Generalizing deep learning-based distress segmentation models for subway tunnel images by test-time training
2024 年 5 巻 1 号 p. 34-41
詳細
2024 年 5 巻 1 号 p. 34-41
This paper proposes generalizing deep learning-based distress segmentation models for subway tunnel images by test-time training. Although it is promising to see that deep learning-based models are greatly alleviating the burden on subway tunnel maintenance workers, practical use of deep learning-based models for distress detection in subway tunnel images faces an obstacle, difficulty in training a generalizable model. Due to the diverse characteristics and different tunneling methods of the numerous subway tunnels, a model trained with data collected from one tunnel may not work well for another tunnel. Whereas training with data of a wide range of tunnels would be an ideal way, collecting such a large amount of well-labeled data is expensive. As an alternative to pursuing a highly generalizable model, it is more flexible and low-cost to generalize the model to specific test data at test time. In tasks of which the inference is not necessarily realtime, finetuning the model with the unlabeled test data may significantly improve the performance, not increasing too much inference time. In this paper, we focus on semantic segmentation of distress region in subway tunnel images and develop a test-time training method for generalizing the segmentation model to test data of different subway tunnels from the training data. Our method is simple yet effective, predicting pseudo labels with test-time batch normalization and finetuning the model with the pseudo labels. Extensive experimental results demonstrate that our method improves the distress segmentation performance in various scenarios, especially for crack which is a major and hard-to-detect distress type.
Currently, distress detection during subway tunnel maintenance is heavily reliant upon manual inspection, which is labor-intensive and may be increasingly expensive due to reduction in the labor force. Along with the advancement of deep learning technologies, it is anticipated that distress detection of subway tunnels can be automated with deep learningbased models using subway tunnel images. To tackle this task, we have proposed methods for semantic segmentation of distress region using deep convolutional neural networks1)-4) and further developed a data augmentation method for improving the segmentation performance5) and an evaluation method that is tailored to the needs of better evaluation for crack segmentation6). Despite promising performance, practical use of the methods still faces an obstacle, difficulty in training a generalizable model. Images collected from different subway tunnels have diverse characteristics, and a model trained for one tunnel may thus have poor performance for another one. To our knowledge, the problem is not yet resolved.
To obtain a generalized model for a wide range of subway tunnels, an intuitive way is to train the model with data collected from all the tunnels. However, fine-grained annotations of distress segmentation for the large number of subway tunnel images are expensive. Moreover, there may still be unseen tunnels in real-world application scenarios, and generalization to the unseen data is not guaranteed. To avoid increasing the annotation costs, we adopt a distinct way that does not require wide-ranging training data, generalizing the model at test time. Specifically, given a pre-trained model, in the test phase, we finetune the model with test data for a limited number of iterations. The finetuned model can generalize better to the test data without using ground truth annotations. Moreover, since there are no changes made to the training phase, our method can be performed with any pre-trained model.
Our test-time training method is developed on the basis of two simple yet effective techniques, test-time batch normalization (test-time BN) and pseudo-label finetuning. Test-time BN has shown to be effective for applying a pre-trained classification model to new domains7)-8), while the improvement by test-time BN is limited for distress segmentation. On the other hand, the use of pseudo labels has been studied for unsupervised domain adaptation of semantic segmentation9)-10). However, it is problematic to finetune the whole model with pseudo labels for test-time training because the model may degrade due to the small amount of test data and poor accuracy of pseudo labels. Considering the above problems in the previous studies, we combine the two techniques and make a change to the training with pseudo labels, finetuning only a small proportion of the model parameters.
As mentioned above, in this paper, we propose a test-time training method for generalizing deep learning-based distress segmentation models across different subway tunnels. The test-time training comprises two steps in each iteration: inference with test-time BN and pseudo-label finetuning. The test-time BN uses current batch statistics instead of the running statistics of training data at all the batch normalization layers. This can, to some extent, reduce distribution gaps between the training and test data at the feature level. The inference results using test-time BN are not final results but used as pseudo labels in the following pseudo-label finetuning, in which a small number of parameters of the pre-trained model are finetuned with supervisions of the pseudo labels. Due to the limited numbers of iterations and parameters, the finetuning process does not take a long time, hence our method can be readily applied to a series of different subway tunnels.
This study’s contributions can be summarized as follows.
(1) We propose a test-time training method for deep learning-based models of distress segmentation in subway tunnel images, which improves the model’s generalization performance for different tunnels with minimal expense.
(2) We conduct extensive experiments to validate our method’s effectiveness over various scenarios, i.e., evaluating different pre-trained models with test data of multiple tunnels. The results demonstrate the effectiveness and generalizability of our method for distress segmentation of subway tunnels.
In this section, we first review the deep learningbased distress segmentation model for subway tunnel images that we previously developed5). Based on the model, we introduce the test-time training method for generalizing the model to different subway tunnels. Figure 1 illustrates both the training phase which is the pre-training with our previous method and the test phase where the test-time training is performed.

(1) Preliminary: distress segmentation in subway tunnel images
Our previous distress segmentation model is developed on the basis of a deep convolutional neural network, DeeplabV211) with the ResNet10112) backbone, which has been validated in a wide range of applications. We formulate the distress segmentation as a two-class multi-label segmentation task. In other words, each pixel of an image is inferred whether belonging to two distress classes which we define as a "crack" class for all the cracks and a "the-others" class for all the other distress types except crack, in light of the fact that cracks are thin lines while all the other distress are identified as regions. Due to the high resolutions (most with a short side longer than 5,000 pixels) of the original subway tunnel images, we first crop the images into patches of 256×256 pixels with a stride of 100 pixels, and then train the model with the produced patches.
The segmentation model is trained with a conventional cross entropy loss and an additional data augmentation strategy, selective image cropping and patching5) (SICAP). SICAP is developed on the basis of the random image cropping and patching13) (RICAP), which augments training data by cropping images into patches and combining patches of randomly sampled images into a new training image. For distress segmentation, as distress regions typically constitute only a small portion of the whole images, RICAP produces a substantial number of negative samples without any distress14). Since normal regions abundantly present in the original training data, positive samples of distress are more valuable to produce in the data augmentation. To this end, SICAP selects patches from only those containing distress of any type to make sure all the produced samples are positive samples.
In summary, as shown in the upper part of Fig. 1, the training phase of the distress segmentation model consists of three steps: cropping the subway tunnel images into patches of an appropriate size, data augmentation with SICAP for the patches, and model training using the augmented patches.
(2) New proposition: test-time training for generalizing pre-trained models
In the test phase, given test data, the pre-trained model is finetuned to generalize better to unseen test data in a self-training manner. Self-training is to train the model with pseudo labels predicted by itself, which has been widely used in studies on semi-supervised learning15)-17) and unsupervised domain adaptation18)-19). In our task, because there may exsit considerable differences between training and test images that are collected from different subway tunnels, pseudo labels produced by normal model inference may have a very poor accuracy. Training with such pseudo labels is less helpful to improving the model.
To produce more accurate pseudo labels, we make a cost-free change to the inference process, using testtime BN. Test-time BN is the same as normal BN except for the features statistics (i.e., mean and standard deviation) used in the normalization during inference. To be specific, in a normal BN layer, during training input features are normalized with the feature statistics of the current batch, and meanwhile running statistics (i.e., exponential moving average of statistics) of the training data are stored. Then, in the inference process during test, the running statistics of training data are used to normalize the features input into the BN layers, while the test-time BN uses the test-batch statistics which may deviate from the correct distribution of test data due to a small batch size. The normal BN fails to yield expected results when the training data and test data have different distributions. It has been reported that for test data distributed differently from the training data, using the statistics of the current test batch can yield better results than using the running statistics of the training data7)-8). Moreover, subway tunnel images of the same tunnel do not have significant differences, thereby stabilizing the test-batch statistics. Therefore, we use the test-time BN to produce more accurate pseudo labels for the following finetuning.
The fine-tuning process is performed using the same loss function as that of the training phase, but is different from the training phase in trained parameters. During the test-time training, only affine parameters of the BN layers are updated while all the other parameters of the model are frozen. We make this change for two reasons: first, to preserve the knowledge of the pre-trained model, and second, to reduce time cost of the finetuning. For the first reason, because of the noisy pseudo labels and the possibly small amount of test data, training all the model parameters solely with the pseudo labels can harm the model’s capacity instead. Training only the affine parameters of the BN layers has a much lower risk of losing knowledge learned by the pre-trained model, and can rectify feature distributions of the test data to achieve better performance20). As to the second reason, although the inference for subway tunnel images is not necessarily real-time, the test-time training should not take a long time as too much increase in time cost may reduce the flexibility of the test-time training. Because the number of the affine parameters is very small compared to the total number of the model parameters, training only the affine parameters is faster than training the whole model, which makes it appropriate for the test-time training.
The test-time training, as shown in the lower part of Fig. 1, is summarized as follows. The test phase is composed of three steps: pseudo label producing with test-time BN, finetuning of BN affine parameters with pseudo labels, and final inference for test data. In the pseudo-label producing, a confidence threshold is used to filter out unreliable predictions, which is empirically set to 0.7. The final inference uses the normal BN with running statistics of the test data cal-culated during the finetuning.
(1) Research data
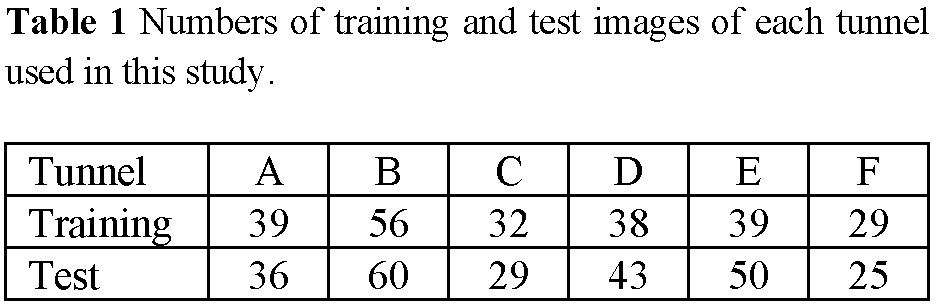
In this study, all the research data are provided by Tokyo Metro Company Limited. We used subway tunnel images collected from six tunnels of different subway lines. Table 1 shows the numbers of training and test images of each tunnel. Most images have a width of 5,000~6,000 pixels and a height of 5,000~7,000 pixels. For training, the images were cropped into patches of 256×256 pixels with a stride of 100 pixels.
(2) Evalution metrics
We performed evaluations of two different types: conventional pixel-based evaluation of semantic segmentation with Intersection over Union (IoU) as the metric and region-based evaluation that we proposed for crack segmentation6). As in practical use, segmentation for cracks is not necessarily precise at the pixel level, evaluation with region-level (i.e., small patch) labels and predictions can better reflect the crack segmentation performance and meet the pracitical needs. We used recall, precision, and F-1 score as metrics of the region-based evaluation.
Figure 2 illustrates the region-based evaluation. The regions are counted with a sliding window in both the prediction and ground truth. For each region, positive pixels are counted to determine the region label, i.e., a region is labeled as positive if the positive pixels account for more than 1% of all pixels within the region. Then the regions of prediction are counted as true/false positive and ture/false negative regions according to the ground truth region labels.

(3) Quantitative results
Table 2 shows all the experimental results. We performed the test-time training with three models trained on "D", "E" and "F" on images of all the other five tunnels, respectively. For comparison, we also evaluated all the six models each on images of the same tunnel, respectively.

First, for the pixel-based evaluation, it can be seen that in most scenarios the test-time training clearly improved the crack segmentation performance. Only in 3 of the 15 scenarios, the IoUs of crack segmentation show no improvement or slight decrease. On the other hand, for segmentation of the other distress, the results were improved in less scenarios than crack segmentation. Clear improvements can be seen in four scenarios, and in some of the scenarios, the model failed to segment the other distress even after the test-time training. We think it may be explained by the larger gaps between the characteristics of the other distress in different tunnels than that of cracks.
For the region-based evaluation, we can see more significant improvements than those of crack IoUs in the pixel-based evaluation. Moreover, for the scenarios where the improvements in f1-score are slight or absent, such as "test-A-train-D", "test-E-train-F", and "test-F-train-E", we can still see clear improvements in recall, which is prioritized in practical applications because overdetection of cracks is tolerable while overlook is unacceptable. Therefore, from a practical respective, the test-time training improved the crack detection performance in all the scenarios shown in Table 2. In addition, comparing the testtime training results to those using training and test data of the same tunnel (i.e., in-distribution evaluation), we can see that in some scenarios such as "test-A-train-E", "test-D-train-E", and "test-D-train-F", the f1-scores were improved close to the in-distribution ones by the test-time training, which implies the practical use potential of our method.
(4) Qualitative results and visualization
Figures 3 and 4 illustrate several qualitative examples of pixel-based and region-based crack segmentation results. In both the images, each row shows one test image, the ground truth of crack segmentation, the prediction without the test-time training, and the prediction with the test-time training in four columns, respectively. The images in Figs. 3 and 4 are the same ones, each of which is of a different tunnel. The model was pre-trained on tunnel "E". Figure 3 shows the pixel-level crack segmentation results, while Fig. 4 visualizes the region-level crack detection results. Regions classified as positive, i.e., containing crack distress, are highlighted in the heatmap images, and color close to red represents high density of positive regions.


From the figures, it is clear that both the pixel-level and region-level results were significantly improved by the test-time training. Especially for the images of tunnel "A" and tunnel "B" in the first and second rows, the original model could hardly detect any cracks, and after the test-time training, most cracks and crack regions annotated in the ground truths were found in the results. The qualitative results visually demonstrate the application potential of our method.
In this study, we have presented a test-time training method for generalizing deep learning-based distress segmentation models for subway tunnel images. Our method comprises a pseudo-label producing process with test-time BN and a pseudo-label finetuning process adapting the BN affine parameters. It can be readily employed without much additional annotation and time costs, moreover, it makes no changes to the training phase, thereby being applicable to any pre-trained segmentation models. The experimental results showed that our method improved the crack segmentation performance over a wide range of scenarios, indicating its effectiveness and application potential.
There are several limitations in this study. First, the test-time training method was implemented with only one segmentation network, the peformance has remained to be evaluated with other networks, especially the state-of-the-art ones. Second, our method failed to improve the segmentation of the other distress expect cracks in some scenarios. Since the variations of the other distress are more complicated than those of cracks, we leave it as future work. Moreover, the crack segmentation performance improved by our method is still unsatisfactory for the practical use. Further improvement may be made by introducing a batch sampling strategy that takes into account the proportion of patches with distress in a batch. Finally, models trained with images of multiple tunnels were absent in this study. It is worthy of study how the more generalizable models can be further generalized to unseen test data.
In this research, we utilized the inspection data that were provided by the Tokyo Metro Company Limited. This work was partly supported by JSPS KAKENHI (Grant Number JP23K11211).