研究報文
講演音声の音声的特徴とその印象に対する評価構造モデル
2007 年 11 巻 1-2 号 p. 30-36
詳細
2007 年 11 巻 1-2 号 p. 30-36
音声言語は我々がコミュニケーションに用いる最も一般的なツールであり, その知覚・認知についての研究は心理学・音声学・音声工学など様々な分野で広く行われてきている. 言語的コミュニケーションにおいて, 音声によりその言語的情報が伝達されるのみならず, 非言語的な情報も音響的特徴の中に畳み込まれて伝達されている. 例えば, 「怒り」や「悲しみ」といった話者の感情状態が聞き手に伝わったり, 「上手い」話し方や「速い」話し方などといった印象を与える要素が伝達されている. そういった非言語的情報については, まだ言語を獲得していない新生児や乳児においても, 声のピッチやテンポ・抑揚といった非言語情報に対する処理能力が存在することが示唆されており(斉藤他, 2005), 音声コミュニケーションにおける基本的な要素であると考えられる.
そのような音声言語の音声的特徴と, その音声から受ける印象との関係に着目した研究は近年増えつつある. Murray & Arnott(1993)は感情音声の音声的特徴についてまとめており, 木戸他(2002)は通常発話における声質表現語と音響関連量との関係を調査し, 重野(2004)は感情表現された音声についての認知と音響的性質との間の対応関係を検討している.
しかしながら, これまでの研究においては単語や短文といった比較的短い音声を対象として研究がなされてきた点が指摘されよう. 単語や短文レベルで伝達される印象も確かに存在するであろうが, 発話全体から受ける総体的な印象というものもまた存在するであろう. 例えば, 「発話の速さ感」のような印象は短い音声によってもある程度判断できるような印象であるだろうが, 「上手さ」や「好ましさ」といった印象については, ある程度の長さを持った音声により明確に受け止められる印象であると考えられる. また日常場面において, そのような短い要素だけでコミュニケーションが完結することはまれであり, 現実場面に則った研究の進展が今後必要となってくるであろう.
Erickson(2005)が指摘するように, 音声処理技術の発展や音声コーパスの整備・増加により上記の問題は解消されつつある. 特に『日本語話し言葉コーパス』(前川, 2004)は約660時間におよぶ講演音声を主とする自発音声のデータベースであり, 約3300ファイルの音声信号が収録されると共に, 各音声の転記テキストや韻律情報・形態論情報といった豊富な研究用情報が付随している. 自発音声の自動認識や音声合成といった音声情報処理学的研究に利用出来るだけの豊富なデータ量と, 音声学や言語学的研究に利便性のある多様な付加情報を兼ね備えているのが特徴である. 『日本語話し言葉コーパス』に収録されている講演音声は主に学会講演と模擬講演の2種に大別される. 学会講演の音声は, 工学系・人文社会系の種々の学会における研究発表をその場で録音したもので, 各講演の長さは10~25分程度のものから1時間に及ぶものまである. 模擬講演の音声は, 年齢と性別のバランスを取った一般話者による日常的な話題についてのスピーチを録音したもので, 10~15分程度のものである. 学会講演・模擬講演ともに講演全体の音声が収録されており, 『日本語話し言葉コーパス』は現実場面に近い形での生態学的妥当性を満たす音声データを提供してくれる. このようなデータベースの存在により, ある程度の長さを持った音声から受ける全体的な印象といったものについての研究が可能となってきている.
また, 先行研究においては, 特定の1つの印象と音声的特徴との関係をみるにとどまっており, 全体として種々の印象がどう関係しており, それらと音声的特徴がどのように結びついているのかは検討されていない. 人がどのような発話に対してどのような印象を受けるのかを明らかにする上で, 音声特徴のあるパラメータが異なる複数の印象に対して, それぞれどのような影響を及ぼすのかを知ることも重要である.
そこで今回の研究では上記の点について『日本語話し言葉コーパス』に収録された音声データならびに印象評定データを用い, 自発的に発話された講演音声の音声的特徴とその印象評定に対する因果モデルを構築し, 講演音声における印象評価構造がどのようなものであるかを明らかにすることを目的とする.
本論文では『日本語話し言葉コーパス』に付随する印象評定データを用いて分析を行った. 今回分析の対象としたのは, その中でも著者らがデータ収集作業を行った「集合評定データ」と呼ばれる印象評定データである. そこで以下に『日本語話し言葉コーパス』における「集合評定データ」がどのように収集されたものであるかを簡単に説明する. なお, 『日本語話し言葉コーパス』に付随する印象評定データについては, 籠宮他(2004)に詳細が記載されている.
2.1 音声データ『日本語話し言葉コーパス』の「コア」と呼ばれる約50万語分のデータセット(『日本語話し言葉コーパス』全体では約750万語)に含まれる音声のうち, 独話の講演音声177を印象評定の対象音声とした. 「コア」に相当する音声に対しては, 通常付与される情報に加えて, さらに多様かつ精密な研究用情報が付与されている. 例えば, 言語音研究等に利便性のある分節音ラベルや韻律ラベルなどの情報が付与されている. 「集合評定データ」と呼ばれる印象評定データもまた, 様々な研究上の利便性を増すために付与されたものである. 表1に今回の分析で用いた「コア」に含まれる独話の講演音声の種別を示す.
印象評定にあたっては, 講演の全音声を聞かせるのではなく, 各講演の時間的に「冒頭」「中盤」「終盤」それぞれ1分程度の内容的にまとまりのある部分を抜き出し, 聴取単位とした. 講演の全音声ではなく部分を聞かせる理由としては, 各講演音声は10分から15分程度の比較的長いものであるため全てを聞かせた場合, 評定者の疲労や集中力低下の恐れがあったためである. また同時に, 長い講演音声の中で, どの部分に対する印象であるのかという点を明確にするためでもある.
これらの音声とは別に, 評定者が行った評定の一貫性を確認するために, 同一音声を2回評価するものを『日本語話し言葉コーパス』に収録されているコア以外の講演音声データから2音声選んで加えた. これら2つの音声は, 工学系学会講演と人文社会系学会講演から各1音声ずつ選出された. この一貫性確認のための音声データも「冒頭」部分の1分程度のまとまりのある部分を抜き出し, 聴取単位とした. これらの同一音声に対する評価が著しく異なっている場合, その評定者の評価には一貫性がないと判断し評価データとして使用しなかった.
2.2 評定者人材派遣会社を通じて集めた20代男性・20代女性・50代男性・50代女性それぞれ5名ずつの計20名を評定者とした. いずれも過去に音声学・言語学・心理学に関する仕事に従事したことのないものであった. 特定の年代や性別に偏った評定データではなく, ある程度の幅をもった年代の評定を得るために, このような年代・性別の評定者を選定した.
2.3 評定尺度自発的な音声, 特に講演音声の印象を「話し方の特徴」という観点から総合的に捉えるための尺度である『講演音声評定尺度』(山住他, 2005)が用いられた. この尺度は, 表2に示すとおり対語形式の20項目からなっている. 講演音声評定尺度は4項目から成る5つの下位尺度(「好悪」「上手さ」「速さ感」「活動性」「スタイル」)を含んでいる. 各項目は7段階で評定を行ったので, それぞれ1~7までの得点を与え数値化した. よって各下位尺度は4~28までの尺度得点を取ることになる.
2.4 実施方法印象評定は個人法で行われた. 音声刺激の呈示と印象評定の回答にはパーソナルコンピュータが用いられた. 評定者ごとに項目の呈示順や語対の左右の配置・音声刺激の呈示順はランダムになるようにし, 刺激音声はヘッドフォンを通じて呈示された. なお印象評定は, 刺激音声を聴き終えた後に行われた.
印象評定は, 1日あたり75から90聴取単位の評定を行い, 約2週間の日程で全ての評定を行った. 評定の一貫性を確認するための音声は, この中で日をおいて2度呈示された.
2.5 評定データの扱い評定の一貫性を確認するために含めた2つの聴取単位に対する評定値間の相関係数が0.5未満であった10名のデータは, 評定の一貫性が保証されない恐れがあるため採用されなかった. したがって, 残った10名の評定者(20代男性3名・20代女性3名・50代男性2名・50代女性2名)による尺度得点の平均値を印象評定データとして用いた. 評定者数が半数となったが評定データの信頼性という点を考えると, 一貫した評定を行っていない評定者のデータを含めることは望ましくない. 今回の分析では, 評定対象とする音声の聴取単位数は500を超えるものであり, 安定した評定者のデータを用いることで, モデルの一般化に十分な量のデータが確保されていると考えた.
2.6 分析方法講演音声の特徴量として, 以下のものを『日本語話し言葉コーパス』に付随している音声データの書き起こしテキストを用いて算出した.
・モーラ数/秒(聴取単位中の総モーラ数/聴取単位中の発話時間長の総計)
・文節数/秒(聴取単位中の総文節数/聴取単位中の発話時間長の総計)
・ポーズ比(聴取単位中のポーズ総時間/聴取単位の時間)
・ポーズ数/秒(聴取単位中の総ポーズ数/聴取単位の時間)
・単独の笑い数/秒(聴取単位中の単独の笑いの総数/聴取単位の時間)
・笑いながら発話数/秒(聴取単位中の笑いながらの発話の総数/聴取単位の時間)
なおここでのポーズとは, コーパスの転記基本単位として区切られる, 200ms以上の無音区間を指す.
講演音声の特徴量としては, 他にF0周波数やスペクトル特性やフォルマント分析に基づくものなど(Boves, 1984)も考えられる. しかし本論文では「話し方の特徴」から講演音声の特徴を捉える『講演音声評定尺度』との関係を調べることを重視し, さらに局所的な指標となるような音声特徴量ではなく, 上記のような発話全体の大局的な変化を捉えるような音声特徴量を用いることにした. また, 自発音声に特徴的なイベントとしての「笑い」に関する指標も加えた.
上記の特徴量に対し「発話量」「ポーズ」「笑い」という3つの潜在変数を仮定した. 以下にそれら3つの潜在変数の内容について説明を行う.
「発話量」は, モーラ数/秒と文節数/秒といった, 無音時間を除いた純粋に音声が発声されている単位時間あたりの発話量の多さに関係した観測変数に影響を及ぼす潜在変数である. 「ポーズ」は, ポーズ比やポーズ数/秒といった発話間の無音区間の割合やその頻度に影響を及ぼす潜在変数である. 「笑い」は, 単独の笑い数/秒や笑いながらの発話数/秒といった発話中に生起する笑いというイベントに影響を及ぼす潜在変数である.
これらの講演音声の特徴量に関する3つの潜在変数と講演音声評定尺度の5つの下位尺度との関係について, 構造方程式モデリング(SEM:Structural Equation Modeling)による印象評価構造モデルの構築を試みた. 構造方程式モデリングとは共分散構造分析とも呼ばれてきたもので, 「構成概念や観測変数の性質を調べるために集めた多くの観測変数を同時に分析するための統計的方法である(豊田, 1992)」.
まずモデルを構築するにあたっては, 音声を聴き終えてから印象評定を行うという時間的順序を重視し, 講演音声の特徴量が, 印象に影響を与えるという流れを基本的な枠組みとして取り入れた. そして講演音声評定尺度で測定される5つの下位尺度間で, お互いに影響を与えるという流れを考えるが, ここで5つの印象間に階層構造を仮定することにした.
『講演音声評定尺度』は, 「好悪」「上手さ」「速さ感」「活動性」「スタイル」という5つの下位尺度から成っており, それぞれ話し方の特徴の各側面を測定している. これらの下位尺度の中で, 「好悪」「上手さ」といったものは, 他の下位尺度と比較して総合的な評価としての側面を持ち, 上位階層にあるようなものとして考えた. 籠宮他(2003)の分析において, 講演音声の特徴量と『講演音声評定尺度』の各下位尺度との重回帰分析を行っているが, 「好悪」の尺度についての分析結果は良いものではなく, 単純に物理的な指標と関連するものではないことが示唆されている. そのような点もふまえて, これらの尺度は特徴量からの直接のパスによって説明されるというよりは, 他の印象からのパスによって説明されるというモデルを考えた. 他の3つの尺度については, 音声特徴量による説明は容易なものとして, 「好悪」「上手さ」よりも下位の階層にあるものとして考えた.
まとめると, 講演音声の特徴量により「速さ感」「活動性」「スタイル」といった印象が影響を受け, それらの印象がさらに「好悪」「上手さ」といった総合的な評価へと結びつくというモデルを仮定した. そのようなモデルに対してSAS(Ver.8.2)のCALISプロシジャを用い, 構造方程式モデリングを実施した.

「コア」に含まれる独話の講演音声の種別

講演音声評定尺度
表3に講演種別の音声特徴量の基礎等計量を, 表4に分析に用いた観測変数間の相関係数を示す. これらの観測変数間の相関関係をもとに, 構造方程式モデリングにおけるパラメータの推定を行った.
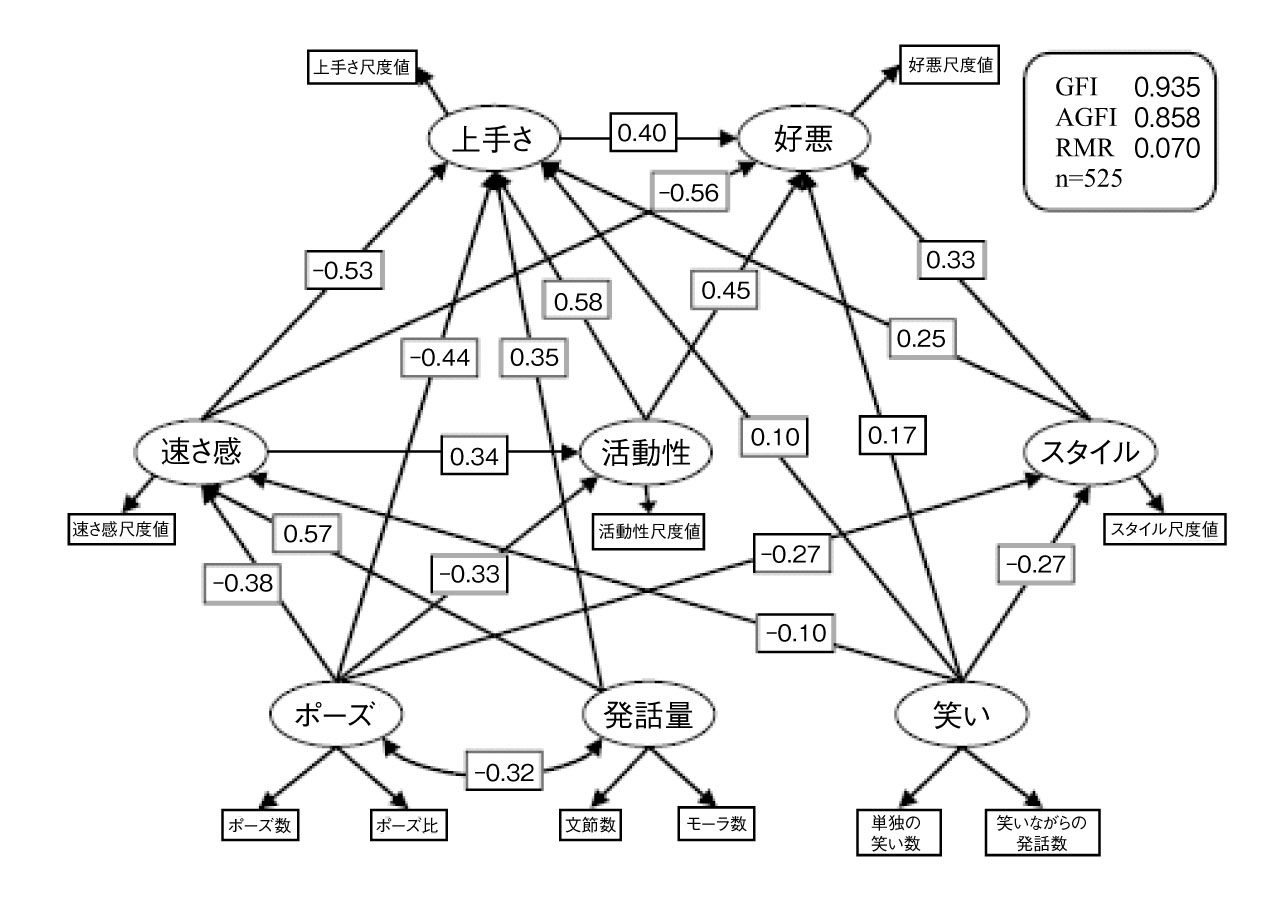
モデルの適合度(GFI・AGFI)や情報量(AIC)等の指標を参考とし, またモデルとしての解釈可能性という点を考慮した結果, 最終的に採択したモデルのパス図(標準化解)を図1に示す. パス係数は全て5%水準で有意となっている.
上位の階層として設定した「好悪」「上手さ」にも, 講演音声の特徴量である「ポーズ」「発話量」「笑い」からのパスの多くが有意なものとして残った.
講演音声の特徴量を表す潜在変数間では, 「ポーズ」と「発話量」の間に負の相関関係(-0.32)が有意なパスとして認められた.
適合度の指標はGFI=0.935, AGFI=0.858であり, GFIとAGFIの間に若干の開きはあるもののモデルとデータの標本共分散行列との適合に問題はないと判断した.
講演音声に対する印象評価構造モデルのパス図

講演種別の音声特徴量の基礎等計量

分析に用いた全観測変数間の相関係数行列
本モデルにおいては, 講演音声特徴量を表す, 「ポーズ」, 「発話量」, 「笑い」, という3つの潜在変数が各印象へと影響を与えている.
「速さ感」の印象には, 「発話量」と「ポーズ」の寄与が大きく, 「発話量」が多く「ポーズ」の少ない講演音声が「速い」発話の印象へと結びついている.
「活動性」の印象には, 「ポーズ」の寄与が大きくまた「速さ感」からの影響もある. すなわち「ポーズ」が少なく「速さ感」が速い印象を持たれる講演音声であるほど「活動性」の高い講演だという印象が強くなることが示されている. 「発話量」という講演音声特徴量は「活動性」に対して直接のパスはないが, 「速さ感」を経由して間接的に影響を与えている.
「スタイル」には「ポーズ」と「笑い」が影響を与え, 両者が少ないものほどあらたまった発話という印象が高まる.
「上手さ」の印象に対しては, これまで見てきた「速さ感」「活動性」「スタイル」といった印象からの影響を受ける. 「速さ感」が速くなく「活動性」が高く「スタイル」のあらたまった発話によって, 「上手い」発話という印象が高まる. また, 講演音声特徴量からの影響もあり, 「ポーズ」の少なさと「発話量」の多さが「上手さ」の印象に寄与している.
ところで「速さ感」の印象は直接的には速くなるほど「上手さ」の印象を低下させるが, 「活動性」を経由した間接効果でみてみると「速さ感」が上昇することで「活動性」の印象が高まり, それによって「上手さ」の印象が上昇する. この間接効果の大きさは0.34(速さ感から活動性へのパスの因果係数)×0.58(活動性から上手さへのパスの因果係数)=0.20と直接効果の-0.53と比べると小さいものの, ある程度の「速さ感」が「上手さ」の印象を押し上げるという関係が現れている.
「好悪」の印象では, 「上手さ」の印象が高い音声ほど「好まれる」話し方の講演であるという関係が示された. また「速さ感」が速くなく「活動性」が高く「スタイル」のあらたまった発話の印象も, 「好悪」の印象を高める要因となっている. 「活動性」を経由した「速さ感」の間接効果に関しては「上手さ」で見られたのと同様の関係であるが, こちらは0.34(速さ感から活動性へのパスの因果係数)×0.45(活動性から好悪へのパスの因果係数)=0.15と小さく, 「好悪」の印象に与える影響は少ない.
本モデルでは, 「上手さ」「好悪」といった総合的な評価の印象は, どちらも「速さ感」が速くなく「活動性」が高く「スタイル」があらたまっている印象によって上昇する関係が示されている. そして「上手い」話し方という印象を持たれる講演は, さらに「好まれる」話し方の講演だという印象が強まるということが示された. それらの印象に対しては, 「ポーズ」や「発話量」からの直接のパスもあるが, その因果係数の値はいずれも他の印象からのパスの因果係数の値よりも小さなものとなっている. 従って, 「上手さ」や「好悪」の印象は, 直接「ポーズ」や「発話量」のような物理的特徴との対応で説明するよりも, それらによって形成される「速さ感」や「活動性」といった印象によってより良く説明される, 認知的・総合的な印象として捉えられることを本モデルは示している.
本モデルでは, 講演音声特徴量が各印象に異なる程度で寄与する関係も示されている. 「ポーズ」の少なさは「速さ感」「活動性」「スタイル」の印象を同程度に高める一方, 「ポーズ」と負の相関関係のある「発話量」は増加し, 「発話量」の多さは「速さ感」の印象を高めている. 「ポーズ」の少なさは「上手さ」の印象を高めるが, 「ポーズ」の少なさ・「発話量」の多さによって高まる「速さ感」の印象は逆に「上手さ」の印象を低下させるという関係になっており, 適度な速さ感が求められる関係となっている. また「笑い」の多さは「好悪」の印象を高めるが, 同時に「スタイル」の印象を低下させ, そのことにより「好悪」の印象を低下させる要因にもなっている. このように本モデルでは, 重回帰分析のような個々の印象と音声特徴との関係を調べるだけでは見ることの出来ない,音声特徴量と印象との複雑な関係を見てとることが可能となっている.
本研究では,『日本語話し言葉コーパス』に収録された講演音声の印象評定データを元に構造方程式モデリングを行い,講演音声に対する印象評価構造モデルの構築を行った. その結果,講演音声の音声的特徴である「発話量」「ポーズ」「笑い」と,「好悪」「上手さ」「速さ感」「活動性」「スタイル」といった講演音声の話し方の印象との関係,並びに印象間の関係を明らかにした. 特に「上手さ」「好悪」といった印象は講演音声特徴量によって規定される「速さ感・活動性・スタイル」といった印象から形成される総合的な評価であるという関係が示された. また「上手さ」の印象が高いほど,「好悪」の印象が高まる関係であることが示された.
今後はこのモデルで見られた関係が,音声特徴のパラメータを実際に操作した時にも見られるかどうか,音声再合成による実験的検討を行ない,今回の印象評価構造のモデルの妥当性を検討していく予定である.