Chat GPT (Generative Pre-trained Transformer) is a generative artificial intelligence (generative AI) application released by OpenAI in November 2022. It can provide answers in a conversational format, and by specifying the desired response format, one can adjust the output content (such as the word count and expression style). Chat GPT is expected to be used for various applications, such as text summarization, translation, scenario creation, programming, etc. In this study, we presented questions on the vertigo domain from the Otorhinolaryngology Head and Neck Surgery specialist examinations to Chat GPT to evaluate its potential in clinical diagnosis. We presented 51 questions related to vertigo and balance medicine (excluding questions with images) selected from the Otorhinolaryngology specialty certificate examinations held from 2013 (25th) to 2022 (34th) to GPT-3.5 and GPT-4 and evaluated their accuracy rates. The accuracy rates of GPT-3.5 and GPT-4 were 21.6% and 49.0%, respectively. Although the accuracy increased with the version upgrade, Chat GPT is not a specialized AI application for medical use; it is a general-purpose AI. Given the accuracy rates in this study and the possibility of inaccurate answers, it is currently considered uncertain for use for clinical diagnosis in the real world. However, it is expected to be useful for applications such as summarizing patient histories and literature searches to improve the efficiency of medical tasks, and with improvements of the accuracy through version updates, there is potential for application of ChatGPT in the field of medicine in the future.
人工知能(AI: Artificial Intelligence)はスマートフォンのアシスト機能,ロボット掃除機,自動車の自動運転などにも導入され日常生活に身近なものとなっている。Chat GPT(Generative Pre-trained Transformer)は2022年11月にOpen AI社によって公開された生成的人工知能(生成AI)である。登録することで誰でも無料で利用でき,対話形式で解答を得ることができる簡便さより,公開から2か月目で月間の利用者数が全世界で1億人を突破(チャットGPT,ユーザー数の伸びが史上最速=UBSアナリストhttps://jp.reuters.com/article/openai-chatgpt-idJPKBN2UC04M)し,様々な分野での応用が検討されるなど話題となった。期待する回答の様式を指定することにより,出力内容(文字数,表現方法など)を調整することが可能であり,文章の要約,翻訳,シナリオ作成,プログラミングなど様々な用途への応用が期待される。現在Chat GPTには,無料で公開されているGPT-3.5と,その後継モデルとして有料のGPT-4が公開されている。どちらも2021年9月までのデータを学習モデルとして使用しているが,GPT-4の方がモデルに用いられる学習データが多く質問の読解力,文章の構成の改善が期待される。医学教育においてこれまでにいくつかの医学系試験をChat GPTに解答させる試みがなされ,医学知識に対するAIによる解答の正確性が報告1)~4)されている。一方で実臨床において,汎用AIであるChat GPTを診断に用いることはないと思われるが,患者がChat GPTに症状を入力し健康相談を投げかける可能性がある。Chat GPTによる臨床診断能力は興味にあるところである。これまでに様々な医学系試験に対するChat GPTの評価が行われてきたが,耳鼻咽喉科領域の研究はなされていない。今回我々はChat GPTによる臨床診断能力推測のため,耳鼻咽喉科専門医試験のめまい領域に関する問題を提示し,解答の正確性について検討した。
なお耳鼻咽喉科のなかでめまい平衡領域に限定した理由は,古くより本学会における検査の基準化や診断基準が確立され,診断の標準化がなされてきた5)。また問診票による診断もさまざま検討されてきた6)。このような経緯より,耳鼻咽喉科のなかでも,めまい平衡医学領域は比較的AIに受け入れやすいと考えたからである。
2013年度(第25回)から2022年度(第34回)の耳鼻咽喉科専門医試験問題のうち,めまい平衡医学に関連する51題を選択した。なお,Chat-GPTでは,画像データは扱えないので画像を含む問題を除いた。これらを,GPT-3.5およびGPT-4に提示し,その正答率の評価を行った。提示した問題文は原文のままとした。正解肢数が指定されている多真偽形式では,すべて正しく選択された場合のみを正答とした。問題の内訳は一般問題が40題,臨床問題が11題であった。解答形式別に分類を行うと単純択一形式が33題,多真偽形式が18題であった。問題の難易度をTaxonomy(教育目標の分類学)に沿って分類した。Taxonomyとは,解答に要する知的能力によって分類を行う方法であり,I型(想起),II型(解釈),III型(問題解決)の3つに分類される。今回用いた全51題のうちI型は19題,II型は25題,III型は7題であった。本研究は,2023年6月9日から6月16日の間に,URL https://openai.com/chatgptにアクセスすることにより行った。
選択問題では無作為に解答しても一定の正答率は得られる(たとえば5者択一なら20%の正答率)ので,得られた正答率が無作為の解答による偶然の結果と差があるかについて二項検定を用いて検討した。またGPT-3.5とGPT-4における正答率の差は,McNemar検定を用いて検討した。対応のない2群間の正答率の差はFisherの直接確率検定で,3群間においてはCochran-Armitage検定で評価した。統計解析にはEZR ver.1.357)を用い,有意水準を5%とした。
全51題に対するGPT-3.5およびGPT-4による正答率を図1に示す。正答率は前者が 21.6%,後者が49.0%であった。また,GPT-4はGPT-3.5よりも有意差を持って正答率が高かった(p = 0.0060)。
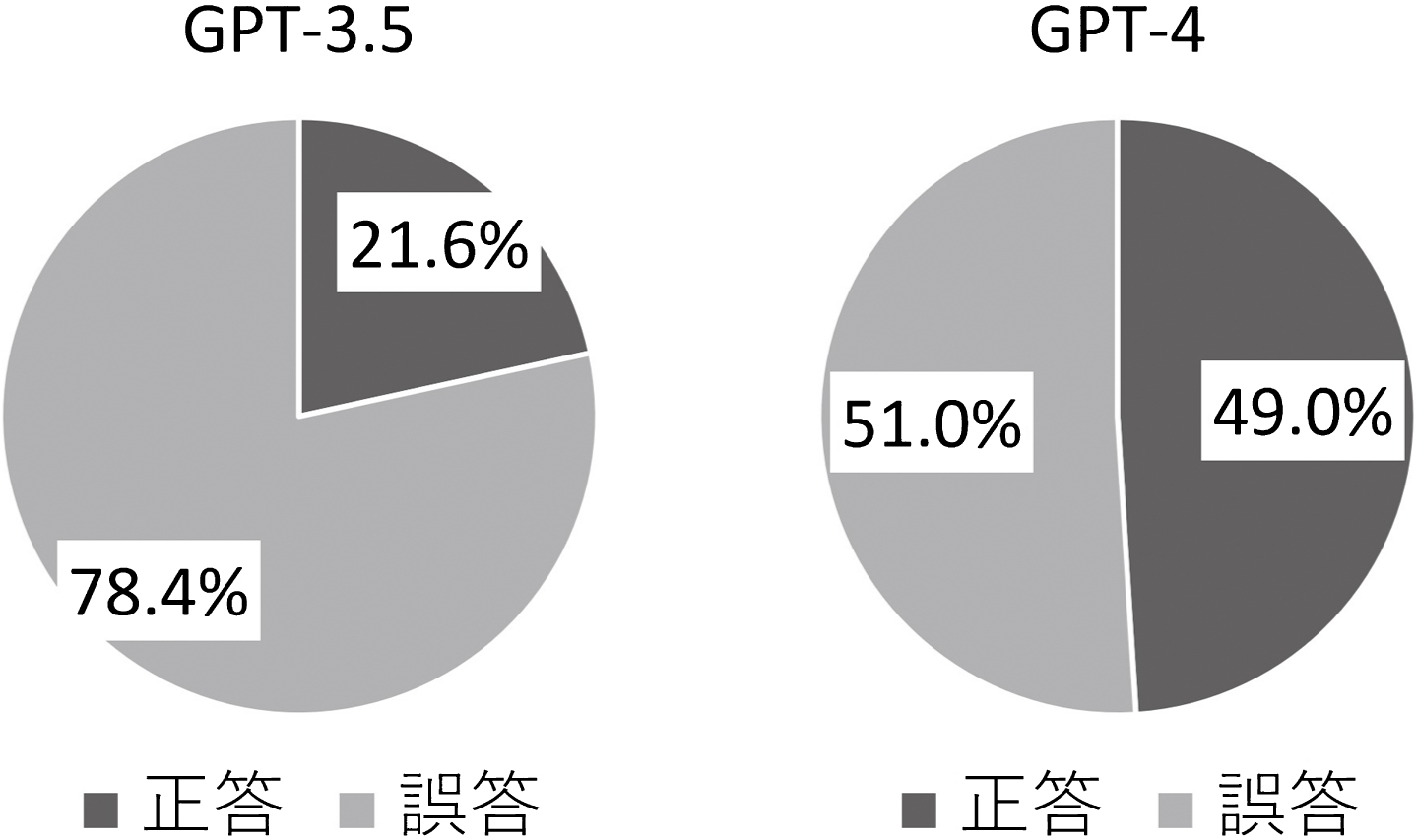
両者の正答率には有意差を認めた(p = 0.0060,McNemer検定)。
問題形式別の解答結果を図2から4に示す。出題形式別の正答率は,一般問題ではGPT-3.5で20.0%(p = 0.34),GPT-4で52.5%(p = 1.83 × 10−7)であり,臨床問題ではGPT-3.5で27.2%(p = 0.27),GPT-4で36.4%(p = 0.095)であった。GPT-4の一般問題の正答率は偶然の結果より有意差をもって高かった。GPT-4では,臨床問題は一般問題よりも正答率が有意差をもって低かった(p = 0.015)。GPT3.5では出題形式による正答率の有意差は認めなかった(p = 0.68)。選択形式別の正答率については,単純択一形式ではGPT-3.5で24.2%(p = 0.52),GPT-4で48.5%(p = 0.23 × 10−3)であった。多真偽形式ではGPT-3.5で16.7%(p = 0.42),GPT-4で50.0%(p = 0.21 × 10−4)であった。GPT-3.5の正答率は偶然の結果と有意な差を認めなかったが,GPT-4では偶然の結果より有意差をもって高かった。GPT-3.5,GPT-4のいずれにおいても,単純択一式と多真偽形式との有意な差は認めなかった(GPT-3.5 p = 0.72, GPT-4 p = 1.00)。Taxonomy分類による問題難易度別の正答率は,I型ではGPT-3.5で21.0%(p = 0.39),GPT-4では57.9%(p = 5.46 × 10−5),II型ではGPT-3.5で20.0%(p = 0.39),GPT-4では40.0%(p = 0.0042),III型ではGPT3.5で28.6%(p = 0.34),GPT-4では57.1%(p = 0.020)であった。GPT-3.5の正答率は偶然の結果と有意な差を認めなかったが,GPT-4では偶然の結果よりも有意差を持って高かった。Taxonomy分類による問題難易度別の正答率の差は,GPT-3.5,GPT-4のいずれにおいても有意差を認めなかった(GPT-3.5 p = 0.77, GPT-4 p = 0.64)。
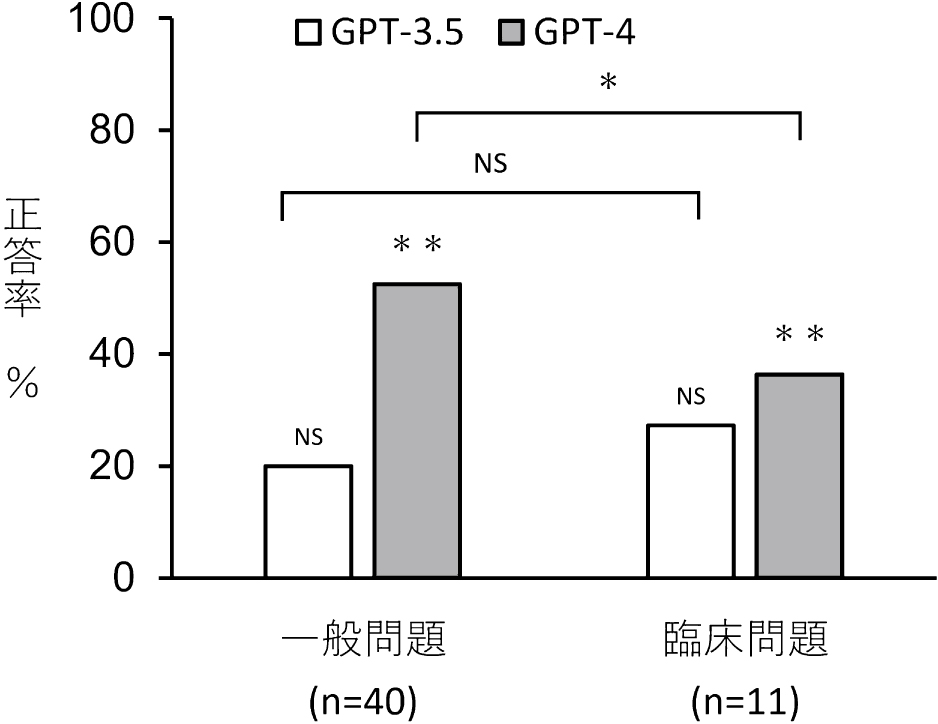
二項検定ではGPT-3.5では偶然の結果と比べ有意差を認めなかった。GPTでは有意差を認めた(一般問題:p = 1.83 × 10−7,臨床問題:p = 0.095)。Fisherの直接確率検定ではGPT-4では2群間の正答率に有意差を認めた(p = 0.015)。NS : not significant,* : p < 0.05,** : p < 0.01
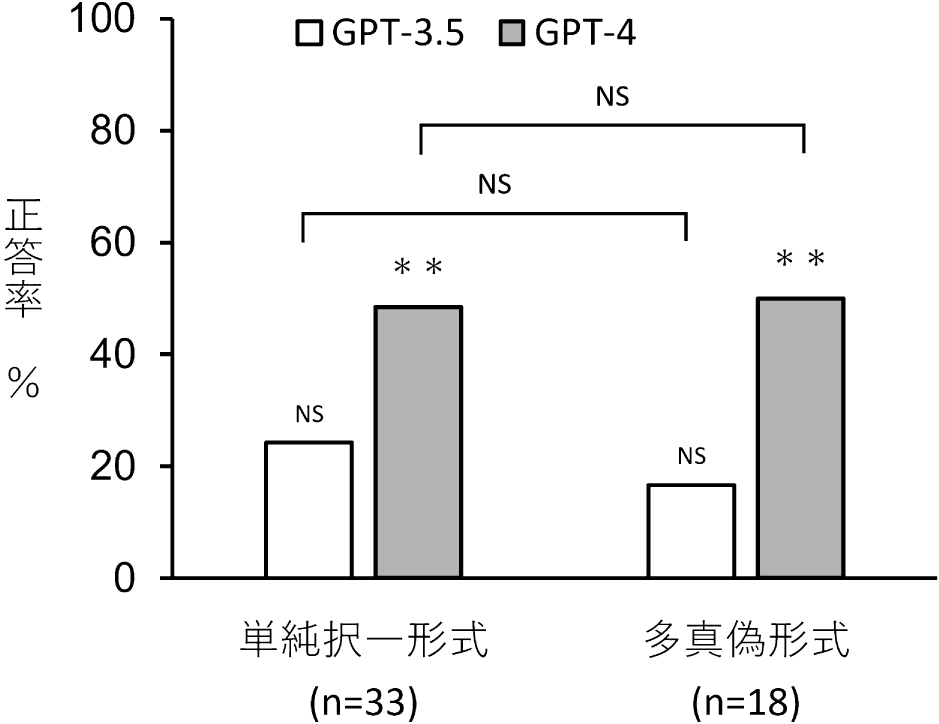
二項検定ではGPT-3.5では偶然の結果と比べ有意差を認めなかった。GPTでは有意差を認めた(単純択一形式:p = 0.23 × 10−3,臨床問題:p = 0.21 × 10−4)。Fisherの直接確率検定ではGPT-3.5,GPT-4いずれも2群間の正答率に有意差を認めなかった。NS : not significant,* : p < 0.05,** : p < 0.01
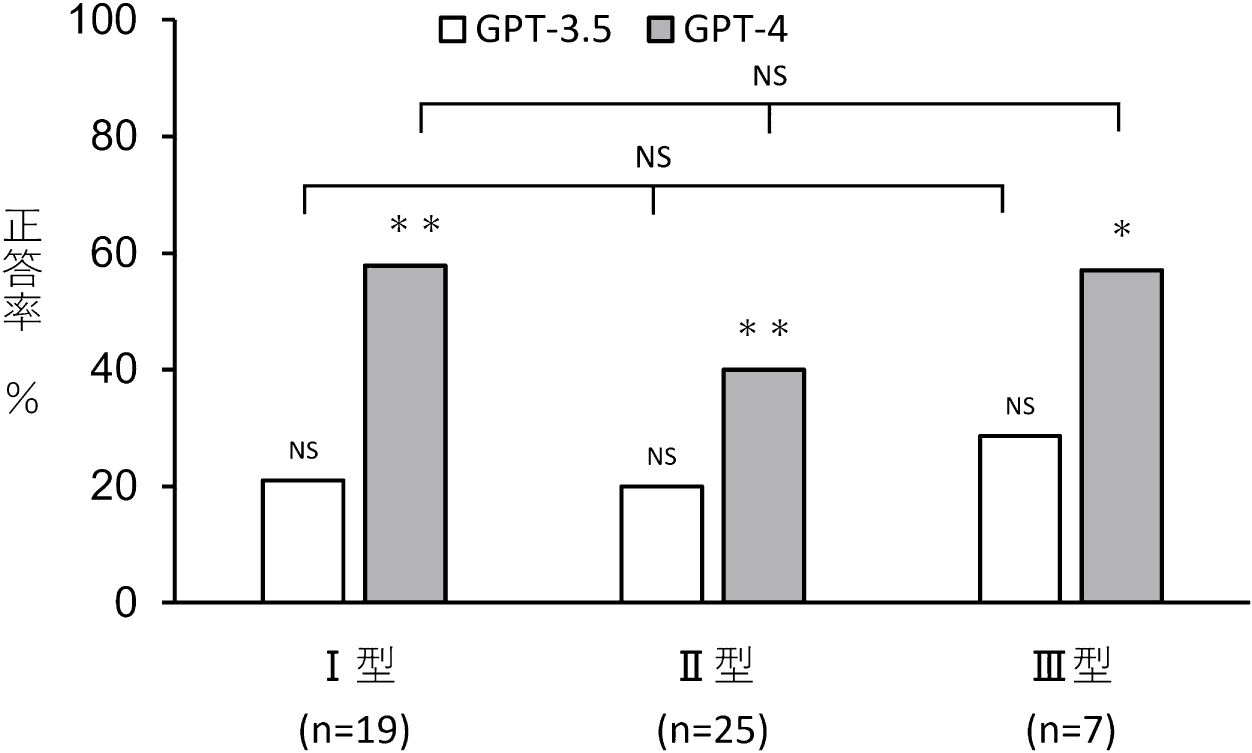
二項検定ではGPT-3.5では偶然の結果とくらべ有意差を認めなかった。GPT-4では有意差を認めた(I型:p = 5.46 × 10−5,II型:p = 0.0042,III型:p = 0.020)。Cochran-Armitage検定ではGPT-3.5,GPT-4いずれも各群の正答率に有意差を認めなかった。NS : not significant,* : p < 0.05,** : p < 0.01
本研究における全問題の正答率はGPT-3.5で21.6%,GPT-4で49.0%であった。耳鼻咽喉科専門医試験の合格点は公表されていないが,50%以下の正答率では合格には至らず,十分な臨床能力があるとは言えないと考える。GPT-3.5では,いずれの出題形式においても偶然の結果と差を認めなかったので,以下の検討は主としてGPT-4について述べる。
選択形式による正答率の有意差は無く,バージョン改定による正答率上昇を認めたのみで解答の選択数が正答率の影響を与えることは少ないと考える。
出題形式による比較では,一般問題は臨床問題より正答率が高く,臨床問題では偶然の結果と有意差がなかった。病歴などの情報がなく問題内容が簡素であれば,正答率が有意に上昇することが示された。
Taxonomy I型は単純な知識の想起によって解答できる問題,II型は与えられた情報を理解・解釈してその結果に基づいて解答する問題,III型は設問文の状況を理解・解釈した上で,各選択肢の持つ意味を解釈して具体的な問題解決を求める問題である(医師国家試験改善検討部会報告書https://www.mhlw.go.jp/file/05-Shingikai-10803000-Iseikyoku-Ijika/0000128989.pdf)。各群の正答率の比較で有意差は認めなかった。Chat GPTは,問題の解釈力が苦手であるわけではないことが示された。
本研究と他研究における医療系試験に対するChat GPTの正答率を表11)~4)に示す。日本の医師国家試験,米国の医師国家試験であるUSMLE,米国消化器学会の自己評価試験では合格基準に近い点数もしくは合格基準を超える正答率であった。本研究は海外の報告と比べると低い正答率であった。その原因として,言語や文章の内容による問題,日本の医療情報の学習不足があげられる。Chat GPTは日本語に対応しているものの,基本言語は英語である。田中らによる日本の医師国家試験問題におけるGPTの成績による研究1)ではGPT-3.5に提示した研究では問題文(n = 290)の英訳により正答率が52.8%(153/290)から56.3%(163/290)へと上昇が報告されている。さらに英文の要約を行うことにより63.1%(183/290)まで上昇したことが報告されている。本研究では問題文を調整することなく入力しているが,入力内容を調整することにより正答率が上昇する可能性がある。また本研究で用いた試験問題には日本特有の医療情報に関する問題(指定難病制度,障害者認定,疫学)が4題含まれていた。それらの問題はGPT-3.5で1題正答したが,その他すべての問題はGPT-3.5,GPT-4では不正解であった。これらの原因としては日本の医療情報の学習データ不足が考えられる。本研究と田中ら1)による研究の正答率の差は大きく,これには,今回用いた問題内容の専門性が影響していると考える。
| 試験名 | GPT-3.5 | GPT-4 | 合格基準 |
|---|---|---|---|
|
米国消化器学会自己評価テスト (2021年度+2022年度)(n = 455) |
65% | 62% | 70% |
|
USMLE(2022サンプル問題) ※不確定な回答を除く(n = 350) |
62–75% | 60% | |
| 米国眼科学会 トライアル問題(n = 125) | 46% | ||
| 117回医師国家試験(n = 262) | 63% | 83% |
80%(必修) 74%(臨床) |
|
耳鼻咽喉科頭頸部外科専門医試験 めまい平衡医学領域(自験例) |
17.9% | 43.6% |
これまでの他の医療系試験に対する報告はGPT-4による正答率がGPT-3.5を上回っていた1)4)。本研究でも有意に正答率の改善を認め,バージョンが改定されるごとに正答率は向上している。Open AI社によると,GPT-4はGPT-3.5に比較して,自然言語の認識と生成の向上がなされている(GPT-4 Technical Report https://cdn.openai.com/papers/gpt-4.pdf)。そのために,学習データを増加させ,また不正確もしくは無意味な解答(このような現象をAIの幻覚と呼ぶ)の低減を目指したとされる。GPTのパラメータ数は,GPT-3までで1750億8),非公式ながらGPT-3.5では3550億に対し,GPT-4では非公式ながら1兆を超えると言われており(GPT-4 architecture, datasets, costs and more leaked https://the-decoder.com/gpt-4-architecture-datasets-costs-and-more-leaked/),このことはChat GPT-4がより多くの内容を学習したことを意味するものである。また,AIの幻覚に対しては,その原因としてOpen AI社は次の3点を挙げている(Introducing ChatGPT https://openai.com/blog/chatgpt)。1)学習データはWebサイト・書籍・論文など多岐にわたり,中には誤った情報も存在し,そのようなデータに基づく解答は誤ったものになる。2)望ましい解答は,人間の知識ではなくモデルの知識に依存するので,人間の評価者による教師あり学習では誤った解答が導かれる可能性がある。3)解答を正確かつ有益な情報のみ解答できるように制限をかけると,正しく解答を行うことができたはずの解答を有益ではない,正確ではないと判定してしまい解答できなくなる場合がある。GPT-4では,完全には除去しきれていないものの幻覚を抑制する手法がとられている。Kung THら2)によると,GPT-4による解答はGPT-3.5におけるものよりも解答内容の矛盾が減っているといいう。GPT-4におけるこれらの改良点が,正答率の上昇につながったものと思われる。Open AI社によるテクニカルレポートでは米国司法試験における正答率がGPT-3.5では下位10%相当に対しGPT-4では上位10%に入る正答率であったと報告されている。
Chat GPTは医療用に特化した人工知能(Artificial Intelligence: AI)ではなく,入力内容に対して対話形式で解答を作成する汎用のAIである。本研究で示したような低い正答率,これまで知られているような不正確な解答が生まれる可能性から,現時点では実臨床における診断に用いるには適さないと考えられる。今後学習データ量の増加,バージョン改定によっては正答率の上昇が期待される。その他Chat GPTの医学への応用として,Sohail SSら9)は,文章の要約が可能であることから患者と医師の診察のやり取りの内容,患者の病歴の要約など医療記録管理の合理化の可能性や,研究分野における文献検索と内容の分析により大量の情報から必要なリソースの抽出など研究に用いる時間の短縮などが提案されている。Kung THら2)のUSLMEに対する研究では,解答の内容の評価を行っており,矛盾の低さから学習におけるプロセスモデルになる可能性を示唆している。Ayers JWら10)による医師への質問フォーラムに投稿された質問に対するChat GPTの回答と医師による回答の評価を行った研究では,内容の質がChat GPTの方が高く評価された報告もされている。解答の文章量や質問者への共感などを評価しており,患者への回答文の作成に役立つ可能性を示唆している。
問診から得られる情報と検査所見を複合して診断に至るめまい診療において,入力された情報から回答を導き出すChat GPTは役立つ可能性があるものの,現時点では実臨床においては応用が難しいと思われる。なお本研究は,めまい平衡領域に限ったが,耳鼻咽喉科の他の分野においては明らかではない。今後,他の領域に対する検討も必要であろう。
利益相反に該当する事項はない。
生成AIの利用について:今回の研究において生成AIによる問題に対する解答を評価するためOpen AI社より公開されているChat GPTを用いた。