各個人の過去の複数の前回値による個体内変動を用いた個別データ精度管理システムを開発した。院内ネットワークへのトラフィック負荷を軽減するため,インデックス検索によって瞬時に過去の検査データを検索できるシステムを開発し,各個人の標準偏差,四分位偏差,前回値チェックによる検査過誤,偶発誤差の検出を試みた。コンピュータシミュレーションによるアクセス時間の比較実験でのインデックス検索は,逐次検索より瞬時に検索が可能であった。約4か月間における日常運用においても,インデックス検索による検索システムのアクセス時間は全ての測定項目で0.001未満~0.671秒であり,検索対象項目それぞれの平均値は0.025~0.119秒であった。約1年間運用した結果,SDI(standard deviation index),QDI(quartile deviation index)による個体内変動を用いた方法での警告出現率は4.55~6.35%,検査過誤検出率は3.83~6.90%であり,不要な再検や検査過誤の削減に有効であった。
信頼性のある検査結果を患者に提供するために日常行われている管理試料による統計学的精度管理手法は,系統誤差の発見など分析状態の管理として有効である。しかし,検体取り違えの検出や入力ミスなどの人為的な検査過誤や突発的な偶発誤差の発見は困難とされている1)。これらの課題に対して,デルタチェック法などの患者データの前回値と今回値の差や相関を利用した個別データ精度管理1)~4)が多く利用されているが,これらは判断基準の設定が困難であることや異常シグナルの多発などの問題点も指摘5)されており,千葉ら5)は,前回値からの経過日数も考慮し,治療効果による測定値の変化も加味したエキスパートシステム出現実績ゾーン法を開発し,多くの施設で利用されるようになった。しかしながら,膨大なデータの蓄積の必要性6),施設規模などによりその導入が困難な場合も考えられる。本研究では丹後7)の提唱した「個人の基準範囲の推定」を応用し各個人の過去の複数の測定値による個別データ精度管理システムを構築し,その基礎的評価を行ったので報告する。
サーバと自動分析装置(AU-480;ベックマン・コールター)をRS232Cで接続し,血球計数装置(LC-661;堀場製作所)はLAN方式(Ethernet; 1Gbps)で接続した。検索システム用の端末はLAN方式によってサーバに接続し,プログラミング言語はF-BASIC ver6.3(富士通ミドルウェア)を,OS(operating system)にはWindows 10を用いた。検索対象項目は生化学および免疫検査39項目,血算11項目とし,検索方法として各個人の過去のデータをリアルタイムに検索するために保存されたレコードの行番号(以下,ポインタとする)最大100個をファイルに格納し,これを参照して検索する方法(以下,インデックス検索)を用いた。
2. コンピュータシミュレーション方法サーバに直接アクセスして過去のデータを検索するために,レコードの先頭から末尾までアクセスする方法(以下,逐次検索)では,蓄積データの増加にともないネットワークのトラフィック負荷やアクセス時間の遅延が懸念されるとする報告8),9),コンピュータシミュレーションの報告10)(以下,シミュレーション)に従い逐次検索とインデックス検索のアクセス時間を比較した。シミュレーション用プログラムを作成した後に,自施設のファイルサーバのレコードを用いて5万件(200 MB × 2)から100万件(2 GB × 2)の5種の記憶容量の違うモデルレコードを作成し,過去100回までの生化学,免疫,血算50項目それぞれの平均値,標準偏差,中央値,第1四分位数,第3四分位数を算出した。これに要したアクセス時間をBASIC言語であるmillitime関数によって測定し,キャッシュの動作予測は困難であるので11),20秒間隔で50回ずつアクセスを繰り返し平均値で求めた。逐次検索は患者ID番号を,インデックス検索は100個のポインタを一様乱数によって測定ごとに作成して行った。また,一様乱数はBASIC言語のTIME$関数をシードにしてRANDOMIZE文により系列を変更したRND関数によって発生させ抽出した。
3. 検索システムのプログラム検査システムの受付ルーチンにおいて,患者の新規登録および再診登録の都度,各患者の最も新しいポインタを100個までファイルに登録し,これを参照することによってインデックス検索を行った。検索システムにおいては,F-BASIC言語のタイマイベントによって,一定時間ごとに逐次的にオーダーされた患者の個別データ精度管理を行う方法を用いた。この時,チェックの有無を記録するファイル(以下,チェック・タスクファイルとする)を検索用端末に記録し,これを順次参照して未チェックの患者データの検索を行った。Figure 1にプログラムのフローチャートを示している。
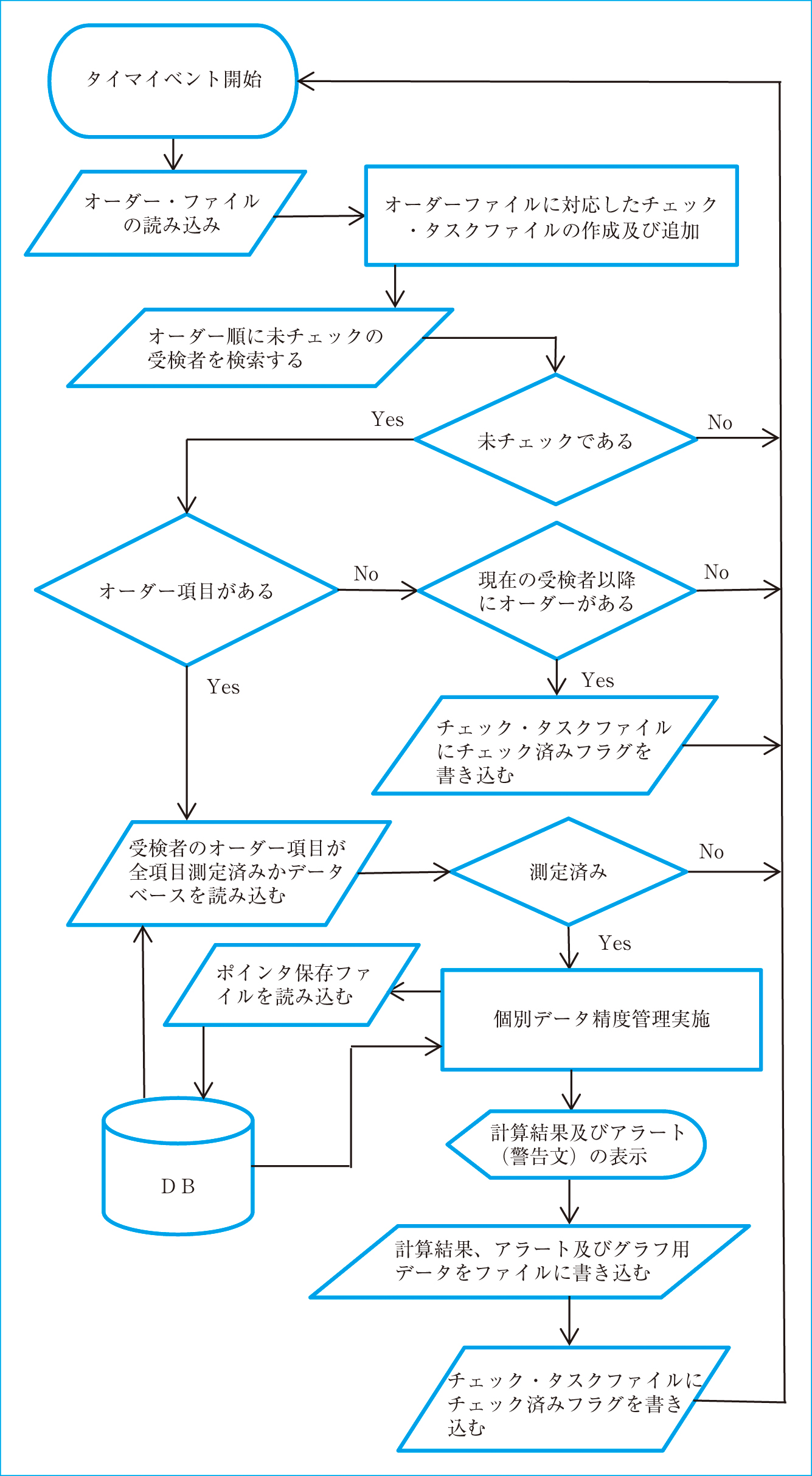
検索システムプログラムのフローチャート
検査システムに蓄積された各個人の過去の複数のデータに基づいて,今回のデータがあり得る結果なのか否かを推定するために,丹後7)が報告した個人の基準範囲の推定方法を応用した。集めた個人の複数の前回値によってSDI((今回値-平均値)/標準偏差)を算出し,±3.0を超えた場合に表示およびアラームによって警告した(ヒット)。ただし,参考にできる個人のデータ数(n)が少ない場合は推定誤差が大きくなるので,丹後7)の提唱した逐次的意志決定による個人の基準範囲の推定方法から導いた標準偏差の推定値(標準偏差推定値)をSDI算出に用いた。個人の基準範囲を正規分布仮定の下に
と考えたときCnは
で与えられ,有意水準を10%とし
として,2 ≤ n ≤ 5のとき,これを用いてSDIを算出した。
2) QDI(quartile deviation index)の算出方法集めたデータが分布の正規性を満足しない場合も少なくないと考えられ,「今回値と第1四分位下側または第3四分位上側に外れた差/四分位偏差」をQDIとして算出し,±3.0を超えた場合警告した。ただし,nが極端に小さい場合,推定誤差が大きくなると考えられ,2 ≤ n ≤ 4のとき,QDIがヒットした場合でも警告を行わないで,今回値と前回値の差の絶対値(|差|)を用いて,|差|/標準偏差,|差|/2×生理的変動幅12),13),|差|/個体内標準偏差2),3),14)の前回値チェック2)を行って,いずれも暫定的に3.0を超えた場合警告した。また,標準偏差,四分位偏差が計算不能の場合も前回値チェックを実施した。
3) 管理ルールの設定個人の生理的変動域が加齢によって変化することや7),年に1~2回実施される健診受診者の場合,過去の経時データの数は一般に多く期待できないことから7),過去10年までの測定値を検索対象とした。また,集めたデータを時系列順に並べ,分布の左右に偏りが観察された場合は管理限界が過去側のデータに影響されるのでn ≥ 20でデータを2分割し,2群の差の検定(Wilcoxon rank-sum test)を行い,有意水準p < 0.01のとき直近の分割データを計算に用いた(時系列分割)。さらに,SDIは±3SD 1回外れ値棄却法を用い,QDIは第1四分位または第3四分位から四分位偏差の5倍を超えたデータを外れ値として除外した。これらのデータを基にSDI,QDI,前回値チェックでヒットした場合に単項目再検推奨警告として警告した。また,同一の検体で複数の測定項目が同時にヒットした場合,検体取り違えの可能性を想定して試験運用時でのヒット率を考慮した。暫定的に,自動分析装置ではSDIが3項目以上とQDIはSDIより鋭敏な傾向が観察されたため4項目以上ヒットした場合,加えて血球計数装置では各項目の変動の関連性が高いことから11項目中SDIが4項目以上とQDIが5項目以上ヒットした場合に検体取り違えを警告した。さらに,標的項目3),15)としてChE,Tcho,Alb,TP,ZTT,MCV,MCH,MCHCのいずれかがヒットした場合も検体取り違えとして警告した。また,再検実施是非の参考のため個体内変動分布図,項目間チェック16)も参照した。管理ルールの設定はFigure 2に示すように,管理限界値,係数,外れ値棄却法など変更できる。Figure 3に分布に偏りが認められた時系列分割実施前の個体内変動分布図を示した。
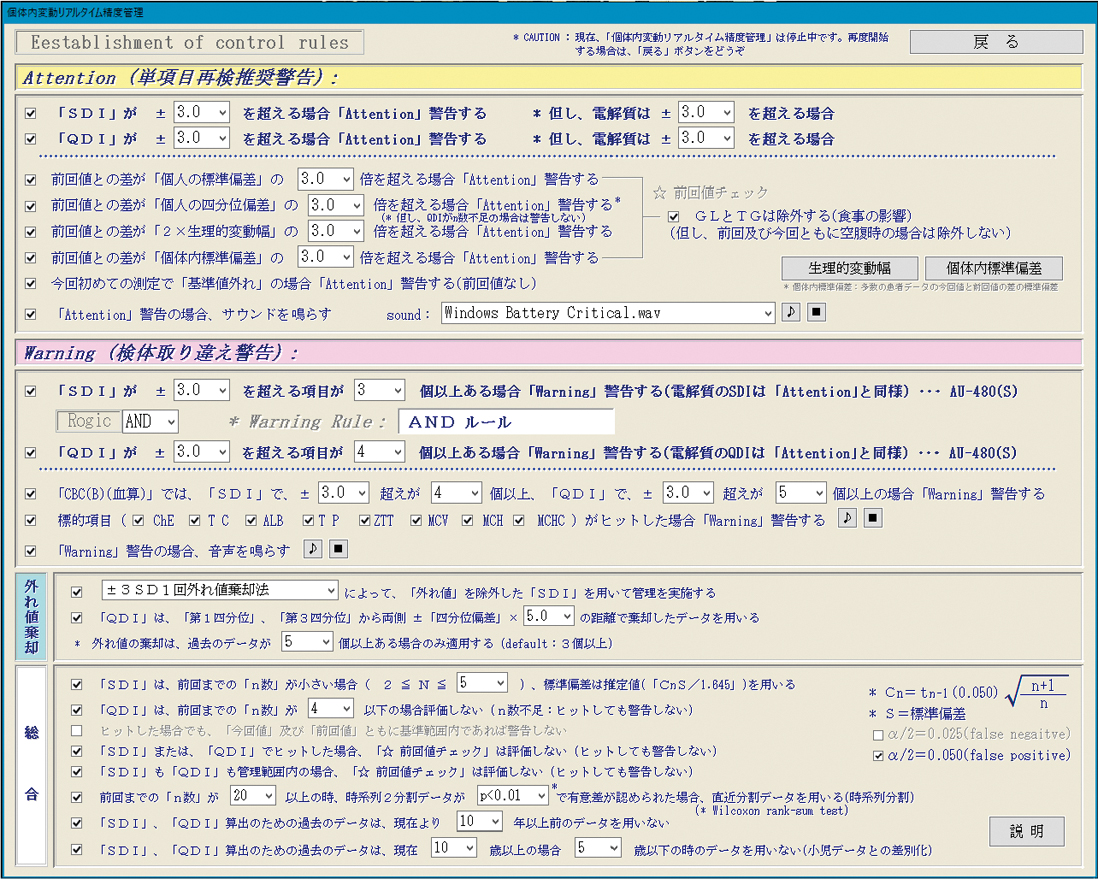
管理ルールの設定画面
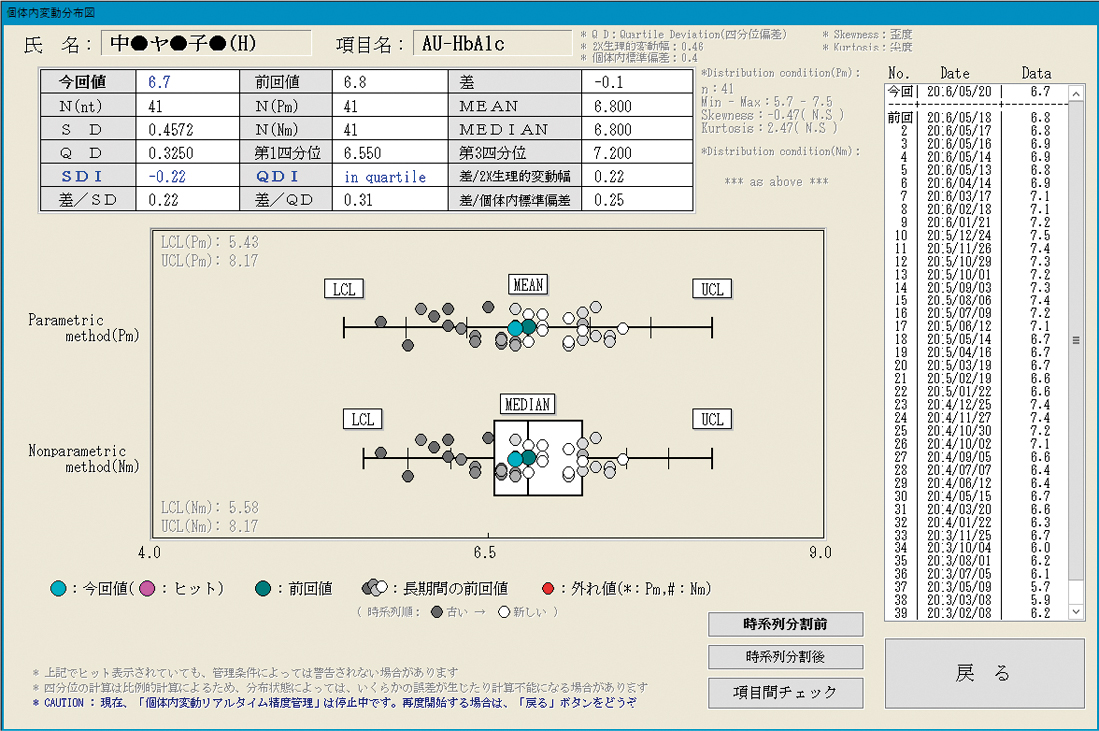
個体内変動分布図
シミュレーションによって逐次検索とインデックス検索のそれぞれのアクセス時間を比較した。また,2015年4月から7月までの日常運用でのアクセス時間を調査した。
2) SDIとQDIの相関性過去の測定回数nによる検出精度への影響を検討する目的として,2015年10月から2016年9月までの日常運用での外来患者および住民健診のデータによって算出したSDIとQDIの相関をn数別に調査した。ただし,QDIが四分位範囲内の場合は0として算出した。
3) 警告出現率と検査過誤検出率個体内変動による個別データ精度管理の運用効果を調査するため,同運用期間におけるSDI,QDI,前回値チェックでの警告出現率(ヒット率;警告出現数/測定項目数×100)およびヒットした項目全てを再検して乖離をみた検査過誤検出率(検出率;検査過誤検出件数/ヒット件数×100)を集計して比較した。また,基準値を外れた項目の割合,さらに検出した測定項目の検査過誤の原因を調査した。
シミュレーションにおける過去の100個のデータを検索するために要したアクセス時間の比較をFigure 4に示した。逐次検索では,アクセス時間の平均値(秒)は記憶容量の増加にともない,1.91から45.19と比例的に増加したが,インデックス検索では全てのモデルレコードで0.1未満であった。また,本システムの日常運用時の平均値は自動分析装置で0.094,血球計数装置で0.119,単項目検索したGL,HbA1c,食塩摂取量で0.039,0.025,0.038であり全体では最大0.671,最小0.001未満であり,シミュレーションと同様に瞬時に検索を実施できた。

コンピュータシミュレーションにおけるアクセス時間の比較
Figure 5に示すように,過去の測定回数,2 ≤ n ≤ 4,5 ≤ n ≤ 10,n ≥ 11では相関係数0.891,0.896,0.870と強い相関が認められた。2 ≤ n ≤ 4においてはSDIとQDIに大きな乖離が認められ,n ≥ 5では近似した。
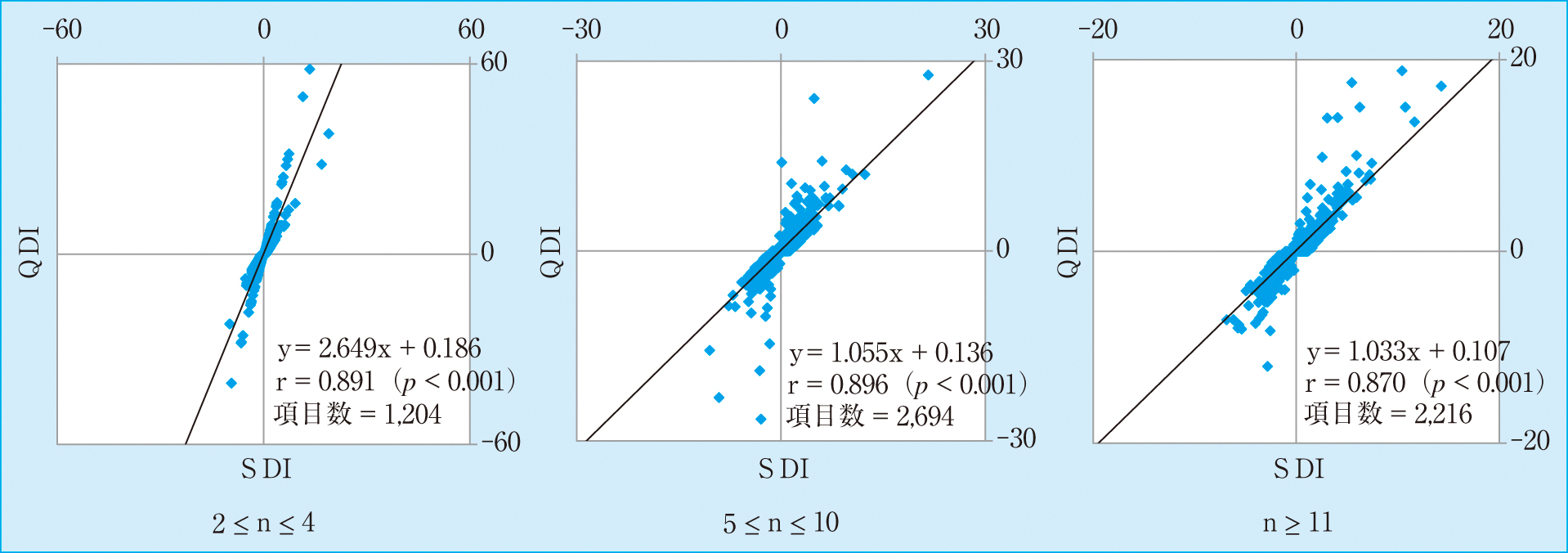
SDIとQDIの過去の測定回数(n)における相関
Table 1に単項目再検推奨警告におけるヒット率と検出率を示した。SDI,QDI,|差|/標準偏差でのヒット率は4.55~6.35%,検出率は3.83~6.90%であった。また,2 ≤ n ≤ 4でのQDIは管理に用いないが11.25%と高値であった。2 × 生理的変動幅と個体内標準偏差による前回値チェックにおいては,1 ≤ n ≤ 4の場合のみ管理に用いたが,ヒット率は各々6.42%,3.55%であった。検出率は前者が2.53%であったが,後者は1件も検出することができなかった。また,1日100項目以上測定した測定日の異常率の日差平均値は,18.50 ± 5.07%であった。
| 管理方法 | 過去の測定回数 | 測定項目数 | ヒット率(%) | 検査過誤検出件数 | 検出率(%) |
|---|---|---|---|---|---|
| SDI | 2 ≤ n ≤ 4 | 1,209 | 4.80 | 4 | 6.90 |
| n ≥ 5 | 4,945 | 4.55 | 9 | 4.00 | |
| QDI | 2 ≤ n ≤ 4 | 1,209 | 11.25 | 5 | 3.68 |
| n ≥ 5 | 4,931 | 6.35 | 12 | 3.83 | |
| |差|/標準偏差 | 2 ≤ n ≤ 4 | 1,209 | 4.88 | 3 | 5.08 |
| n ≥ 5 | 4,945 | 4.91 | 8 | 3.29 | |
| |差|/2 × 生理的変動幅 | 1 ≤ n ≤ 4 | 1,230 | 6.42 | 2 | 2.53 |
| n ≥ 5 | 3,255 | 5.99 | 3 | 1.54 | |
| |差|/個体内標準偏差 | 1 ≤ n ≤ 4 | 1,437 | 3.55 | 0 | 0.00 |
| n ≥ 5 | 3,933 | 1.96 | 1 | 1.30 |
今回,γGTで再検データと乖離した検査過誤が4例検出された。4例目が検出された時点でタイムコースを調査した結果,4例とも反応曲線にシフトが認められた。この現象は,クロスコンタミネーションが疑われ,試薬サンプリング前の洗剤による試薬プローブ,撹拌子の特殊洗浄挿入によって,その後γGTの検査過誤は検出されなかった。また,PSAで1例検出したが再検データのバラツキが認められたため,試薬残量減少による試薬劣化を疑い試薬ボトルの変更により改善された。その他の検出項目は血算7項目であり,検出件数はPLT 5件,Ht 1件,MCH 3件,MCHC 2件,MON% 2件,GRA% 2件,LYM% 1件であった。血小板凝集およびフィブリンは確認されず,再検は乖離した全ての項目で2回以上測定したが,再検数16例中5例(PLT 3例,MON%,GRA%)で再検測定そのものにバラツキが認められた。そこで,始業前洗浄,測定件数10件ごとの洗浄,終業時洗浄,週ごとの強化洗浄を徹底したことで,処置前4例検出したPLTが運用期間中においては処置後1例のみの検出であり,Htの検出はなかった。しかし,MCH 2例,他の項目で各々1例検出され,血算においては明確な原因は確認できなかった。
検体取り違え警告においては,運用期間中41例(7.64%)の警告が認められたが,全ての警告において再検値との乖離は認められず,多くは病態変化と考えられ,検体取り違えは確認できなかった。この内,複数の項目の同時ヒットが6例(生化学2例,血算4例),標的項目は35例であり,Tcho 2例,TP 1例以外は全て赤血球恒数であった。
丹後7)は,個人差の大きい検査は集団の基準範囲を適用することは不適切であり,個人の基準範囲の設定が望まれている。現時点のデータが正常か異常かを判定できる範囲を過去の健常時のデータに基づいて決める「個人の基準範囲の推定」を提唱した。この考え方は,現在の測定値が過去の個人の測定値に基づいており,あり得る測定値なのか否かを推定する方法と同義と考えられている。今回これを応用し,各個人の過去の複数の測定値による個体内変動を用いた検査過誤,偶発誤差を検出するシステムを構築し,その評価を行った。
逐次検索とインデックス検索のアクセス時間の比較シミュレーションを行った結果,前者では蓄積データ量の増加にともないアクセス時間は増加し,院内ネットワークへのトラフィック負荷が懸念された。後者は蓄積データ量にかかわらず瞬時に検索が可能であることが判り,本システムの日常運用においてもリアルタイムにデータを検索できることが確認できた。また,端末に記録されるチェック・タスクファイルを参照することで頻繁にサーバへアクセスすることが回避でき,ネットワーク負荷軽減に有効と考えられた。
各個人の過去の測定値が安定期にある場合,あるいは直近の測定値が病態コントロール不良と推察される場合など,時系列的に分布に2峰性が認められる測定項目が散見され,このとき管理限界値が過去側のデータによって影響され推定精度の低下が予想されるので時系列分割を実施した。また,外れ値が存在する場合も,管理限界幅が広くなり推定精度が低下すると考えられ除外した。個体内変動分布図は視覚的に各個人の過去の複数のデータと測定値を比較でき,再検実施是非の判断に有用と思われた。
標準偏差推定値の計算では,有意水準を5%とした場合,false negativeの確率も大きくなることが期待されるため7)10%とした。nが極端に小さい場合,標準偏差が非常に小さく計算される場合が少なくないので,標準偏差推定値は係数Cnによって標本標準偏差より大きくなり7),四分位偏差は実データによるため両者に乖離が認められたものと考えられた。この場合,QDIによる誤検出,すなわち不要な再検の増加が予測されるので,QDIの警告を行わず前回値チェックによって推定精度を補った。今回,Table 1に示したように2 ≤ n ≤ 4でのQDIのヒット率が11.25%と高値であったことから,nが小さい場合でのヒンジ幅の統計学的な推定方法が望まれる。また,nが5以上だと両者は近似するが,いくらかの乖離が認められることからSDIとQDIを併用することが有用と思われた。
単項目再検推奨警告は個体内変動による管理法の異常率が18.50%であったことや,千葉ら5)の報告にある従来法でのヒット率が平均で10.68%であることから,4.55~6.35%と比較的低いヒット率で検査過誤を検出することができたと考える。前回値チェックでは検出率が低く,|差|/2 × 生理的変動幅に対し管理基準幅の大きい|差|/個体内標準偏差で1例も検出できなかったことから,後者はfalse negativeの確率が高いことが予想された。このことから画一的な集団による管理基準を用いた前回値チェックには課題が多いことが推察された。また,多くの測定項目の生理的変動幅や個体内標準偏差を自施設で算出する煩雑さがあることも短所と言える。各個人の個体内変動による管理法は,過去のデータが蓄積されることにより,あらゆる測定項目で管理が実施できる利点がある。ただし,nが極端に少ない場合は管理できない欠点を有する方法であり,このような場合は直近1回分の前回値チェックが重要と考えられる。単に直線的な推定では誤判定の原因となることから千葉ら5)の出現実績ゾーン法のように,きめの細かい管理方法の必要性が求められる。これらは今後の課題としたい。また,血算項目においては洗浄による対処後も検出されたことから,生化学検査とは異なる血液検査特有の誤差要因17)に対応するためにも,血算における個別データ精度管理の導入は重要と考えられた。
検体取り違え警告では,取り違えを検出することはできなかったが,標的項目による管理は検出能が良好とは言えず,不要な再検の増加が予想される結果となった。特に赤血球恒数のヒット率が高値であり,その変動動態の調査が必要と考える。また,複数同時ヒット項目での管理では生化学2例,血算で4例とヒット数が少なかったことから,SDIおよびQDI単独での管理方法のあり方や項目数など,この方法の活用方法は再調査を要するものと考えられる。
中18)は,デルタチェック法が集団の標準偏差などを用いた管理限界を設定しており,個人の生理的変動を求めていないので誤検出が起こる可能性を指摘している。北村15)は誤検出と病態変化の区別に対する有効なチェックポイントとして,長期間を経た前回値の活用を提唱した。今回,各個人の多数の過去の測定値を用いた方法を試みたが,本法においても,再検した結果の多くが変わりがないという問題は解消できなかった。しかし,個人の個体内変動は,生理的変動,病態変化,治療経過などによってバラバラであり,本法は集団の管理基準ではない各個人の管理基準を用いるので,一定の効果が得られたものと考えられた。個別データ精度管理の最終目的は,再検の数を減らし検査室の経済効果に寄与することのみならず,TQCの一環として臨床検査環境の問題発見と改善にその目的があるものと思われた。
個人の過去の複数の測定データを瞬時に検索するコンピュータシステムを開発し,各個人の個体内変動による個別データ精度管理を可能とした。また,SDIおよびQDIによる方法は,低い再検率で検査過誤を検出でき有用であった。今後,誤検出をさらに削減するために,出現実績による方法の導入,測定項目ごとの個体内変動動態の特性の調査を進めるなど,より有効な管理法が求められた。
本研究は,医療情報学,精度管理学に関する研究であり,直接ヒトの医療情報,個人情報に関連した研究でないため,倫理委員会の承認を得ていない。
本論文に関連し,開示すべきCOI 状態にある企業等はありません。