ユーザのWEB 検索やコンテンツ閲覧履歴等を利用した情報推薦に関する技術が数多く研究されている.このような技術では,一定量の履歴が蓄積されるまで推薦精度が向上しないCold-start という問題がある.特に飲食店等のスポットの推薦に目的を絞ったスポット情報閲覧履歴の分析では,一般のWEB 検索などに比べ利用頻度が少ないため履歴の蓄積が進まず推薦精度が向上し難い.本論文では,スマートフォンの普及等により,ライフログの一つである継続的なGPS 移動履歴の収集が容易となっていることを利用して,スポットの推薦精度を向上させる手法を提案する.提案法では,GPS 移動履歴からユーザ行動範囲を抽出し,インターネット等からユーザ行動範囲のスポットのデータを収集し基準となる分布を算出する.統計的仮説検定の考え方を利用し,この分布との比較により,スポット情報閲覧履歴と,GPS 移動履歴を特徴化し,複数の検定結果を組み合わせるStouffer’s Z-score method により統合し解析する.飲食店推薦を対象とした実環境での実験を行い提案法の有効性を示した.
近年,ユーザの嗜好や状況等に合わせた情報推薦や検索を行うサービスが多く提供されている.これは,インターネットの発展に伴い,ユーザが大量のデータを利用できるようになったため,適切なデータを見つけることが難しくなっているためと考えられる.例えば,飲食店については,総務省調査による総飲食店数との比較から,90%程度である60 万件以上の店舗が既にインターネット上の各種サイトに登録されていると見られ,それぞれに対して口コミ等により詳細な情報が日々追加されている(総務省, 2007; 食べログ, 2011).実際に,ユーザが設定した嗜好情報等の検索条件と,ユーザの現在地点をGPS 等で取得し周辺店舗のデータを提示するサービスが,ぐるなび,ホットペッパーグルメ,食べログ等の主要な飲食店ガイドサービスにおいて提供されている.

しかし,ユーザが,自分の嗜好に合った店舗データを得るために,ユーザ自身が設定した嗜好データ等の検索条件を手入力することは,インターネット上のデータが大量,詳細になるにつれ,過大の負担を強いることになる.
また,モバイルインターネットの普及によりスマートフォン等による情報検索も増え,画面に一度に表示できるデータの少なさ,検索条件入力の困難さから,ユーザの嗜好を履歴から把握する技術のニーズは,ますます高まっている.
これらのため,ユーザのインターネットにおける閲覧履歴等を分析することで情報推薦や情報フィルタリングを行う技術が数多く研究されている.このような研究では,大量のデータから,ユーザの嗜好等に一致する情報を精度よく取り出すことを目指している.しかし,従来の技術では,一定量のユーザ履歴を蓄積するまで推薦精度が向上しないCold-start という問題がある.この問題により,ユーザのサービス利用初期に,適切な推薦が行えず,満足度が上がらないことから継続利用されないため,履歴の蓄積が進まない.この結果,推薦精度の向上が長期化しサービス普及が進まないことは,情報推薦サービス提供者にとって重大な問題である.
特にレストラン検索等のためのスポット情報推薦では,目的を絞っていることから一般の情報推薦に比べ利用頻度が低いため,収集できる閲覧履歴量が少なく精度が向上し難い.このため,スマートフォンの普及等により継続的な収集が容易となっているGPS 移動履歴と組み合わせた分析を考えることができる.ただし,表1 の通り,GPS 移動履歴は,市街地・屋内等で測位誤差が大きく,GPS 移動履歴単独での訪問飲食店傾向分析による嗜好の推定には限界がある.しかし,スポット情報閲覧履歴と組み合わせて分析する場合には,補完関係を持ち推薦精度を向上することが期待できる.この補完関係は,共通の対象であるスポットに対して「情報閲覧」と「訪問」という別の行動種別を分析対象できることによる.特に,情報閲覧し且つ訪問するという行動履歴を利用できれば,ユーザの嗜好分析において大きな価値を持つと考えられる.
本論文では,GPS 移動履歴とスポットに関する情報閲覧履歴を組み合わせた分析により,スポットの推薦精度を高めた手法を提案する.
ユーザによるWEB ページや画像等のコンテンツ(以降,アイテム)の閲覧履歴,検索履歴を利用した情報推薦技術は数多く研究されているが,これらの取り組みで,少ない履歴量での推薦,すなわちCold-start 問題への主な対策について述べる.
まず,閲覧履歴,検索履歴を基にした情報推薦技術は,メモリベース法と呼ばれ,協調フィルタリングとコンテンツベースフィルタリングに大別される(神嶌, 2007).この2 つの方法のうちで,アイテムにカテゴリ等を示すタグを付与することができる場合は,コンテンツベースフィルタリングがCold-start 問題に強いといわれている.
このため,履歴の蓄積状況など,一定の条件で,この2 つの技術を切り替える方法がある.さらに,この2 つの方法を混合する方法が研究されている.Burke によるEntreeC は飲食店の推薦システムである(Burke, 2002).本システムは,最初の段階では,価格帯やグルメジャンルなど,希望する条件のユーザ入力を用いて,コンテンツベースフィルタリングで候補となるレストランを選び出す.その後,協調フィルタリングによって,候補の順位付けをする.この方法では,一定の推薦精度を早い段階で実現できるが,候補の絞り込みのための飲食店の希望条件をユーザ手入力に依存している.このため,候補が多い場合の推薦精度の向上には,順位付けのため履歴の蓄積が必要となる.つまり,この方法は,多くの候補が存在するわりに履歴の蓄積が少ない,飲食店推薦等の応用分野では,十分とは言えない.
少ない履歴量で利用できる,他の推薦方法として,事前に多数のユーザの履歴を収集し,その履歴からユーザのクラスタを作成しておき,新規ユーザに対して,少ない履歴においてもクラスタに分類して推薦する方法がある(Xue, Yang, Xi, Zeng, Yu, & Chen, 2005; 神嶌, 2003).この方法では,アイテムへの閲覧パターンが類似しているユーザのクラスタを作成し,新規ユーザについて履歴パターンが近いクラスタを見つける.このクラスタ内のユーザのアイテムに対する平均評価値等をもとに推薦する.関連する方法として,ユーザではなくアイテムをクラスタリングする方法(Connor & Herlocker, 1999) や,ユーザとアイテムを同時にクラスタリングする方法(George & Merugu, 2005) などがある.このようなクラスタによる方法では,ユーザを分割するクラスタ数で推薦の性質が大きく変わる.少ない履歴量を考える場合は,クラスタ数を小さくすることが一般に有利だが,クラスタ数が小さくなるにつれ,個人差への適応性が失われることが問題となる.なお,推薦サービス提供側としても,この問題により,推薦結果の画一化が進み,一部店舗への推薦による誘導の集中などが発生するため望ましくない.また,このような方法においても,閲覧履歴のみを利用する場合には,履歴量の制約は残るため,多くの候補が存在するわりに履歴の蓄積が少ない,飲食店推薦等の応用分野では,十分とは言えない.
これらのアプローチによって従来研究では,少ない履歴量で,汎用的に高い推薦精度を実現することには困難さがあるといえる.このため,比較的ユーザ負担なく収集可能なGPS 移動履歴を分析対象に加えた,スポットの推薦が考えられる.
GPS 移動履歴単独からの嗜好や属性を推定する研究として,Fujita et al. が,GPS 移動履歴から抽出した近接するスポットから,統計的に特徴を抽出することでユーザの嗜好を推定する方法を提案している(Fujita, Morishita, Minami & Mizuta, 2010).また,Xiao et al. は,GPS移動履歴から抽出した近接したスポットの時系列パターンから,ユーザ類似度を分析する手法を提案している(Xiao, Zheng, Xie, Luo, & Ma, 2010).屋内での移動履歴に対しては,松尾・岡崎・中村・西村・橋田・中島(2006) により,近距離センサとの近接頻度から,嗜好や属性を推定する研究が行われている.
このように,GPS 移動履歴の分析手法が提案されているが,情報閲覧履歴と統合して分析する方法はない.この統合分析を実現するためには,GPS 移動履歴と情報閲覧履歴の違いを考慮する必要がある.代表的なメモリベースのコンテンツベースフィルタによる推薦手法であるRocchio法では(土方, 2004; Rocchio, 1971),履歴で出現したアイテムに付与されたタグの合計数をベクトル化してユーザプロファイルとし,推薦対象のアイテムに付与されたタグによるベクトルとの類似度順で推薦を行う.なお,この合計数については,TF-IDF などで重み付けした値とすることが多い.つまり,履歴で特徴的な出現をするタグには,ユーザの嗜好や興味があると考えて推薦を行うことが従来から行われてきた.しかし,閲覧履歴では,ユーザが選択したアイテム(スポット)の特徴を分析することができるが,GPS 移動履歴では,ユーザが訪問したアイテム(スポット)はGPS の誤差等により知ることができないことが問題となる.たとえば,単純にGPS 移動履歴との近接によりアイテム(スポット)を抽出する場合は,大量のユーザの嗜好に無関係なアイテム(スポット)が分析対象となってしまう.
また,行動履歴の分析においては,プライバシーや個人情報保護の観点が重要であることが広く指摘されている(総務省, 2009).この観点でも,コンテンツベースフィルタリングは,他ユーザとの比較等を行わず各ユーザ履歴のみを分析するため,データ管理,及び履歴利用のユーザ許諾を得ることが比較的容易という利点がある.
本論文では,メモリベースのコンテンツベースフィルタリングにおいて,スポット情報閲覧履歴とGPS 移動履歴を,それぞれ分布と見なし,複数の統計的な仮説検定として統合解析する方法を検討する.
提案法の基本的な考え方は,詳細閲覧履歴にある飲食店と,GPS 移動履歴から抽出できる近接店を,ユーザ行動範囲内の店集合からの,ユーザによる標本抽出であると見なすことに基づく.この時,各店に付与されているタグ(グルメジャンル等)の出現数と,無作為抽出による出現数との乖離を計算する.出現数の乖離が大きいタグは,ユーザの嗜好と関連していると考え,推薦に利用する.
以降の3.2 節~3.6 節で嗜好学習処理の詳細を述べる.つぎに,3.7 節で飲食店推薦処理の詳細を述べる.
3.1. 想定する環境提案法のシステム構成と,処理の入出力データについて述べる.なお,提案法は,飲食店情報推薦以外への適用も可能であるが,本論文では,飲食店情報推薦を具体例とした実験と評価を行う.また,簡略化および各ユーザの履歴データのみを分析対象とすることを明確化するため,1 ユーザの推薦を対象とした場合のシステム構成を示す.
システム構成を図1 に示し,入出力データについて表2 に示す.システムは携帯端末と推薦サーバからなる.飲食店推薦処理では,推薦サーバが,携帯端末からの要求に対して,飲食店DB から読み出した要求で示された条件に適合した店データの集合について,嗜好DB から読み出したユーザ嗜好との合致度順にソートした推薦リストを返す.飲食店DB と推薦リストのデータ項目のうち,「概要」は店の概要紹介文等のデータであり,「詳細URL」は,メニューや地図等のより詳細なデータを確認するためのWeb サイトへのリンクである.また,ユーザ推薦要求と飲食店DBの「タグ」は,各飲食店のグルメジャンル,駐車場有無等の属性である.嗜好学習処理では,推薦リストをもとに,ユーザに推薦順に各店の概要を提示し,詳細を確認するために閲覧した店のURL履歴である詳細閲覧履歴と,携帯端末にて継続的に収集したGPS 移動履歴を利用する.嗜好学習処理の分析結果は,嗜好DB に保存する.


GPS 移動履歴からユーザの行動範囲を分析し,この行動範囲内の店舗群である参照飲食店集合を抽出する.参照飲食店集合は,ユーザ毎に1 つ抽出する.抽出方法は,収集した各ユーザのGPS 移動履歴について,全測位点の重心を計算し,その重心から各測位点が含まれる距離d を計算する.なお,一般に飲食店データとして,高度情報は得られないことが多いため,d はスカラー値とし二次元空間上での処理とする.この距離d を半径とし,計算した重心を中心点とする円エリアを参照エリアと呼び,参照エリア内に存在する飲食店を参照飲食店集合とする.なお,参照飲食店集合は,ユーザが訪問する可能性が高いエリアにおける無作為抽出によるタグの出現数の分布を得るため円エリアとした.
3.3. 詳細閲覧履歴の分析詳細閲覧履歴に出現する店に関して,各店が保持するタグの合計数について,参照飲食店集合から無作為抽出した場合との乖離を確率として算出する.
3.3.1 閲覧チャンクの抽出後述のGPS 移動履歴との統合解析を考慮した乖離の算出のため,詳細閲覧履歴から,閲覧時刻の近さをもとに詳細閲覧のまとまりを抽出する.このまとまりを閲覧チャンクとよぶ.具体的には,あるユーザの詳細閲覧履歴が多数ある場合に,各履歴の前後一定時間以内に別の履歴がある場合は,これら履歴を同じ閲覧チャンクとしてまとめる.この処理を,時系列に順次行うことで,詳細閲覧履歴から閲覧チャンク群を抽出する.なお,一般に,ユーザの情報閲覧は,一定の時間に連続的に行われる.この時,一連の情報閲覧の中で,各詳細閲覧店の選択には,他の詳細閲覧店との関係も存在すると考えられるため,閲覧チャンク化による分析は推薦精度向上への寄与が期待できる.
本論文では,この一連の閲覧行動と見なす一定時間の閾値を経験的に30 分とする.なお,4 章で示す実験においては,閾値の30 分を,1 時間,2 時間と変えた場合でも抽出できる閲覧チャンク数は変化しなかった.
3.3.2 無作為抽出からの乖離指標算出前節で抽出した各閲覧チャンクを,参照飲食店集合からの標本と捉え,タグi の閲覧チャンクj における参照飲食店集合からの無作為抽出に対する乖離の指標を,
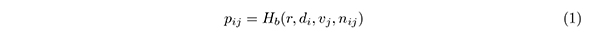
とする.ただし,

とし,r は参照飲食店集合内の飲食店数であり,di は参照飲食店集合内のタグi が付与された飲食店数である.vj は閲覧チャンクj 内の出現飲食店数であり,nij は閲覧チャンクj 内でタグi が付与されている飲食店数である.なお,r,di,nij の各数値は,図1,表2 の飲食店DB から読み出して算出する.ここで,数式Hb(r,di,vj,nij) は,各タグi について超幾何分布により参照飲食店集合からvj 店抽出した時にタグi が付与されている飲食店数がnij 個以上となる確率を算出している.つまり,Hb は,タグi について閲覧チャンクj よりも極端な事象が起こる確率を算出しており,「参照飲食店集合からの非復元抽出で,タグi の出現数が無作為抽出での出現数と同じである」という帰無仮説に対するp 値に相当する.たとえば,10000 件の参照飲食店集合で,タグx が1000 件に付与されている環境で,ユーザが6 件の飲食店を閲覧し,内3 件にタグx が付与されていた場合のHb は0.02,2 件であれば0.11,1 件であれば0.47 となる.一般に,履歴データからは,多数のチャンクを抽出できることから,各チャンクの本指標値を統合解析することで定常的な嗜好を分析する.特に,次節で説明する通り,GPS 移動履歴についても同様の指標値を算出することができるため,データ形式が大きく異なる異種履歴について統合解析が可能となる.
3.4. GPS 移動履歴の分析 3.4.1. 滞在チャンクの抽出ユーザが飲食店を訪問している可能性が高い時,一定時間,一定範囲に留まるGPS 移動履歴が得られる.本論文では,このようなGPS 移動履歴を滞在チャンクとよぶ.滞在チャンクの抽出には,GPS 測位点にしばしば現れる外れ値や測位結果の変動を一定程度排除するためDBSCAN法を利用する(Ester, 1996).DBSCAN は,分析対象点群について距離の閾値Eps と近接対象点数の閾値MinPts という二つのパラメータで決定される,接続関係(DDR)で連結される群を求める手法である.ただし,本論文では接続関係の探索を時系列に限定し,連結が抽出できた場合には,始点と終了点の間の時間間隔を計算し,一定時間を超えた群を滞在チャンクとする.その際,初めの時刻を滞在開始時刻,終わりの時刻を滞在終了時刻とする.
得られた滞在チャンクに属するGPS 測位点の重心を中心点とし,一定距離内に存在する飲食店を,図1,表2 の飲食店DB から抽出する.抽出した飲食店を滞在チャンクにおける訪問可能性飲食店とする.なお,この一定距離のパラメータは使用するGPS 機器の測位精度や,履歴の特徴等により決定する.本論文では,一定距離のパラメータは表1 の結果及び,事前実験等から50m とする.
3.4.2. 無作為抽出からの乖離指標算出抽出した各滞在チャンクにおける訪問可能性飲食店を,参照飲食店集合からの標本と考え,タグi の滞在チャンクk における参照飲食店集合からの無作為抽出に対する乖離の指標を,


とする.ただし,

とし,sk は滞在チャンクk の訪問可能性飲食店数であり,nik は滞在チャンクk でタグi が付与されている訪問可能性飲食店数である.
なお,各滞在チャンクの分析については,訪問店は原則1 店であると考え,式(4)では,タグiが訪問可能性飲食店に1 つ以上含まれている場合のみの,無作為抽出との乖離を算出する.
3.4.3. 時刻による飲食行動可能性より高精度なスポット推薦のためには,推薦対象のスポット種別に訪問している可能性が高い滞在チャンクの影響を強く考えることが適切である.各滞在チャンクは,滞在開始時刻と滞在終了時刻を持つため,時刻を考慮した重要度を算出し分析に利用する.本論文では,特に飲食店推薦を目的とすることから,時間帯別の食事行動率のデータ(図2)を用意し,各滞在チャンクの滞在開始時刻から滞在終了時刻までの食事行動率の平均値を,滞在チャンクk の重要度wk とする.このwk について,本論文では,総務省統計局の社会生活時間調査の値を利用する(総務省, 2006).
3.5. 詳細閲覧後の訪問分析詳細閲覧後にユーザが実際に飲食店へ訪問した可能性を分析に反映するため,閲覧チャンクに出現した飲食店と,滞在チャンクで訪問可能性飲食店の共起について,ここまでの各履歴への分析と同様に無作為抽出した場合との乖離を確率として算出する.
3.5.1. 飲食店共起の抽出各閲覧チャンクに出現した飲食店が,閲覧時刻から滞在開始時刻が一定時間以内の滞在チャンクにおいて,訪問可能性飲食店として出現した場合に共起飲食店として抽出する.本論文では,提案法の適用を想定するサービスとして,スマートフォン等のモバイル向けを想定するため,外出先等での食事のための飲食店検索を想定し,閲覧後のこの一定時間を24 時間とする.
この共起飲食店は,ユーザが詳細閲覧した飲食店データを契機として訪問した可能性があると考えられる.ただし,当該時間内に繁華街等で頻繁に滞留し,多数の飲食店に近接して,偶然共起した可能性を排除する必要がある.このため,各共起飲食店が,一定期間内の滞在チャンクで訪問可能性飲食店となったことの珍しさを,参照飲食店集合からの無作為抽出との乖離として指標化する.
3.5.2. 無作為抽出からの乖離指標算出閲覧チャンクの閲覧時刻から一定時間内の滞在チャンクの訪問可能性飲食店すべてを,参照飲食店集合からの標本と考え,タグi の閲覧チャンクj における飲食店共起に対する無作為抽出との乖離の指標を,

とし,vij は閲覧チャンクj におけるタグi が付与された詳細閲覧店数である.oj は,閲覧チャンクj の閲覧時刻から一定時間内の全滞在チャンクの訪問可能性飲食店数の合計であり,cij は閲覧チャンクj におけるタグi が付与された詳細閲覧店で,閲覧時刻から一定時間内の滞在チャンクの訪問可能性飲食店として共起した数である.
3.6 嗜好スコア算出ここまでに算出したpij,pik,picj を


により統合解析し,各タグi に対するユーザの嗜好スコアZi とする.このZi が大きいほど嗜好が強いと考える.J は,閲覧チャンクの総数であり,K は滞在チャンクの総数であり,wk は3.4.3 節で述べた滞在チャンクk の重要度であり,φ−1(p) は標準正規分布の累積分布関数の逆関数である.なお,式(6)は,Stouffer’s Z-score method に基づいており,各結合対象の重要度に対して,自然な形で重みを導入し確率を結合できる(Rosenthal, 1991).また,ξ(1 − p) において,φ−1 (p) > 0 では結果を0 とすることは,対象のチャンクにおいて,無作為抽出からの乖離がなく嗜好に関する特徴が得られなかったと考えるためである.
3.7 飲食店推薦処理本節では,飲食店推薦処理について述べる.飲食店推薦処理は,携帯端末からユーザ要求を受信したことを契機にして,候補飲食店集合を作成する.候補飲食店集合は,ユーザ要求で指定された条件,例えば地域条件として「X 駅から1km 以内」等に基づいて,飲食店DB を検索して作成する.候補飲食店集合の各飲食店について,次節で述べる飲食店スコアを算出し,降順にソートした結果を,推薦飲食店リストとする.これを携帯端末に返信することで推薦を行う.

飲食店スコアを,

にて算出する.r は候補飲食店集合の要素である飲食店の識別子とし,Z は, 各列i に3.6 節で算出した嗜好スコアZi を値として持つベクトルであり.Tr は,各行i に飲食店r にタグi が付与されている場合は1 を,それ以外は0 の値を持つベクトルである.
日本最大級のグルメ情報サイト『ぐるなび』,NTT コミュニケーションズ,およびNTT により共同実験を行い,提案法の評価を行った.本実験では,被験者に対し,スマートフォン(NTTdocomo SO-01B)を,グルメレコメンドサービスと履歴収集を行う実験用アプリケーションをインストールして貸与した.なお,実験用スマートフォンは,基地局情報を活用し測位精度を上げるAGPS にて位置測位を行う.実験に利用したグルメレコメンドアプリケーションイメージを図3 に示す.被験者は,グルメレコメンドサービスの主な利用者層を想定して募集したOL や会社員等の15 名で,各被験者に約30 日間普段の行動の一部として実験サービスを利用いただいた.また,各被験者から飲食店に関するアンケートを回収し推薦精度の評価を行った.
4.2. 収集データ本実験のために収集したデータは,詳細閲覧履歴およびGPS 移動履歴の被験者の履歴データ,飲食店DB の飲食店データ,推薦精度分析のための正解データとしての嗜好アンケートデータである.履歴データの収集量について,図4 で示す.図4 は,閲覧チャンクと滞在チャンク数について15 名の合計を実験開始からの経過日数毎に示している.閲覧チャンクは,実験期間の序盤と終盤に集中的に蓄積しているが継続的には蓄積されていない,一方,滞在チャンクは閲覧チャンクが蓄積されていない期間にも継続的に蓄積されていることが分かる.



飲食店データは,インターネットからの収集,事業者からの提供や購入によって得ることができる.提案法の分析に必要なデータの内容は,表2 で示したとおりである.今回の実験で利用した飲食店DB の飲食店数は,517712 件であり.タグは190 種類である.タグの例を表3 に示す.
嗜好アンケートデータは,多数の飲食店が存在する繁華街で,各被験者が共通に訪れたことのない地域(駅)をヒアリングにより把握し,当該地域(駅周辺)の110 件を評価対象飲食店とした.各評価対象飲食店について,被験者に店舗の概要文を提示して,「推薦されたら行きたいか」を,個々の店について回答いただいた.
4.3. 履歴データ特性評価収集した履歴データの特性について確認を行った.表5 は,各履歴から抽出した滞在および閲覧チャンクによる,分析過程の統計値である.総数としては,GPS 移動履歴がより多くのチャンクを抽出することができる.これは,GPS 移動履歴には,食事行動以外の行動も含まれているためである.しかし,この食事以外の行動による滞在チャンクは,嗜好の分析においてはノイズとなる.また,GPS 移動履歴では,チャンクに含まれる飲食店数の平均も高く,また標準偏差も大きくなっている.これは,繁華街等に滞在し無関係な飲食店が大量にあることがある一方で,食事以外の行動による滞在では,郊外等で周辺に飲食店が無い場合も多数あるためである.実際の外食では,ある1 つ店舗に訪問しているため,このような滞在チャンク内の大量の飲食店は,分析においてはノイズとなる.
このようなノイズにより,提案法で嗜好の強さを表現するZ 値は,情報閲覧履歴によるほうが平均値が高い.これは,想定どおりの結果である.つまり,GPS 測位誤差等により,実際の訪問店を分析対象にできないGPS 移動履歴では,ノイズとなるデータが多いため履歴量は多くとも分析結果として得られる嗜好情報は,情報閲覧履歴に比べ少ない.しかし,提案法により,情報閲覧履歴と統合分析可能な方法で,ノイズに相当するデータを無作為抽出として捉え,統計的に有意な特徴を抽出することで,一定の嗜好情報を得ることができるため,GPS 移動履歴の利用により推薦精度向上を期待できる.

推薦精度評価を行う従来法と提案法の条件を以下に示す.
Proposal
第3 章で述べた提案法である.
Proposal(Gps)
提案法において,GPS 移動履歴を利用した分析による方法である.この条件の結果から,提案法により,GPS 移動履歴から嗜好情報が抽出できているか確認する.なお,提案法は,情報閲覧履歴分析においても,GPS 移動履歴から抽出する参照飲食店集合を利用するため,情報閲覧履歴単独での利用はない.
CountUp(Browse)
メモリベースのコンテンツベースフィルタリングの従来法として,詳細閲覧履歴に出現した各飲食店にタグが付与されていた場合に,タグ種別毎の指標値ti を加算した累計をベクトルとして,評価対象の飲食店に付与されたタグによるベクトルとのコサイン類似度を飲食店スコアとする方法である(Baldi, Frasconi, & Smyth, 2003).なお,これは,Rocchio 法において,選択しなかったアイテムの影響度パラメータγ を0 とした場合と同等である(Rocchio, 1971).
この指標値ti,についてはタグが付与されている場合に定数「1」を加算する方法と,各タグi の詳細閲覧履歴における出現しやすさの違いを考慮するため,各店舗を文章と見なし算出したIDF(Inverse Document Frequency)値,1/ log( Ei),1/Ei で実験を行った.Ei は,飲食店DB におけるタグi が付与された飲食店の総数である.IDF 値は飲食店DB 全体を文書集合全体として算出した.なお,文書分類等ではTF やTF-IDF も広く利用されているが,今回の実験では,飲食店に対するタグを分析対象としているため,各飲食店について各タグの出現数は常に1 であり,文書長も無いことからことから評価を見送った.
評価結果では,ti として定数「1」を利用する場合が最も
CountUp(Gps)
GPS 移動履歴から抽出した訪問可能性飲食店(3.4 章参照)に付与されているタグを,加算対象とする方法である.
CountUp(Gps+Browse)
従来法によるGPS 移動履歴との統合解析方法として,詳細閲覧履歴に出現した各飲食店と,GPS 移動履歴から抽出した訪問可能性飲食店(3.4 章参照)に付与されているタグの双方を,加算対象とする方法である.
RandomSort
候補飲食店集合の各店舗を無作為にソートする方法である.例えば,「現在地から1km 以内」等を条件とした検索で,ユーザによる嗜好や条件入力や,他の推薦手法がない場合は,この方法と同じといえる.なお,後述4.6 節の評価では期待値を利用する.
4.5. 推薦精度の評価指標精度評価の指標として,各比較手法による評価対象飲食店110 件の推薦順に対して,情報検索の分野で多く利用されている順位を考慮した適合度指標であるnDCG(normalized DiscountedCumulative Gain)を算出した(Jarvelin & Kekalainen, 2002; Manning & Raghavan, 2008).nDCG を採用した理由は,本技術の適用先として想定する携帯端末(スマートフォン等)向けグルメレコメンドサービスでは,一度に表示できる情報量が少ないため,嗜好との合致度順に提示できることが重要であるためである.nDCG は,


とする.IDCG(n) は,上位n 位が理想的な順番で並ぶ最大のDCG 値とする.n は,推薦順位の上位n 位までを評価することを示し,今回の実験では,被験者ヒアリングにより得た推薦結果に対する平均的な確認範囲を反映してn = 32 とした.i は推薦順位を表す,g(i) は,推薦順がi位となった飲食店に対する被験者アンケートの回答から表4 の通り値を決定した.
なお,表4 において「行きたい」側の選択肢が多い理由は,提案技術の適用先であるグルメレコメンドでは,「行きたい」店舗を推薦することが目的のため,より精緻を収集したためである.また,表4 において「まあまあ行きたい」と「どちらでもない」の間のnDCG 入力値g(i) の値の開きは,事前の被験者ヒアリングにより,飲食店推薦の満足度には,「行きたくない」飲食店の推薦を如何に減らすかが重要であることが判明したため,評価の低い飲食店が上位となる場合のnDCGの減衰を大きくするためである.ただし,結果が表4 の定義に依存しないことを確認するため,g(i) をシンプルな降順(5,4,3,2,1) の結果も確認した.
4.6. 履歴量による精度影響評価各比較条件による被験者平均のnDCG と履歴量(履歴収集期間)の関係を図5 に示す.本実験では,Cold-start 問題を解決すべき履歴量として,一ヶ月という心理的な区切りと,多くのサービスで初月利用のキャンペーンがある等から30 日間とした.図5 から,提案法によるGPS 移動履歴と情報閲覧履歴の統合解析により履歴収集開始初期から,比較条件より推薦精度が高く,詳細閲覧履歴が少ない状況でも,より高い精度での推薦が可能であることが分かる.また,想定した期間である30 日後においては,明確な推薦精度の向上が見られる.これらから,Cold-start 問題に対して,GPS 移動履歴を加えて分析することは効果があることが分かる.なお,CountUpでは,定数「1」を指標値ti として加算した場合がIDF,1/ log(Ei),1/Ei による結果に比べ精度が高かった.このため,図5 ではCountUp の定数「1」を指標値ti とした場合の結果を示す.

また,図4 にて示したnDCG 入力値g(i) をシンプルな降順(5,4,3,2,1) にした場合でも同様の結果を得ることができた.
Proposal(Gps) については,従来法のCountUp(Gps) に比べて高い精度を実現しており,CountUp(Browse) に近い精度を実現している.これにより提案法の分析モデルにより,GPS移動履歴からユーザの嗜好を一定程度分析できていることが分かる.
なお,履歴収集期間の中盤にてProposal(Gps) の精度が大きく落ちており,Proposal の精度もやや落ちている理由としては,まず,実験期間初期は,図4 からも分かるように,被験者が頻繁に実験アプリケーションを利用していることから,実験アプリケーションの推薦に従った外食も多く嗜好情報を得易かったと考えられる.また,この実験期間の中盤には大型連休があったため,多様で活発な移動が行われ,外食行動に関するデータ以上にノイズとなるデータが増えたためと考えられる.ただし,実験期間終盤には,滞在チャンク数が蓄積することで,Stouffer’s Z-score method により統計的な収束が進むことで,ノイズの影響が低減されることと,実験アプリケーションの利用頻度も増えたことにより,再び推薦精度が向上していると考えられる.
4.7. 分析処理時間評価提案法の実用性を確認するため,学習処理時間の計測と考察を行った.今回の実験条件では,2.8 GHz 4 コアのCPU(Intel 社Xeon),地理空間情報拡張を持つDB(PostGIS),Linux(CentOS)のサーバ環境にて,1 つの履歴チャンクあたり平均1.8 秒であった.実験における被験者の一日のチャンク数は平均2.1 個であったことから,分析結果の推薦への反映を24 時間以内とする現実的な前提で,本測定結果のサーバ環境でも,1 万人以上の収容が可能である.さらに,今回は単一サーバ且つシングルスレッドによる実装で評価したが,提案法は,タグ毎,チャンク毎に独立に計算するため,同時に必要なメモリ量が少なく,分散処理(マルチスレッド化)が容易な特徴を持つため高速化の余地は大きい.この結果から,十分実用的と考えられる.
GPS 移動履歴と情報閲覧履歴の統合解析に基づいたスポット推薦手法を提案した.具体的には,飲食店の推薦を対象に実験及び評価を行い,より少ない情報閲覧履歴での推定精度の向上から提案法の有効性を確認した.
また,提案法は,今回評価を行った飲食店以外にも,スポット情報閲覧し実際に訪問するケースにおいて,様々なスポット種別の推薦に対して利用が可能である.例えば,週末等の余暇の訪問スポットの推薦が考えられる.公園,遊園地,動物園,各種ショッピング施設,ゲームセンター,カラオケ等について,評価,属性,設備等をタグとしてDB 化することで,スポット情報閲覧とGPS 移動履歴分析により,ユーザの好みに合ったスポットの推薦を実現できる.その他,宿泊施設・旅行情報検索,観光地ガイドサービス,不動産情報検索,結婚式場情報検索などの応用が考えられる.
今後の課題としては,提案法が,履歴をチャンクとして分割して分析することを活かして,チャンク毎のコンテキスト(天気,気温,各チャンクの前後関係等)を分析に反映することを検討する.さらに,提案法を拡張し,統合解析対象の履歴及びデータ種別を広げ,ブログ,メール,スケジューラー等の多様なライフログデータとの統合解析による分析の高度化を検討する.また,実サービスへの展開に向けて有用性を高めるために,大規模な飲食店DB 利用時にはボトルネックとなる地理情報処理の効率化,分析の分散処理対応を検討し処理効率化を行う.