原著論文
オンライン調査モニタのSatisficeに関する実験的研究
2015 年 31 巻 1 号 p. 1-12
詳細
2015 年 31 巻 1 号 p. 1-12
本研究は、オンライン調査会社のモニタの回答行動について実験的な比較調査を行うものである。調査によるデータ収集で常に深刻な問題となるのは、協力者の回答に対する低関与とそれによる(研究者にとって)「望ましくない」回答行動であるSatisfice(目的を達成するために必要最小限を満たす手順を決定し、追求する行動)がしばしば見られること、すなわち協力者が調査に際して応分の注意資源を割こうとしないことである。オンライン調査はこうした回答行動が生じる可能性が高い環境であるのと同時に、それらを検出しやすい環境でもある。そこで、オンライン調査環境で、教示や質問文を精読しなければ適切な回答行動ができない調査を実施し、Satisficeに代表される「望ましくない」回答行動の発生率や発生パタンを検討する。
オンライン調査の隆盛とSatisfice問題近年、社会心理学における調査環境は著しく変化している。これまでは、ランダムサンプリングを重視する必要性の高い内容であれば選挙人名簿などから抽出したサンプルを対象とした訪問による面接や留置回収などのいわゆる社会調査が、その必要性が低い内容であれば大学等の講義参加者を対象とした集合場面での調査が、それぞれ一般的であった。しかしそれらに取って代わりつつあるのがWebインタフェースを介したオンライン調査であり、中でも対象者として調査会社の登録モニタ(集合的には「パネル」と呼ばれる)を利用したものが増えている。例えば日本社会心理学会の2014年度年次大会の研究発表のうちこうしたデータにもとづくものは386件中少なくとも41件に達している(大会発表論文集データベースの全文検索機能で「モニタ」「モニター」「パネル」「Web調査」「オンライン調査」「インターネット調査」をキーワード検索し、調査会社のモニタを利用したオンライン調査であることが明記されているもののみをカウントした)。またこれは日本に限らず世界的な傾向でもあり、Amazon社の提供するクラウドソーシングサービスMechanical Turk(MT; https://www.mturk.com/mturk/)を利用して登録者に「タスク」を遂行させるスタイルで調査(あるいは実験)を実施した学術論文が特に英語圏において急増している。
こうしたオンライン調査にはもちろん利点がある。例えば、回答を必須とする条件を付与することで欠損値を減らし(なくし)たり、尺度項目の提示順序をランダマイズして順序効果を相殺したり、教示などによる実験的操作を調査票に含めたり、画像/音声を利用した刺激を活用したり、といった工夫が施しやすい。これにより、よりダイナミックな環境で過不足のないデータ収集が期待できる。
一方、前述したSatisfice問題はむしろモニタを対象としたオンライン調査においてより深刻となる可能性がある。かれらは調査協力に際して(1調査あたりの単価(ないしは抽選により獲得できる期待値)はごくわずかではあるが)報酬を得るため、これを主目的に数多くの調査に積極的に協力するモニタは少なくない。調査協力を「小遣い稼ぎ」の手段であると謳ってモニタを募集している調査会社は複数あり、山田・江利川(2014)では、調査に協力したモニタのうち約7割が平均して1日1件以上、3分の1は2件以上回答していることが示されている。これは従来型の調査の協力者とは大きく異なる傾向であり、かれらが日常的に数多くの調査を「こなす」ことはSatisficeに結びつきやすい可能性がある。研究者にとってみれば、Satisficeの所産として得られるデータは調査結果の解釈を困難なものとさせる点で、きわめて望ましくない。
調査による測定が適切に行われるためには、回答者が項目の意味を正確に理解し、関連する情報を記憶の中から検索し、検索された情報を認知的に統合し、提示された回答形式に合致する反応に変換する必要がある。これらの一連の手順を適切に実行するには認知的負荷がかかるため、常にすべての回答者が最適な回答行動をするわけではない。調査研究で問題となるこうしたSatisfice行動について、Simon (1957)のOptimize(最適化)とSatisficeの議論を応用して体系的な分類を行ったのがKrosnick (1991)である。
Krosnick (1991)によれば、調査回答におけるSatisficeは2つに分類される。1つは弱いSatisficeと呼ばれるもので、調査項目の内容を理解した上で回答しようとしているが、選択可能な選択肢を部分的にしか検討しないといった回答行動が生じる。例えば、人の態度はリッカート尺度上で1点に定められるほど精確なものではなく許容できる幅(“latitude of acceptance”)をもっていると考えられる(Sherif & Hovland, 1961; Sherif, Sherif, & Nebergall, 1965)。弱いSatisficeが生じている場合、左から順にリッカート尺度の選択肢を検討した上で、許容できる幅の中で初めて現れた選択肢を選択してしまう傾向が強まる。この場合、リッカート尺度の左側の選択肢が肯定的な回答なのか、右側の選択肢が肯定的な回答なのかによって回答の分布が異なってしまう。
もう1つは強いSatisficeと呼ばれ、調査項目の内容を理解するための認知的コストを払わず、誰にでも選択可能な選択肢(DK(わからない;Don’t Know)やリッカート尺度の中点など)を選んだり、あてずっぽうに選択したりする回答行動が生じる。本研究が対象とするのは強いSatisficeであり、特に教示文や調査項目を読まずに回答するSatisficeに焦点を当てる(以降、これをさして単にSatisficeとする)。これらの回答行動はデータの質を著しく低下させ、そのデータから得られた推論の妥当性を毀損する可能性がある。したがって、強いSatisficeが生じている度合い、およびその発生パタンを把握し、対処方法を検討することは重要である。
Satisficeの発生メカニズムSatisficeが生じる主要な原因としては、調査項目の難しさ、回答者の能力、回答者の動機づけが挙げられる(Krosnick, 1991)。これらのうち本研究では回答者の動機づけに着目する。回答者の動機づけは、回答者の認知欲求(need for cognition) (Cacioppo, Petty, Feinstein, & Jarvis, 1996)、調査テーマの個人的重要性、調査への回答が何かの役に立つという信念、回答による疲れ、調査主体の姿勢(注意深い回答を要求するか否かなど)に影響される(Krosnick & Presser, 2010)。
オンライン調査に関する初期の研究では、調査モードの違いの観点からその有用性が検討されてきた。オンライン調査と電話調査への回答行動の違いを実験的に検討したFricker, Galesic, Tourangeau, & Yan (2005)は、オンライン調査ではリッカート尺度で測定される態度項目で、尺度上の同じ選択肢が選択されやすいことを見いだしている。これは、オンライン調査で測定される態度項目がしばしばマトリックス形式で提示され、回答行動が単調になりがちであることから発生している可能性がある(Couper, Tourangeau, Conrad, & Zhang, 2013; Tourangeau, Conrad, & Couper, 2013)。これに対して、Chang & Krosnick (2009)は、無作為抽出された標本に対して実施されたオンライン調査ではRDD(乱数番号法)による電話調査よりもSatisficeが少ないことを報告している。これはオンライン調査の方が回答者のペースで時間をかけて回答可能であることが一因として考えられる(Fricker et al., 2005)。また、紙と鉛筆による質問紙調査とオンライン調査を比較したGosling, Vazire, Srivastava, & John(2004)は、オンライン調査回答者の低いモチベーションや高頻度の調査回答は大きな問題とはなっていないとし、心理学研究におけるオンライン調査の有用性を主張している。
しかし、オンライン調査が一般化するにつれて、調査モードによるSatisficeの違いだけでなく、セルフセレクションで集められたオンライン調査パネルの質に関する問題が前景化してきた。セルフセレクションによる代表性の問題に対しては、傾向スコアを使った統計的補正や(e.g., Kobayashi & Hoshino, 2011)、無作為抽出によるオンライン調査パネルの構築2)、セルフセレクションサンプルと無作為抽出データの分布情報を組み合わせたマッチング(Rivers, 2006)などが試みられてきた。しかし、セルフセレクションによって抽出されたオンライン調査パネルのデータは無作為抽出調査と比較して一貫して正確性が低いことが指摘されている(Yeager, Krosnick, Chang, Javitz, Levendusky, Simpser, & Wang, 2011)。前出のAmazon MTのサンプルについても、ローコストな実験サンプルとして適切であるとの報告もあるが(e.g., Berinsky, Huber, & Lenz, 2012)、実験刺激に対する注意のレベルが低く、事実に関する設問ではインターネットを使って正答を探そうとする傾向があることが指摘されている(Goodman, Cryder, & Cheema, 2013)。現在では、Satisficeを行う傾向の強い回答者を事前にスクリーニングする方法がさまざまな形で検討されている(e.g., Berinsky, Margolis, & Sances, 2014; Chandler, Mueller, & Paolacci, 2014)。
日本では、オンライン調査モニタのSatisficeに関する実証的研究はまだあまり多くない。山田と江利川は、一連の研究において複数回答形式と個別強制選択回答形式を比較し、前者においてよりSatisfice(かれらは「最小限化」と呼んでいる)が発生しやすいこと(江利川・山田,2013; 山田・江利川,2013)、これを回避するためには複数選択式の選択肢を減らすことが有効である可能性(江利川・山田,2014; 山田・江利川,2014)を示唆している。また三浦(2014)は、成人のモニタを対象とした調査において、27項目からなるリッカートタイプの5件法尺度の中に「この設問は必ず「一番左(右)」の選択肢を選んでください」の2項目を含め、調査協力者ごとにランダムに出現させるようにした。その結果、協力者1103名のうちどちらの指示にも従わなかった者が207名(19.5%)にのぼり、うち107名は両設問とも中間値3を選択していた。これらの知見は、日本のオンライン調査でもSatisficeが看過できないレベルで発生していることを示唆している。
SatisficeとHouse effectsこうしたSatisficeの度合いはオンライン調査パネルの構築方法や管理方法によって異なる可能性がある。同時期に同一内容の調査を実施しても、調査会社により結果が異なる現象はHouse effectsとしてオンライン調査以前から知られている。例えばアメリカ大統領選挙のキャンペーン中には多くの調査会社が大統領候補の支持率を測定・発表するが、調査会社により±3%程度のバイアスが生じる。こうしたHouse effectsは、調査会社間の方法論的違い(サンプリング方法や調査プロトコル、質問項目のワーディングなど)によっても生じるとされる(Jackman, 2005; Mann & Klofstad, 2015; Smith, 1978)。
オンライン調査会社のHouse effectsについては十分に検討がされていないが、例外としてVonk, van Ossenbruggen, & Willems(2006)によるオランダでのオンライン調査パネルの比較が挙げられる。Vonk et al. (2006)は、オランダの19個のオンラインパネルを対象に160万人以上からデータを集めてパネル間の比較を行った。その結果、パネルの構築・維持方法によるHouse effectsは限定的であったが、Satisfice傾向の強いパネルでは政治的関心や広告・ブランド認知率が低いなどの違いが報告されている3)。また、2010年に発表されたアメリカ世論調査協会によるオンライン調査に関するレポートでも、パネルの特性や方法論に大きな違いがあるため研究者はパネルの選択に注意すべきであると指摘されている(Baker, Blumberg, Brick, Couper, Courtright, Dennis, Dillman, Frankel, Garland, Groves, Kennedy, Krosnick, Lavrakas, Lee, Link, Piekarski, Rao, Thomas, & Zahs, 2010)。日本におけるオンライン調査パネルのHouse effectsに関する研究には大隅を中心とした産学協同研究グループによるもの(例えば、前田・中谷・横田・中田・中島・上嶋・大隅(2007))などがある。パネル間で質や特性に違いが見られる場合はそれによって得られるデータや分析結果が異なってくる可能性があるため、研究者がオンライン調査を使うためにはこうしたパネル間比較に関する情報がきわめて重要である。
本研究の着眼点以上の議論にもとづき、本研究では日本のオンライン調査パネルを対象として、二つの方法を用いてモニタの回答行動に関するデータを収集し、Satisficeの程度を測定する。
一つ目の測定方法では、回答者が調査票の教示文を十分に読み、指示どおりの回答行動を行う程度に注目する。具体的には、まずスクリーニング調査においてOppenheimer, Meyvis, & Davidenko (2009)が開発したIMC(Instructional manipulation check; 図1)を踏襲した設問を用いて、ベースラインとなるモニタのSatisfice傾向を測定する。IMCでは、心理学の調査でよく用いられる回答形式(リッカート法や複数選択式など)の設問に「正しく」答えないように求める教示を付随させることでSatisficeの有無を測定する。Oppenheimer et al. (2009)の研究では、報酬としてコースクレジットか現金10ドルを報酬として約束された大学生を対象としたオンライン調査において、教示に違反した協力者が46%(Study 1)ないしは35%(Study 2)も存在していること、教示を遵守した協力者と性・年齢や報酬の種類には差がない一方で、回答時間(教示違反者が短い)と認知欲求(同・低い)には有意差が見いだされている。

二つ目の測定方法では、三浦(2014)と同様に、多数の項目からなるリッカートタイプの尺度項目を十分に読む程度に注目する。リッカートタイプの尺度は心理学でよく用いられるが、望ましくない回答行動(例えば特定選択肢への過度の集中や相互矛盾する回答など)が見られやすいことがしばしば問題となる(増田・北岡・荻野,2012; 山田,2010)。本研究では、実験参加者をIMCで測定されたSatisfice傾向に応じてブロッキングし、各ブロック内でリッカート尺度の項目数の異なる3種類の本調査に無作為配置する。こうすることで、そもそものSatisficeしやすさ(IMCへの反応)と、調査票の特性(リッカート尺度の項目数)に起因するSatisfice行動を弁別できる。つまり、リッカートタイプの尺度におけるSatisficeがそもそも教示文も読まないようなSatisficeしやすい回答者において顕著に見られるのか、それともそうしたSatisficeしやすい先有傾向とは独立に、項目の多さに応じた「厭気」のような形で発現するのかを明らかにする。
さらに、House effects検討のために2つの調査会社間の比較も行う。日本国内のすべてのオンライン調査パネルを対象とした比較はコストの面から現実的ではないが、2つの調査会社間比較でもSatisficeの度合いに違いが見られれば、調査会社を選定する際にHouse effectsに対して十分な注意を払うことの必要性を示すことになるだろう。
モニタ登録者を協力者とするオンライン調査サービスを提供しており、社会心理学の研究でよく利用されている5社を対象として、目的(モニタの回答行動に関する調査会社間の比較)を伝えた上でスクリーニング調査と本調査の全質問項目を提示して調査実施を打診し、うち2社(以降、A社とB社とする)から応諾を得た。A社とB社の登録モニタのうち、成人男女(A社36125名、B社81900名)を対象として協力依頼メールが送信された。なお、パネルの構築・維持方法によるHouse effects要因として、調査協力に際する報酬の形式が両社で異なる点がある。A社では協力者の中から抽選により一定人数にのみ報酬が付与され、B社では協力者全員に報酬が付与される。方法論的な違いにもとづくHouse effectsに関しては、画面の標準的なフォーマット(色やクリックボタンの形状など)は各社独自のものを用いたが、調査タイトル「あなたの生活に関するお伺い」、改ページやワーディングなどは完全に同一とし、極力統制することを試みた。
調査期間2014年8月8日12時~2014年8月13日13時(A社)あるいは8月8日12時~2014年8月9日9時48分および8月13日12時25分~2014年8月13日23時7分(B社)。調査開始時間は2社で同一としたが、終了時間は本調査への協力を依頼する予定数(1800件)を満たす数の回収終了までの所要時間が異なり、同一とはならなかった。またB社はデータの回収要件に関する誤解があり、必要サンプルを回収する前にいったん調査を終了させてしまったため、2回にわたって調査依頼とデータ収集が行われたが、両回で依頼を受けたモニタはいなかった。
質問項目個人属性(性別・年齢・居住地域/婚姻状況・子ども有無/職業;全3ページ)、IMC項目、社会経済地位(Socioeconomic Status; SES)に関する主観的評価(1(もっとも低い)~10(もっとも高い)と「答えたくない」から1肢選択)、他社へのモニタ登録有無、をこの順に問うた。また、設問単位ごとにページを改め、回答後は前ページに戻れない仕様とした。IMC項目は、Oppenheimer et al. (2009)にならい、「以下の質問には回答せずに(つまり、どの選択肢もクリックせずに)次のページに進む」旨を明記した教示文の後にリッカートタイプ(「あてはまらない」~「あてはまる」の5件法)の質問項目を3つ並べる形式(順序は回答者ごとにランダマイズ)とした(図2参照)。なお、調査実施を打診したうち3社が不可とした理由は、いずれもこのIMC項目が「モニタに不快感を与える」と判断したものであった。また、質問項目への回答以外の回答行動に関する変数として、調査全体とページごとの回答所要時間(秒)を取得した。

スクリーニング調査への協力者の中から一定の基準でスクリーニングを行い、本調査への回答を依頼した。スクリーニング基準については「結果」節で詳述する。
調査期間2014年8月20日12時~2014年8月25日13時(A社)あるいは8月26日9時30分(B社)。調査開始時間は2社で同一としたが、終了時間は同一にはならなかった。なお調査期間中の回答の督促については特に統制をしなかったが、A社は行わず、B社は22日と24日の2回にわたって行った。
質問項目分析の中心となるのは、Satisficeを測定するために用意されたリッカート尺度である。本研究では、性格検査の際にもっともよく用いられているものの1つとして性格の主要5因子を測定する尺度を用いた。5因子性格検査短縮版FFPQ-50(藤島・山田・辻,2005)を参考にして、総項目数の異なる3条件(5因子に該当する項目が2/6/10項目となる10/30/50項目)を作成し、これにSatisficeを測定するための「この質問は一番左(右)の選択肢を選んでください」の2項目を加えた。藤島ら(2005)と同じく「1.全くちがう」「2.ちがう」「3.どちらとも言えない」「4.そうだ」「5.全くそうだ」の5件法による回答を求めた。なお、項目順序は回答者ごとにランダマイズした。また、スクロールによって項目のみが画面に表示された状態になる(選択肢が見えなくなる)事態を防ぐために、10項目程度ごとに選択肢を再表示させるレイアウトとした。本調査への協力者を総項目数の異なる3条件に無作為配置するため、リッカート尺度の項目数の多寡がSatisficeに及ぼす因果効果を推定することが可能となる。
さらに、因果効果の推定の効率性を高めるため、Satisficeに効果をもつと予測される共変量としてオンライン調査への協力頻度と学術研究に対する信頼を測定した。協力頻度は週単位の数値回答で測定され、頻度が高いほど個々の調査回答における動機づけは低下することが予想される。学術研究に対する信頼は、Krosnick & Presser (2010)によって調査回答者の動機づけへの影響が指摘されている「調査への回答が何かの役に立つという信念」に対応し、文系(例として心理学・社会学・政治学を挙げた)・理系(同・医学や化学、工学)のそれぞれについて「研究成果が社会の役に立っている」「研究者が信頼できる」「研究内容に関心がもてる」の3項目・5件法によって測定した。これらの共変量は実験者によって操作される変数ではないため、因果効果を推定することはできない。
調査の仕様はスクリーニング調査と同様とし、タイトルは「あなたのお考えに関する調査」とした。調査全体とページごとの回答所要時間も取得した。
スクリーニング調査の回答総数は、A社6561名、B社7980名であった。まず、回答者の重複を避けてパネルの質の差によるHouse effectsを検出可能にするため、他社モニタ登録を「なし」と回答した協力者のみを本調査の対象とした。その結果、スクリーニング調査への協力者のうち他社モニタ登録を「あり」または「わからない」と回答したモニタ(A社4431名、B社5943名)のデータはこの時点で分析対象から除外された。また、A社ではモニタが回答時に使用していたWebブラウザの設定上の問題で回答所要時間が測定できなかったケースが6件、B社では同社基準による「不正回答」が16件あったため、それらのデータを除外した。さらに、B社では回答の中断と事後の再開を認めていることも影響して所要時間が非常に長いものが見られたため、調査全体で3600秒=1時間)を超える17件を除外した(A社では3600秒を超えるものはなかった)。その上で、本調査の対象とする1800名をそれぞれランダムに抽出した。以降の分析は抽出されたデータに関して行った。なお、協力者の個人属性・SESに、除外モニタと抽出モニタの違いは特に見られなかった。また、抽出モニタにおける調査会社間の違いもほとんどなく、やや異なるのは性別構成のみで、A社には男性(特に正社員)が、B社には女性(特に専業主婦やパート・アルバイト)が多い傾向があった。
IMC項目への回答IMC項目は、教示を遵守した場合(以降「遵守群」と呼ぶ)には3項目とも「無回答」となり、3項目のいずれか1つでも回答(任意の選択肢をクリック)した場合は教示に従っていないことになる(以降「違反群」と呼ぶ)。違反群(そのほとんどは全3項目に回答していた)の比率はA社51.2%、B社83.8%で、調査会社間で顕著な差が見られた(χ2(1)=437.79, p<.001)が、一方で両社ともにOppenheimer et al. (2009)よりも高い違反率を示した。これはサンプル抽出元の母集団の質の違いによるものとみなすことができよう。Oppenheimer et al. (2009)の協力者は第2筆者の在職する大学の学生(授業受講者)から抽出されており、調査会社のモニタとは母集団が大きく異なる。このことは、調査協力に対する動機づけの違いに影響している可能性がある。
教示の遵守に影響をもつ変数を把握するため、協力者による教示の遵守/違反を従属変数とし、個人属性(性・年齢・未既婚・子ども有無)とSES、調査会社を独立変数とする名義ロジスティック重回帰分析を行ったところ、B社モニタ、男性、高年齢、既婚、子どもありの協力者において違反率が高かった(ps<.05; Cox–Snell’s R2=0.13)。このうち調査会社によるHouse effectsについては本調査の結果も含めて後に議論する。
Satisfice傾向と回答所要時間遵守群と違反群で、IMC項目およびその前後の項目(群)に対する回答所要時間を比較するために、遵守/違反群と調査会社を独立変数とする多変量分散分析を行った(各群の平均値を表1に示す)。まずIMC項目に対する回答所要時間には遵守/違反群による主効果が見られ、遵守群の方が違反群よりも長かった(p<.001)。その分布を見ると、遵守群では30秒以上かけた協力者が全体の85%に達し、60秒以上も30%程度いたが、違反群では30秒未満が80%、ほぼ半数が15秒以下で、遵守は「教示の精読」、違反は「教示の読み飛ばし」によるものであることが強く示唆された。これはOppenheimer et al. (2009)と呼応する結果である。
| 個人属性1 性別・年齢・居住地域 | 個人属性2 婚姻状況・子ども有無 | 個人属性3 職業 | ||||
|---|---|---|---|---|---|---|
| A社 | B社 | A社 | B社 | A社 | B社 | |
| 遵守群 | 21.5(76.07) | 20.6(111.04) | 8.5(28.78) | 7.7(10.74) | 11.4(94.04) | 7.8(26.29) |
| 違反群 | 17.6(48.50) | 17.6(83.78) | 9.0(36.99) | 9.0(37.73) | 6.9(13.33) | 8.7(77.57) |
| IMC | SES | 他社登録有無 | ||||
| A社 | B社 | A社 | B社 | A社 | B社 | |
| 遵守群 | 59.3(83.82) | 61.8(45.56) | 31.6(39.31) | 32.4(15.83) | 7.7(11.13) | 10.6(24.59) |
| 違反群 | 28.0(47.55) | 23.4(63.55) | 19.4(21.31) | 25.1(88.24) | 8.8(6.10) | 11.3(5.59) |
また、IMC項目前後の項目(群)に関する回答所要時間を比較したところ、IMC項目より前に配置された個人属性項目には遵守/違反群と調査会社の主効果は有意ではなかった一方で、後に配置されたSESと他社モニタ登録の有無については、SES項目で遵守/違反群の主効果が有意(遵守群>違反群)であった(p<.001)。この結果は、IMC遵守群はIMC項目により「教示を精読すべき」という規範を獲得し、画像刺激(ラダースケールの図)を含み、また教示文も比較的長いSESに関する項目にも、内容を精読してから回答するよう動機づけられたことを示唆している。なお、他社モニタ登録の有無はごく短い質問文であったが、B社の方がA社よりも回答所要時間が長かった(p<.001)。
本調査への協力者の無作為配置調査会社ごとに、本調査に対する協力者の無作為配置を行った。600サンプルずつを、リッカートタイプの尺度の項目数に関して3パタン用意した調査に、遵守群と違反群にブロッキングした上でブロックごとに完全無作為配置した。
本調査協力者の特徴本調査への回答を依頼した1800名中、回答を完了した有効回答者数は、A社1297名(10項目版431名、30項目版444名、50項目版422名)、B社1575名(それぞれ523名、529名、523名)であった。A社の方がやや有効回答率が低かったが、各社内の総項目数条件間で有意差はなかった。つまり、回答総項目が多くなったからといって脱落率が高くなるとはいえない。このことは、多くのオンライン調査が最後まで完答することで謝礼が支払われる仕組みとなっていることと関連している可能性がある。
表2に調査会社ごとの協力者の個人属性やSES、オンライン調査への協力頻度、文系/理系の学術研究への信頼(単純加算して0-1のレンジに一次変換した(文系:A社α=0.86, B社α=0.86、理系:A社α=0.83, B社α=0.86)の比率・平均(SD)データを示す。オンライン調査への協力頻度(週単位)に調査会社間の差が顕著に見られ、B社の方がA社より有意に高かった(t(2870)=12.74, p<.001)。山田・江利川(2014)と比較すると、A社は週1回あるいはそれ未満が6割以上と少なめであり、B社は1日1回以上が約6割、3割程度が2回以上回答しており、ほぼ同程度であった。
| A社 | B社 | |
|---|---|---|
| 性別(男性%) | 60.1 | 49.3 |
| 年齢(平均(SD)) | 47.7(13.37) | 47.2(16.75) |
| 結婚歴(既婚%) | 75.0 | 70.5 |
| 子ども(あり%) | 60.8 | 56.4 |
| 職業(主要4種%) | ||
| 正社員 | 27.1 | 24.0 |
| パート・アルバイト | 4.1 | 6.8 |
| 主婦 | 14.2 | 20.4 |
| 無職 | 11.5 | 14.6 |
| SES(平均(SD)) | 5.8(1.82) | 5.4(1.85) |
| オンラインモニタ調査協力頻度(平均(SD)) | 5.32(14.71) | 18.06(25.99) |
| 文系学術研究信頼性評価(平均(SD)) | 0.60(0.22) | 0.56(0.20) |
| 理系学術研究信頼性評価(平均(SD)) | 0.70(0.19) | 0.63(0.20) |
有効回答率との関連を見ると、A社では男性、子どもあり、IMC違反群ほど有効回答率が高く、B社では年齢が高いほど有効回答率が高い傾向が見られた。サンプルの脱落による共変量バランスの悪化の有無を確認するため、リッカートタイプ尺度の総項目数3条件への割り当てを従属変数とし、上記の共変量を独立変数とする多項ロジットモデルを推定した。その結果、Joint-probability testはA社IMC違反群でp=0.39、A社IMC遵守群でp=0.97、B社IMC違反群でp=0.91、B社IMC遵守群でp=0.19であった。いずれも共変量によって割り当ては有意に予測できておらず、脱落による共変量バランスの毀損は見られなかった。
リッカートタイプ尺度項目への回答リッカート尺度項目に含めた「この項目は一番左(右)を選択してください」に対する回答について、「左」については「1.全くちがう」以外、「右」については「5.全くそうだ」以外を選択した協力者においてSatisficeが生じているとみなす。少なくとも1項目において協力者が項目文の指示とは異なる選択肢を回答した場合を「Satisfice」、2項目とも指示どおりの選択肢を回答した場合を「not Satisfice」とすると、協力者全体(2872名)のうちSatisficeが生じていたのは383名(13.3%)であった5)。それらの内訳を、調査会社およびIMCブロックごとに示したのが図3である。縦軸はそれぞれのサンプルにおけるSatisfice率を表す。
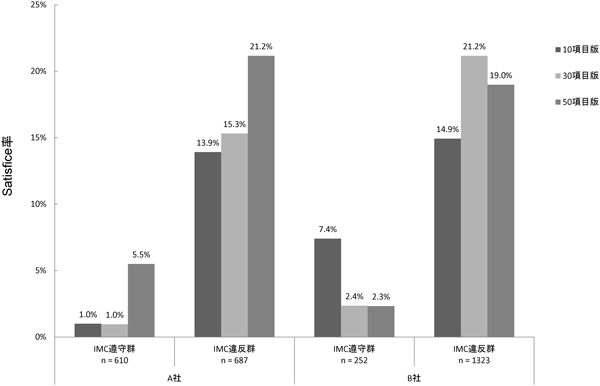
まず、Satisfice率は最大でも2割強であり、予備調査におけるIMCと比較するとSatisfice率はかなり低い。このことから、長い教示文は読み飛ばしても、リッカート尺度の個々の項目内容は読んでいる回答者が多いことがわかる。IMC遵守群と違反群でプールした場合、IMC遵守群でのSatisfice率は2.9%、違反群では17.8%であり、この差は有意(p<.0001)かつ顕著であった。また、調査会社ごとにプールしたSatisfice率を見ると、A社で10.0%、B社で16.1%であり、この差も有意であった(p<.0001)。予備調査と同様にA社の方がSatisfice率は低いが、この差はIMCで見られたものほど大きくはない。つまり、前述の「教示文は読み飛ばすが尺度項目の内容は読む」という回答行動はB社においてより顕著に見られた。
Satisfice率の条件間比較次に、無作為配置した総項目数条件間でSatisfice率を比較する。まずA社では、IMC遵守群と違反群ともに10項目条件と30項目条件ではSatisfice率にほとんど差が見られない一方、50項目条件では4~6%程度高くなっている。このことから、A社のモニタは少なくとも30項目程度のリッカート尺度項目は内容を読んだ上で回答しているが、50項目を超える尺度の場合は回答疲れによる動機づけの低下によってSatisfice率が高まっていることがうかがえる。A社のIMC遵守率が約5割であったことをふまえると、A社モニタを対象に50項目以上の尺度を測定しようとすると約1割の回答者は尺度項目の内容を読まずに回答することが予測される。一方B社の場合はA社よりもやや複雑なパタンを示している。まず、IMC遵守群では30項目条件と50項目条件の場合に10項目条件よりもSatisfice率が低下する傾向が見られた。また、IMC違反群では30項目条件は10項目条件よりもSatisfice率が6%程度高いものの、50項目条件のSatisfice率は30項目条件よりも低くなっていた。こうした総項目数に対する非線形な反応がB社において生じた理由については明らかではない6)。しかし、A社の場合はIMCに対する反応と実験刺激(総項目数)の主効果がストレートに現れるのに対して、B社の場合は両者の間に複雑な交互作用が見られるという結果は、どの調査会社のモニタであるかによって同一刺激に対する反応のパタンが異なるというHouse effectsが生じる可能性が高いことを示している。
また、「Satisfice」協力者による、本来の5因子性格検査短縮版を構成している尺度項目に対する回答傾向を見ると、すべての項目に中間値3を回答している協力者が40/106, 46/134, 42/143名(順に10, 30, 50項目版)ともっとも多かった。この「かなり強い」いわば確信犯的なSatisfice傾向7)をもつ可能性が高い協力者の出現比率には、総項目数のパタンによる差はなかったが、調査会社間では差が見られ、A社(2.85%)よりB社(5.78%)で高かった(χ2(1)=14.29, p<.001)。また、調査全体の回答所要時間には群間で有意差が見られ、調査会社によらず、どの調査パタンでも「Satisfice」協力者の方が短く、同群においては50項目版の所要時間が30項目版とほぼ同程度であった(回答所要時間の平均値 10項目版:Satisfice 130.0秒–not Satisfice 226.2秒、30項目版:199.0秒–291.0秒、50項目版:196.1秒–392.7秒)8)。これはOppenheimer et al. (2009)と同様の傾向である。総じて、本調査において項目を精読しなかった協力者には、元来調査協力への動機づけが低い確信犯的なSatisficerに、そこまで動機づけが低いわけではないが項目数の多さに「厭気」がさしたことによって一時的に生じたSatisficerが上乗せされていると考えられる。
Satisfice傾向に対する尺度項目数の影響最後に、Satisfice率の差の統計的有意性を検討する。独立変数は無作為配置したリッカートタイプ尺度の総項目数の3条件で、10項目条件を参照カテゴリとして30項目条件と50項目条件を表すダミー変数を作成した。共変量には、性別ダミー(女性が参照カテゴリ)、年齢、既婚ダミー、子ども有無ダミー(子どもありが参照カテゴリ)、職業ダミー(会社勤務(一般社員)、パート・アルバイト、主婦、無職)、SES(予備調査を参照)、オンライン調査への週平均回答頻度、文系・理系の学術研究に対する信頼を用いた。
以下では、調査会社およびブロック(IMC遵守群・違反群)ごとに本調査におけるSatisficeを予測するモデルを推定する。調査会社をプールした分析をしないのは、本研究はオンライン調査パネルごとにモニタの特性が異なる可能性に注目しており、独立変数および共変量の回帰係数が調査会社間で等しいという強い仮定をおくことが適切ではないためである。加えて、無作為配置はブロックごとに行っているため、独立変数の効果もブロックごとに推定するのが適切である。また、IMC遵守群と違反群で独立変数および共変量の回帰係数が等しいという仮定は強すぎると考えられる。実際、図3のB社で見られるように、IMC遵守群と違反群では総項目数に対する反応パタンが異なっている。なお、独立変数の係数をそのままSatisfice率の増減として解釈可能であること、従属変数のセルの度数が小さい場合に最尤法による推定が不安定になる現象を回避できることから、推定は最小二乗法で行った9)。推定の結果を表3に示す。
| A社 | B社 | |||
|---|---|---|---|---|
| IMC遵守群 | IMC違反群 | IMC遵守群 | IMC違反群 | |
| Coef.(B) | ||||
| 30項目 | 0.005(0.015) | 0.014(0.034) | -0.070*(0.028) | 0.066*(0.026) |
| 50項目 | 0.045**(0.015) | 0.062†(0.035) | -0.045(0.028) | 0.038(0.026) |
| 女性 | -0.026(0.016) | 0.008(0.040) | -0.041(0.029) | -0.021(0.027) |
| 年齢 | 0.000(0.001) | -0.005**(0.002) | -0.001(0.001) | -0.002*(0.001) |
| 既婚 | -0.042†(0.022) | 0.005(0.047) | 0.021(0.043) | -0.007(0.036) |
| 子どもあり | 0.012(0.019) | 0.075†(0.040) | -0.017(0.040) | -0.007(0.031) |
| 正社員 | 0.006(0.017) | 0.006(0.034) | 0.000(0.034) | 0.032(0.029) |
| パート・アルバイト | 0.006(0.023) | -0.075(0.061) | -0.011(0.038) | -0.046(0.039) |
| 主婦 | 0.011(0.023) | -0.150**(0.057) | 0.102**(0.039) | -0.046(0.038) |
| 無職 | -0.022(0.022) | 0.055(0.056) | 0.040(0.040) | -0.061(0.038) |
| SES | -0.002(0.004) | -0.003(0.008) | -0.004(0.007) | 0.005(0.006) |
| オンライン調査への週平均回答頻度 | 0.001(0.001) | 0.001(0.001) | -0.001(0.001) | -0.000(0.000) |
| 文系学術研究に対する信頼 | -0.005(0.039) | 0.184*(0.076) | -0.014(0.072) | 0.090(0.071) |
| 理系学術研究に対する信頼 | 0.002(0.047) | -0.396**(0.084) | -0.198*(0.077) | -0.329**(0.073) |
| 定数 | 0.029(0.044) | 0.495**(0.089) | 0.283**(0.061) | 0.405**(0.058) |
| N | 578 | 674 | 241 | 1260 |
| 決定係数 | 0.037 | 0.083 | 0.142 | 0.053 |
カッコ内は標準誤差**: p<.01, *: p<.05, †: p<.10
推定の結果、A社においてIMC遵守群と違反群ともに、50項目条件では10項目条件よりもSatisfice率が4~6%程度有意に高まることが示された。また、B社ではIMC遵守群で、30項目条件の場合に10項目条件よりも7%程度Satisfice率が低下する有意な効果が見られたが、50項目条件と10項目条件の間では有意な差は見られなかった。B社のIMC違反群では30項目条件では10項目条件よりもSatisfice率が6.6%上昇する有意な効果が見られたが、50項目条件と10項目条件の間では有意差は見られなかった。
本研究は、オンライン調査会社のモニタの回答行動について、特に「望ましくない」それとしてしばしば問題となるSatisficeに焦点を当てて検討した。Satisficeを検出可能な2種類の設問(教示と尺度項目)を含む調査を2社で同時実施し、Satisfice傾向の発生頻度や発生パタンを比較検討した。教示の読み飛ばしによるSatisficeは非常に頻繁に生じることが示され、尺度項目の読み飛ばしによるSatisficeは相対的には少ないがその発生パタンに調査会社によるパタンの違いすなわちHouse effectsが見られた。
Satisfice率、特にIMC項目の遵守/違反率と「より強いSatisfice」傾向に調査会社間による差が見られたことは、House effectsの中でも興味深い知見である。A社とB社は調査協力に対する報酬の形態が異なる。A社は協力者からの抽選による付与であり、スクリーニング調査では100名に500円が、本調査では200名に500円が支払われた。一方、B社は協力者すべてに同額がポイントとして付与され、スクリーニング調査では数円、本調査では50円未満の数十円(いずれも正確な数値は開示されなかった)が支払われた。両社ともに独自の「不正回答」チェック基準を設定しているが、本研究の2つの設問については、どのように回答しても「不正」とはみなされない。報酬額の期待値はあまり変わらないとしても、「何かを回答すれば確実に報酬が獲得できる」場合に、とにかく協力頻度を高めようとするストラテジーが働きやすいのは当然のことであろうし、それに呼応して「教示や質問項目を精読し、正確に回答する」ことに対する動機づけの低いモニタが増加する可能性は否めない。なお、本研究ではスクリーニング調査の段階で複数の調査会社に登録しているモニタを排除したため、2社の特徴がより際立った形で析出されていることには注意が必要である。
本研究の結果、オンライン調査においてあらかじめスクリーニング調査を実施することは、それ自体が事後の調査における協力率を高め、またそこにSatisfice傾向をもつ回答者を特定できる強めの設問をおくことによって、Satisficeの含まれにくいデータを得やすくなる可能性が示された。スクリーニング調査にどのような「仕掛け」を施すかは、研究者がどのようなデータを得たいのか、つまりその研究目的や調査内容に依存する。単にいくつかの尺度項目の評定を求めることが目的で、またその項目内容もそれほど複雑でないなら、IMCほど強力な設問によるスクリーニングをする必要はなく、きわめて回答への動機づけが低い、ごく短い質問項目すら読み飛ばすような人を特定するだけで十分だろう。一方で、教示文の内容で条件を操作する実験的調査を実施するのであればIMCは有効であろうし、違反者を本調査対象に含めないことも検討した方がよいだろう。ただし、IMCのような「正しく」答えないことを求める設問を許容しない調査会社もある。
オンライン調査は、従来の方法と比べてデータ収集にかかるコストが低く、また収集できるデータの量と質の両方を充実させうる有効な手段であることは間違いない。一方で、特に協力者の質に本研究のデータが如実に示す現状もある。実際、Mechanical Turkの普及を背景に、Satisficeを防ぐさまざまなスクリーニング方法が開発されつつあることは前述したとおりである。ただし、Satisfice傾向をもつ回答者を特定することとそれを排除することは、完全に同義というわけではない。いつも誠実に教示文や質問項目を熟読する回答者はSatisficeによる汚染を受けない「優良」なデータを提供してくれはするが、オンライン調査のモニタにおいてはむしろ少数派である可能性が高い。となれば、Satisfice傾向をもつサンプルの排除によってデータの質を高める努力が一方では研究の外的妥当性を低めることにつながり、本来のオンライン調査のメリット—学生などを対象としたConvenience sampleを用いるより外的妥当性が高い—を毀損しかねない。本研究の知見が示しているのは、データによる実証科学である社会心理学において、研究者は常に自らの研究目的や調査内容に照らして、より適切な場所、より適切な方法は何かをよく吟味した上で、慎重にデータ収集にあたる必要がある、というごく当然の事実である。