速報
化学系特許中の表及びテキストからの材料知識データ抽出
2023 年 22 巻 2 号 p. 21-23
詳細
2023 年 22 巻 2 号 p. 21-23
Material Informatics (MI) needs large amount of data about materials. However, the cost of data extraction is very high. Therefore, chemical researchers are interested in technology to automatically extract the data from published documents such as patents. Previous technologies can extract the data from text in patents, but not tables. Therefore, we develop the data for MI extraction method from texts and tables in patents. In our evaluation, our method can reduce the time of data extraction by one-half. In the results, it can be expected that the new method can sufficiently reduce the cost of data extraction.
Material Informatics (MI) needs large amount of data about materials. However, the cost of data extraction is very high. Therefore, chemical researchers are interested in technology to automatically extract the data from published documents such as patents. Previous technologies can extract the data from text in patents, but not tables. Therefore, we develop the data for MI extraction method from texts and tables in patents. In our evaluation, our method can reduce the time of data extraction by one-half. In the results, it can be expected that the new method can sufficiently reduce the cost of data extraction.
国際的な材料開発競争の激化に伴い,短時間・低コストでの材料開発が必須となっているため,材料メーカ各社はマテリアルズインフォマティクス (MI)に大きな投資を行っている.MIは物質・材料の物理的・化学的性質に関する膨大なデータとAIなどのIT技術を駆使して,材料開発を効率化する取り組みである.MIを実施するため,材料メーカ各社は,特許等の公開文献からのMI用材料知識データ抽出に取り組んでいる.ここでは,材料知識データは,材料合成プロセスを示した情報であり,ある生成物に関する物性値,素材と使用量,生成物合成時行った操作の情報が含まれるとする.しかし,実際の現場では,材料知識データの抽出は研究者が人手で行っていて非常に高コストであり,材料知識データ自動抽出技術が求められている.材料知識データ抽出に関する既存手法 [1, 2]では,主に公開文献中のテキストから高精度にデータ抽出できる.しかし,材料知識データは文献中の表にも記載される場合が多く,高品質なデータの抽出には,表も含めたデータ抽出技術が不可欠である.
そこで,本研究では特許を対象とする表とテキストからのマルチモーダルな情報抽出技術 (Figure 1参照)を開発した.本報告では開発技術の内容と,開発技術によるデータ抽出時間削減率を評価した結果を示す.
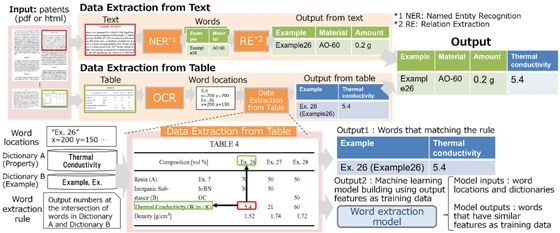
Overview of Multi Modal Data Extraction from Texts and Tables
過去の特許文献は主にpdf形式及びhtml形式で保管されている.本技術では,特許記載の実施例ごとに何らかの生成物ができると仮定し,実施例単語と実施例に対応する生成物に関する単語を特許から抽出する.
まず,テキスト側情報抽出処理を説明する.本処理では,特許からテキストを抽出した上で,既存機械学習手法 [3]を用いて,「材料名」などのユーザが設定する単語種別ごとに単語抽出を行った.また,ルールベースで単語間の関係付け及び単語が紐づく実施例の推定を行った.
次に,表側情報抽出処理について説明する.まず,既存pdf形式特許中の表からの情報抽出には,OCR技術を用いて画像化された表の構造認識及びテキスト化した上で,OCR結果に自然言語処理技術を適用する必要がある.OCRには既存OSS Tesseract [4]を用いた.OCR結果から情報抽出行うが,例えばFigure 1の表のように縦罫線が省略されているとOCRで表構造を正しく認識できないため,表中の各単語の座標情報のみを手がかりに表中の単語同士の関係を認識する必要がある.そこで,我々は材料特許固有の表記パターンに着目した.材料系特許中の表では,Figure 1のように,「Example1」のような実施例 (Example)を示す単語と,「Thermal Conductivity」のような各実施例にて生成された材料の物性値名 (Property)を表す単語が,行・列ヘッダに記載されるパターンが頻出である.よって,我々は実施例名の単語辞書と抽出すべき物性値名の単語辞書をそれぞれ作成し,各辞書中の単語の位置座標を取得した.さらに,単語抽出用ルールとして,実施例名座標と物性値名座標の交点に位置する数値を抽出すべき値と設定した.また,「Example1」が「Ex.1」と記載されるなど,表記ゆれが存在し,辞書単語と表中の単語が照合出来ない場合がある.そこで,「Example1」の値と「Ex.1」の値の周辺語の位置関係に関する特徴量が似ているという仮定のもと,抽出すべき値の周辺語の位置関係に関する特徴量を学習した機械学習モデルを作成した.本モデルでは表中の各値とその周辺語の特徴量を入力とし,その値を抽出すべきか示す0∼1の確率を出力する.
上記表側情報抽出処理の概要をFigure 1下部にまとめた.本処理では,単語位置座標情報,2種の辞書,単語抽出用ルールを入力とし,ルールに合致した単語同士を関係づけた上で出力する.情報抽出時,前述の方針で構築された機械学習モデルが存在する場合,ルールによる出力とモデルによる出力を両方処理全体の出力として採用することで,表記ゆれにも対応する.なお,本処理は単語位置座標情報の代わりに<table>タグで囲まれたhtml表情報を入力とすれば,html形式表からの情報抽出も可能である.
最後に結合処理について説明する.本処理では,表とテキストから得られた情報それぞれに含まれる実施例名の記載をキーとして,表とテキストから得られた情報を結合した.この際,"Example"と"Ex."のような軽微な表記ゆれをルールベースで修正した.
開発技術による材料知識データ抽出時間削減率を評価した.なお,本評価では,実施例ごとに何らかの生成物ができると仮定し,テキスト側から生成物の素材となる材料名とその使用量,表側から生成物の熱伝導率値を抽出した.その後,同一実施例に含まれるテキスト側単語と表側単語を結合し,最終出力データとした.
実験条件概要を示す.テキスト側は,テキストと約200単語が記載された材料名・使用量単語辞書を訓練データとして既存手法 [3]でモデルを作成し,モデルによりテキスト中から材料名単語と使用量単語をそれぞれ抽出した.さらに,材料単語と使用量単語をルールベースで関連付けした.また,実施例を示す見出し単語と各単語の位置関係を用いたルールにより,単語と実施例の関係を推定した.表側は,Figure 2の通り,表へのOCRにより得られた単語とその位置座標,熱伝導率と実施例単語を示す2種の辞書,単語抽出用ルールを使用し,モデル作成とデータ抽出行った.化学系特許100件を訓練データとしてテキスト側・表側それぞれでモデル構築行い,評価用特許10件からデータ抽出実施した.

Inputs for Data Extraction from Table
材料開発の有識者一名による人手でのデータ抽出と,自動抽出データ修正時間を比較し,データ抽出時間削減率を概算した.結果,人手でのデータ抽出に約4時間,自動抽出データの修正には約2時間かかった.よって本技術によるデータ抽出により,データ抽出時間を人手の約1/2に削減できる見通しを得た.また,情報抽出結果を人手で作成した正解データと比較,精度 (F値)を算出した結果をTable 1に示す.自動抽出データを確認すると,材料となる製品名や化学物質名を示す特許固有の言いかえ単語 (例 "KBM-573" = "3-phenylaminopropyltrimethoxysilane")が多数未抽出となっており,精度改善の余地がある.精度向上により,更なるデータ抽出時間削減が期待できる.
| Inter mediate output from text | Inter mediate output from table | Output | |
| F1 | 0.7 | 0.78 | 0.54 |
本評価の結果により,本技術によるデータ抽出時間削減の実現可能性を確認できた.今後は技術の適用範囲を広げ,生成物の合成に用いた操作などの実験条件に関する情報も含む高品質な材料知識データの抽出を目指す.
材料開発においては,MIを行うための材料知識データ抽出コストの削減が課題の一つである.材料知識データは公開文献中のテキストと表に記載されているが,既存手法は過去文献中のテキストのみが抽出対象であった.よって,本研究では,表とテキストからのマルチモーダルな情報抽出技術を開発した.評価の結果,本技術によって材料知識データ抽出時間を約1/2に削減できる見込みで,上記課題解決の可能性が示唆された.