論文
情報ソースの種別を考慮した記事の特徴分析
2016 年 5 巻 1 号 p. 49-66
詳細
2016 年 5 巻 1 号 p. 49-66
将来に生起するであろう事象をインターネット等に存在する情報ソースをもとに予測する研究は多数なされているが,情報ソースの多様性などから単一ないし少数の情報ソースで事象を説明や予測している場合が多い.しかし,内容的に異なる大量の膨大なデータを利活用して予測するという点からは,十分な研究がなされていない.このような研究のためには様々な情報ソースの特徴や相互間の対応関係などの評価が必須である.そこで,本論文ではニュースについて事象の事実を伝える情報ソース,各種ソーシャルメディアを事実に対する評価を掲載する情報ソースとして位置づけ,それら複数の情報ソースの数量的な特徴の把握と対応関係を明らかにする.そのための方法として,まずインターネット上の情報を分類し,その項目と主観的評価をもとにした分類を用いて対応関係などを明らかにする方法を提案する.また特徴のある項目を抽出する手法をも提案する.実データとしてトヨタ自動車に関する情報を分析した結果,個々の情報ソースが時系列的・内容的変化でよく特徴付けられていること,特徴ある変化を示す個別の項目が当該企業の状況を反映していることが明らかになった.
There have been a number of researches to predict future events with information sourceson the internet, and they mostly utilize single or few information sources for prediction. Onereason of the small number of information sources is because it is not necessarily appropriateto assume that plural information sources have identical features in terms of contentsand that prohibits dealing all the information sources equally. In order to utilize variety ofinformation sources on the internet as possible, it would be essential to extract differentialfeatures of information sources, and evaluate how they relate one another. This paper assumesthat news from major Japanese newspaper publishers represent business facts, andblog and message board (hereafter ’social media’) contain evaluation of business facts. Itthen introduces analytical framework to extract differential features of each of the informationsources. Specifically, this paper hypothesizes that differential features are added in thesocial media’s news quotation onto original news, and discusses how to extract the featuresin a numerical manner. It also discusses features can be at the level of information sourcesper se as well as at more granular taxonomy level. Entropy term-weighting and Naive-Bayesclassifier are adopted to categorize contents and singular vector decomposition is adoptedto extract the differential features. These procedures are applied to the data relating toToyota motors, and result of the analysis not only supports the hypothesis but also exemplifieshow differential features at granular taxonomy level represent the company’s currentcharacteristics.
将来に生起するであろう事象を予測することは重要であると考えられる.そのために分析として,一般社会で利用可能な情報ソースで説明するデータ分析の試みはこれまで多数なされて,一定の成果を上げている.例えば, Gilbert and Karahalios (2009) ではLivejournal.com という特定のブログサイトを情報ソースとしてS&P 500 の株式指数の説明を試みている.また, Tetlock(2007) はWall Street Journal column のデータでDow Jones Industrial Average などの指標の予測を実施している.インターネットの出現によって多種多様な情報ソースがより容易にアクセスされデータ分析で活用できるようになったことにより,このような情報ソースを利活用して予測しようとする研究も重要性を増している.
しかし,これまでの研究成果の多くは単一ないし少数の特定サイトを情報ソースとして説明を試みている.その理由として,インターネットには膨大で多様な情報ソースが存在し,その多くを情報ソースとして用いることは現実的ではないことがあるが,情報ソースで主として事実を記述するもの,発信者の個人的な評価を記述しているものなどの,情報ソースそれぞれに内容的な違いがあり,それらをどのように統合化すべきかなどの課題があるのでないかと考えられる.複数情報ソースそれぞれの特徴の違いを把握することができる場合,それらを説明に活用することは単一の情報ソースのみの場合に比較して,分析の範囲を拡げられる可能性がある.
このような各種の情報ソースをもとにした研究として, 吉田(1971) は情報の伝達過程の決定論的モデル,確率モデルなど多くの理論的模型を提示している. 石井・吉田・新垣・山崎(2007) はヒットという顕著な過渡期的な現象をそのときに人々の間でやりとりされる情報で説明付ける方法を提案している.また,文化の伝播のありようを局所的収斂とグローバルな分極化を伴った形で表現するエージェント・ベース・モデルが Axelrod (1997) により提案されている.
インターネット上にはソーシャルメディアなど多数の公開された情報ソースが利用可能になっているが,株価変化や利益予測などのビジネスの将来予測においては,それらの複数の内容的に異なる情報ソースを用いて予測することは行われていない.それは,複数の情報ソースそれぞれの特徴やそれらの相互間の対応関係が把握されておらず,ビジネス環境での意思決定に活用するためには情報として十分に統合されていないと解釈されているからであろう.しかし,情報ソースの特質について考慮すれば,ニュースとニュース以外の情報ソースをビジネス環境でも用いることができるのでないであろうか.ニュースは主として事実を伝えるもので,ビジネスの現況を説明していると想定することは妥当であろう.この点から,ビジネス事象の説明や将来を予測するために,ニュースを有望な情報ソースとして位置づけることもできよう.また,事実に対してどのような評価がなされているかを把握することも予測の観点からは重要である.自動車会社を例に取ると,自社製品の不具合に対応すべくリコールするというニュースが流れたとする.車の品質問題という内容で,不具合という否定的なニュースを受けて,そのまま否定的な品質問題として捉える人々もいれば,企業全体の真摯な姿勢として肯定的に捉える人々もいる.事実に対する評価を捉える重要性は,評価に応じてその後の評価者の行動に違いが出る可能性,評価される側のビジネス上の判断や行動に違いが出る可能性に求めることができる.この点から,ビジネス事象の説明や将来を予測するために,ニュースに対する評価なども含むことができるソーシャルメディアの利活用が重要であると言えよう.ニュースとソーシャルメディアの関係としては,ブログや掲示板で議論が開始され,それが一定程度の量や期間で存在することでニュースとして取り上げられるに至る過程も存在するなど,ソーシャルメディアからニュースへという方向も存在する.しかし,ニュースがソーシャルメディアの引用を明確にしている場合は少なく,相互間の関係を捉えることが困難な場合が多いため,今回は,ニュースが先に発生して,ソーシャルメディアへ波及するという方向のみを想定する.
本論文では,先ず,ニュースを事実を掲載する情報ソースとして,ソーシャルメディアを主としてニュース内容やそこでの事実に対する評価を掲載することができる情報ソースとして,それぞれの価値があると仮定する.この仮定を検証するために,複数の情報ソース間の関係がどのようになっているか,具体的にはニュースで論じられていることが他の情報ソースでどのように評価され,その内容の特徴付けがなされているかを数量的に捉えることで検証する.また,ニュースにも蓋然性が含まれる可能性や内容的に評価を含む可能性があるが,本論文では,ニュースは事実を掲載するものと仮定することで単純化を行う.また,分析結果に関して,ニュースに対するソーシャルメディアの追加的特徴の理解に関しても検討する.
この提案方法は,将来的にどのような応用分野へも適用可能であるが,株価などはビジネスの評価の変化がその変動に関係する可能性があり,この方面での応用を試みる.
ビジネス活動を説明するために提案するモデルで分析する記事の情報ソースとしてニュースの他に,ブログと掲示板を扱う.企業に対する評価を考える際にニュースは有用な情報ソースと考えられる.また形式面から分けるとブログと掲示板は対比的であり,近年MAB(Multi-AuthorBlog)という形式が出現しているものの基本的には1 箇所に1 個人の形式であるブログに対して,掲示板は1 箇所で複数人の対話や議論を行う形式である( Harman & Koohang, 2005).また,掲示板は主に特定のコンテンツに関する議論を目的としており,コンテンツに対するアクセス提供や再配布を主目的としているブログと対比することができる( Harman & Koohang, 2005).掲載箇所と参加人数の形式に限定して着目すれば,ブログと掲示板はソーシャルメディアが取りえる形式を代表するもので,本論文ではその形式の違いがニュースに対する反応の違いをどの程度説明するものか検討する.
ニュース,ブログ,掲示板の3 つの情報ソースすべてに於いて,1 単位のテキストを本論文では記事と呼ぶ.具体的にはニュースではひとつのニュース記事,ブログではひとつのブログエントリー,掲示板では1 スレッドの中の複数の書き込みの中の1 つを1 単位とし,それぞれを記事と呼ぶ.本論文の主目的は,複数情報ソースそれぞれの特徴を数量的に評価することであるが,より具体的には以下の仮説を置き,検討する.
• ニュース記事に反応して書かれたブログや掲示板の記事はニュース記事に内容的な特徴を加えている
• ニュース記事に反応して書かれたものに着目すると掲示板は特定のテーマに関して複数人が書き込む形態で他者の議論による制約を受ける.したがって,ニュース記事に対して加える内容的な特徴が個人の意見をそのまま表明できるブログに比べて小さい
しかし,掲示板とブログ間の関係については着目しない.
次に,あるニュース記事の内容や,それに対する掲示板やブログの記事に於ける反応の内容を捉える必要がある.ここで扱うデータはテキストデータである.ここではキーワード頻度のみではなく5W2H(Who, What, When, Where, Why, How, and How much)のような内容に関する要素をもとに分類することにする.特に,本論文では企業関連データを扱うことを想定し,以下の6 つの分類項目を設定する.
(1) 供給主体(ビジネスの場合は企業),
(2) 供給物(ビジネスの場合は製品・サービスの品質),
(3) 供給主体の需要主体への働きかけ(ビジネスの場合は販売活動),
(4) 需要主体の担うコスト(ビジネスの場合は製品・サービスの価格),
(5) 需要主体の担うベネフィット(ビジネスの場合は製品・サービスがもたらす便益),
(6) その他(上の5 つの分類項目に入りきらないもの)
上記は順にWho,What, How, How much, Why, Other に相当する.When に関してはニュース記事やソーシャルメディアの記事が掲載された日時とし,Where に関しては特にソーシャルメディアの場合地理的な概念を超えたサイバー空間に存在し,かつ,地理的な場所が企業関連の分析テーマに含まれている場合は供給主体や供給物にその内容が含まれることがほとんどであるため,着目しない.また,それぞれの項目に対して記事から判断する主観的評価として,肯定・否定・中立の3 つの状態を想定する.したがって,ある情報ソースの1 記事は,縦が分類項目,横が主観的評価である6 × 3 の行列の中で該当する特定要素に1,それ以外の要素に0 として表現される.この行列を本論文では評価行列と呼ぶ.
2.2. 分類のためのNaï記事を行列要素に振り分け判定をする手法には,大別すると統計的な手法とルールベースの手法が考えられる.分析する対象に通暁している場合は,ルールベースの手法を採用し網羅的にルールを作ることで正確性の高い判別をすることができる.その反面,ルールを作成する個人の知見に依存してしまうこと,複数人で実施する場合の一貫性に考慮を要する点,また作成・維持活動にかかる工数が大きくなりがちなことが問題点である.統計的な手法は,分析者や分析対象が異なっても同一な方法を維持することができ,正確性も一定レベルに維持できる点が優位点であると言える.そこで,このモデルでは,一般的な適用可能性が比較的容易な統計的な手法でも,最も簡潔な統計的手法として広範に採用されるNaï D j )が存在する際に特定カテゴリー( H i )に属するという可能性 P ( H i | D j ) は以下の条件付確率で表される.
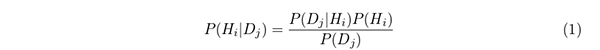
P ( D j ) はすべてのカテゴリーに対して共通で相対的な確率の大小には影響を与えないため無視できる.
Naï P ( H i | D 1 , . . . , D J ) を導くもので,以下のように尤度 P ( D j | H i ) を掛け合わせたものに事前確率 P ( H i ) を乗じたものに比例する.
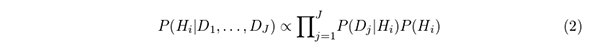
Naïï Domingos and Pazzani (1997) は多くの分類器の中でもNaï
2.3. 評価行列の作成「情報ソースと分類」の節では,ある記事を分類項目× 主観的評価に割り振るとした.その割り振りのために,初めにトレーニングセットとして情報ソースからいくつかの記事を抽出し,それらを複数人による作業で分類項目× 主観的評価に分類する.次に,トレーニングセットから形態素解析をして語を抽出した上で,語の重みを計算し重みが一定以上の語をNaï P ( H i ) や尤度P( D j | H i ) を求めておく.最後に,トレーニングセット以外のデータを形態素解析し,Naïï
語の重み付けには文章長も考慮したBM25 法が用いられことが多いが,ここでは,ブログや掲示板は監修されていない個人の意見の表明であると考え,その文章長自体も情報をもっていると捉えtf-idf を元にしたEntropy による方法を採用した. Dumais (1991) はTerm frequency, GfIdf,Idf, Entropy などの各種手法で語の重みを付けた上での情報検索の正確さを比較し,Entropy はTerm frequency より30%正確性を向上させ,最も正確性向上に寄与した語の重み付け手法であったという分析結果を示している.また, Sekar (2011) は文書の中から経営リスクなどに関する記述内容を検出する上で同様に各種の語の重み付け手法を比較し,Entropy とGfIdf が最も良い結果に貢献したとしている.Entropy で語句の重み( w i )を計算するに際し, N を全体の文書件数, f i,j をある語句( i )の特定文書( j )に於ける出現頻度とし,それを文書群全体での語句出現頻度(Σ l f i,l )で標準化する. f i,j = 0 の際はlog(.) は0 としている.ある語句の文書群全体に於ける出現数を逆数にしており,ある語句が特定文書にどれだけ偏在しているかを指標としている点が特徴的である.
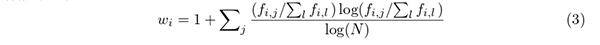
本論文では実際に広く利用されているSAS Institute 社のText Miner に実装されているEntropyの指標を用いた.以上の処理により,ある1 つの記事は,縦が分類項目,横が主観的評価である6 × 3 の評価行列の中で該当する特定要素に1,それ以外の要素に0 として表現される.
本論文はニュースに対する評価としてのブログや掲示板がニュースにどのような内容的な特徴付けをしているかを見ることを大きな目的としており,ブログと掲示板に関してはその記事がニュースに反応しているものか否かを区別する必要がある.また分析テーマに沿って情報ソースから収集してきた記事の中には,そのテーマの中心的な題材に沿っているものと,それに付随する中心的でない題材に関するものがあるため,記事の内容がテーマに照らして中心的か・そうでないかを区別する必要もある.このことを考慮すると,評価行列は,ニュース(1 つ),ニュースに反応し中心的なテーマの内容を持つソーシャルメディア(ブログと掲示板の2 つ),ニュースに反応し中心的なテーマでない内容のソーシャルメディア(同2 つ),ニュースと無関係なソーシャルメディア(同2 つ)の計7 つのテーマ別に対応して求められる.ニュース記事の中で他のニュースの引用をする・しない,ニュースの内容が中心的・中心的でない,という区別も可能であるが,過度に複雑なモデルにすることを避けるため,ニュースはそれ以上の区別をしないこととする.以上の7つを本論文の中では7 つのデータソースと呼ぶ.この7 つのデータソースを時点毎に作り,時系列的な変化を捉えることができるようにする.つまり,各記事への評価は7(データソース)×6(分類項目)×3(主観的評価)× 時点( t )数の4 元行列のある要素に対応付けられる.この4 元行列を N と表してその要素を
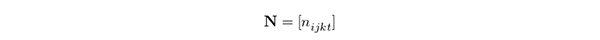
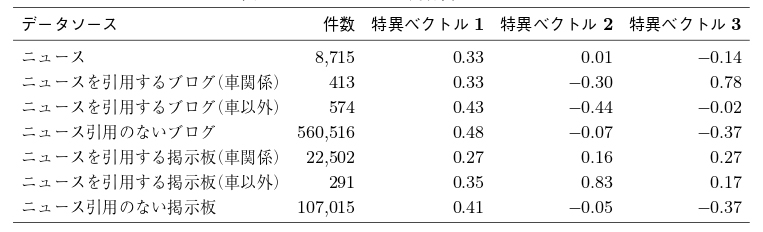
と表現する.ここで i はデータソース( i = 1, 2, . . . , 7), j は分類項目( j = 1, 2, . . . , 6), k は主観的評価( k = 1, 2, 3), t は時点( t = 0, 1, . . . , T )である.
2.4. 記事の影響に関する逓減行列 N をもとに分析するのであるが,過去のデータの影響を考慮して分析する必要がある.いま,時点毎のデータソースの個々の記事は分類され行列 N の要素の1 または0 として加算される.一方,ある時点 t での記事は t +1, t +2, . . . にも影響を及ぼす. Gilbert and Karahalios (2009)では影響する時点数として過去3 時点を用いているが,ここでも同様に d 時点の間継続するとして,また,データソースの記事が公表されてから徐々に影響力が逓減すると想定した.この d はデータとして存続する期間や,それが公表されてから通常人の記憶に残っている期間などから設定する.また,この影響は個々の記事ではなく,行列の要素 n ijkt により評価する.これは,個別の記事間の関係を捉えることは誤差が大きくなると考え,むしろ,合算された行列はある時点のデータソースと,分類項目をある程度安定して表現していると考えたからである.このようにその影響の減衰を踏まえた行列とし,
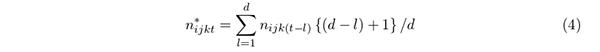
を求め,この行列 N∗ をもとに分析することにした.
2.5. データ分析行列 N∗ をもとにデータソースの特徴について分析することになるが,この場合2 種類の分析を考える.1 つの分析はニュース記事に反応して書かれたブログや掲示板の記事はニュース記事に内容的な特徴を加えている,などの先の仮説について検討するために,複数データソースの特徴を数量的に評価するものである.そのために,データソース( i = 1, 2, . . . , 7)に着目しそれを変数とし,それ以外の行列 N∗ の項目をケースとして行に対応させて,行列 N∗ を列方向がデータソースで行方向が分類項目× 主観的評価× 時点と並べて2 元行列へと変形する.データソースの特徴を捉えるために,この変形した行列に対して特異値分解を行うことにする.
もうひとつの分析は,将来予測などの場面での適用を考え,データソース× 分類項目× 主観的評価の変数から実際の適用に有効な変数を抽出する目的で,特徴的な変化を示す項目を抽出する分析である.そのために,その記述内容の特徴を捉える変数として列方向にデータソース× 分類項目× 主観的評価の組合せを配置し,時点をケースとして対応させて行方向に配置し2 元行列とし,特異値分解を適用することで列方向に展開した行列 N∗ の特徴を捉える分析である.
分析の適用のための対象としてはトヨタ自動車に関するニュースやそれに対する反応について分析する.当該企業はいち早くエコ・カーを開発・販売するなど先進的な話題を先んじて提供しており,ニュースに対する評価の変化を捉えるという本論文の狙いの一つをよく表現する題材であると考えられるからである.

本適用例で利用したデータの獲得源を表 1 に例示する.自動車に関するニュースへの反応を捉える目的で自動車に特化したブログを追加したことを除いては一般的なデータ獲得源を対象とした.また,データ獲得の便宜からインターネットからツールを用いてダウンロードする形を取った.
データ獲得に使ったツールはEffyis Inc. のBoardreader.com で,獲得時のキーワードは日本語・英語で表記揺らぎを考慮したトヨタ自動車の会社名表記とし,結果2010 年7 月から2012 年6 月までの2 年間データが212,447 件獲得された.キーワードの具体例は,表記揺らぎ等を考慮し「トヨタ自動車」,「トヨタ」,「TOYOTA」,「TMC」,「toyota」などである.
ブログや掲示板の記事が取り扱う内容が中心的なテーマか否かの判別に関して,ニュースを引用した上で企業の業績や自動車に関するキーワードが記事のタイトルに含まれているか否かで判断し,含む場合はその内容が中心テーマに沿っているとし(以降「ニュースを引用(車関係)」とする),含まない場合は中心テーマではないとした(以降「ニュースを引用(車以外)」とする).キーワードの具体例としては,「トヨタ」,「日産」(その他自動車各社,表記揺らぎ含む),「プリウス」,「インサイト」(その他各社主要ブランド),「エンジン」,「ハイブリッド」,「EV」,「リコール」(その他部位・技術・品質関係の関連語)などである.
3.2. ニュース引用の判定と記事公開時点の判定ニュースの引用があったかどうかの判定は便宜的な方法を取った.ブログの場合はニュースサイトのサイトアドレスをテキストの中で記述している場合に引用と判定した.掲示板の場合はスレッドが明確に特定のニュースに関して議論をする場であり,スレッドの中のすべてのエントリーが内容的には特定ニュースに対する反応であると考えられるとしても,個別のエントリーそれぞれがサイトアドレスを記述しているとは限らないことから,スレッドのタイトルにニュースに関することが記述されていた場合,そのスレッド内に記述されていることはすべてニュースへの反応であり,そうでない場合はニュースへの反応ではない,とした.具体的にはスレッドタイトルに「【ニュース】」,「【自動車】」,「【国内】」等々があるかどうかで判断した.
この便宜的な方法の妥当性であるが,ブログでニュースを引用する場合にサイトのアドレスを明記することは出所明示の原則で決まっており,サンプルで検証した結果,ニュース引用があると上記のロジックで判定した100 件の文書の記事の中で内容的に引用ではない,と考えられるものは1 件であった.同様に掲示板の引用があったとロジックで判定された120 件の文書を検証したところ,そのすべてが何らかの形でニュースのテーマに対して反応しているものと確認された.したがって本論文で引用ありとしたものは実際に引用があったと理解してほぼ問題がないと解釈した.逆にニュース引用がないとロジックで判断され,内容から引用ありと判断されたものはブログでは120 件中17 件,掲示板では120 件中7 件存在した.前者はツイッター(ミニブログ)で短縮されたアドレスで入力されていて元アドレスを復元できない,また膨大なブログ文字数の場合に全テキストを獲得できない,という2 つのデータ獲得ツール上の技術的原因によるもので,サイトアドレスをテキストで記述している場合に引用と判断するアプローチ自体は有効であると考える.後者に関しては,スレッドタイトルはニュースとは無関係と判断されるが,本文内にニュースサイトのアドレス記述がある,あるいは他のニュースに関係するスレッドのサイトアドレス記述がある,という2 つの場合があった.前者は技術的な改善,後者はアプローチの改善を図る必要があるが,本論文では「引用あり」の判定は正確で,「引用なし」の判定も概ね正しいとみなすことにした.
情報ソースの種類や中心的なテーマか否かの判別,ニュースの引用の有無の区分で得られる時点毎の7 つの行列は,ニュース,ニュースを引用するブログ(車関係),ニュースを引用するブログ(車以外),ニュース引用のないブログ,ニュースを引用する掲示板(車関係),ニュースを引用する掲示板(車以外),ニュース引用のない掲示板,となった.
記事が公開された時点の判定に使ったデータとしては,ニュースはニュースリリース日時,ブログはそれが掲載された日時,掲示板は各掲示板スレッドの中にエントリーが掲載された日時である.時点は日単位とした.また記事の影響の逓減に要する期間 d は28(28 日間,約1 ヶ月)とした. d = 28 としたのは,ニュースなどがネット上で公開されている期間が1 週間から1 ヶ月として設定されている場合が多いことからである.
3.3. Naï6 つの分類項目として,企業の評判(供給主体),車の品質問題(供給物),販売活動(供給主体の需要主体への働きかけ),車の価格や燃費(需要主体の担うコスト),車の使い勝手(需要主体のベネフィット),その他とした.また3 つの主観的評価は肯定・否定・中立とした.
その割り振りのために,トレーニングセットとして情報ソースからいくつかの記事を抽出し,それらを複数人による作業で分類項目× 主観的評価に分類する.ただし,分析テーマに関して高度な知見のある複数の人物が必ずしも存在するとは限らないことも考慮し(1) 分類項目ごとにキーワードを多めに準備,(2) キーワードマッチの頻度などで機械的に分類作業実施,(3) 機械的分類結果に対して再度分析者による調整,という手順を採用した.
Naï
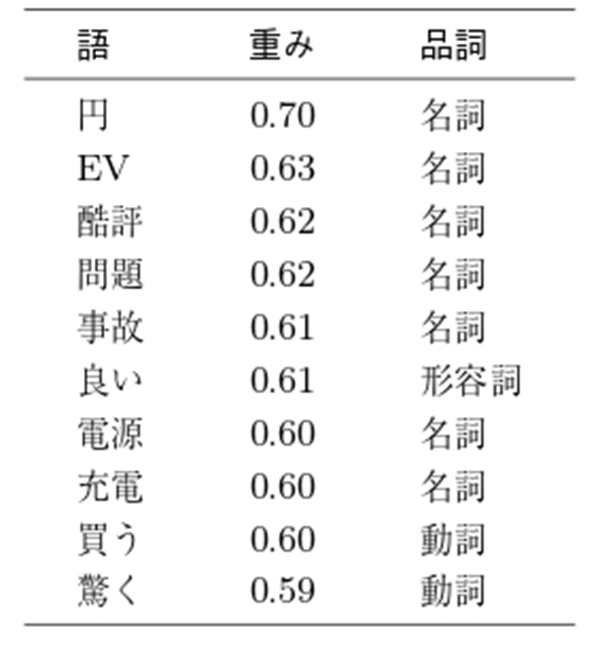
次に,トレーニングセットから形態素解析をして語を抽出した上で,語の重みを計算し重みが一定以上の語をNaïï 2 に呈示する.形態素解析のツールとしてはSAS Institute 社のText Miner を使用した.
また,トレーニングセットを用いて,6 つの分類項目,3 つの主観的評価の事前確率 P ( H i ) や尤度P( D j | H i ) を求めておく.最後に,トレーニングセット以外のデータを分類項目× 主観的評価に振り分けていく.第1 時点データを形態素解析した上でその語と表 2 の例のキーワードとの合致を求め,事前確率とキーワード毎の尤度で分類項目,主観的評価の各分類項目に所属する確率比を求めて最大の分類項目に機械的に所属させる.第1 時点データをすべて分類項目× 主観的評価に分類し終え,事前確率を更新した上で第2 時点データの処理に同様に取り掛かる.この処理を全ての時点に対して実行する.
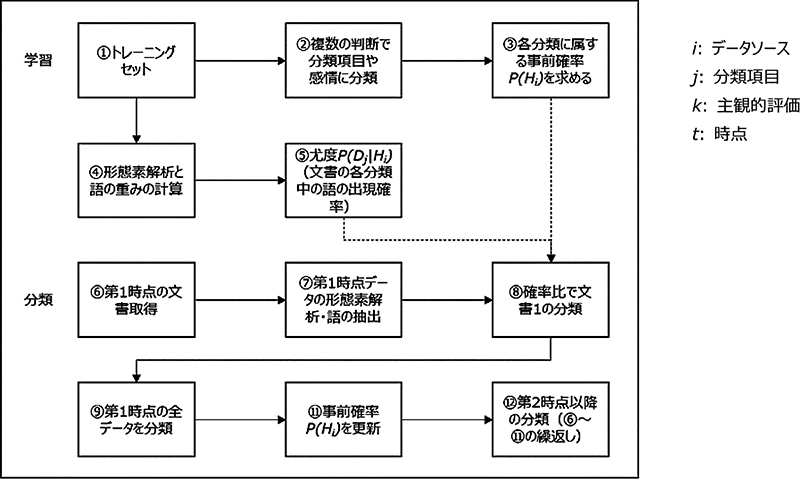
この節で記述したNaï 1 にフローの形で図示する.
当該適用例に於いて時点は日単位にし,2012 年1 月から2012 年6 月の半年の79,385 件を分析対象とした.
各カテゴリーで尤度P( D j | H i ) の大きいキーワードを重複の無いように記載すると,ポジティブで「価格」,「思う」,「良い」など,ネガティブで「事故」,「走行」,「発表」など,企業の評判で「電池」,車の品質問題で「リコール」,販売活動で「人気」,車の価格や燃費で「キロ」,車の使い勝手で「初めて」などであった.また,当該適用例に於けるデータの最終日である2012/6/29 の分類項目× 主観的評価に分類済の492 件からランダムに100 件サンプルを抽出し実際に目で読んで精度チェックをしたところ,Naïï 那須川(2006)が論ずるように多様な表現をすべて網羅して分類エラーを排除することはほぼ不可能で,むしろある基準で大量文書の分類をした後に可能になる,より詳細な分析に価値を見出すべきである.
3.4. 評価行列の例示データ分析に入る前に,これまでの処理の結果として得られた評価行列を例示する.下の表 3 は,列の左から,2012/1/30 からの日付,日付シーケンス番号,ニュースの評価行列18 項目(6分類項目×3 主観的評価),ニュースを引用するブログ(車関係)の評価行列18 項目,ニュースを引用する掲示板(車関係)の評価行列18 項目をまとめて一表にしたものである.
18 項目を表に並べる順序として,6 つの分類項目をひとかたまりにして3 つの主観的評価別に分ける形で表現した.スペースの関係上,最もニュースの反応を明瞭に表わすニュースを引用するブログ(車関係)と同掲示板(車関係)をニュースに加えて選択した.
この表を作るに当たって「プリウスPHV」というキーワードが含まれるデータに絞った上で評価行列に表現した.各セルには日別に各行列要素の件数が入るが,件数の多いセルであれば濃い色,少ないセルは薄い色で強弱を付けた.
ニュースとして1/30 以降盛んに取り上げられ,それに反応してブログや掲示板でも取り上げられている様子が見て取れる.ニュースが車の価格・燃費に関して中立的な取り上げ方をしているのに対して,掲示板は車の価格・燃費やその他に関して概ね肯定的な反応,ブログは逆に車の価格・燃費や販売活動に関して否定的な捉え方が支配的であった.
上記の例で見られるように,ニュースにブログと掲示板が反応していること,またその反応の仕方は複雑さを伴ったものでニュースに於ける行列要素とは別な要素で反応していること,この2 点が見て取れる.

複数データソースの特徴を数量的に評価する実例をもって仮説の妥当性を示すことがこの章の主目的であるが,その目的のためにデータソース( i = 1, 2, . . . , 7)に着目しそれを変数とし,それ以外の次元である分類項目,主観的評価,時点をケースとして行に対応させ,データソースの特徴を捉える.具体的にはニュースとそれを引用するブログや掲示板の内容的な特徴を検討するために,「データ分析」の節で述べた手順に沿って4 元行列を列方向がデータソースで行方向が分類項目× 主観的評価× 時点と並べた行列に配置し直した上で特異値分解することで列方向に展開したデータソースの特徴を捉える分析をする.最終的に2012 年1 月から2012 年6 月までのデータは,2214 行7 列の行列となった.
特異値分解を用いた分析を行う前にまず7 データソース相互間の基本的関係を捉えておく.データの分布が正規分布とは仮定しがたいため,データソース相互間の関係としてスピアマンの順位相関係数を以下の表 4 に示す.各列で対角を除く最大の順位相関係数で0.500 以上のものを特にハイライトする.
表 4 からニュースを引用しないブログとニュースを引用しない掲示板の相関が0.887 と特に高いこと,またニュースと,ニュースを引用しないブログの相関が0.695 と高いこと,がわかる.ニュースを引用する掲示板(車関係)とニュース引用のない掲示板,という掲示板の中の相関も0.703 と高い.
車のニュースを引用しないブログとは,その記事の中にトヨタ自動車やその製品に関して語られているため分析対象となった記事を指し,多くの場合個人が日常生活を記述するものである.個人が日常生活をブログに掲載するという行為は個々人に意思決定がすべて任されているため分類項目・主観的評価別の書き込み数が規則性なしに発生する可能性が考えられるが,トヨタ自動車やその製品に関して語っている場合は,その内容(分類項目や主観的評価)と変化のあり方がニュースと似た傾向にあり,その結果相関が高くなっているものと思われる.また,ニュースを引用しないブログと掲示板相互間の相関がとても高いことは個々人の日常生活の記述の内容とその変化はデータソースの違いを超えて相似的であることを示唆している.
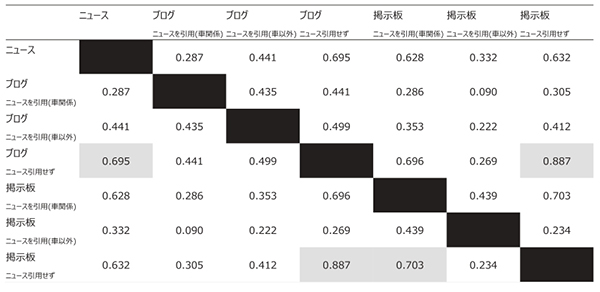
それとは逆にニュースを引用するブログ(車関係・車以外の両方)がニュースと相関が低いことも指摘できる.相関の低さは直接的には分類項目や主観的評価の件数とその時系列的な変化が,ニュースを引用しているにも関わらずニュースとは全く異なっていることを示している.
4.2. データソースに関する特徴本節では,「ニュース記事に反応して書かれたブログや掲示板の記事はニュース記事に内容的な特徴を加えている」など「情報ソースと分類」の節で掲げた仮説を検証する.その目的のためにデータソース( i = 1, 2, . . . , 7)に着目しそれを変数として列方向に展開し,それ以外の4 元行列の項目,分類項目× 主観的評価× 時点,をケースとして対応させて行方向に展開し2214 行7 列の行列にする.その上で特異値分解を適用し列方向に展開したデータソースの特徴を捉える.
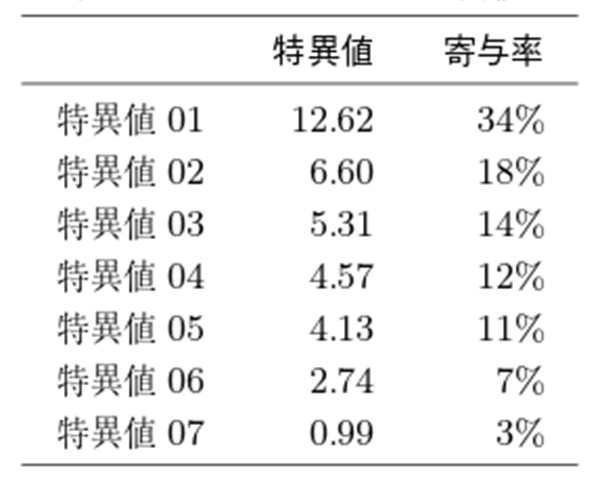
特異値分解を用いた分析では特異値の大きい順に上位2 つを対象にすることが通常多いが,特異値1 に対応する特異ベクトル1 の要素は全て正の値となっている.特異ベクトル2 と3 は正負の値を含みより内容的な特徴を表現することができると考え,上位3 つの特異値および特異ベクトルを分析対象とすることにした.また,表 5 に特異値の変化を示したが,上位3 つの特異値で全体の60%超の寄与率を示している.これらからこの3 つを選ぶことは適切であると考える.
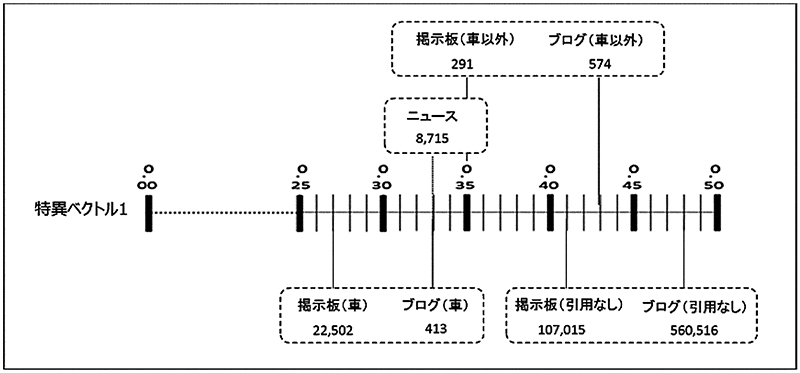
データソースの特徴を比較するために,特異ベクトル1 の値を図 2 に図示する.図 2 において,ニュース引用のあり方ごとに,つまりニュース引用があり車関係の内容(「車」),ニュース引用があり車以外の内容(「車以外」),ニュース引用をしない(「引用なし」)の別でニュースの値(0.33)との偏差と件数が対応していることがわかる.件数は各データソースを表す列の名前の下に示されている.
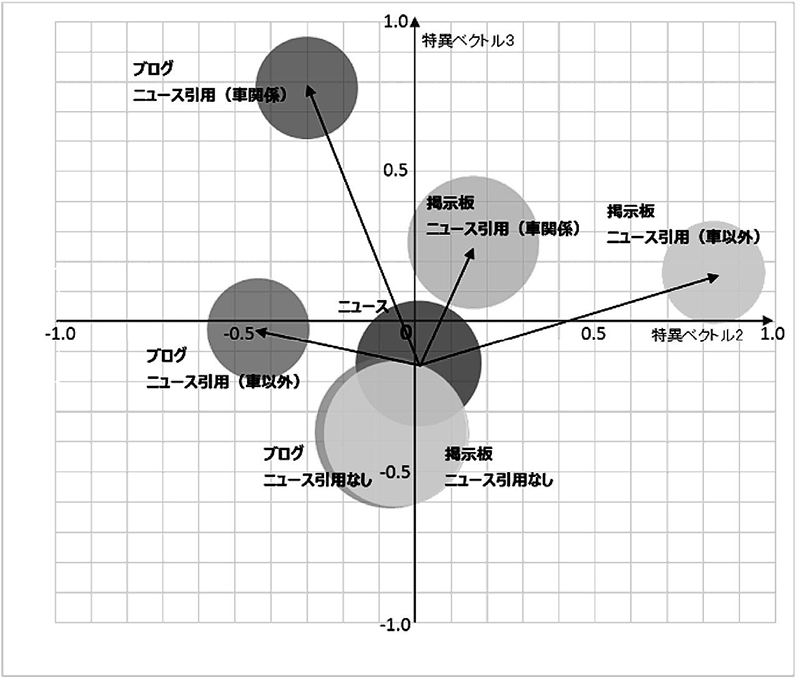
また,特異ベクトル1 の値ではニュースの値との偏差が件数と対応し,すべてが正の値であるのに対して,特異ベクトル2 と3 は正負の値を含むと共に,より内容的な特徴を表していると考えられる.特異ベクトル2 と3 のバブルチャートを図 3 に示す.件数のlog の値と円の面積を対応付けた.
図 3 では特異ベクトル2 が掲示板かブログかを区別し,特異ベクトル3 が車関連のニュース引用か,車以外のニュース引用か,ニュース引用をしてないかを区別していると解釈される.ニュースは最も中心点に近い場所に位置しているのに比較して,ニュースを引用したブログや掲示板は特異ベクトル2 と3 でその特徴が空間的に表わされている.また,ニュースを引用しないブログや掲示板は中心点付近に位置し,内容の特徴が乏しい様子を示す.これはニュースを引用してコメントしているブログや掲示板はニュースに内容的な特徴付けをしているという仮説を裏付けている.図の矢印はニュースの行列からニュースを引用したブログや掲示板の行列にそれぞれ伸びており,異なる方向で付け加えられた内容を示していると解釈できる.また,ニュースを引用したブログ(車関係)は特異ベクトル2 と3 の両方で特徴を見ることが出来る.それに比較して,ニュースを引用した掲示板はそれが車に関係あるかないかに関わらず,ほぼ特異ベクトル2 だけで特徴付けられており,ニュースを引用して論じる場合,掲示板がブログと比較して特徴がより小さいという仮説が妥当であることを示唆している.
前節で全体的な特徴を捉えた.このようなデータ分析の応用として,ニュースに対する反応の変化が株価など将来の経済事象にどのような影響を与えるか予測する簡潔なモデルの作成が考えられる.その場合,時点毎の株価に対して,時点ごとに時点以外のすべての4 元行列の項目,7(データソース)×6(分類項目)×3(主観的評価)=126 個の変数を用いて説明することもできるが,実際的には節約の原理からより少数の説明変数を用いて説明することが望ましい.この目的のために,もとの変数の中から特徴への寄与が大きいとみなされる変数を抽出して説明変数として採用することが考えられる.記述内容の特徴を捉える変数として列方向にデータソース× 分類項目× 主観的評価の組合せを配置し,時点をケースとして対応させて行方向に配置して行列 T∗ とし,特異値分解を適用することで列方向に展開した行列 T∗ の特徴を捉える.
本適用例に於いては,前節のデータソースに関する特異値分解の結果から,ニュース引用のないブログや掲示板はニュースに対する内容の特徴付けが大きくないことが分かったため,この2つのデータソースは分析対象から除外した.また,特徴をより端的に表すことを意図して中立の主観的評価は対象から除外した.その結果,行は時点,列は5 データソース×6 分類項目×2 主観的評価= 60 個の変数の行列 T∗ となり,この行列に対して内容的な特徴へ寄与する変数を選ぶために特異値分解を適用した.
前節と同様に,特異値の分析は上位2 つを対象にすることが通常多いが,特異値1 に対応する特異ベクトル1 の要素はすべて正の値となっている一方で,特異ベクトル2 と3 は正負の値を含みより内容的な特徴を表現することができると考え,上位3 つの特異値および特異ベクトルを分析対象とすることにした.また,表 7 に特異値の変化・寄与率の変化を示したが,寄与率の変化を見ると特異値2 と特異値3 は1%の違いであるのに際し,特異値3 と4 の違いは2%でそれ以降はまた1%以下の差が続くことを見ると特異値3 までを1 つのカットオフと考えることが適切であると考えられる.特異値11 以降は表示を省略している.

60 変数から選ぶ基準としては60 変数が同じ寄与率であると想定した場合の寄与率
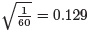 を考慮して,ここではその約1.5 倍に当たる0.20 以上を基準値とし,特異ベクトル1 の絶対値が0.20 以上で,かつ特異ベクトル2 と3 の絶対値のいずれかが0.20 以上であるものを特徴のあるもの採用することにした結果,6 個の変数(行列
T∗
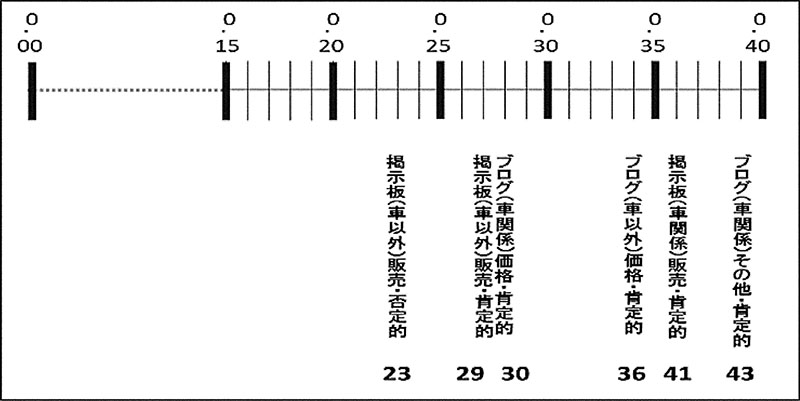
の列方向での変数)が選ばれた.それらは,「掲示板(車以外)販売・否定的」,「掲示板(車以外)販売・肯定的」,「ブログ(車関係)価格・肯定的」,「ブログ(車以外)価格・肯定的」,「掲示板(車関係)販売・肯定的」,「ブログ(車関係)その他・肯定的」である.「(車関係)」はニュースの引用があり車に関する記事,「(車以外)」はニュースの引用があり車以外の記事を指している.また,特異ベクトル1 での6 変数の値を図示(図
4)する.件数は行列
T∗
の列の変数名の下に示されている.行列
T∗
の列の変数についての特異ベクトル1 は,件数の大小に応じて大小の値を取っていることを示している.
を考慮して,ここではその約1.5 倍に当たる0.20 以上を基準値とし,特異ベクトル1 の絶対値が0.20 以上で,かつ特異ベクトル2 と3 の絶対値のいずれかが0.20 以上であるものを特徴のあるもの採用することにした結果,6 個の変数(行列
T∗
の列方向での変数)が選ばれた.それらは,「掲示板(車以外)販売・否定的」,「掲示板(車以外)販売・肯定的」,「ブログ(車関係)価格・肯定的」,「ブログ(車以外)価格・肯定的」,「掲示板(車関係)販売・肯定的」,「ブログ(車関係)その他・肯定的」である.「(車関係)」はニュースの引用があり車に関する記事,「(車以外)」はニュースの引用があり車以外の記事を指している.また,特異ベクトル1 での6 変数の値を図示(図
4)する.件数は行列
T∗
の列の変数名の下に示されている.行列
T∗
の列の変数についての特異ベクトル1 は,件数の大小に応じて大小の値を取っていることを示している.
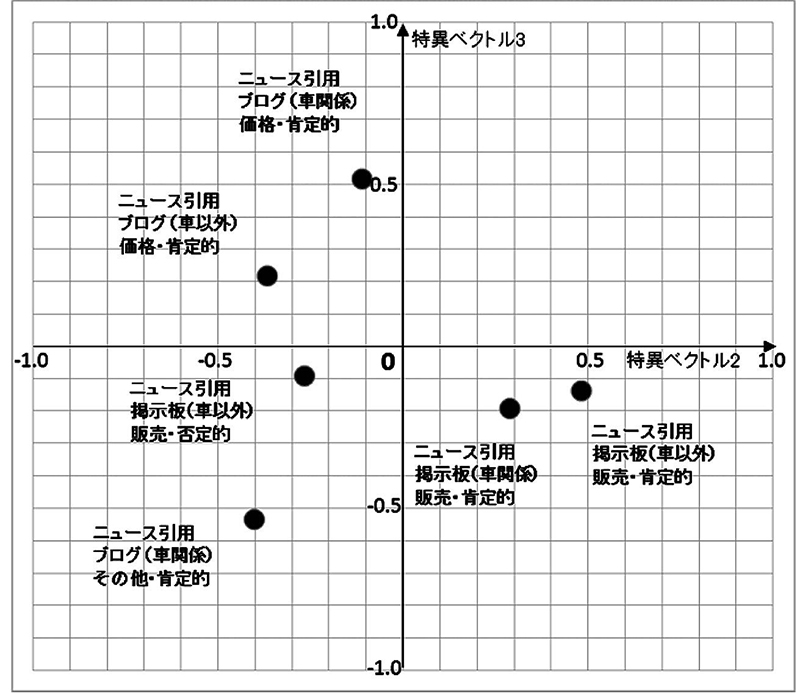
また,特異ベクトル1 の要素はすべて正の値で,件数に反応しているのに対し,特異ベクトル2 と特異ベクトル3 は,より内容的な特徴を表していると解釈できる.
図 5 から全体的に,特異ベクトル2 が掲示板かブログかを,特異ベクトル3 が価格に関する内容か販売に関する内容かを区別していると解釈できる.ただし例外は「掲示板(車以外)販売・否定的」で,これは唯一否定的な項目であり,主観的評価の違いに関しては特異ベクトル2 と3 だけでは空間的に特徴付けることができていない.また「ブログ(車関係)その他・肯定的」は,この中で唯一の「その他」の項目で,本来「その他」として認識されるべきでない特徴的なものが潜んでいるにも関わらず「その他」としてカテゴリーされた結果であると考えられる.これはNaï
特徴的な行列 T∗ の項目として価格や販売に関する事柄が多く出現したが,これは当該企業の主力製品がプリウスなどエコ・カーであることから車の価格や燃費に関して多様な意見の表明があったこと,またその売行きが良く多様な形で話題になったこと,この2 点が背景にあると考えられる.
また前節のデータソースを列とする行列の特異ベクトルと,ここでのデータソース× 分類項目× 主観的評価を列とする行列の特異ベクトルの両方に共通していることは,それぞれの特異ベクトル1 が件数に関することを指し,特異ベクトル2 がインターネット上の情報ソースの種類(ブログか掲示板か)を指していることである.
本論文に於いて,ニュースに対してソーシャルメディアのブログ・掲示板が反応することを仮定したもとで,ニュースを引用して個人的なコメントを付け加えているブログや掲示板はニュースに内容的な特徴付けをしていること,ブログはニュースを基としながら自身の考えを自由に展開する点で掲示板に比べて特徴が大きく,一方掲示板はその場の論調に制約を受ける傾向があるため特徴が小さいこと,以上を仮説として提示したが,当該適用例から得られた結果はそれらの仮説を支持する内容となっていた.また,一般的には個人の日常生活を記録するブログの内容は個々人の自由意思に任されており規則性が低いことが考えられるが,本適用例に於いてはニュースを引用しないブログや掲示板の評価行列相互間,またニュースとニュースを引用しないブログの評価行列の相関が高くある一定の規則性があることも見出された.データソースに関する特異値分解の適用の結果,特異ベクトル1 の値はニュース引用のあり方ごとにニュースの値との偏差と件数が対応していることが見出された.
提案したモデルは単純な分析モデルではあるが,定性的に記述の内容に踏み込んだ分析をより容易にする点で一定の有効性があることを示している.提案したモデルの拡張として,本論文では着目しなかった逆方向の影響関係,具体的にはブログや掲示板が起点となった議論がその後ニュースで取り上げられるまでの過程をモデルに取り込むこと,またブログや掲示板が参照される一般的な期間を加味して情報ソース別に減衰期間を再検討すること,などが考えられる.一方,提案したモデルの応用のために,ニュースへの評価を要素とする特異値分解をする過程で特徴的と認められる項目が見出された.これは,ニュース評価の変化が将来の経済事象・社会事象にどのような影響を与えていくか予測をする際に,行列項目のすべてを説明変数として使うのでなく,特徴的と認められるものに限って説明変数とするなどの応用に活用することができる.
本稿を執筆するにあたり,特異値分解を適用した分析に関して多摩大学教授今泉忠氏から多大なご助言を頂いた.ここに記して謝意を表す次第である.また,2 名の匿名の査読者および編集委員会からは有益なご助言を頂いたことにお礼を申し上げたい.