字体と字形の狭間で 文字情報基盤整備事業を例として
2015 年 58 巻 3 号 p. 176-184
詳細
2015 年 58 巻 3 号 p. 176-184
符号化文字集合を論じるうえで欠くことのできない,字体と字形という2つの言葉の意味を明確にしたうえで,利用者集団や目的によって字体を区別する粒度が異なることについて論じる。
漢字をコンピューターで扱うための符号化文字集合を議論するとき,字体と字形という2つの言葉を抜きに議論することは,事実上不可能である。
しかし,字体と字形についてのとらえ方は,論じる人によって千差万別であり,さまざまな混乱を引き起こす遠因ともなってきた。たとえば,JIS X 0208の1978年版と1983年版の規格票に掲げられている字形の相異に起因する混乱(いわゆる新旧JIS問題)も,煎じ詰めれば,当時は,情報処理分野における字体概念,字形概念が成熟していなかったためだったととらえることもできる1)。
本稿では,まず,字体と字形,および字種という言葉の意味を明確にしたうえで,特に,字体と字形の関係を中心に,複数の文字集合を関係づけることの困難さについて,文字情報基盤整備事業を通した筆者の見聞を例に論じる。
文化審議会国語分科会漢字小委員会の資料2)に,字種,字体,字形について,非常にわかりやすい記述がある。
「字種とは,同じ音訓・意味を持ち,語や文章を書き表す際に互換性があるものとして用いられてきた漢字のまとまりのことである」(p. 1)
「字形とは,個々の文字の見た目,形状のことである」(p. 2)
「字体とは,文字の骨組みのことである。文字の骨組みとは,ある文字がその文字として認識される字形のバリエーションの範囲を枠組みとして捉えたときに,その枠組み内にある様々な字形に一貫して表れている共通項を抽出したものである」(p. 3)
一方,JIS X 0213注1)では,字体,字形について,次のように定義している。
i)字体(ZITAI)図形文字の図形表現としての形状についての抽象的概念。
h)字形(ZIKEI)字体を,手書き,印字,画面表示などによって実際に図形として表現したもの。
文化審議会資料もJIS X 0213も,字体を漢字の形状にかかわる抽象的概念とし,字形を漢字の形状の具体的視覚表現としている点では共通している。
本稿では,国際符号化文字集合における定義注2)も踏まえ,字体と字形を次のように規定したうえで,議論を進めることとする。
|
字体とは,漢字の形状の抽象的概念である。 字形とは,漢字の形状の具体的視覚表現である。 |
字体と字形の関係はどのようなものであろう。実は,その関係は,字体と字形の定義ほど自明のことではない。
字体とは,漢字の形状の抽象的概念である。それゆえ,字体を字体として実際に認識できるように視覚表現化することは実際には不可能であり,個々の字形を見た人が,その背後に存在するものとして認識する以外に術(すべ)はない。そのため,字体について語る際には,何らかの方便を用いる必要がある。
先の文化審議会資料にも,字体と字形の関係について,次の記述がある。
「字形に違いがあっても,他の字種と混同することがなく,文字の認識に関わるものでなければ,原則として同一の字体とみなし,同じ漢字であるとするのが常用漢字表の基本的な考え方である」(p. 4)
「字体は本来,抽象的な概念として把握されるべきもので,具体的な形状を持つものではない。そのため,常用漢字表は,便宜上,明朝体のうちの一種を例に用いて,具体性を持たせた『印刷文字における現在の通用字体』を示している」(p. 7)
文化審議会資料の場合は,「便宜上」,ある特定の明朝体のデザインを例示することによって字体を示している。
本稿では,情報技術的な観点から,字体を具体的な字形表現の集合に事後的に付けられた単なるラベルであると見なすこととする。
簡単な思考実験で説明する。
さまざまな新聞や雑誌などから切り取ってきた多数の文字(具体的な字形の集合)を,視覚的類似性を手がかりに複数のグループにまとめる。まとまった字形のグループを,小さな箱か袋にまとめて入れる。これらの箱や袋に,他と明確に区別できる整理番号や固有の名前を付ける。
この整理番号や固有名を字体と見なすのである。
すなわち,同一の箱に入れられた字形は同じ字体に属し,異なる箱に入れられた字形は字体が異なる,と考える。
読者の多くは,はぐらかされたように感じられると思うが,情報技術としての符号化文字集合では,ラベル(整理番号や固有名)そのものを伝達や複製などの処理の対象としても,何ら不都合は生じない。逆にいえば,情報処理装置は,ビット列に還元できるラベルしか扱うことができない。
字体とは異同を判別するために字形の集合に付けられた固有名である。
文化審議会資料によると,常用漢字表は,ある字体を便宜上ある特定の書体デザインによる字形を用いて示す,という立場を取っている。一方,筆者は,字体を字形の集合に付けられたラベルと考える,という立場を取る。この2つの立場は,常用漢字表のようなある字体に結び付けられた字形とラベルを1対1に対応付けることで,容易に関連付けることができる。
一般に,ある一定の考え方で字形を集めた表(仮に文字の表と呼ぶ)は,その背後に1つひとつの字形がそれぞれ1つの字体に対応する字体集合を想定することができる。常用漢字表は,あるポリシーで設計されたデザインに基づくフォントによる字形が表として示されているが,この文字の表は,例示された1つひとつの字形がそれぞれ1つひとつの字体に対応付けられた字体集合としての性格をもっている。そのうえで,常用漢字表においては,「(付)字体についての解説」として,明朝体のデザイン差や手書きの楷書体について,同一書体に属すると見なしてよい字形の差異についての記述がある。
文字の表は,字体集合と見なすことができる。そして,それぞれの字体に属するさまざまな字形については,ある範囲で視覚的な差異が容認される。問題は,ある字形を誤字と見なすか否か,ある2つの字形を同一の字体に属すると見なすか異なる字体に属すると見なすかといった判断が,人や状況によってさまざまに異なるところにある。
ある特定の文字の表で区別して掲げられている字形は,それが同一の字体に属するという特段の注記がないかぎりは,その文字の表では異なる字体に対応すると考えられる。では,複数の文字の表があるとき,それらの文字の表に対応する字体集合間の関係については,どのように考えればよいだろうか。
筆者の考えを結論から述べると,要素となる文字に相違がある複数の文字の表は,字体集合としては互いに共約不可能である。
共約不可能性(incommensurability)という言葉は,あまり耳慣れたものではないかもしれない。パラダイム論で著名な科学史家のトマス・クーンが提唱した概念で,異なるパラダイムに属する科学理論の優劣を比較することはできない,という考え方だ。それまでの自然科学が連続的に進歩する,という見方に異を唱えた。
筆者は,複数の言語も,クーンが用いた意味で原理的には共約不可能である,と考えている。そして,複数の字体集合も,同様に共約不可能であると考えている。
しかし,現実には,個人の間のレベルでも,複数の言語の間のレベルでも,日常の生活において不都合や齟齬(そご)が顕在化しない程度には,文字を用いたコミュニケーションが成立しているように見受けられる。
クーンが共約不可能性という言葉でえぐり出した問題圏は,まさに,この「原理的には」と「見受けられる」の間隙(かんげき)にある。「原理的」には関連付けることが不可能な複数の文字集合を,実用上差し支えない範囲で,どのように関連付けていくか。筆者がかかわってきた国際符号化文字集合における統合漢字の問題も,文字情報基盤整備事業が行ってきた戸籍統一文字と住基ネット統一文字の整理統合の問題も,突き詰めていくと,このような互いに共約不可能な複数の文字表を実社会で不都合が生じない程度に妥協できる範囲で何とかして関連づける,という営為だったといえよう。
現在筆者がかかわっている文字情報基盤整備事業注3)も,この事業が成果を引き継いでいる汎用電子情報交換環境整備プログラム注4)も,ともに,戸籍,住民票の電子化処理において中核を担う文字集合である,戸籍統一文字注5)と住基ネット統一文字注6)という大規模文字集合を整理統合することを目標として行われてきた。
しかし,戸籍統一文字と住基ネット統一文字との間にも,汎用電子情報交換環境整備プログラムの成果物である文字一覧注7)と文字情報基盤整備事業の成果物であるMJ文字情報一覧表注8)との間にも,先に述べた文字集合間の共約不可能性の問題が潜んでいる。
以下,いくつかの具体的な例を用いて,文字集合間の共約不可能性について述べることとする。
戸籍統一文字と住基ネット統一文字は,一方では戸籍の行政実務,もう一方では住民基本台帳の行政実務に資するために策定されたもので,法制上は,互いに密接にかかわっている。しかし,その策定方針の違いにより,その性格はかなり異なっている。汎用電子情報交換環境整備プログラムにおいても文字情報基盤整備事業においても中心的役割を担ってこられた国立国語研究所の高田智和氏らの論文によって,その相違を概述する。
「住基ネットに登載されている統一文字は21039字であり,仮名・ラテン文字・符号・記号などの非漢字を除くと,漢字は19435字である(2002年5月8日版)。これは,各地方自治体が住民基本台帳を電算化してコンピュータで扱うために必要であろうと考えられる文字の集まりである。具体的には,日本国内のコンピュータに標準で登載されているJIS漢字(JIS X -208の第1水準・第2水準漢字,JIS X 0213の第3・第4水準漢字,JIS X 0212の補助漢字),地名に用いられる文字(地名外字),各地方自治体にシステムを納めている情報機器メーカー各社の拡張文字から成る。メーカー拡張文字は,情報機器メーカー各社が顧客からの要望に応えてシステムに取り込んだ文字であり,パソコンが普及する以前から蓄積されてきたものである。この点から,住基統一文字は,情報機器メーカー各社が電子計算機の時代から情報機器で扱ってきた文字の集合体と言ってもよい」(p. 97)
「戸籍の電算化とオンラインでの使用にあたり,法務省は戸籍統一文字を定め,戸籍簿に使うことができる文字を網羅している。その数は56040字にのぼり,漢字は55267字である(平成16年12月6日)。戸籍簿に記載可能な文字については,戸籍行政における法務省民事局長通達によって取り決めがなされており,現在,戸籍簿に記載することのできる主な漢字を示すと次のようになる。
1.常用漢字表の適用字体
2.戸籍法施行規則別表第二「漢字の表」に掲げる字体
3.漢和辞典に正字として記載されている漢字
4.漢和辞典に同字・古字・本字として記載されている漢字
5.漢和辞典に俗字として記載されている漢字
6.第5200号通達別表に掲げる字体
ここでいう「漢和辞典」とは,現在市販されているものを指し,ゆるやかな定義である。戸籍行政においてよりどころとして重視されてきた『康煕(こうき)字典』も含まれる。常用漢字と人名用漢字を併せても3000字に満たず,『康煕字典』の見出し語が50000字程度であることから,戸籍統一文字の大部分が漢和辞典の見出し字であることは容易に想像ができる。後述するように,現在市販されている中型規模以上の漢和辞典の見出し字が大部分を占めており,戸籍統一文字は現代の漢和辞典の集合体であると言ってよい」(p. 97〜98)
「住基統一文字が,実務に使用している道具である情報機器の搭載文字に基づいているのに対し,戸籍統一文字は,実務のために設けられたルールの範囲内で,理論上可能となる臨界点を目指す網羅主義によって設計されている。住民基本台帳と戸籍とは,同じようなものを扱っているようであっても,電算化のためのシステムに搭載する文字セットの設計思想には大きな違いがある」(p. 98)
「戸籍は各地方自治体において電算化の途上にあるため,住民基本台帳のように,戸籍統一文字の使用実態を知ることはできない。しかしながら,住基ネットで使用実績のある文字が12000字程度であることから,これと同程度の水準であろうと推測される。戸籍統一文字もまた,戸籍簿で実際に使われている文字の集まりと同一視できないことを特記しておく」(p. 98)
このような策定方針の相違により,戸籍統一文字と住基ネット統一文字とでは,そこに含まれる文字がさまざまな意味で異なっている。
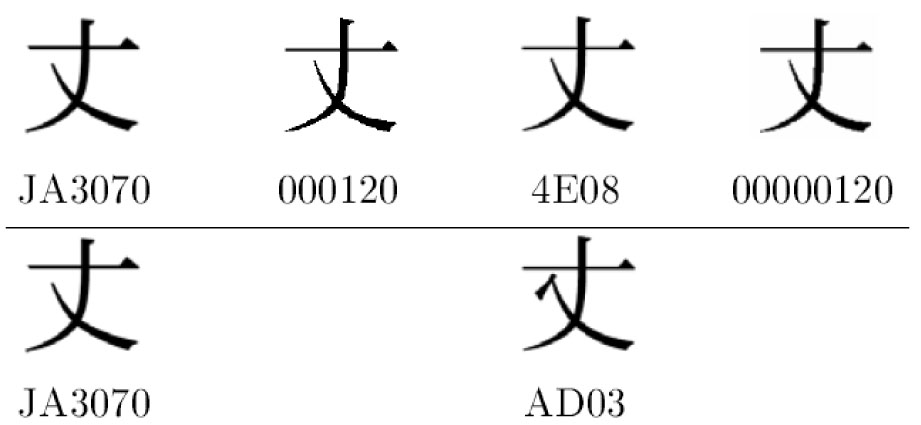
図1は,UCS注9)では通常同一の符号位置に統合されるが,戸籍統一文字や住基ネット統一文字では別の文字として扱われているものの一例である。
UCSでは,U+845Bという符号位置をもつ「葛」の字である。左から,平成明朝体,戸籍統一文字,住基ネット統一文字,登記統一文字の順に並んでいる。
戸籍統一文字の欄が空白になっているものや住基ネット統一文字の欄が空白になっているものがある。
たとえば,JTB9D7という平成明朝体は,戸籍統一文字では,どの字に対応するのだろう。「わからない」が正解である。実は,文字一覧表で平成明朝体と戸籍統一文字,住基ネット統一文字が,それぞれ対応関係が付けられていたとしても,その背後に想定される字体が,平成明朝体において,戸籍統一文字において,住基ネット統一文字において,それぞれどの程度の字形の広がりをもっているかは,やはり「わからない」のである。
はっきりしていることは,UCSの「葛」の字を,戸籍統一文字なら5種類,住基ネット統一文字なら6種類に区別して扱っている,ということだけである。
戸籍統一文字や住基ネット統一文字を,情報システムにおいて関連付けて用いるときには,それぞれの文字集合で区別されている文字を,一切縮退注11)させることなく相互変換(round trip conversion)できなければならない。このことは,情報システムを安定的に運用するためには欠くことのできない要件なのである。

汎用電子情報交換環境整備プログラムと文字情報基盤整備事業との間にも,一方は実務利用を前提としない調査研究事業,もう一方は実務運用を前提とした開発事業という性格の相違があり,その成果物の間にも,共約不可能性がある。
汎用電子情報交換環境整備プログラムでは,戸籍統一文字と住基ネット統一文字を整理統合する際,1990年以来JIS X 0208やJIS X 0213の規格票の例示字形として用いられてきた平成明朝体デザインを軸として戸籍統一文字と住基ネット統一文字の対応関係を整理した。その際,デザイン統一と称して,複数の戸籍統一文字や住基ネット統一文字に単一の平成明朝体字形を対応付ける,という操作を行った。平成明朝体という1つの明朝体デザインにおいて,そのデザインポリシーの整合性を考慮するとやむをえなかったこととはいえ,このことが,実務運用を前提とした対応表やフォントの開発において,大きな障害となった。
1つ例をあげる。いわゆる「筆押さえ」という明朝体に特有のデザイン処理である。
文字情報基盤整備事業の一環として開発したIPAmj明朝体にも,筆押さえの有無を区別しているものがある。

ところが,汎用電子情報交換環境整備プログラムの報告書に掲示されている平成明朝体では,この区別を行っていない(図2,図3)。
当初,IPAmj明朝注12)においても,汎用電子情報交換環境整備プログラムにならい,MJ文字図形MJ006303とMJ006304,MJ008041とMJ008042の区別を行っていなかった。しかし,住基ネット統一文字や戸籍統一文字で区別されている文字が,MJ文字図形集合の視覚表現として区別できなければ実務運用上の混乱が予想される,との意見が多く寄せられた。結果的に,文字情報基盤整備事業として,IPAmj明朝体のデザインポリシーのいかんにかかわらず,戸籍統一文字もしくは住基ネット統一文字で区別されている文字に対しては,原則としてすべて異なる字形を対応付ける,という方針に転換した。
この事例は,互いに共約不可能な複数の文字表の対応関係を取ることの困難さを端的に物語っている。
戸籍統一文字集合と住基ネット文字集合を対応付ける際,情報システムにおける実運用を前提とすると,いずれかの文字集合において別字体として区別されているものを同一視することは,システム間の相互運用性を担保するうえでも許されない。
汎用電子情報交換環境整備プログラムがデザイン統一と称して行ったことは,戸籍統一文字とも住基ネット統一文字とも共約不可能な,独自の世界観に基づく新たな文字の表,すなわち新たな字体集合を,つくり出すことにほかならなかった。

実務を行ううえでは,戸籍統一文字や住基ネット統一文字のような大規模な文字集合の間の対応付けだけではなく,災害等の緊急時におけるシステム運用も含め,既存の専用システムや市販の情報機器類に登載され広く普及しているJIS X 0213などの比較的小規模な文字集合との対応付けが必要になる場合がしばしばある。
しかし,繰り返し述べてきたように,異なる文字集合を対応付けるのは,原理的に不可能であるとともに,実際の作業のうえでも多くの困難が伴う。
大規模文字集合と小規模文字集合を対応付ける際,個々の文字については,おおむね,次の3通りの場合が考えられる。
ちなみに,小規模文字集合の1つの文字に対応する大規模文字集合の文字の存在を複数許容することも可能であるが,その場合,双方向互換性(round trip conversion)は,保証されなくなる。
では,対応関係はどのようにして明らかにするか。
本論では,MJ文字図形集合の中から,JIS X 0213への対応付けが事実上不可能なものを中心にいくつか例示することで,この作業の困難さについての説明に代えることとする。

一見すると,「苗」の誤記とも見てとれる。しかし,『大漢和辞典』には,苗は別字,と明確に記載されている。『康煕字典』にも独立した字として掲げられているが,JIS X 0213には対応する文字が見当たらない。このように,『大漢和辞典』や『康煕字典』には掲載されて,しかも,JIS X 0213の字と関連をもたないものは多数存在する。
いわゆる国字にも,厄介な例がある。

「うしのあつもの」と読む。角川書店の『大字源』注13)や東京堂の『国字の字典』注14)に掲げられているが,もともとの出典は,平安時代に僧侶昌住(しょうじゅう)により編纂(へんさん)され,日本最古の漢字字典とされる『新撰字鏡(しんせんじきょう)』注15)にまで遡(さかのぼ)る。実際には,1803年に発行されたいわゆる享和本(1803年)に記載があり,「羹之類也牛乃」との語釈がある。

読んで字のごとく「おやま」である。このような熟字訓をもつ熟語を1つの文字として扱う例は多々見受けられる。歌舞伎の外題(げだい)等で,縁起を担いで5文字や7文字に見せるために合字(ごうじ)として書かれたものが,明治期以降の翻刻の際,1文字として鋳込まれた,といった経緯があると推測される。
このような文字は,意味が明確であるゆえに,かえってJIS X 0213の1つの文字に対応付けることは不可能であり,「牛の羹(あつもの)」なり「女形(おやま)」なりといった意味的に対応する表記に置き換えることが適当であろう。
他方,対応付けが不明な文字も多くある。これらの文字の一部には,一見して,ある文字の誤記に起因すると推測できるものもあるが,一方,まさに音義不明のものもある。

おそらく「奠(てん)」の誤記に起因したものと思われるが,推測の域を出ない。
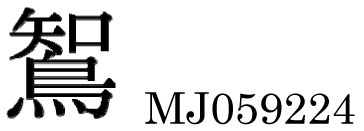
おそらく善知鳥(うとう)という3文字熟語の後ろの2文字が合字化したものと思われる。しかし,地名にこの形での使用例があるとの報告もあり,どのような処理をすべきかについては即断が難しい。

文字の構成要素は一般的なものでありながら,音義一切不明である。
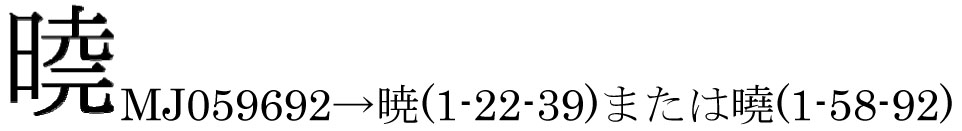
「曉(ぎょう)」の異体字であることは,字典等から明白だが,JIS X 0213には,いわゆる正字体である「曉」と常用漢字体である「暁」がともに独立した面区点位置をもち,一意に決定することができない。
対応するJIS X 0213の符号位置が複数あるものについて,実際の対応付けを行う際には,常用漢字優先などの原則が立てられるものについては,一括して機械的な処理を行い,一定の原則で処理できないものについては,機械的な処理は行わず,出力処理や転記処理などの実務で必要が生じたタイミングで,状況に合わせて現場の判断で対応付けを決定するといった判断が必要であろう。
このようにみてくると,大規模文字集合と小規模文字集合とを対応付ける際には,一括処理に偏ることなく,事後的に現場の判断で処理できるプロセスをシステム的に組み込むことを検討することも,今後の実用システム構築においては重要な技術課題となるだろう。
常用漢字表,JIS漢字コード,戸籍統一文字など,さまざまな規模の文字の表は,いずれも,それぞれに掲示された字形と1対1に対応する字体を要素としてもつ字体集合の存在を想定することができる。そして,それらの字体集合は,原理的には相互に共約不可能である。
それにもかかわらず,複数の文字の表の間を対応付けることは,われわれの実生活,中でも,電子政府などの行政実務には不可欠である。
文字情報基盤整備事業は,このような困難な課題に挑み,一定の成果をあげてきた。東京オリンピックが開催される2020年ごろまでには,国際整合性を担保したうえでの実稼働システムが普及することが期待されている。
一方,世上の一部に,6万字にも及ぶ巨大な文字集合を策定し実運用に供していくことに対する批判があることも事実である。
しかし,汎用電子情報交換環境整備プログラムを含め,関係諸氏による浜の真砂(まさご)を拾い集めるような地道な,ある意味では泥臭い作業により,現代日本社会における行政分野での人名表記のための文字使用の全貌が,ようやく見渡せる状況となってきた。
今後は,文字情報基盤MJ文字情報一覧表のような大規模文字集合に拘泥することなく,実務実態に即した利便性の高い規模での文字集合の運用を心掛けていくことも必要であろう。
また,実態を直視しない空疎な批判ではなく,この文字情報基盤整備事業の成果を含め,実運用の実態を踏まえた,積極的かつ生産的な議論が交わされることを期待する。文字情報基盤整備事業が目指してきたことの1つは,そのような議論を始めるための基盤作りでもあったといえるかもしれない。
本稿の考察は,筆者の永年の国際標準化活動および十余年に及ぶ汎用電子情報交換環境整備プログラム,文字情報基盤整備事業での実体験に基づいている。国際標準化の局面でご尽力いただいた織田哲治委員長(日本IBM),山本知幹事(日立製作所)をはじめとする情報処理学会情報規格調査会SC2専門委員会の方々に敬意とともに謝意を表する。また,両事業にかかわった方々,中でも,平本健二氏(内閣官房CIO補佐官),田代秀一氏(情報処理推進機構国際標準推進センター長),高田智和氏(国立国語研究所准教授),沼田秀穂氏(事業創造大学院大学副学長),池田佳代氏(清泉女学院大学准教授),武藤圭祐氏(情報処理推進機構国際標準推進センター)の各氏とは,まさに苦楽をともにしてきた。あらためて,衷心(ちゅうしん)からの謝意を表する。
情報技術,特に,国際標準化,符号化文字集合,電子書籍を専門とする情報技術コンサルタント。元ISO/IEC JTC1/SC2議長,元Unicode Consortium Director,元International Digital Publishing Forum Director,独立行政法人情報処理推進機構専門委員,明治大学兼任講師,長岡技術科学大学非常勤講師。