Instrumentation, Control and System Engineering
Surface Defects Classification of Hot Rolled Strip Based on Few-shot Learning
2022 年 62 巻 6 号 p. 1222-1226
詳細
2022 年 62 巻 6 号 p. 1222-1226
Surface defect classification plays an important role in the assessment of production status and analyzing possible defect causes of hot rolled strip steel. It is extremely challenging owing to the rare occurrence and various appearances of defects. In this work, an improved deep learning model is proposed to solve the problem of poor classification accuracy when only a few labeled samples can be available. Different from most inductive small-sample learning methods, a transductive learning algorithm is designed where a new classifier is trained in the test phase and therefore can fit in with the needs of unknown samples. In addition, a simple feature fusion technique is implemented to extract more sample information. Based on a real-world steel surface defect dataset NEU, the proposed method can achieve a high classification accuracy of 97.13% with only one labeled sample. The experimental results show that the improved model is superior to other existing few-shot learning methods for surface defects classification of hot-rolled steel strip.
Surface defects of hot rolled strip affect not only its own quality, but also the physical and chemical properties of the end-products, such as corrosion resistance, oxidation resistance and wear resistance.1) The classification of their types of defects makes it possible to quickly and eliminate the causes of the damage occurrence. Obviously, effective and accurate identification of defects is the key to control product quality.2,3)
In recent years, deep learning-based models for the classification of surface defects of hot rolled strip achieved unprecedented success when a large number of labeled data can be available.4,5,6,7,8,9,10) For example, on a dataset with 1800 samples, Li et al. proposed a 7-layer convolutional neural network(CNN) for surface defect recognition where an accuracy of 99.05% can be achieved along with a speed of 0.001s for each image detection.5) Masci et al. introduced a maximum pooling CNN for surface defects detection of hot rolled strip, and obtained an accuracy of 98.57% with a recognition speed of 0.008s.6) For the same task, Wang et al. developed an improved CNN model with reduced training parameters, and improved the accuracy and speed of defect classification to 99.63% and 333 FPS, respectively.11) These previous works show that the deep learning-based models have strong generalization performance for the classification of surface defects of hot rolled strip if there are enough labeled samples can be available.
However, due to the rare occurrence and appearance variations of defects, it is usually a difficult task to collect and annotate a large number of defect images of hot-rolled steel strip in the actual production environment.1) Furthermore, the generalization of deep learning models might be seriously challenged when dealing with new defect classes if only a few labeled instances for each category. Therefore, in this work, a computational model based on few shot learning is proposed for surface defect images of hot rolled strip to address this problem.
The data used in this work come from surface defect dataset named NEU which was constructed by the Northeast University, China.5) There are six typical surface defects of hot rolled strip images, i.e., crazing (Cr), inclusion (In), scratch (Sc), rolled-in scale (Rs), patches (Pa) and pitted surface (Ps). Each type of defect contains 300 images and some of them are shown in Fig. 1. The original size of each image is 200×200. In order to reduce computational cost of the network, all the images are resized to 84×84 before it is sent to the network.

Six typical defect sample images in NEU database.
The standard deep learning model has strong generalization performance only when it is trained with a large number of labeled data. However, humans can learn new tasks rapidly from a handful of instances. Few shot learning therefore attempts to bridge this gap by simulating human learning paradigm. In the few-shot setting, a model is first trained on a base dataset
Different from the inductive few shot learning, which firstly learns the rules of the model from the training samples, and then uses the distance between query and support samples to judge the type of the query instances, this work adopts the transduction inference method for surface defect detection of hot-rolled strip steel.11,12) Specifically, in the training phase, a large number of labeled data are used as the input of the feature extractor fθ. Then fθ and linear classifier is trained in the same way as the standard deep learning method. After several rounds of optimization and iteration, the model has a wealth of prior knowledge. In the testing phase, S labeled and Q unlabeled samples are fed to the feature extractor fθ that has been trained in the training phase, and a new classifier, parametrized by weight matrix
The TIM loss is defined as:
| (1) |

The training and testing process of few shot learning. (Online version in color.)
Although various deep learning neural network structures have been developed for image recognition successfully, practical applications in industry have specific requirements where lightweight and/or easy-to-train model is needed. Wide residual networks (WRNs), a variant of deep network ResNet, is a product of this state.14,15) ResNet is one of the most classic and popular backbones in the field of deep learning whose multi-level network structure can continuously improve learning performance. However, each fraction of a percent of improved accuracy costs nearly doubling the number of layers, and therefore slows the training of network. To address this problem, WRNs reduces the depth of network and increases the feature output dimension to improve the performance of the model. To further speed up model training, this work uses a wide residual structure with 28 layers of depth and 10 times the output dimension, named WRN28-10, as the feature extractor. In the meantime, the dropout regularization strategy is used to avoid model over-fitting. The network structure of WRN28-10 is shown in the Fig. 3(a).
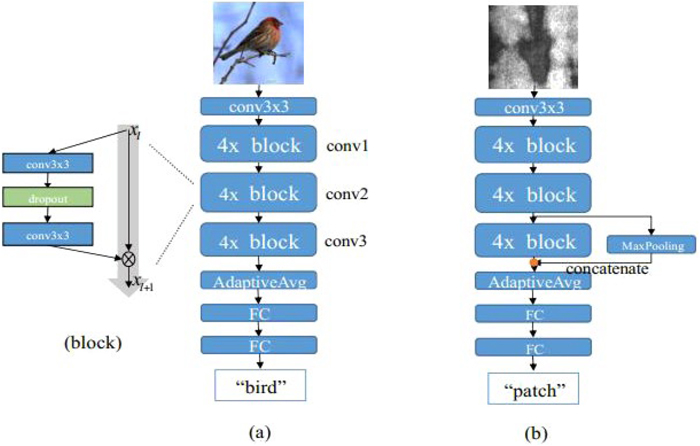
The structure of feature extractor in training and testing phase. Here, conv3x3 represents convolution layer with kernel size equal to 3, and 4x represents that the convolution layer is composed of four blocks. AdaptiveAvg and FC refers to adaptive average pooling and fully connection layer. (Online version in color.)
In the testing phase, the trained WRN28-10 is transfered to extract the features of new samples. In addition, by increasing the number of neurons in the penultimate fully connected layer of the model, the last two convolution blocks of the model are fused to make more comprehensive use of the information of the trained feature extractor. The specific fusion method is shown in Fig. 3(b). Herein, the features of the third convolutional layer named conv2 is down-sampled by maximum pooling, because it can reduce the image size without introducing parameters.
In this work, all of the experiments are implemented on a Tesla V100 GPU hardware platform. The batch size is set to 256, the initial learning rate is 0.1, and the decay of learning rate is 1e-3. The mini-ImageNet is used to be training dataset for the feature extraction. The mini-ImageNet is a subset of 100 classes selected from the ILSVRC-12 with 600 images in each class. It is divided into training, validation, and test meta-sets with 64, 16, and 20 classes respectively.16,17) The learning performance of the improved model is continuously trained and evaluated on the NEU data set. The evaluation experiments are repeated 600 times, and 15 query samples are included in each of them. The final prediction accuracy is the average of 600 experimental results.
4.1. Prediction Performance of Improved ModelIn order to classify steel surface defects by few shot learning method, the WRN28-10 model with feature fusion introduced in the testing phase has been proposed to expand the feature expression dimension of samples of unknown categories. When the support samples Ks for each new category are 1 shot and 5 shots, the confusion matrices of the prediction results are shown in Fig. 4.

Confusion matrices of the prediction results. (Online version in color.)
It can be seen from the Fig. 4 that there are 2 and 1 incorrect predictions of query samples when Ks equals 1 and 5, respectively, which indicates that the prediction accuracy of the model is 96.67% and 98.33%. More specifically, the improved model can achieve 100% of classification for four defects, i.e., inclusion, patches, pitted surface and scratch. When Ks = 5, the classification accuracy of rolled-in scale also reaches 100%. Obviously, the proposed model is effective in the defect image classification.
4.2. Classification Performance of Feature Fusion on Different BackbonesIn this work, feature fusion strategy is adopted in the improved model, and therefore the sample information used in this work is the combination of the output feature vectors of the last two convolution blocks of the model. To verify the effectiveness of feature fusion adopted in the proposed model in this work, the feature fusion technology is applied to different network backbones, including Conv4, lightweight MobileNet, residual network ResNet, dense connection network DenseNet and WRN28-10.14,15,17,18,19,20) The classification accuracy of strip surface defects obtained by different feature extractors is shown in Fig. 5.

Recognition accuracy of different backbones. (Online version in color.)
It can be seen that the feature fusion method proposed in this work can improve classification performance on different backbones, especially when there is only one support sample. It is interesting that the classification performance of the feature fusion decreases when the support sample is 5 for the Conv4 network backbone. The possible reason is that the advantage of expanding the sample expression dimension is lower than that of increasing the number of support samples. When the expanded dimension is large, the new classifier parameters cannot be fully trained, and therefore the robustness of the model will reduce.
4.3. Comparisons with Other State-of-the-art MethodsTo further evaluate the effectiveness of our improved model in the surface defects classification of hot rolled strip, several state-of-the-art few shot learning methods are compared with the support samples number is 1, 5, 10 and 15, respectively. Three inductive methods based on statistical rules, i.e., ProtoNet, CTM and SimpleShot, and another transduction-based method TIM are considered for comparison.11,12,13,20,21) The prediction accuracy of different models is shown in Table 1.
| Results Method | Accuracy (95% confidence interval) | |||
|---|---|---|---|---|
| 1-shot | 5-shot | 10-shot | 15-shot | |
| ProtoNet17) | 0.6798 | 0.8558 | 0.8896 | 0.8991 |
| (0.0061) | (0.0040) | (0.0032) | (0.0029) | |
| CTM6) | 0.7157 | 0.8602 | 0.8905 | 0.8978 |
| (0.0060) | (0.0036) | (0.0032) | (0.0031) | |
| SimpleShot7) | 0.8347 | 0.9441 | 0.9566 | 0.9584 |
| (0.0054) | (0.0024) | (0.0022) | (0.0020) | |
| TIM8) | 0.9652 | 0.9867 | 0.9901 | 0.9908 |
| (0.0031) | (0.0013) | (0.0010) | (0.0009) | |
| This work | 0.9713 | 0.9876 | 0.9912 | 0.9913 |
| (0.0028) | (0.0012) | (0.0009) | (0.0009) | |
It can be seen from the Table 1 that as the number of support samples increases, the classification accuracy and stability of all models generally improves, especially for the sample size from 1 to 5. When there is only one supporting sample, the classification accuracy of inductive learning methods is 67.98%, 71.57% and 83.47% respectively. In contrast, the transductive-based method achieves a better prediction accuracy of 96.52%. Compared with the TIM method, this work additionally introduces the feature of the penultimate convolution block in the test phase. As a result, the proposed model yields the best prediction results of 97.13% for 1 shot, 98.76% for 5 shots, 99.12% for 10 shots and 99.13% for 15 shots. The results demonstrated the effectiveness of the proposed method in the classification of hot-rolled steel strip surface defects. Moreover, in practical applications, to ensure the quality of the hot rolled strip, the classification accuracy of the algorithm for identifying strip surface defects is required to be more than 85%, and the higher the recognition accuracy is, the higher the qualification rate in production will be.22) Currently, the detection accuracy of the defect detection system applied in industrial field can reach 90%, while the accuracy of the strip defect classification method based on few-shot learning proposed in this work is 97.13% for 1 shot, which shows that our method can fully meet the actual accuracy requirements.
4.4. Classification Performance on the Aluminum Profile Defect DatasetTo further verify the classification performance of our proposed method, the model was also applied to the public aluminum profile surface defect dataset provided by the Tianchi big data platform. The dataset contains 11 defect types and one health category. In this work, only 6 defect categories and 1 health category are selected for the experiment to avoid the heavy image preprocessing work, such as removing irrelevant image background. Some preprocessed images and defect categories are shown in Fig. 6. With the same experimental setting as above, the comparison results between our model and TIM method without feature fusion are shown in Fig. 7. It can be found that when there are 1, 5, 10, and 15 support samples, the prediction accuracy of our model is 55.16%, 72.87%, 77.67%, and 79.03% respectively, which are higher than that of TIM method.

Surface defect image of aluminum profile. (Online version in color.)

Classification performance on the aluminum profile defect dataset. (Online version in color.)
Surface defect inspection is an important issue to ensure the quality of products. Due to the rare occurrence rate of defects, the surface defects classification of hot rolled strip often encounters the challenge of training with only a small number of defect samples. In this work, a deep learning method based on small samples is proposed to solve the problem of low classification accuracy of most defect detection methods. On the basis of transductive few shot learning and the improved model structure in the test stage, the classification accuracy of our model with only one labeled sample is 97.73%, which is higher than that of the current state-of-the-art methods. Moreover, the feature fusion method shows a great improvement in prediction accuracy on multiple feature extractors. These experimental results demonstrate that our proposed method of fusing model features in the test phase is effective, and therefore helpful to the steel industry.
This work was supported by the National Natural Science Foundation of China (Nos. 62172004, 62072002, and 61872004), Educational Commission of Anhui Province (No. KJ2019ZD05), Educational Commission of Anhui Province (No. KJ2019ZD05).