総説
行列・テンソル分解によるヘテロバイオデータ統合解析の数理
―第1回 行列分解―

2021 年 1 巻 2 号 p. 18-25
詳細
2021 年 1 巻 2 号 p. 18-25
生命科学分野で取得されるデータ集合は、雑多(ヘテロ)な構造になり、ヘテロなデータ構造を扱える理論的な枠組みがもとめられている。本連載では、汎用的なヘテロバイオデータの解析手法である行列・テンソル分解を紹介していく。第1回では、第2回以降のアルゴリズムの基礎となる、1行列での行列分解について説明する。
生命は幾つもの生体分子(例:RNA、DNA)や現象(例:SNP、CNV)が複雑に関連しあったネットワークで構成される。この大規模なネットワークに関わる生体分子や現象を全て同時に計測することは現在までのところできていない。そのかわりに、生命科学研究ではオミックスと称し、特定の生体分子や現象のみに限定した上で、それらを網羅的に計測するアプローチがとられている。このようなアプローチで得られた雑多(ヘテロ)なデータ集合から、いかに生命現象の全体像を導き出せるかが、今後のバイオインフォマティクス研究の重要な課題の一つだと考えられる。
生命科学データのヘテロ具合は、他のデータサイエンス分野と比べても群を抜いている。例えば、1細胞RNA-Seqデータをとっても、どの遺伝子がどの細胞で発現したのを計測した遺伝子発現量行列だけでなく、その行列が異なるバッチ、実験条件、生物種などで複数あったり、遺伝子に紐づいたパスウェイ情報、下流のターゲット遺伝子、更にそのターゲット遺伝子に関連した遺伝子機能まであったり、細胞に紐づいた情報としても、別のオミックスデータや、細胞の空間配置、その細胞の計測に関する実験的メタデータなどもある(図1)。このような複雑に繋がりあったデータ集合を、どのように解析すべきなのかは自明ではなく、多くの場合、個々に解析をした後に、解析結果を見比べる“ベン図型”アプローチがとられる。例えば、1細胞RNA-Seq解析でよく行われるベン図型アプローチとしては、1細胞マルチオミックス解析で、RNA-Seqで検出された発現変動遺伝子の領域と、ATAC-Seqで検出されたオープンクロマチン領域同士でベン図をとったものや、細胞型ごとの機能アノテーション解析で、まず細胞型ごとに変動する発現変動遺伝子を特定し、次にそれら遺伝子に関わる機能タームをエンリッチメント解析する2ステップの解析などが挙げられる。本連載では、そこからさらに進んで、複数のデータを同時に扱うアルゴリズムを紹介する。このようなアプローチをうまく活用することで、ノイジーなデータからのシグナル検出を他のデータでサポートできたり、あるデータの欠損値を他のデータとの兼ね合いで補完できたり、複数のデータ間を跨いだ予測モデルを構築できるなど、ベン図型アプローチでは実現できない事が可能となる。
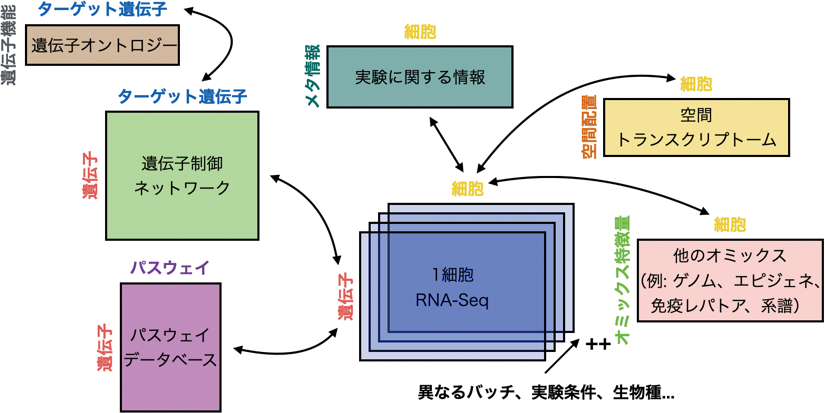
遺伝子×細胞の遺伝子行列に加え、遺伝子、細胞に関する他のデータが互いに繋がりあっている。
本連載では、ヘテロなデータに特化したアルゴリズムを紹介する。なお、近年Webデータマイニング業界では、Heterogeneous Information Networks(HINs[1])というキーワードのもとで、雑多なデータ集合をどのように解析すべきなのか議論されている。HINsの定義は、あるグラフのノードの種類が2種類以上、またはエッジの種類が2種類以上の場合とされているため[2]、本連載でもこの定義を継承する。
本連載で扱うデータは全て類似度行列・テンソルとする。それ以外の尺度(例:距離)は何らかの方法で類似度に変換してから利用するものとする(例:ユークリッド距離⇆コサイン類似度[3]/カーネル類似度[4]、木⇆セマンティック類似度[5])。紹介するアルゴリズムは、行列分解やテンソル分解とする。これは、著者が知る中で、最も汎用性が高く、どれだけデータ構造が複雑化しても統一的に解析できる点や、結果の解釈が容易で、実装しやすく、高速化しやすいアルゴリズムを著者が好む傾向にあるためである。ただし、同様の問題を別の理論的枠組み(例:深層学習、マルチカーネル学習、ランダムウォーク、ベイズ推定)で解くことは可能である[6, 7, 8, 9, 10]。一般論として、パラメーターが多い複雑な非線形モデルの方が、精度で勝る場合も多い。ただし、どのドメインデータのどの問題においても、同じ枠組みが適用できることを知ることは、今後ヘテロなバイオデータを扱うであろう、読者の理解を助けるものと考えている。なお、紙面の都合上、紹介するアルゴリズムの厳密な議論(目的関数の導出、初期値・ハイパーパラメーターの設定方法、解の一意性、生物学的解釈、実データでの性能比較など)はあまり説明できないため、詳細は引用文献を参照して欲しい。また、多くの行列・テンソル分解では、1つの目的関数に対して最適化手法が複数あり、これらは本来分けて考えるべきものであるが、紙面の都合からよく知られた代表的な最適化手法のみを紹介していることや、できるだけ最先端の手法を紹介するために、バイオインフォマティクス分野でまだ利用されたことが無い手法も一部とりあげていることにも留意してほしい。
まずは、この先で説明する全てのアルゴリズムで基本となる、1つの行列における行列分解、特に利用実績が多いPrincipal Component Analysis(PCA)、Non-negative Matrix Factorization (NMF)、Independent Component Analysis (ICA)を説明する[11]。ここでは、n×pの行列Xを分解する。例えば、RNA-Seqデータであれば、nはサンプル数、pは遺伝子数であり、行列の各要素は遺伝子発現量を表す。行列分解では、この行列Xを以下のように近似する。
ここでUは n×kの行列、Vはp×kの行列である。ただし、kは1≦k≦min(n, p)を満たす整数とする。または、U、Vの列ベクトルの長さが1となるように正規化し、その分の重みをΛ(k×kの対角行列)の対角要素にまとめた形で
と説明される場合も多い。このような式が何を意味しているのか、なぜ分解をするのかについて考えてみる。ここでは、読者の多角的な理解を助けるため、「パターンの和としての行列分解」と「射影としての行列分解」を説明する。これらは、本質的には同じ計算を違った角度で見ているだけではあるが、アルゴリズムによっては、どちらかの方法で解釈した方が素直に理解しやすいため、本稿ではこのようなやり方を導入した。なお、Nguyen, N. D.らは、前者のことをFactorizationベースの手法、後者のことをAlignmentベースの手法と分類している[12]。
まずは、パターンの和として行列分解を説明する。行列を分解するということは、すなわち、行列に含まれるパターンを取り出すということである(図2)。例えば、式(2)の右辺をベクトルで書くと、
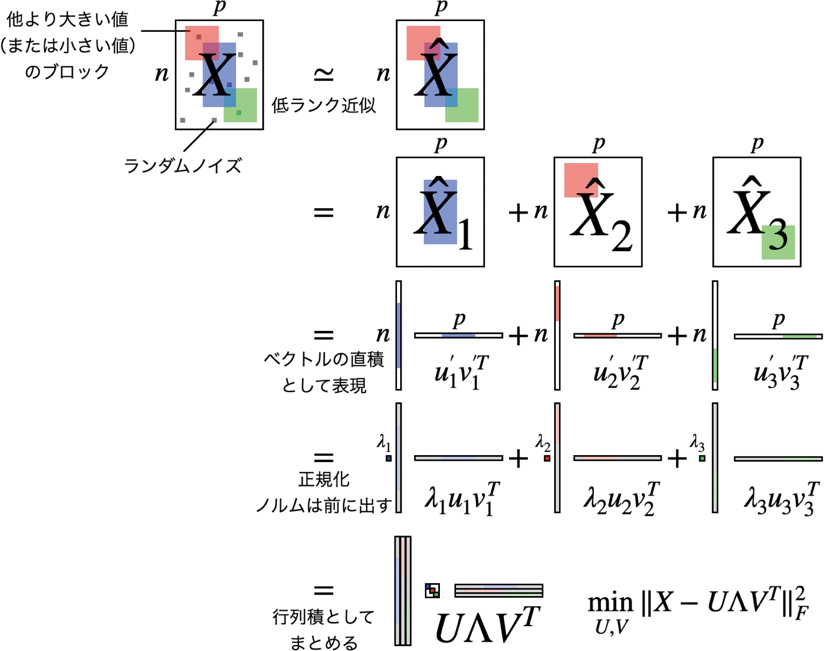
行列分解とは、データ行列を少数のパターン(ランク1行列)の和として近似することに相当。
これらのベクトルやスカラを利用して、さらにデータ解析を進める事ができ、UやVを細胞や遺伝子の特徴量抽出や、可視化、クラスタリングに利用したり、Λでどのパターンまでが情報を持っていそうか確認できる。少数のパターンの和として、データ行列を近似し、それにより行列のランクが下がるため、低ランク近似とも呼ばれる。また、kの値次第では、元のp次元よりも次元が落ちるため、次元圧縮とも呼ばれる。うまくシグナルの特徴をとらえる事ができたら、ノイズを回避してシグナルだけを取り出せるため、ノイズ除去しているとも言える。
実際にパターンを取り出すためには、Xとの誤差がなるべく小さくなるように、以下のようなU、Vに関する目的関数を最適化することになる。
なお、このままではこの最適化問題を閉じた形で解析的に解くことはできず、何かしら制約を設定することになる。PCAでは、列ごとの平均値を0に中心化したデータ行列Xに対して、UT U = VT V = Ikを制約とし(正規直交性、Ik : k×kの単位行列)、後ほど説明する固有値分解(Eigen Value Decomposition; EVD)や特異値分解(Singular Value Decomposition; SVD)で最適化する[13, 14]。
NMFでは、非負値データ行列Xを分解する。因子行列U、Vの非負値性(U, V ≥ 0)を制約とし、式(1)をU、Vで各々微分して勾配をもとめ、勾配法でU、Vを収束するまで交互に推定する最適化手法Multiplicative Update Rule(MU則)を利用して以下のように最適化する [15, 16]。
ただし、ここで∘は2行列の要素ごとの積(アダマール積)、/は2行列の要素ごとの商である。
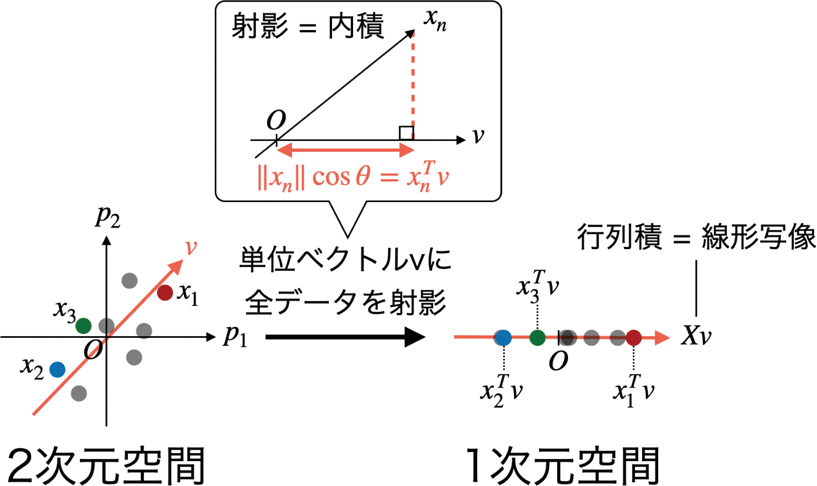
次は、射影として行列分解を説明する。まずは簡単に2次元空間にあるデータ点を、1次元空間に射影する場合を考える(図3)。ここで図3の赤線で示した単位ベクトル(原点を通る長さ1のベクトル)v上に、データxnを射影する。内積の定義(a∙b = |a||b|cosΘ)とコサインの定義から、原点Oから射影先のxnまでの距離は、xnとvの内積値
となる(V+は行列Vの一般逆行列[18, 19])。すなわち、射影としての行列分解の文脈では、行列分解の式(1)の右辺のUはXのスコア、Vは射影行列(ローディング、または因子負荷量ともいう)である。PCAの場合は、列直交性からV+ = VTであるため、さらに簡単にX = UVTとなり、式(1)の形と一致する。
行列積とは、データをベクトル上に射影することに相当。
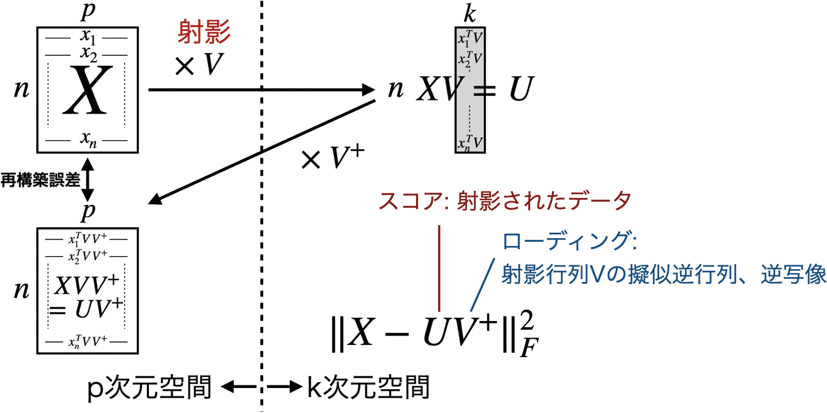
行列分解とは、低次元に射影して、再構築した際の誤差を最小化することに相当。
さて、このVをどのような基準で推定するかが問題となるが、PCAの場合は、列ごとの平均値を0に中心化したデータ行列Xを式(1)のように分解する際に、Uの列ベクトルの分散の総和が最大となるようにVを求める。Vの正規直交性(VT V = Ik、Ik : k×kの単位行列)という制約の下で、var(XV)を最大化する問題はラグランジュ未定乗数法より、Xの分散共分散行列
として解く事ができる(Sは固有値を対角要素にもつk×kの対角行列)。右辺のVを左辺に移項した以下の式
は、ΣXXの対角化といい、対角要素を最大化させることから、トレース(行列の対角要素の和)を使って、
と書くこともある。式(3)を以下のように変形すると、式(3)の誤差最小化と式(9)の分散最大化は同じ意味である事がわかる(Cは定数)。
となることから、UはGXXの固有値ベクトルであり、かつΣXXと固有値を共有していることがわかる。このGXXのEVDはDual PCAやQモードPCAと呼ばれる。Uの列ベクトルを単位ベクトルとするとA2=(nS)−1となることから、UとVの関係性は、以下のようにしてまとめることができる。
この形式はSVDと言われ、k×kの対角行列Λの対角要素は特異値と呼ばれる。特異値と固有値には、Λ2=nSという関係がある。通常のPCA(Rモードという)で得られた固有ベクトルVと、QモードPCAで得られた固有ベクトルUは式(12)により容易に変換できることから、ΣXXとGXXのサイズが小さいほうで計算することで、計算量を削減できる。
なおICAの場合は、列ごとの平均値を0に中心化したデータ行列Xを式(1)のように分解する際に、Uの列ベクトルが互いに独立になるようにVを推定する。ICAの問題設定は、PCAやNMFと比べるとやや特殊で、制約はUのみに設定する。Uの列ベクトル間にいかに独立性をもたせるかで様々なアルゴリズムがある。ICAではまず、計算量の削減と最適化の収束性向上のための前処理として、以下のように白色化という処理を行う。
ただし、Xは列ごとの平均値を0に中心化したデータ行列、VはPCAにおける固有ベクトル、Sは固有値である。Vの列数kをフルランク(min{n, p})よりも小さい値にすることで、Xの次元圧縮も同時に行える。白色化により、Xwhiteの分散共分散行列は以下のように単位行列になるため球状化とも呼ばれる。
相互情報量最小化でスコア間の独立性を定式化するInfomax[20, 21, 22, 23]では、以下のように自然勾配法でUを逐次的に最適化する。
(tは逐次最適化の反復ステップ、η(t)は定数か1/tなどの減衰関数、φ(X)はtanh(X)など何らかの非線形関数)。非ガウス分布性を最大化することで、スコア間の独立性を定式化するFastICA[20, 21, 22, 23]では、以下のように不動点法でUのi番目の列ベクトルuiを逐次的に最適化する。
ただし、Eは期待値であるが標本平均で代用する。Uの列ベクトルは互いに直交になるように、最適化時にDeflation(Gram-Schmidt-like Decorrelation)やLöwdin Symmetric Orthogonalizationといった処理が入る。
今回は、1行列における代表的な行列分解アルゴリズムであるPCA、NMF、ICAを「パターンの和としての行列分解」と「射影としての行列分解」という2つのアプローチで説明した。これらの分解のイメージは、第二回以降の行列同時分解やテンソル分解の理解にも役立たせることができる。
最後に、本稿で紹介した行列分解手法の利用ガイドラインを示しておく。アルゴリズムにより、行列分解の結果に違いが見られる。どの手法が最も優れているのかを決めるのは難しく、データや状況、その行列分解で何をしたいのかに依存するが、大まかな各手法のメリット・デメリットを以下に記す。
まずPCAのメリットとしては、UやVが無相関であるため(直交=内積が0の時、Pearsonの相関係数も自ずと0となるため)、そうでない場合(斜交)と比べて、似たようなパターンが取り出されづらい点が挙げられる。また、Eckart-Young定理[25]として知られるように、SVDは式(2)を最も最小化させることが保証されている。ただしデメリットとしては、直交制約が不利に働いたり、負値を含んだベクトルが解釈しづらい場合もあることが挙げられる。このあたりの改善は、トピックモデル[26]の発展とも関連が深い。またSVDの符号の曖昧さ(Sign Ambiguity)、すなわち
一方、NMFのメリットとデメリットはかなりはっきりしている。メリットとしては、得られるパターンが解釈しやすいことである。Xが非負値でかつ正の方向に変動したパターンにしか興味が無い場合は、NMFではUやVのうち正の方向に大きい要素のみに注目すれば良い。また、正規化されたUやVは、確率ベクトルとして解釈することができ[27]、そのままクラスタリング手法として利用することも可能である[28]。ただし、デメリットとしては、非負値性の仮定が崩れる場合、例えばXが負値を含む場合や、負のパターン(例:負の方向に変動した遺伝子発現)もしくは正のパターンと負のパターンの対比(例:A/Bコンパートメント[29])にも興味がある解析には適さない。またNMFで得られたパターンは、パーツごとに分離されがちで、この特徴はメリットにもデメリットにもなり得る。例えば、NMFは当初顔画像の解析に利用されたが、目や鼻など、顔を構成する小さいパーツを分離し、顔の輪郭のような大きいパターンは取り出さない傾向になることが指摘されている[15]。また大域的最適解が得られる保証が無いため、初期値を変えて複数回アルゴリズムを実行し、ばらつきを調べたり、最も目的関数の値が小さい解を使うなど、やや工夫が必要となる。
ICAは、音声信号処理(ブラインド信号源分離)や脳波・神経活動データなどで実績があり、ガウスノイズを仮定したモデルでは取り出せないシグナルが取り出せる場合がある[20, 21, 22, 23, 24]。デメリットとしては、PCAと同様に符号の曖昧性があること、NMFと同様に大域的最適解が得られる保証が無いこと、また前処理として行われる白色化の影響で、PCAのPC1、PC2のようになんらかの基準(例:分散の大きさ)によって、取り出したパターンを順位づけることが難しいため、どのパターンをより注目すべきか指針を立てづらい点である。
なお、上記の複数の行列分解をかけ合わせることで、互いのデメリットを補うような手法もあり、PCAのように直交性を持たせたNMFやICAとしてOrthogonal NMF[30]、Reconstruction ICA[31]、NMFのように非負値性を持たせたPCAやICAとしてNon-negative PCA[32, 33]、Non-negative ICA[34]といったハイブリットな行列分解手法も提案されている。
Heterogeneous Information Networks
・PCAPrincipal Component Analysis
・NMFNon-negative Matrix Factorization
・ICAIndependent Component Analysis
・EVDEigen Value Decomposition
・SVDSingular Value Decomposition
・MU則Multiplicative Update Rule
 |
露崎 弘毅 2015年、東京理科大学生命創薬科学科博士後期課程終了。博士(薬科学)。同年より、理化学研究所情報基盤センターバイオインフォマティクス研究開発ユニット(現在の所属1)に在籍。現在、基礎科学特別研究員及びJSTさきがけ研究員を兼任。個人としては、世界で最もBioconductorにRパッケージを登録している。(1細胞)トランスクリプトームデータを中心に、複数のデータを統合する解析手法の開発に取り組んでいる。テンソル分解の執筆・講演依頼が多く、テンソル芸人としての地位を確立しつつある。趣味はサーフィン、バイク、料理。 ホームページ:https://sites.google.com/view/kokitsuyuzaki |