Wu, L., Hu, W., Zhang, W., Kim, K., Lee, S. C., Yang, T. J., et al. (2016) The complete chloroplast genome sequences of five Epimedium species: lights into phylogenetic and taxonomic analyses. Front. Plant Sci. 7, doi:10.3389/fpls.2016.00306.
- Zhang, Y. J., Ma, P. F., and Li, D. Z. (2011) High-throughput sequencing of six bamboo chloroplast genomes: phylogenetic implications for temperate woody bamboos (Poaceae: Bambusoideae). PLoS One 6, e20596.
