Abstract
Detection of subway tunnel distress is a crucial task for ensuring public safety. It is typically performed manually by technical workers, which has become increasingly expensive due to the decline in working-age population and increase in aging subway tunnels. We have previously proposed deep learning-based approaches for segmenting distress regions in subway tunnel images to reduce the maintenance cost; however, these approaches still have some difficulties in practical application and cannot address some worksite requirements. Thus, in this study, we developed technologies for enabling deep learning-based distress segmentation approaches to adapt better to practical scenarios. We propose a soft label approach for model training to specifically address the issue of slight deviation in the manual annotations of cracks. Additionally, for model evaluation, we propose using region-based metrics as a supplement to the commonly employed pixel-based metrics for a better evaluation of the crack segmentation performance. In the experiments, our distress segmentation approach, when enhanced by the above technologies, demonstrates the potential for practical use in subway tunnel inspection.
1. INTRODUCTION
Recently, there has been an increase in research on the application of deep learning technologies to computer vision tasks during infrastructure maintenance1)-4). Subway tunnels, a crucial facility of urban traffic infrastructure, currently rely on labor-intensive manual inspection for distress detection during the maintenance5), which is anticipated to be replaced by automation approaches. We have developed approaches for automatic distress segmentation in subway tunnel images6)-9) using deep learning models and further proposed a data augmentation approach10) to enhance the segmentation performance. Although the approaches achieved promising performance, some problems encountered during practical application still need to be addressed. For instance, the manual annotations of cracks may slightly deviate from the exact positions due to small crack widths, which can make the ground truth (GT) labels of cracks noisy. Furthermore, the commonly employed pixel-based metrics for semantic segmentation, such as intersection of union (IoU), may not reflect the actual performance of crack segmentation due to the small width and imperfect annotations of cracks. In addition, in the practical maintenance, it is considered more significant to measure the region-level crack density than recognizing the crack pixels, which makes the pixel-level evaluation unable to meet the actual needs. As crack is the most prevalent type of distress in subway tunnel images, it is crucial to customize the learning approach and evaluation metrics for adapting to practical scenarios.
In this study, we developed technologies to address the above-mentioned issues. To address specifically the issue of the slight deviation of crack annotations, we propose a soft label approach that expands the original labels of cracks by assigning soft labels to the nearest k pixels around each boundary pixel of cracks. Pixels near the boundaries are assigned values close to one, with values close to zero for far pixels. The effects of the annotation deviation can be reduced using the soft label approach, thereby improving the performance of the trained model. Regarding the evaluation metrics, we propose region-based metrics for evaluating crack segmentation performance. The images are cropped into small regions in the region-based evaluation, and each region is assigned a positive/negative label according to the ratio of the number of crack pixels to the total number of pixels in it. We then compute f1-score, recall, and precision as the region-based evaluation metrics for cracks using the region labels. Notably, the region-based metrics are unaffected by the slight deviation of crack annotations and more crucially, can meet practical application requirements better than the pixel-based metrics because the crack segmentation findings are not necessarily accurate at the pixel level.
This study’s contributions can be summarized as follows.
(1) We propose a soft label approach to reduce the effects of annotation deviation for cracks.
(2) We propose region-based evaluation metrics that are more suitable for evaluating crack segmentation performance than the typical pixel-based evaluation metrics for semantic segmentation.
(3) We perform experiments to validate the effectiveness of the soft label approach and perform evaluations with both pixel-based and region-based metrics. Furthermore, we visualize the segmentation findings in several ways for meeting various practical application requirements.
2. METHOD: DISTRESS SEGMENTATION IN SUBWAY TUNNEL IMAGES
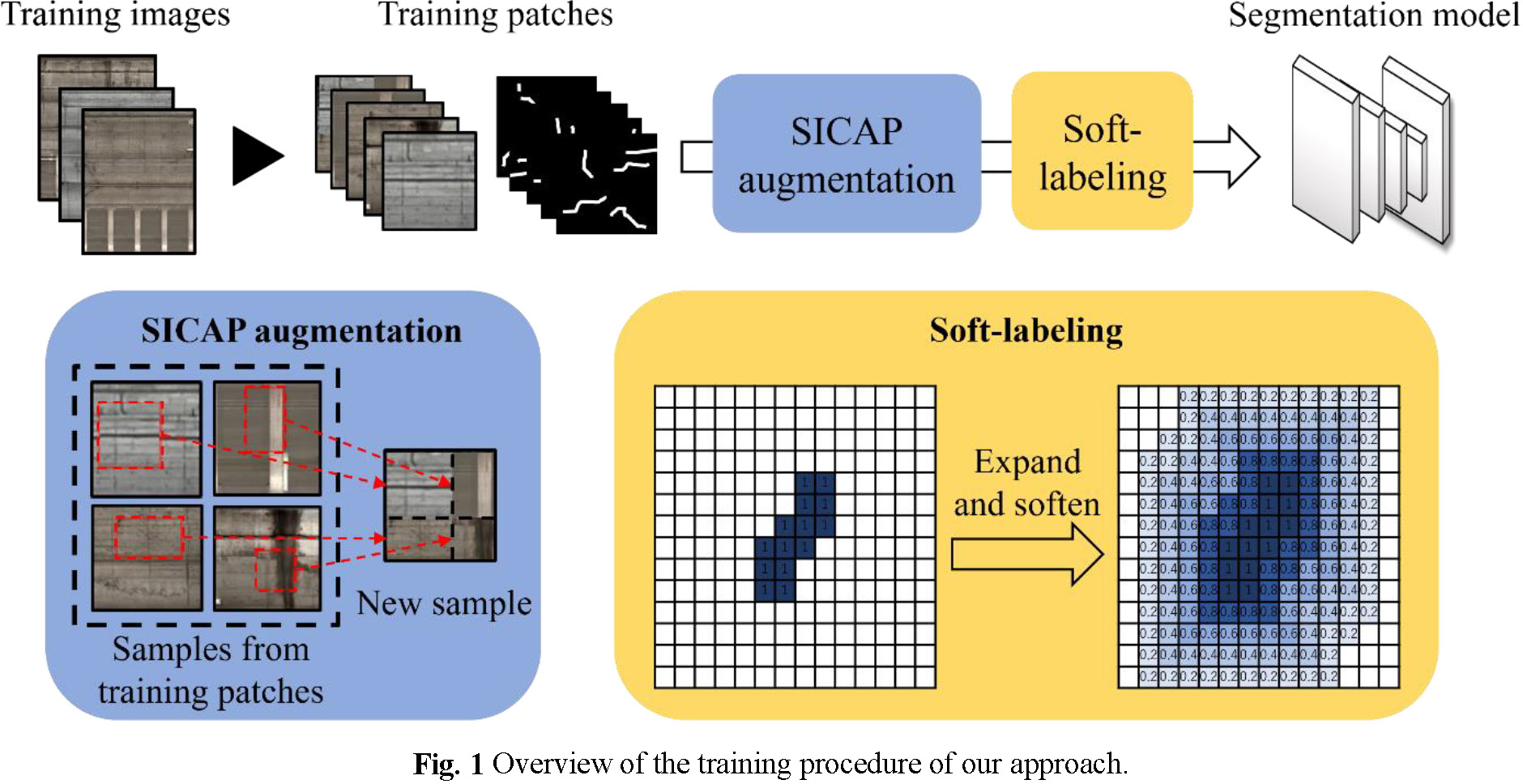
In this section, we first introduce our previously proposed segmentation approach that trains a deep convolutional neural network (DCNN) using a data augmentation approach called selective image cropping and patching (SICAP)10). Then, we describe the soft label approach and region-based evaluation, which are newly proposed in this study. Figure 1 demonstrates an overview of the training procedure of our approach.
(1) Distress segmentation using DCNN
In this study, distress segmentation is a two-class multilabel segmentation task. Regions where cracks are concentrated need to be detected and quickly repaired during subway tunnel inspections. Therefore, we consider all cracks as a “crack” class and the other distress as an “all-the-others” class. For each class of each pixel, the segmentation model predicts the positive/negative label. As the segmentation model, we employ the DeeplabV211) network with the ResNet10112) backbone, of which the effectiveness has been widely confirmed in various segmentation tasks. To train the model, we use the cross entropy loss. And to address the issue of imbalance between background pixels and distress pixels, we assign a ten-time weight, which is selected experi-mentally, to the pixels with a positive label.
(2) Data augmentation using SICAP
SICAP, a data augmentation method, is an extended version of random image cropping and patching13) (RICAP), which randomly crops patches from various samples and combines the cropped patches to obtain a new sample. RICAP was confirmed to be effective for distress segmentation14); however, it can be further enhanced by considering the specific data imbalance into the distress segmentation task. The training samples are small patches that are cropped from the original images with very large sizes; most of these patches often contain only background pixels. Most samples produced by RICAP do not contain distress pixels because RICAP randomly selects the samples for producing new samples, and such new samples are less meaningful for enhancing the segmentation performance than new samples containing distress pixels. Thus, we proposed SICAP, an improved version of RICAP, which selects only samples containing distress pixels for producing new samples. Specifically, we randomly select four samples that contain distress pixels for producing one new sample. For the four selected samples, given their original size (H, W), we randomly crop four patches with sizes (x, y), (H − x, W), (x, W − y), and (H − x, W − y) from them respectively, where x and y are sampled from a beta distribution B(5, 5). Then, the four cropped patches are combined to obtain a new sample. We produce the same number of samples as the original samples containing distress pixels, in other words, doubling the number of samples containing distress pixels.
(3) Soft label strategy
Due to manual errors, some cracks are not annotated at the exact positions, and the widths of the cracks may also be inaccurate. Some previous researches15)16) focused on learning with coarse annotations which are kind of different from the crack annotations in terms of error patterns. To reduce the effects of the slight deviation of the crack annotations, we expand them to the pixels near the crack boundaries; however, expanding the crack regions with a label value of one may annotate too many background pixels as positive. Therefore, we used a trade-off approach, which assigns soft labels to the pixels as per their distance from the nearest crack pixel. Figure 2 demonstrates the soft-labeling process. Specifically, for each crack pixel on the boundary, we first assign 0.8 to its nearest eight pixels. Similarly, we assign 0.6 to the nearest eight pixels of each pixel with 0.8, 0.4 to the nearest eight pixels of each pixel with 0.6, and 0.2 to the nearest eight pixels of each pixel with 0.4. If a pixel is assigned more than one label value, only the largest one would be retained. Thus, we can prevent the trained model from predicting too many background pixels as positive with high confidence.

(4) Region-based evaluation
As stated above, the widths of cracks are too small to manually annotate them without any deviation, which may also affect the evaluation at the pixel level. Moreover, in practical applications, the users do not expect predictions with high accuracy at the pixel level. Therefore, pixel-based metrics such as IoU are considered as too strict to assess the crack segmentation performance. We propose a region-based evaluation to better meet the actual needs for the evaluation, as illustrated in Fig. 3. For inference, we do not crop the original image into patches like that in the training but feed the entire image into the model. After inference, we crop the prediction and the corresponding GT of the entire image into patches of 250×250 pixels with a stride of 50 pixels. We then evaluate the ratio of the number of crack pixels to the total number of pixels in the patches for assigning region-level labels to them. We define patches in which >1% of pixels are crack pixels as positive patches and the others as negative. For the region-level prediction, we employ the same definition and threshold, that is, patches with >1% pixels predicted to be crack are predicted to be positive and the others to be negative. Then, with the region-level predictions and labels, we compute the f1-score, recall, and precision for evaluating the crack segmentation performance at the region level. We choose the patch size and stride according to the pixel spacing of subway tunnel images. In our study, the patch and stride have an actual region of 0.5 m × 0.5 m and a length of 0.1 m and a pixel spacing of 2 mm, which are appropriate dimensions in practical applications. We determined the threshold of crack pixels in the range of 0.1%–5% by qualitatively evaluating the visualization results of the region-based evaluation.
The advantages and significance of the region-based evaluation can be summarized as follows.
(1) The region-based evaluation is not affected by the slight annotation deviation.
(2) The evaluation can reflect the performance of the region-level localization of cracks, which is more meaningful than the pixel-level performance in practical applications.
(3) For assessing the development of cracks after a period, region-level results are more intuitive and easier to compare than pixel-level results.
3. EXPERIMENTS
(1) Research data
In this study, Tokyo Metro Company Limited provided the subway tunnel images and the corresponding labels. We employed 38 images with approximately 5000×6400 pixels as training data, five images as validation data, and five images as test data. The 38 training images were cropped into 109,248 patches of 256×256 pixels with a stride of 100 pixels. After conducting the SICAP augmentation, the number of training patches increased to 143,059, with 67,622 patches containing distress pixels. Of the distress patches, 61,275 contain crack pixels and 31,574 contain pixels of the other distress.
(2) Quantitative results
Table 1 lists the findings with and without the soft label approach. We have reported IoUs of crack and other distress for the pixel-based evaluation and reported the f1-score, recall, and precision of cracks for the region-based evaluation. The findings in Table 1 demonstrate that the soft label approach enhanced the crack segmentation performance in both the pixel-based and region-based evaluations. The IoU and f1-score of cracks were increased by 0.0108 and 0.0122, respectively, indicating the effectiveness of the soft label approach in reducing the effects of the annotation deviation. Although the precision score was slightly decreased by the soft label strategy, it is acceptable considering the more importance of recall than precision for the practical use and the trade-off relationship between recall and precision. The quantitative enhancements may seem minor, but the segmentation findings of some regions were clearly enhanced. The local improvements can only slightly influence the metrics computed over the entire test data. We have shown some examples for regions with clear improvement in the next subsection. Notably, our approach achieved a high recall score with the soft label approach, thereby satisfying the need in the practical scenario where overlook (i.e., false negative) of cracks is unacceptable but over detection (i.e., false positive) is relatively tolerable.

(3) Qualitative results and visualization
Figure 4 illustrates the qualitative findings of the crack segmentation for one test image per row. The four columns are for test image, GT of crack, and predictions of crack with and without the soft label approach, respectively. Figure 5 illustrates the enhancement of the crack segmentation for some regions through the soft label approach. Furthermore, as illustrated in Fig. 4, most of the cracks are detected with only a small amount of false positives. However, the pixel-based quantitative result for the IoU of crack has a relatively low score, a little greater than 0.3, which seems inconsistent with the qualitative results. Such inconsistency between the quantitative and qualitative results shows the significance of employing the region-based evaluation metrics. The f1-score being greater than 0.8 reflects better the crack segmentation performance than IoU.
Additionally, we have visualized the region-based results with the soft label approach in Fig. 6. The four rows show the findings of the four images in Fig. 4. The two left columns are the region-based heatmaps for GT and prediction. The regions labeled or predicted as positive are highlighted in the figures; the color closer to red represents more positive regions at that position. The pixel-level GT is added in both heatmaps as a reference. The region-based heatmaps are more practical than the segmentation findings in Fig. 4 for the workers performing maintenance because regions that are likely to contain cracks are cared for the most. Furthermore, the qualitative evaluation for region-based results is easier than that of pixel-based results as the heatmap of prediction with the additional GT of the crack is intuitive.
In Fig. 6, the right two columns show the region-based heatmaps of predictions in the horizontal and vertical directions. We employed Sobel filters to retain only the horizontal/vertical predictions and visualized them based on regions, similar to that of the left two columns but with a less positive threshold because the crack predictions became thinner after being filtered. The horizontal/vertical heatmaps can also be useful for monitoring the crack development process. If the same positions are inspected periodically in the future, it is possible to estimate the degree of development of cracks by computing the positive rate in the horizontal/vertical heatmaps.
4. CONCLUSION
In this study, we proposed technologies to help our previously proposed deep learning-based distress segmentation approaches for subway tunnel images adapt better to practical scenarios. The technologies include a soft label approach for reducing the effects of crack annotation deviations and the region-based evaluation, which can reflect better crack segmentation performance than the pixel-based evaluation and meet practical application requirements. In the experiments, we confirmed the effectiveness of the soft label approach and practicality of the region-based evaluation. Furthermore, we have demonstrated visualizations of the region-based results that may be useful during the maintenance.
This study has several limitations. First, we focused on the crack distress, and the other types of distress were segmented as one class. The respective performance for the distress types except crack was unknown in this study. Second, the test data used in the experiments were limited, and it is supposed to evaluate our method with a larger number of test data. Third, we used data only from one interval block of one subway line, and the performance of the method in other blocks or lines is remained to be evaluated. As future works, we will use data of different subway lines and study on the model generalization for different lines. Moreover, it is meaningful to study on the distress development process using periodical inspection data.
Acknowledgments
In this research, we utilized the inspection data that were provided by the Tokyo Metro Company Limited. This work was partly supported by JSPS KAKENHI (Grant Number JP20K19856).
References
- 1) Koch, C., Georgieva, K., Kasireddy, V., Akinci, B. and Fieguth, P.: A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure, Advanced Engineering Informatics, Vol. 29, No. 2, pp. 196-210, 2015.
- 2) Dung, C. V.: Autonomous concrete crack detection using deep fully convolutional neural network, Automation in Construction, Vol. 99, pp. 52-58, 2019.
- 3) Ogawa, N., Maeda, K., Ogawa, T. and Haseyama, M.: Distress image retrieval for infrastructure maintenance via self-trained deep metric learning using experts’ knowledge, IEEE Access, Vol. 9, pp. 65234-65245, 2021.
- 4) Ogawa, N., Maeda, K., Ogawa, T. and Haseyama, M.: Deterioration level estimation based on convolutional neural network using confidence-aware attention mechanism for infrastructure inspection, Sensors, Vol. 22, No. 1, pp.382, 2022.
- 5) Shen, B., Zhang, W. Y., Qi, D. P. and Wu, X. Y.: Wireless multimedia sensor network based subway tunnel crack detection method, International Journal of Distributed Sensor Networks, Vol. 11, No. 6, pp. 184639, 2015.
- 6) Wang, A., Togo, R., Ogawa, T. and Haseyama, M.: Detection of distress region from subway tunnel Images via U-net-based deep semantic segmentation, IEEE 8th Global Conference on Consumer Electronics, pp. 766-767, 2019.
- 7) Li, Z., Togo, R., Ogawa, T. and Haseyama, M.: A note on retrieval of visually similar distress regions in subway tunnel images: introduction of deep features extracted by semantic segmentation network, ITE Technical Report, Vol. 119, No. 421, pp. 65-68, 2020.
- 8) Takada, S., Maeda, K., Togo, R., Ogawa, T. and Haseyama, M.: A note on distress detection based on deep learning with hierarchical multi-scale attention mechanism for supporting maintenance of subway tunnels, ITE Technical Report, Vol. 46, No. 6, pp. 377-381, 2022. (in Japanese)
- 9) Wang, A., Togo, R., Ogawa, T. and Haseyama, M.: Defect detection of subway tunnels using advanced U-Net network, Sensors, Vol. 22, No. 6, pp. 2330, 2022.
- 10) Maeda, K., Takada, S., Haruyama, T., Togo, R., Ogawa, T. and Haseyama, M.: Distress detection in subway tunnel images via data augmentation based on selective image cropping and patching, Sensors, Vol. 22, No. 22, pp. 8932, 2022.
- 11) Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K. and Yuille, A. L.: Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 40, No. 4, pp. 834-848, 2017.
- 12) He, K., Zhang, X., Ren, S. and Sun, J.: Deep residual learning for image recognition, IEEE Conference on Computer Vision and Pattern Recognition, pp. 770-778, 2016.
- 13) Takahashi, R., Matsubara, T. and Uehara, K.: Data augmentation using random image cropping and patching for deep CNNs, IEEE Transactions on Circuits and Systems for Video Technology, Vol. 30, No. 9, pp. 2917-2931, 2019.
- 14) S., Haruyama, Maeda, K., Togo, R., Ogawa, T. and Haseyama, M.: A note on improvement of deep learning-based distress detection for supporting maintenance of subway tunnels ~ accuracy verification focusing on tunnel wall characteristics ~, ITE Technical Report, Vol. 45, No. 4, pp. 1-6,2021. (in Japanese)
- 15) Liu, J., Yao, Y., Hou, W., Cui, M., Xie, X., Zhang, C. and Hua, X.: Boosting Semantic Human Matting with Coarse Annotations, the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8563-8572, 2020.
- 16) Das, A., Xian, Y., He, Y., Akata, Z. and Schiele, B.: Urban Scene Semantic Segmentation with Low-Cost Coarse Annotation, the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 5978-5987, 2023.