Invited Review
Targeted genome modifications in cereal crops
2021 Volume 71 Issue 4 Pages 405-416

Details
2021 Volume 71 Issue 4 Pages 405-416
The recent advent of customizable endonucleases has led to remarkable advances in genetic engineering, as these molecular scissors allow for the targeted introduction of mutations or even precisely predefined genetic modifications into virtually any genomic target site of choice. Thanks to its unprecedented precision, efficiency, and functional versatility, this technology, commonly referred to as genome editing, has become an effective force not only in basic research devoted to the elucidation of gene function, but also for knowledge-based improvement of crop traits. Among the different platforms currently available for site-directed genome modifications, RNA-guided clustered regularly interspaced short palindromic repeats (CRISPR)-associated (Cas) endonucleases have proven to be the most powerful. This review provides an application-oriented overview of the development of customizable endonucleases, current approaches to cereal crop breeding, and future opportunities in this field.
According to the United Nations, the world population is expected to rise by 2 billion and reach 9.8 billion by 2050, which will increase the demand for food by 60% and require gains in production yield (FAO et al. 2018). Due to climate change and soil degradation, arable land that would otherwise support the growth of crops is being lost, thereby greatly limiting the food production chain. Crop breeding is a critical avenue for coping with these global challenges by harnessing genetic resources, such as naturally occurring and artificially generated variants, to increase yield and plant resilience against abiotic stress, pathogens, and pests.
Throughout the history of human farming, crop domestication and the development of new crop varieties have relied on spontaneous mutations in existing cultivated germplasm that led to more productive farming and/or were associated with improved product utility. In addition to passive selection of emerging traits in one crop species, targeted crossbreeding also opened the door to combining useful traits from different germplasm. However, spontaneous mutation rates are low across the genome and rarely affect a gene with potential use for crop improvement. To accelerate the discovery of agronomically relevant genetic diversity, methods aimed at inducing random mutations have been developed. Crop plants have been subjected to ionizing radiation such as X-rays, gamma-rays, or heavy ion beams, as well as chemical mutagens like ethyl methanesulfonate or sodium azide (Ahloowalia and Maluszynski 2001). To date, many induced mutant lines have been generated and incorporated into several crop breeding programs. For example, the short-straw barley (Hordeum vulgare) cultivar ‘Diamant’ was produced via gamma-ray irradiation; the causal denso mutation has been since introgressed into over 100 cultivars grown worldwide (Ahloowalia et al. 2004). However, the desired mutations are accompanied by many additional mutations randomly distributed across the genome, some of which remain due to linkage. In addition, identification of the causal gene is typically challenging, even when using segregating populations and selecting for the phenotype of interest, as the candidate interval is likely to contain more than one mutation, only one of which is causal. These problems were partially alleviated by the development of the Targeted Induced Local Lesions in Genomes (TILLING) method, which allows for the identification of mutations in a given candidate gene by reverse genetics on pooled DNA from mutant populations (McCallum et al. 2000). Efficient selection methods based upon DNA marker-trait associations were also developed and broadly embraced in modern plant breeding (Rasheed et al. 2017). In addition, advanced sequencing technologies have become indispensable for providing comprehensive genome data in all crop species (Bayer et al. 2020). Taking advantage of these resources, several new methods have emerged that facilitate the rapid cloning of genes of interest, even in the context of cereals with comparatively large genomes such as mapping-by-sequencing using MutMap, mutant chromosome sequencing (MutChromSeq), mutagenesis with resistance gene sequence capture (MutRenSeq), targeted chromosome-based cloning via long-range assembly (TACCA), and association genetics with resistance gene enrichment sequencing (AgRenSeq) (Abe et al. 2012, Arora et al. 2019, Bettgenhaeuser and Krattinger 2019, Sánchez-Martín et al. 2016, Steuernagel et al. 2016, Thind et al. 2017).
The development of genetic transformation techniques based upon Agrobacterium (Agrobacterium tumefaciens)-mediated or direct delivery of recombinant DNA to totipotent plant cells has opened another chapter in crop breeding history (Kumlehn and Hensel 2009). This technology makes it possible to ectopically express, overexpress, or downregulate the expression of genes of interest to achieve desirable modifications of plant traits. In addition, the ability to easily introduce transgenes into most plant backgrounds has greatly facilitated basic plant research aimed at deciphering gene function (Kumlehn et al. 2019). The Flavr Savr tomato (Solanum lycopersicum), the first genetically engineered crop, was released for commercial use in 1994. Several other genetically engineered crops have since been developed. However, their commercial use is still largely confined to herbicide- and pest-resilient varieties due to public concern about the potential but unproven human risks associated with this technology, even though each new genetically engineered crop goes through a comprehensive and costly review process prior to approval.
More recently, emerging customizable endonucleases have begun to pave the way for the introduction of mutations or predefined sequence modifications at any genomic position, followed by the removal of transgenes by simple segregation in the progeny (Koeppel et al. 2019). This new technology, which is commonly referred to as genome editing, has already been implemented and demonstrated to work in most crop species. Customizable endonucleases hold great promise to greatly accelerate mutation breeding in crops, either via the precise introduction of previously known allelic states conferring desired traits into advanced breeding backgrounds or by the generation of novel genetic diversity at target genes. In this review, we introduce this novel technology to readers and provide examples of its applications in the major cereal crops rice (Oryza sativa), maize (Zea mays), wheat (Triticum aestivum), and barley. Finally, we discuss the potential of employing customizable endonucleases for future plant breeding programs.
To ensure the survival of organisms in the face of DNA damage, their constituent cells must repair DNA breaks efficiently, which mostly relies on any one of three major repair mechanisms that are equally relevant for site-directed genome modification methods (Kumlehn et al. 2018, Fig. 1). Non-homologous end-joining (NHEJ) repair is the predominant cellular repair mechanism for DNA double-strand breaks in plants. NHEJ involves the recognition and re-ligation of free DNA ends, which is error-prone and therefore leads to insertions and deletions of usually one or a few nucleotides. NHEJ repairs the majority of events induced during site-directed mutagenesis efforts, after the customized endonuclease has targeted and cleaved the intended site of modification, although the resulting modification itself is random. Other repair mechanisms rely on sequence homology and result in more predictable repair outcomes. Even small sequence repeats located on either side of the DNA break induced by the nuclease allow for their overlapping annealing, since opposite single strands of both DNA ends are complementary along these repeats; any remaining single-stranded DNA ends are degraded before the newly assembled double strand is cured by ligation. This mechanism of microhomology-mediated end-joining (MMEJ) repair is very common in plants and produces precise, predictable deletions of one of the repeat sequences and the sequence between them. Another virtually error-free basic mechanism of DNA repair is based on homologous recombination (HR) between one damaged DNA region and the corresponding and intact sequence of the sister chromatid or a homologous chromosome, resulting in longer stretches of identical sequences than in MMEJ. HR may be harnessed to introduce a foreign DNA fragment as long as it is flanked by regions with homology to the region surrounding the site of DNA cleavage. While HR is essential for meiosis, the underlying enzymes are comparatively rarely active in somatic plant cells. In addition, the sister chromatids that are predominantly recruited as native repair templates are exclusively present in the G2 phase of the cell cycle. These limitations contribute to the current difficulties in implementing HR in plant genetic engineering and for precise genome editing in crop plants.
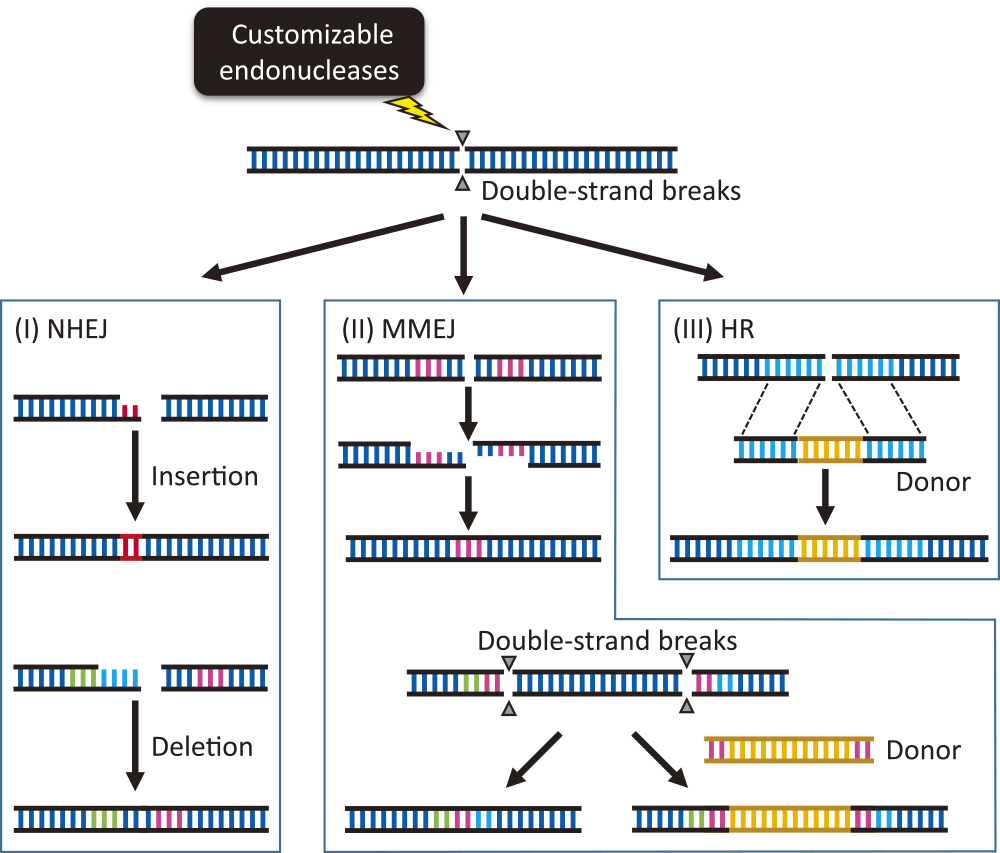
Diagram summarizing the various ways in which customizable endonucleases can be used to introduce modifications into target genes. Customizable endonucleases trigger double-strand breaks in selected target sites of the plant genome. The DNA is then repaired via one of three major mechanisms, resulting in modifications at the target site: I, non-homologous end-joining (NHEJ) repair; II, microhomology-mediated end-joining (MMEJ) repair; and III, homologous recombination (HR). These mechanisms result in possible insertions, deletions, and/or substitutions of individual or multiple nucleotides. The size of the insertion or deletion is random following NHEJ-mediated DNA repair, whereas MMEJ and HR lead to predictable modifications and can thus be utilized for precise genome editing.
Site-directed genome modification is initiated by the cleavage of a given target sequence in genomic DNA by customizable endonucleases. Several effective endonucleases are available: meganucleases, zinc-finger nucleases (ZFNs), transcription activator-like effector nucleases (TALENs), and clustered regularly interspaced short palindromic repeats (CRISPR)-associated (Cas) endonucleases. Meganucleases, such as I-SceI, I-CreI, and I-DmoI, include a transit peptide for nuclear localization, a site-specific double-stranded DNA-binding domain of 12 to 40 nucleotides, and an endonuclease domain to cleave DNA. Although meganucleases have high target sequence specificity, the small number of DNA-binding sequences identified makes it difficult to design a derivative that targets other sequences of interest, unlike ZFNs, TALENs, or Cas endonucleases (see below). These nucleases are typically deployed in plant cells by introducing a transgene including a promoter that drives their expression and is recognized by RNA polymerase II, such as the cauliflower mosaic virus (CaMV) 35S or UBIQUITIN promoters. ZFNs and TALENs are chimeric proteins composed of a DNA-binding domain fused to a nuclease domain derived from the restriction enzyme FokI. The DNA-binding domain of ZFNs is composed of three to six zinc-finger modules derived from DNA-binding transcription factors. Each zinc-finger module specifically recognizes a unique nucleotide triplet. By contrast, the DNA-binding domain of TALENs consists of approximately 20 modules of four basic types, each with specificity to one of the four nucleobases A, C, G, or T (Gurushidze et al. 2014). This DNA-binding principle was adapted for biotechnological use from transcription activator-like effectors produced and delivered by plant pathogenic bacteria to bind to specific host genomic sequences to manipulate gene expression in infected cells. Due to differences in the architecture of the modules, the design and construction of TALENs is more straightforward compared to ZFNs (Budhagatapalli et al. 2016, Hensel and Kumlehn 2019). Since FokI only cleaves DNA as a dimer, two versions of ZFNs or TALENs are typically expressed, with each monomer binding to a DNA sequence on either side of the intended cleavage site and separated by an appropriate distance to direct endonucleolytic cleavage.
Cas endonucleases were originally discovered as components of microbial CRISPR-Cas immune systems. SpCas9 isolated from the bacterium Streptococcus pyogenes is currently the most widely used Cas endonuclease for biotechnological purposes due to its high cleavage efficiency within a physiologically relevant range of temperatures in a variety of hosts. The deployment of Cas endonucleases in microbial cells relies on a single-stranded guide RNA (gRNA) derived from the same native immune system that targets a DNA sequence that is recognized as foreign and must therefore be eliminated. The gRNA can be customized to target any sequence of interest for Cas-dependent cleavage. In most SpCas9 applications, the gRNA is a single-stranded chimeric RNA harboring two parts whose native predecessors were independent molecules: the CRISPR RNA (crRNA), which includes ~20 bp of customizable sequence that binds to the DNA target motif via complementary base-pairing, and trans-activating CRISPR RNA (tracrRNA) scaffold, which binds to the Cas endonuclease. In general, polymerase II-type promoters are used to drive the expression of the genes encoding Cas endonucleases, while polymerase III-type promoters from small non-coding RNAs are mainly used to express gRNAs. A Cas endonuclease target motif is not confined to the sequence bound by the gRNA 5ʹ end via complementary base-pairing, as it must also include a short binding site for the Cas endonuclease. In the case of SpCas9, this so-called protospacer-adjacent motif (PAM) consists of two guanine nucleobases preceded by any nucleobase (i.e., NGG). This general pattern must therefore be given some thought when searching for appropriate Cas endonuclease target motifs within the host genome. Several powerful online platforms are now available that greatly facilitate the identification of target sequences within genes of interest based on experimental considerations such as the Cas endonuclease variant and the host species used (e.g., WU-CRISPR, http://crisprdb.org/wu-crispr/; CRISPR-P 2.0, http://crispr.hzau.edu.cn/CRISPR2; CRISPOR, http://crispor.tefor.net; and CRISPR Guide RNA Design, https://www.benchling.com/crispr).
Among cereal crops, three types of nucleases mentioned above (meganucleases, ZFNs, and TALENs) were used to generate targeted genome modifications prior to the advent of Cas endonucleases. The first example of targeted genome modification using customizable endonucleases was by D’Halluin et al. (2008), who succeeded in inserting the 35S promoter upstream of a promoterless herbicide resistance transgene using a meganuclease in maize. The following year, Shukla et al. (2009) reported the first use of ZFNs for site-directed mutagenesis at the maize INOSITOL-1,3,4,5,6-PENTAKISPHOSPHATE 2-KINASE 1 (IPK1) gene as well as site-directed DNA insertion of a PHOSPHINOTHRICIN ACETYLTRANSFERASE (PAT) gene at the same locus. For TALENs, Li et al. (2012) were the first to successfully modify the promoter sequence of the bacterial leaf blight susceptibility gene SUGARS WILL EVENTUALLY BE EXPORTED TRANSPORTER 14 (OsSWEET14) in rice.
Cas9 endonuclease-based targeted genome modification was first achieved in rice and wheat by Shan et al. (2013), Miao et al. (2013), and Feng et al. (2013), who used SpCas9 to target genes associated with chlorophyll biosynthesis and thus with easily scorable phenotypes: PHYTOENE DESATURASE (PDS), CHLOROPHYLL A OXYGENASE 1 (CAO1), and YOUNG SEEDLING ALBINO (YSA).
Besides SpCas9, endonucleases derived from other CRISPR systems have also been co-opted for targeted genome modification. For example, Endo et al. (2016), Tang et al. (2017b), and Yin et al. (2017) induced mutations by expressing the Cas12a (CRISPR from Prevotella and Francisella 1 or Cpf1) endonuclease in rice. In contrast to Cas9, Cas12a functions with a native single crRNA. Like several other types of Cas endonucleases, Cas12a broadened the choice of possible target sequences because it requires a T-rich PAM (5ʹ-(T)TTV-3ʹ) that resides upstream of the nucleotides bound by the gRNA. Unlike Cas9, Cas12a results in staggered cleavage of the target sequence.
A single nucleotide substitution method called base editing has also been developed. Base editing relies on Cas derivatives (so-called nickases) that cleave only one of the two DNA strands, after which a fused cytidine deaminase or adenosine deaminase domain converts a single nucleobase. For example, Li et al. (2018) expressed a Cas9-adenosine deaminase fusion in rice and wheat and introduced T/A to C/G conversions in target genes.
More recently, another approach for precise genome modifications called prime editing was developed, based upon chimeric fusion proteins between a Cas9 nickase and a reverse transcriptase. Such proteins are coupled with gRNAs carrying a 3ʹ extension that acts as a primer to specify the replacement of particular nucleobases within the target sequence (Anzalone et al. 2019). This method was successfully implemented in rice and wheat among other plants (Hua et al. 2020, Lin et al. 2020).
Highly versatile, precise genome editing can be achieved using homology-based approaches in which customizable nucleases are used along with a repair template that carries DNA fragments with homology to the target region while also harboring the desired modified sequence to be incorporated at the genomic target site (Fig. 1). Proof-of-concept studies demonstrated precise genome editing using meganucleases and TALENs in barley, although these initial examples were confined to the modification of previously inserted transgenes (Budhagatapalli et al. 2015, Watanabe et al. 2015). Begemann et al. (2017) subsequently used the Cas12a endonuclease to perform site-directed DNA insertions in rice, while Gil-Humanes et al. (2017) developed a site-directed DNA insertion method using the replication system of wheat dwarf virus combined with the Cas9 endonuclease, which resulted in increased frequency of knock-in of foreign DNA at a genomic target region in wheat.
Another novel approach that also largely alleviates the need for stable transformation of the host species was reported by Budhagatapalli et al. (2020), who pollinated wheat plants with pollen from Cas9-gRNA-transgenic maize plants, resulting in haploid wheat plants that could be subjected to whole-genome duplication to produce a homozygous mutant and transgene-free wheat. This method was demonstrated using a panel of five diverse genotypes including durum wheat (Triticum durum) and common wheat.
Targeted genome modifications may not require the introduction of a transgene at all, relying instead on preassembled Cas9 or Cas12a nuclease protein-gRNA ribonucleoprotein complexes (Kim et al. 2017, Toda et al. 2019, Woo et al. 2015). Toda et al. (2019) introduced Cas9-gRNA ribonucleoproteins into totipotent rice zygotes to generate plants carrying mutant alleles at GRAIN WIDTH 7 (GW7), DROOPING LEAF (DL), and PSEUDO-RESPONSE REGULATOR 37 (PRR37). Likewise, Zhang et al. (2016) introduced in vitro-transcribed transcripts for Cas9 and the gRNA into common wheat by accelerated microparticles and obtained primary mutants. Subsequently, Liang et al. (2017) successfully performed targeted genome modification of GW2 in common wheat using Cas9-gRNA ribonucleoproteins.
Rice is one of the most important cereal crops worldwide, particularly in Asian countries, where it is consumed as a staple food. The rice genome is smaller than those of other cereal crops and was the first cereal genome to be sequenced. Rice plants are also easier to transform than other members of the Poaceae family, explaining why it has long been used as a model system for monocot plants. In recent years, rice has also been used as an experimental platform to test and implement novel targeted genome modification tools. Such tools have been used to modify genes related to high yield and production stability in ways that would not have been possible via conventional breeding. In this section, we describe how genome modification tools have been used to modify genes of high agronomic importance in rice.
Table 1 lists several examples of targeted genome modification for agronomically important traits in cereal crops. In two pioneering studies, Li et al. (2012) and Zhou et al. (2015) used TALENs and Cas9 endonuclease to modify the promoter regions of the bacterial leaf blight susceptibility genes SWEET14 and SWEET13, respectively. The resulting mutant plants showed increased resistance to Xanthomonas oryzae pv. oryzae, the pathogen that causes bacterial leaf blight in rice. Following these reports, Oliva et al. (2019), Xu et al. (2019), and Blanvillain-Baufumé et al. (2017) also created mutants that are highly resistant to the same pathogen by targeting the promoter regions of SWEET11, in addition to SWEET13 and SWEET14. In another study, Wang et al. (2016) used Cas9 nuclease to modify ETHYLENE RESPONSIVE TRANSCRIPTION FACTOR 922 (OsERF922), thereby increasing resistance to rice blast caused by Magnaporthe oryzae, one of the most destructive plant diseases worldwide. The authors further showed that the induced mutations were inherited by the progeny. Compared to wild-type plants, mutant lines exhibited much smaller blast lesions at both the seedling and tillering stages. Nawaz et al. (2020a) also successfully improved resistance to rice blast by modifying another gene, PYRICULARIA ORYZAE RESISTANCE 21 (PI21). Other examples of mutants generated via site-directed genome modification for higher tolerance to biotic stress were reported by Kim et al. (2019) and Li et al. (2020a) for bacterial blight resistance and by Macovei et al. (2018) for virus resistance.
| Plant | Modified gene | Purpose | Nuclease | DNA repair by |
Reference |
|---|---|---|---|---|---|
| rice | ACC | Herbicide resistance | Cas9 nuclease | NHEJ | Liu et al. (2020) |
| ALS | Herbicide resistance | TALENs, Cas9 nuclease |
HDR/TSI | Li et al. (2016c), Sun et al. (2016) | |
| BADH2 | Fragrant rice | TALENs, Cas9 nuclease |
NHEJ | Shan et al. (2015), Ashokkumar et al. (2020) | |
| CRTI and PSY | Carotenoid accumulation | Cas9 nuclease | HDR/TSI | Dong et al. (2020) | |
| CSA | Male sterility | Cas9 nuclease | NHEJ | Li et al. (2016b) | |
| DEP1 | Grain yield | Cas9 nuclease | NHEJ | Huang et al. (2018) | |
| ELF4G | Virus resistance | Cas9 nuclease | NHEJ | Macovei et al. (2018) | |
| EPSPS | Herbicide resistance | Cas9 nuclease | NHEJ/TSI | Li et al. (2016a) | |
| ERF922 | Blast disease resistance | Cas9 nuclease | NHEJ | Wang et al. (2016) | |
| GA20OX2 | Plant height | Cas9 nuclease | NHEJ | Nawaz et al. (2020b) | |
| GN1a | Grain yield | Cas9 nuclease | NHEJ | Huang et al. (2018) | |
| GS3 | Grain yield | Cas9 nuclease | NHEJ | Zeng et al. (2020b) | |
| GW2 | Grain yield | Cas9 nuclease | NHEJ | Xu et al. (2016) | |
| GW5 | Grain yield | Cas9 nuclease | NHEJ | Xu et al. (2016) | |
| LCT1 | Cadmium accumulation | Cas9 nuclease | NHEJ | Liu et al. (2019) | |
| LOX3 | Storage tolerance | TALENs | NHEJ | Ma et al. (2015) | |
| MTL (PLA1) | Haploid production | Cas9 nuclease | NHEJ | Yao et al. (2018) | |
| MYB30 | Cold tolerance | Cas9 nuclease | NHEJ | Zeng et al. (2020b) | |
| NRAMP5 | Cadmium accumulation | Cas9 nuclease | NHEJ | Tang et al. (2017a), Liu et al. (2019), Yang et al. (2019) | |
| PI21 | Blast disease resistance | Cas9 nuclease | NHEJ | Nawaz et al. (2020a) | |
| PIN5b | Grain yield | Cas9 nuclease | NHEJ | Zeng et al. (2020b) | |
| RC | Proanthocyanidin and anthocyanin accumulation | Cas9 nuclease | NHEJ | Zhu et al. (2019) | |
| RR22 | Salinity tolerance | Cas9 nuclease | NHEJ | Zhang et al. (2019) | |
| SBEIIb | Starch composition | Cas9 nuclease | NHEJ | Sun et al. (2017) | |
| SD1 | Plant height | Cas9 nuclease | NHEJ | Hu et al. (2019), Biswas et al. (2020) | |
| SE5 | Plant height | Cas9 nuclease | NHEJ | Hu et al. (2019) | |
| SWEET11 | Bacterial leaf blight resistance | Cas9 nuclease | NHEJ | Oliva et al. (2019), Xu et al. (2019) | |
| SWEET13 | Bacterial leaf blight resistance | Cas9 nuclease | NHEJ | Zhou et al. (2015), Oliva et al. (2019), Xu et al. (2019) | |
| SWEET14 | Bacterial leaf blight resistance | TALENs, Cas9 nuclease |
NHEJ | Li et al. (2012), Blanvillain-Baufumé et al. (2017), Oliva et al. (2019), Xu et al. (2019) | |
| TGW6 | Grain size | Cas9 nuclease | NHEJ | Xu et al. (2016), Han et al. (2018) | |
| TMS5 | Male sterility | Cas9 nuclease | NHEJ | Zhou et al. (2016) | |
| VP1 | Germination speed | Cas9 nuclease | NHEJ | Jung et al. (2019) | |
| WAXY | Starch composition | Cas9 nuclease | NHEJ | Han et al. (2018), Zhang et al. (2018a), Huang et al. (2020), Zeng et al. (2020a) | |
| XA13 | Bacterial blight resistance | Cas9 nuclease | NHEJ | Kim et al. (2019), Li et al. (2020a) | |
| wheat | α-GLIADINS | Low gluten | Cas9 nuclease | NHEJ | Sánchez-León et al. (2018) |
| CM3 | Low α-amylase/trypsin inhibitor (allergenic proteins) | Cas9 nuclease | NHEJ | Camerlengo et al. (2020) | |
| CM16 | Low α-amylase/trypsin inhibitor (allergenic proteins) | Cas9 nuclease | NHEJ | Camerlengo et al. (2020) | |
| EDR1 | Powdery mildew disease resistance | Cas9 nuclease | NHEJ | Zhang et al. (2017) | |
| GW2 | Grain size | Cas9 nuclease | NHEJ | Zhang et al. (2018b), Wang et al. (2018a, 2018b) | |
| HRC | Fusarium head blight disease resistance | Cas9 nuclease | NHEJ | Su et al. (2019) | |
| MLO | Powdery mildew disease resistance | TALENs | NHEJ | Wang et al. (2014) | |
| MS1 | Male sterility | Cas9 nuclease | NHEJ | Okada et al. (2019) | |
| MS45 | Male sterility | Cas9 nuclease | NHEJ | Singh et al. (2018) | |
| NP1 | Male sterility | Cas9 nuclease | NHEJ | Li et al. (2020b) | |
| NFXL1 | Fusarium head blight disease resistance | Cas9 nuclease | NHEJ | Brauer et al. (2020) | |
| QSD1 | Grain dormancy | Cas9 nuclease | NHEJ | Abe et al. (2019), Liu et al. (2021) | |
| SBEIIb | Starch composition | Cas9 nuclease | NHEJ | Li et al. (2021) | |
| SD1 | Plant height | Cas9 nuclease | NHEJ | Budhagatapalli et al. (2020) | |
| barley | β-1,3-GLUCANASE | Increased callose formation | Cas9 nuclease | NHEJ | Kim et al. (2020) |
| MORC | Fungal resistance | Cas9 nuclease | NHEJ | Kumar et al. (2018) | |
| NUD | Non-adherent hull | Cas9 nuclease | NHEJ | Gasparis et al. (2018), Gerasimova et al. (2020) | |
| maize | AAD1 | Herbicide resistance | ZFNs | HDR/TSI | Ainley et al. (2013) |
| ARGOS8 | Drought stress tolerance | Cas9 nuclease | HDR/TSI | Shi et al. (2017) | |
| GA20OX3 | Plant height | Cas9 nuclease | NHEJ | Zhang et al. (2020) | |
| IPK1 | Phytate accumulation in grain | ZFNs | NHEJ | Shukla et al. (2009) | |
| LOX3 | Resistance to fungal infection | Cas9 nuclease | NHEJ | Pathi et al. (2020) | |
| MS45 | Male fertility | Cas9 nuclease | NHEJ | Svitashev et al. (2016) | |
| MTL (PLA1) | Haploid production | Cas9 nuclease | NHEJ | Kelliher et al. (2017) | |
| PAT | Herbicide resistance | ZFNs | HDR/TSI | Shukla et al. (2009), Ainley et al. (2013) |
NHEJ; non-homologous end-joining, HDR; homology-directed repair, TSI; targeted sequence insertion.
In concerted efforts to improve grain yield, quality, and composition in rice, Tang et al. (2017a), Liu et al. (2019), and Yang et al. (2019) modified NATURAL RESISTANCE-ASSOCIATED MACROPHAGE PROTEIN 5 (NRAMP5) and LOW-AFFINITY CATION TRANSPORTER 1 (LCT1) using Cas9 nuclease to reduce cadmium accumulation, which causes Itai-itai disease. The resulting mutant grains accumulated less cadmium compared to the wild-type, thereby contributing to a safer food supply. Sun et al. (2017) modified STARCH BRANCHING ENZYME IIb (SBEIIb) using Cas9, which produced genome-edited plants whose grains had high resistant starch content. Likewise, Han et al. (2018), Zhang et al. (2018a), Huang et al. (2020), and Zeng et al. (2020a) targeted the WAXY gene, resulting in edited grains with modified starch composition and altered amylose/amylopectin contents. Shan et al. (2015) and Ashokkumar et al. (2020) used TALENs and Cas9 nuclease, respectively, to generate fragrant mutants producing 2-acetyl-1-pyrroline, the aroma compound that gives jasmine and basmati rice their flavor, via site-directed mutagenesis of BETAINE ALDEHYDE DEHYDROGENASE 2 (BADH2). Xu et al. (2016) obtained mutants with larger grains by simultaneously targeting GW2, GW5, and THOUSAND-GRAIN WEIGHT 6 (TGW6) by Cas9 nuclease-mediated multiplex targeted mutagenesis. Ma et al. (2015) improved seed longevity via TALEN-mediated inactivation of LIPOXYGENASE 3 (LOX3). Zhang et al. (2019) and Zeng et al. (2020b) focused on improving tolerance to high-salinity and low-temperature stress, which are of particular relevance in rice, and obtained tolerant mutants by Cas9-mediated genome modification of RESPONSE REGULATOR 22 (RR22) and MYB30, respectively.
The precise modification of ACETOLACTATE SYNTHASE (ALS) and 5-ENOL-PYRUVYL SHIKIMATE-3-PHOSPHATE SYNTHASE (EPSP) using TALENs or Cas9 nuclease resulted in herbicide-resistant rice plants (Li et al. 2016a, 2016c, Sun et al. 2016). In another Cas9-based approach, Dong et al. (2020) inserted an expression cassette of two carotenoid biosynthetic genes, CAROTENE DESATURASE I (CTRI) and PHYTOENE SYNTHASE (PSY), at a predefined target site without the use of a selectable marker. The resulting plants produced carotenoid-enriched rice that accumulates β-carotene in the grains, which may help overcome vitamin A deficiency in the developing world.
Studies involving targeted genome modification have also contributed to a revolution in crop breeding by focusing on genes that do not directly affect agronomic traits. For instance, Zhou et al. (2016) targeted THERMOSENSITIVE 5 (TMS5), a gene involved in thermosensitive genic male sterility, by Cas9 nuclease-mediated mutagenesis and successfully produced male-sterile mutants. Li et al. (2016b) also modified CARBON STARVED ANTHER (CSA), which is involved in photosensitive genic male sterility. These studies have accelerated the expansion of genetic resources for male sterility and the development of a hybrid breeding system in rice. To produce haploid rice, Yao et al. (2018) performed Cas9-mediated modification of the rice ortholog of maize PHOSPHOLIPASE A1 (PLA1, also called MATRILINEAL [MTL] and NOT LIKE DAD [NLD]), which encodes a pollen-specific phospholipase whose inactivation stimulates the development of the unfertilized egg into a haploid embryo. The authors succeeded in producing haploid mutants, which represents another essential tool for modern plant breeding.
Wheat is a major staple food crop in nearly every region of the world. Durum wheat (Triticum durum) and common wheat (T. aestivum) are allopolyploid crops with two and three subgenomes (AB and ABD), respectively. Since these wheats have multiple copies of each gene, conventional mutagenesis affecting any one gene in one subgenome may not result in a phenotypic change due to functional redundancy with the remaining homoeologs from the other subgenome(s). Thus, the most promising method for targeted genome modification of durum and common wheat may be the introduction of mutations in all homoeologs simultaneously or successively. In temperate areas with a rainy season around wheat harvest time, such as Japan, preharvest sprouting and Fusarium head blight disease are major problems. However, genetic resources for tolerance or resistance are limited, making it imperative to develop and deploy breeding techniques that allow for the generation of novel useful genetic variation. In this section, we review agronomically relevant examples of targeted genome modification in wheat.
In common wheat, the cultivars ‘Bobwhite’ and ‘Fielder’ have mainly been used for targeted mutagenesis due to their outstanding transformation efficiency. However, the method of Budhagatapalli et al. (2020) holds great promise to expand the scope of wheat genome editing to other more recalcitrant cultivars.
In an early study of targeted mutagenesis in common wheat, Wang et al. (2014) successfully addressed all three homoeoalleles of POWDERY-MILDEW-RESISTANCE LOCUS O (MLO), a susceptibility factor for powdery mildew disease. Using TALENs, the authors generated single, double, and triple homozygous mutants. Only the triple mutant (aabbdd) displayed resistance to infection by Blumeria graminis f. sp. tritici, whereas all single and double knockout lines remained susceptible. This study demonstrates the power of customizable endonucleases when knockouts in all homoeoalleles of a given target gene must be generated in polyploid species. Zhang et al. (2017) focused on the modification of ENHANCED DISEASE RESISTANCE 1 (EDR1) using Cas9 nuclease to increase resistance to powdery mildew in triple homozygous wheat mutants as well. Moreover, Zhang et al. (2018b) and Wang et al. (2018a, 2018b) performed targeted genome modification of wheat GW2, whose rice ortholog is negatively associated with grain width and thousand-grain weight. In these studies, the wheat cultivars ‘Kenong 199’ and ‘Bobwhite’ were used as starting germplasm, and the inactivation of genes from the B and D subgenomes had more significant phenotypic effects on grain size than their respective single knockout mutants. Sánchez-León et al. (2018) and Camerlengo et al. (2020) produced common wheat and durum wheat with grains that accumulated substantially reduced levels of allergenic constituents by Cas9 endonuclease-mediated targeting of the gene families encoding α-GLIADINs and subunits of α-AMYLASE/TRYPSIN INHIBITOR (CHLOROFORM/METHANOL 3 [CM3] and CM16), respectively. The immunoreactivity of the resulting wheat mutants was significantly reduced, as demonstrated by enzyme-linked immunosorbent assay (ELISA) in both studies. These approaches may therefore greatly contribute to the mitigation of celiac disease in the human population. Abe et al. (2019) succeeded in the site-directed mutagenesis of the wheat gene QTL FOR SEED DORMANCY 1 (QSD1), affecting grain dormancy and resistance to pre-harvest sprouting. The triple mutant (aabbdd) germinated much later than the wild-type counterpart and thus exhibited higher dormancy levels, whereas single and double mutants germinated at similar times to the wild-type. Not all successful attempts at targeted genome modification require the inactivation of all homoeologs, however. Su et al. (2019) identified HISTIDINE-RICH CALCIUM-BINDING PROTEIN (TaHRC) as a quantitative trait locus (QTL) responsible for resistance to Fusarium head blight. The cloning of the causal gene identified a single deletion in the B subgenome copy that was sufficient to cause resistance to Fusarium head blight. This result was validated by independent site-directed mutagenesis of the TaHRC homoeolog from the B subgenome. In an alternative approach using the cultivar ‘Fielder’, Brauer et al. (2020) generated knockout mutants of NUCLEAR TRANSCRIPTION FACTOR, X-BOX BINDING 1-LIKE (NFXL1) and obtained resistance to Fusarium head blight. Okada et al. (2019), Singh et al. (2018) and Li et al. (2020b) generated male-sterile wheat mutants by targeting MALE STERILITY 1 (MS1), MS45, and NO POLLEN 1 (NP1). These studies lead to the production of male-sterile mutants, which are needed for a hybrid seed production system in wheat.
Budhagatapalli et al. (2020) generated doubled haploid wheat with mutations targeting SEMI-DWARF 1 (SD1). Such mutations were obtained in various genotypes, including common and durum wheat, using Cas9/gRNA-transgenic maize as the pollen donor to induce the formation of haploids. Mutant progenies had reduced plant height compared to the wild-type.
Barley is a self-pollinating diploid crop that has long been used as a research model representative of the Triticeae species. Since barley is used as a food for animals and humans and for malting, breeding efforts have focused on yield- and quality-related traits, including resistance to fungal and viral pathogens, tolerance to preharvest sprouting, starch grain content, beta-glucan content, protein content, and brewing suitability. Like wheat, only a limited number of barley genotypes are amenable to efficient genetic transformation, with the cultivars ‘Golden Promise’ and ‘Igri’ being particularly suitable (Hoffie et al. 2021, Kumlehn et al. 2006).
Targeted genome modification via Cas9 endonuclease to target genes of interest for basic research and agronomically relevant traits was recently reported in barley. For example, Kumar et al. (2018) explored the function of the MICRORCHIDIA PROTEIN (MORC) gene in barley and demonstrated its effect on enhancing resistance to viral diseases. Gasparis et al. (2018) and Gerasimova et al. (2020) used the Cas9 endonuclease to perform site-directed mutagenesis of the ERF family gene known as naked caryopsis gene, NUDUM (NUD), which is responsible for the particularly strong adherence of hulls to the pericarp of barley grains. Knockout of this gene resulted in the conversion of hulled barley into barley with naked grains, the form used for human consumption.
Maize, the cereal crop with the greatest production worldwide, is primarily grown in North and South America and is commonly used for livestock feed and as an ingredient in processed foods such as oil and cornstarch. Genetically engineered maize, represented by herbicide-resistant and Bt (Bacillus thuringiensis) corn, has long been cultivated in several countries. It is hoped that new varieties exhibiting both herbicide resistance and a waxy grain phenotype generated by targeted genome modification will be released in the near future (Waltz 2016). However, like wheat and barley, only a few maize germplasms are suitable for genetic transformation. In particular, high type II (Hi-II) hybrids have mainly been used for genetic engineering in the past due to their very high transformation efficiency.
As mentioned above, Shukla et al. (2009) succeeded in performing site-directed mutagenesis of the IPK1 gene as well as site-specific DNA insertion into the PAT gene in maize using ZFNs. A few years later, Ainley et al. (2013) performed homology-mediated DNA insertion of two herbicide-resistance genes in maize encoding ARYLOXYALKANOATE DIOXYGENASE 1 (AAD1) and ALS using ZFNs and Cas9 endonuclease, respectively. Shi et al. (2017) improved grain yield in maize plants exposed to drought stress via Cas9-mediated insertion of the GOS2 promoter onto the upstream region of AUXIN-REGULATED GENE INVOLVED IN ORGAN SIZE 8 (ARGOS8), thereby upregulating its expression. Pathi et al. (2020) performed site-directed genome modification using the Cas9 nuclease at LOX3, a susceptibility factor for smut disease in maize, resulting in moderately resistant plants to Ustilago maydis infection.
To develop haploid technology in maize, Kelliher et al. (2017) used Cas9 nuclease to introduce knockout mutations at PLA1/MTL/NLD, which encodes a pollen-specific phospholipase required for regular fertilization. These mutants generated haploid plants at efficiencies suitable for the development of maize inbred lines. Using preassembled Cas9/gRNA ribonucleoproteins for site-directed mutagenesis, Svitashev et al. (2016) successfully generated male-sterile alleles at MS2 and MS45, holding great promise for the development of a reliable method for hybrid breeding.
Crop breeding has traditionally involved the identification of desirable genetic variants, followed by their incorporation into other germplasm by repeated crosses. To increase the frequency of genetic diversity, plant materials have been exposed to mutagenic chemicals or ionizing radiation. Using these methods, mutations are randomly introduced into the genome. Consequently, very large plant populations had to be phenotyped, processed, and analyzed to identify and validate mutations with potential agronomic value. The major advantages of targeted genome modification are that 1) virtually any target gene may be modified and 2) downstream analyses can be substantially accelerated. Another feature of targeted genome modification using customizable endonucleases is that multiple target genes of interest can be modified simultaneously, which is particularly important for polyploid species or to improve traits that require complex genetic modifications.
However, to fully realize the potential of targeted genome modification, elite germplasms must be amenable to modification, as backcrossing procedures unnecessarily prolong the production of breeding lines until a suitable genetic background is ready for approval and release. Various attempts have been made to overcome the challenge of genotype dependence for genetic engineering. For example, Yeo et al. (2014), Hisano and Sato (2016), and Hisano et al. (2017) attempted to identify genes involved in the transformation amenability of barley. Once these genes are identified, any elite background may become transformable. Using another approach to reduce genotype dependence, Hamada et al. (2017, 2018) and Liu et al. (2021) developed a new method of in planta transformation and targeted genome modification in wheat including commercial varieties, which relies on ballistic DNA transfer to the shoot apex of mature embryos and may allow for the genetic engineering of a wide range of germplasm.
In another approach, Kelliher et al. (2019) and Budhagatapalli et al. (2020) used Cas9/gRNA-transgenic haploidy-inducing lines as pollen donors to induce targeted mutagenesis during early embryogenesis in maize and wheat, respectively. In the case of wheat, this method was effective in accessions typically recalcitrant to transformation. A similar technique for barley using pollen of wild barley (Hordeum bulbosum), the so-called bulbosum method may be employed to create doubled haploid barley carrying targeted genome modifications using any desired elite background (Satpathy et al. 2021).
Mutagenesis has advanced from the era of large-scale screening of random mutant populations to the production of desirable mutants by precisely targeting known genomic sequences. The use of customizable endonucleases has accelerated the generation of knock-in/out gene variants and thus is poised to revolutionize the breeding of field crops. In this review, we provided comprehensive information on generating targeted genome modifications with agronomic relevance for cereal crops. This technology has been steadily progressing and will increasingly contribute to crop breeding in the future. It remains necessary, however, to further increase the efficiency and precision of genome modifications to help usher in the new age of customizable crops.
HH and JK wrote the draft of the manuscript. All authors revised the manuscript and approved of its submission to Breeding Science.
HH and JK were supported by the Joint Usage/Research Center, Institute of Plant Science and Resources, Okayama University (FY2017). HH and FA were supported by the Cabinet Office, Government of Japan, Cross-ministerial Strategic Innovation Promotion Program (SIP), “Technologies for Creating Next-generation Agriculture, Forestry and Fisheries” (funding agency: Bio-oriented Technology Research Advancement Institution, NARO). RH is grateful to the German Ministry of Research and Education (BMBF) for financial support in the context of the IDEMODERESBAR project (FKZ 031B0199C and 031B0887C). HH is supported by JSPS KAKENHI Grant-in-Aid for Scientific Research (B) (Grant Number JP19H02930).