世論調査の「回収率の低下」が問題となって久しく,多くの議論が展開されてきた.しかし一方で,世論調査と他の調査との適正な分類や各調査の目的に応じた課題への対処がなされていない懸念がある.この背景には,各分野で調査に従事している人々が,先人が築き上げてきた調査の歴史と理論と実践の現場を必ずしも把握できていないことをあるのではと推察させる.
本論文では,調査方法論を根本より再考することにより,世論調査と他の調査を区別し,今日の調査研究の課題を考える上での示唆を試みる.1 節で問題提起をする.その問題の解決を念頭に,2 節で世論調査の歴史を振り返り,3 節で海外の世論調査の方法について概観する.4 節では確率論の基礎の数学的定義を確認する.これらを考慮しながら,5 節では調査に関する用語の意味を再確認し,6 節では調査の分類に応じた課題に対して提言を試みる.最後に7 節で将来の展開へコメントする.
「電車でいつも進行方向に向かって座るのだが,今日は逆方向に座ってしまい,気分が悪くなり,とても困った.」
「なぜ,前に座っている人に代わってもらわなかったの?」
「うん,それが問題なのだ.頼みたくても,前には誰もいなかったから.」
(1990 年Stanford 大学での日米国民性研究会議にて,国民性研究の大家Alex Inkeles による小話.問題のないところに問題を見て,本当の問題を見失っている学者への皮肉である.)
科学的分析は,多くの場合,ものごとを分別,分類することから始まる.その分類は明確な基準によることもあろうが,「本質的なものは目には見えない」というサン=テグジュペリの「星の王子様」の台詞は科学においても有効であり,人文社会科学の複雑な事象においては暗黙の基準によることもあろう.われわれは「データの科学」と称する統計哲学を調査研究として実践する中で,人文社会科学で扱う複雑な事象に対してそれに相応するデータ解析で現実を浮かび上がらせるアプローチを具現してきた(林, 2001; 林・山岡, 2001; 吉野, 2002; 吉野・林・山岡, 2010).
世論調査において回収率の低下が問題となって久しい.例えば,社会調査協会の「社会と調査」5 号(2010 年発刊)ではこの問題について特集が組まれ,調査の実践現場の様子等,貴重な情報が得られる.しかし一方で,各種の調査の分類や区別が必ずしもできておらず,それに応じた課題への対処に懸念が禁じえない.冒頭に記したInkeles の小話のように,「解答」ではなく,「問題」を間違えている人々が多いのではないかと思える.この背景には,各分野で調査に従事している人々が,戦後,先人が築き上げてきた歴史と理論と実践の現場を必ずしも把握できていないことがあるのではと推察させる.
回収率低下の問題は,既に70 年代に回収率が70%近くまで落ち込んだ時に,杉山(1973) が論じている.その後,しばしば「回収率は70%以上であるべき」という基準が用いられていたが,それも難しい時代に突入した.しかし,そもそも「回収率70%以上」という数字の根拠を人々が正確に把握しているとは限らないようである.その数字は,例えば内閣支持への賛否が回収標本で60% : 40% のとき,仮に観測不能の未回収標本で賛否の率が40% : 60% のように大きく賛否が逆転していても,回収標本と未回収標本の総計での賛否(真の値)が回収標本の賛否とは逆転しない回収率として示されたのであった.その考えから言えば,より低回収率の場合でもそれに応じた解析の仕方が示唆される(吉野, 2006).
他方で,調査研究の権威的機関Michigan 大学ISR の研究者らが示すように,回収率だけではデータの質を示す良い指標とはならない(Schouten, Cobben, & Bethlehem, 2009, p. 101).他に良い指標が見つからず,多くの人々が「回収率」にしがみつき,なおかつ,現実の調査で低い回収率に直面し,問題視しているのが実情であろう.回収率を無理のない形で維持するリテラシーに加え,バイアスのあるデータでも適切に解析できるリテラシーが重要なのだが,「調査環境が悪化しているから回収率が低くなり,信頼できる分析ができない」とするのは,解析リテラシーのない者の責任転嫁になりかねない.
本論文では,これらの問題を考えるに当たり,以下,2 節では世論調査の歴史を振り返り,3 節では海外の世論調査の方法について概観する.4 節では,確率論の基礎の定義を再確認する.これらを考慮し,5 節では調査に関する用語の意味を確認し,各調査の区別について注意を促す.6節では調査の分類に応じた課題に対し,提言を試みよう.最後に,7 節で将来の展望に触れる.
統計数理研究所では,半世紀以上にわたり「日本人の国民性」に関する調査を続けている.この先駆に,「日本人の読み書き能力調査」がある.これは,当時,日本の占領に携わったGHQ/SCAPの指示で,文部省のもとで統計数理研究所,国立教育研修所,後の国立国語研究所のスタッフを含め,社会学,心理学,言語学,統計学,その他の関連分野の研究者が遂行した学際的研究であった(読み書き能力調査委員会,1951).
この読み書き能力調査の背景には,漢字使用が日本人の初等・中等教育に困難を生じ民主主義の発展を阻害しているので公用語をローマ字化すべきという議論があり,この問題に関連し米国からの教育視察団が報告を出したことがあった(CIE, 1946/1979).実際には米国の政府や軍部の人間関係が複雑に絡んでいたらしいが(レイ, 1992),結果から言えば,日本の歴史,言語や文化を深く研究していた米国人研究者たちの主張が通り,現地の実態と住民の意向を尊重して事を進めるという民主主義の大義を守り,実証的調査を日本人の手で遂行させた.
国勢調査のような悉皆調査は費用も時間もかかり,すぐに政策立案の資料とするためには現実的ではない.そのため,性別,年齢,職業,学歴,収入,居住地を含め,すべての属性に関して偏らずに,日本人全体の縮図となるように,人々の集団(標本)を例えば1 万人選び出し,その集団の調査結果から日本人全体の様子を推定することが必要となる.
2.2. 標本抽出理論と民主主義「日本人の読み書き能力調査」に携わった人々は,GHQ/SCAP の中のCIE(民間情報教育局)から入手した本を勉強し,日本の実情に則した標本抽出計画を練った(高倉, 2004).その「理論」を検証するため,小田原市の集合調査で重病人等を除き成人全員を調べた.そして,その回答者全体の調査票から一部を統計的に無作為に取り出し,それから計算される「推定値」と,「全体の値」とを比べ,標本抽出理論の有効性を確認したという(林, 1951).
実は,「標本抽出理論」自体は,既に大正13 年亀田豊治朗により,単純ランダム・サンプリングの誤差計算がなされ,世界統計学会の大会でも報告されていた(高橋, 2004, p. 109).当時,これは関東大震災の被害調査等に用いられたが,世論調査には結びつかず,戦後に米国から逆輸入されるという形になった.どんなにすばらしい理論も,世の中の問題解決のための実践と結びついて初めて発展するという重要な教訓を示している.
読み書き能力調査の結果,日本人の能力が確認され,民主主義を発展させるのに問題はなく,「日本語のローマ字化」の話は収まったといわれる.これは,さらに戦後民主主義を発展させる基盤として,政府やマスコミが「科学的世論調査」を推進させることに繋がって行った(吉野, 2009).(「科学的」とは,統計的に誤差の範囲が評価できることである(林, 1976, p. 12).)
他方で,この実践的標本抽出方法を活用し,占領終了後の1953 年には統計数理研究所の「日本人の国民性」調査が開始され,これは,やがて米国のGSS,欧州のEVS やユーロ・バロメター等,諸外国が同様の時系列調査を始める刺激となった.
民主主義発展のための世論調査はGHQ の下で開始されたが,世界の中で,整備された住民基本台帳や選挙人名簿が活用できる日本のみが統計理論上からは理想に近い標本抽出が可能となっている.戦後,長年にわたり「日本の民主主義は民主主義ではない」という欧米からの批判があったが,世論調査の方法に関しては,日本は世界で最も民主主義的であろう.
海外では,整備された住民基本台帳や選挙人名簿がない場合が多く,厳密には統計理論上は望ましくない方法をやむなく用いている国々が多い.ただし,統計学的視点ではなく,政治的な歴史や背景がそれらの方法を正当化する面にも留意すべきである.世論調査の方法に各国の政治,経済を含め社会状況が反映されるともいえよう(吉野・林・山岡, 2010).
3.1. 東アジアの状況中国本土では,標本抽出に活用できる可能性のある名簿は,政府,公安,居民委員会(自治会)が各々持っているが,一般には利用できない.筆者らは2001 年より中国調査に乗り出したが,北京と上海の都市部に限定しエリア・サンプリング(住宅地図を作成し,ランダム・ルート法を適用し,各世帯ではKish 法により個人抽出)をした.現在では中国のマスメディアも頻繁に世論調査を遂行しているが,標本抽出法の詳細は不明である.
実質上,一党独裁体制のシンガポールでは,国民の住居(高層集団住宅が多い)が統制されていて,通商産業省統計局の世帯名簿を用いることができる.家計調査を念頭においた名簿なので,各世帯の住居形態(高層マンション,一戸建て等)で層別されている.香港でも類似の名簿が活用される.
韓国は,韓国GALLUP では独自に全国レベルの世帯名簿を作成しているが,(コストや回収率の問題のためか)常にそれを用いるのではなく,性別・年齢層別の割り当て表に従い一定数の回答者をランダム・ウォークで抽出する割り当て法を用いることが多い.
結局,東アジアで統計的に比較的問題の少ない形で全国・全地域レベルの面接調査が可能なのは,「東アジア価値観比較調査」(吉野, 2005) や「環太平洋価値観国際比較調査」(吉野, 2010) で扱われた日本,韓国,台湾,香港,シンガポールくらいであろう.
3.2. 欧米の状況スイスやオーストリアでは電話番号の電話帳への登録が義務づけられていて,調査モードの効果の問題は別にして,電話で標本抽出調査ができる.(しかし,携帯電話やIP 電話なども登録,公開しているのであろうか?)
欧米では,ランダム・ルート法(米国ではランダム・ウォーク法と称す)がよく用いられている.この方法では,調査地点は国勢調査データに基づき確率比例抽出し,各地点でランダム・スタート点をきめ,道路の例えば左側に沿って3 軒おきに訪問し,各戸では有権者の中から誕生日法やKish の乱数表などで個人を特定し調査する.拒否された場合は3 軒先の家を訪ね,これを例えば各地点10 名という回収目標数に到達するまで繰り返す.この方法では計画標本に対する「回収率」という概念はなく,標本抽出誤差は推定できない.回答者を抽出する際の恣意性は排除されているが,母集団に対する標本の偏りが大きくなる危惧がある.また,誕生日法やKish 法では個人抽出確率が世帯の有権者数に依存するため,回収標本について世帯有権者数の逆数比例でウェイト補正しなければならない.しかし,これは調査協力率が100%の場合は有効であるが,実際の回収データは男子若年層が少なく中年の主婦層が多いなどの偏りがあり,このウェイト「補正」をすると,さらにバイアスが大きくなる危惧がある.これは先述のエリア・サンプリングでも同様である(吉野・林・山岡, 2010).
米国では,クォータ法(割り当て法)が面接調査では多く用いられている.クォータ法の場合,地点は国勢調査データに基づき確率比例抽出し,各地点で,あらかじめ指定された属性(性,年齢層,人種等)に関しては国勢調査データに整合させ,地点ごとに定められた標本数の各属性に該当する人をランダム・ウォーク法等で抽出するのだが,この割り当ては精確には容易ではない.例えば性,年齢層,人種だけの割り当てとしても,それらの3 重クロス表に基づいて人口比例で,各地点で例えば計画標本数10 名の属性割り当てを考え,なおかつ全国総数での人口比率との整合性を確保するのは簡単ではあるまい.特に問題なのは,各地点で実際の回答者の抽出にどの程度の恣意性や偏りが入るのかということである.確かに,あらかじめ指定された属性については母集団から偏らないが,指定外の属性の偏りを防ぐことへの配慮は実践の場に依存する(Sudman, 1966).
また,通常,標本抽出調査では若年男性層を回収し難いが,事後に国勢調査データの属性分布に合うよう,回収データに「ウェイト」をかけ,見かけ上,「補正」することがよく行われている.これについては,もともと偏ったデータ(例.回収された若年男性層は,若年男性層全体から偏っている可能性がある)を,さらに想定外の方向へ偏りを助長させる可能性がある(吉野・林・山岡,2010).(ただし,あらかじめ指定した属性以外は回答分布に影響ないという強い仮定が本当に有効であれば,ウェイト調整は正当化される.)
それでは,統計的には望ましくないとされるクォータ法がなぜ世論調査に用いられているのであろうか?
標本抽出理論が既に確立した後に,戦後の民主化の発展のために科学的世論調査方法の開発をみた日本とは異なり,欧米の民主主義発展の歴史では,まず階級,人種,男女の平等が謳われ,そのような社会では利益の異なる集団間の公平性に極めて敏感で,集団間の権利の適正な「quota」が求められる.クォータ法を「割り当て法」と訳すために誤解を生ずるが,quota は権利や義務に強く結びついた分配(率)のことである.その大義の前では,同じ階級や人種,性別でも個人差が存在するという問題以前に,まず,法律で平等とされる性や年齢や人種について適正なクォータが求められるのであろう.
各国や地域は,それぞれの社会で収集された調査データに基づいて,政策立案につながる判断をしている.これを狭い統計理論の見地からのみ批判するのは適切ではない.各国・各地域の歴史や政治的背景から確立している,いわば「調査文化」を尊重すべきなのであろう.
海外の標本抽出調査方法については,さらに詳細は鈴木(1996),鈴木・柳原(2003),吉野・林・山岡(2010) を参照していただきたい.
標本抽出理論の数学的基礎には確率論がある.初歩の確率論は,Laplace (1812) によって与えられた次のような定義がもとになっていることが多い.
着目する事象が全体でn 通りの場合があり,そのいずれも同様に確からしいとする.その時,ある事象A がr 通りの方法で出現するとき,A の確率は,r/n と定められる.例えば,サイコロを1 回振り,その出目を着目する事象としよう.出目は6 通りあり,各目が出る確率が等しいと仮定できるのであれば,例えば,丁の出る事象の数も半の出る事象の数も3 通りであるので,それぞれの確率は3/6(= 1/2) となる.
この定義で「同様に確からしい」という表現が,確率を定義するのに確率を用いているパラドクスと批判される.実際,歴史が示すように,「確率」の直観的概念を数学的に厳密に定義することは容易ではなく,現在でも深遠な議論が継続している(園, 2007).しかし,長年の議論の末に,一応,数学的体系としては,確率空間の定義はKolmogorov (1933) によって確立されたとしてよかろう.
Kolmogorov の測度論的確率着目する事象全体からなる集合を標本空間といい,Ω で表す.標本空間Ω の部分集合からなる族F で次の条件を満たすものを,Borel 集合体という.
(1) Ω はF に属する.
(2) A がF に属すれば,A の補集合もF に属する.
(3) Ak(k = 1, 2, 3, · · ·) がF に属するとき,それらの和集合もF に属する.
この定義から,Borel 集合体は集合の交わり,差集合についても閉じていることが分かる.このとき,F 上で定義された実数値関数P(A) で次の3 条件を満たすものを確率測度という.
(1) F の任意の要素A について,P(A) ≧ 0
(2) P(Ω) = 1
(3) F の要素Ak(k = 1, 2, 3, · · ·) において,互いに排反(2 つの交わりが空集合)のとき,Ak(k = 1, 2, 3, · · ·) の和集合に対応する値は,P(Ak)(k = 1, 2, 3, · · ·) の和になる.
このようにして定義される(Ω, F, P) を確率空間といい,P を確率測度という.F の任意の要素A について,P(A) ≦ 1, P(φ) = 0, P(A の補集合) = 1 − P(A) となる.
Kolmogorov の定義にもまだ問題があることを指摘する立場もある.例えば,Kolmogorov の体系のBorel 集合体は「無限」に関わり,1 階の述語論理では記述できないことを証明し,1 階の述語論理だけで記述する質的確率論を志向する研究がある(Narens, 1985).また,林(1951, 1993)はKolmogorov 流の確率論に満足せず,より直観的なVon Mises の「コレクティフ」という概念に着目していたが,その概念に基づいて厳格な理論体系ができたわけではなかった.本論文では,これらの論理学的議論までは立ち入らないことにする.
Laplace 流の確率を,Kolmogorov 流に見直せば次のようになる.
数学的モデルサイコロ投げの出目を対象事象とするとΩ = {1, 2, 3, 4, 5, 6}, F = Ω の部分集合全体で,F の任意の要素A に対して,P(A) = (A の要素の個数)/6 とおくと,(Ω, F, P) は確率空間をなす.
確率を定義するとき,必ずΩ, F, P の三つ組みがセットになっていることに注意する.したがって,標本空間が同じであっても,確率空間が違えば,違う確率となる.同じ標本空間でも異なる確率空間が導入できることを警告したBertrand の逆説と呼ばれる例を示そう.もとの説明はより詳細であるが,ここでは簡明に示すにとどめる(種村, 1999).
(例)Bertrand の逆説「与えられた円に任意に1 本の弦を引くとき,この弦の長さが内接正三 角形ABC の1 辺の長さより大きくなる確率を求めよ.」
この問題に対し,Laplace 流の定義の「同様に確からしい」ということの解釈によっては,いろ いろな確率の値が出る可能性を,1888 年にBertrand が指摘した.
(1) 一定の方向を持つ直線群は円の一つの直径の上でそれらの交点が一様ランダムに分布し,直線の方向はこれと独立に一様分布すると仮定する.この時,円と交差する直線群の中で,条件を満たすものは円の中心から半径の半分の距離の内部に存在しなければならないので,求める確率は1/2 となる.
(2) 直線と円とは一般に2 点で交わるが,これらの交点が円周上で一様分布すると仮定する.この時,一つの交点は固定でき,他の交点が条件を満たす範囲に存在する確率は1/3 となる.
(3) 円の中心から直線に下した垂線の足が円の内部を一様に分布すると仮定する.その時,条件を満たすためには垂線の足が円の半径の2 分の1 の同心円の内部に存在しなければならないので,確率は1/4 となる.

Bertrand の逆説は,「各事象の生じる同程度の確からしさ」に複数の解釈がある場合,それぞれ異なる確率計算の結果をもたらすが,Kolmogorov 流の定義では,同じ標本空間Ω を扱っていても,Borel 集合体F とそれに応じた確率P が異なる場合があるのは不思議ではない.つまり,数学に矛盾があるのではなく,自身が確率空間をどのように構成するかで現実とそのモデルとしての確率空間に矛盾が生じるか否かの問題なのである.(1990 年頃に盛んに議論された「3 囚人問題のパラドクス」は好例であろう(日本認知科学会, 1988)).
ある集合から任意の1 つの要素X を取り出すとき,Laplace の定義のようにはどの要素がとられるか「同程度に期待」されない場合もある.その場合,実数値関数である確率密度関数F(X) を(1) 任意のX についてF(X) ≧ 0,かつ(2) 定義域全体におけるF(X) の定積分= 1 となるように導入し,任意の事象A について確率P(A) は,A におけるF(X) の定積分で定義する.
日本の世論調査専門家の中では,アンケート用紙を用いた調査だから「アンケート調査」というのではなく,標本抽出理論に基づいていない調査を「アンケート調査」もしくは「アンケート」と称する.アンケート調査のデータは記述統計として扱えるが,日本人全体の何%がどういう意見を持っているかという推測統計としては扱えない.
5.2. 「ユニバース(universe)」と「母集団(population)」と「標本(sample)」統計学の専門ではない辞典やweb 上で公開されている大学の講義録などには,「母集団と標本は統計の専門用語であるが,ユニバースは違う」,「ユニバースと母集団は同じである」等の記述がみられる.教科書や概説書の類でも,ユニバースに一切触れず,母集団と標本の説明から入っているものも多い.西平(2004) の「統計調査法」は1957 年以来のロング・セラーであるが,同書のレベルではユニバース(調査対象)と母集団の区別は不要として,詳細な記述はない(同書, p. 42).鈴木・高橋(1998) は,その区別に注意を促しながらも,説明の便宜上,「母集団(調査対象集団に属する各個体の目的項目の値の全体)」を「調査対象集団」と混用している(同書, p. 11).
杉山(1984) は,例えば東京都の知事選挙での有権者の投票行動の調査では,調査対象は「東京都の有権者全員」,母集団は「それらの人々すべての都知事選での投票行動」としている.「母集団」とは問題とする標識全体であり,その標識を担う人たちの集団を「調査対象の集団」として区別している.さらにその改訂版(杉山, 2011) では,「調査対象」と実際の「調査相手」の区別も強調している.林他(1991) は,水野・林・佐藤(1951) の考えを踏襲するものとして,上記の区別も明確になされている.林(1993, pp. 22–23) ではユニバースの即物的定義(調査対象の人や物)と論理的定義(回答など観測事象)を区別し,いずれにせよ,ユニバースとそれに抽出確率を付与した母集団とは区別している.
一人一票の民主主義を具現する投票やそれを擬した世論調査では,調査対象とユニバースと母集団の対応関係は自明なので区別は不要として済ませることができたのであろうが,ここでは再考してみよう.以下の論理や解釈が唯一可能でも,最善でもないかもしれないが,将来の建設的な展開へ繋げるための試行錯誤を意図する.
世論調査の理論において,「ユニバースの各要素を抽出する事態の全体集合」をKolmogorov の定義の「標本空間Ω」と見なせる.ここで,「ユニバース」は林(1993) の「即物的定義」では「調査対象者の全体の集合」と考えられる.ユニバースの各要素を抽出するオペレーションが特定され,この時,各要素に抽出確率が付与され,母集団はBorel 集合体F と抽出確率測度P が導入された確率空間(Ω, F, P)とみることができる.
他方で,(林1993) の「論理的定義」でユニバースを「調査事象(調査対象者の意見など)の全体」と考えると,例えば同じ有権者全体を扱うのでも何を調べるか(調査項目)でユニバースは区別され,したがって母集団(Ω, F, P)も区別され,それに応じ適切な標本抽出の方法や確率計算も一般には異なり得る.
例えば,世論調査(内閣支持)では,調査対象者i(= 1, 2, · · ·,n) の回答「支持」,「不支持」という事象をAi として,ユニバースは即物的定義で{i},論理的定義で{Ai} となり,各人または各事象に対応する抽出確率をPi とするとΣi Pi = 1.0 となる.一人一票の民主主義における世論調査の場合, = 1.0 となる.一人一票の民主主義における世論調査の場合,Pi はi によらず等しくなる.この制限の下で,Pi に関連して求めるべき統計量を推定するために,適正な標本抽出のデザインが考えられる.
ここで,ユニバース(人や回答)の「比率分布」と,標本抽出デザインにおける「抽出確率」は別であるのに注意する(林, 1951).また,個人の回答過程にも確率を導入することは可能だが,通常,回答は固定したものとしている(本節末の注を参照).
同じ対象者集団を扱うのでも,市場調査や学術調査では目的の違いが確率空間の導入の仕方に違いを生み,それに応じ標本抽出法が異なる場合があり得よう.さらに,面接,自記式,電話等の調査モードにより,同じ回答者でも回答が異なってくることを考慮すると,世論調査では「特定の質問項目に対して特定の調査モードで得られる日本人の有権者の回答の全体の集合」がユニバースと考えられる.ただし,ユニバースの各要素は個人識別標識で弁別できるとする.それらの集合に整合的に確率計算ができるような構造(Borel 集合体F の構造と抽出確率測度P)を入れたのが母集団と考えられる.つまり,「調査対象者」は日本人の有権者全体であっても,何についての意見を調べたいか,それをどのように抽出し,どのような調査モードで調べるかまで考慮するとユニバースも区別できる.ユニバースの各要素について属性の標識の次元をどう捉えるか,母集団の構造が異なり,それに応じて,得られる計算結果も異なり,適切な標本抽出の仕方も異なる場合があろう.
例えば,日本の世論調査では,理論的にはあらゆる属性を考慮して,全調査対象のリストから統計的無作為抽出する.米国のクォータ法では,多くの場合,人種・性・年齢層等の属性を考慮し,同じ属性内の個人差は誤差とみなされる(ここではSudman (1966) 流の割り当て確率標本抽出法を想定しており,標本抽出誤差を考慮しない「単純な割り当て法」については考慮の外である).
(注.なお,個人の認知過程まで踏み込むと複雑になる.特定の標本集団に対して,同じ質問を,例えば数か月の間をおいて再び尋ねる調査をパネル調査という.その間に社会的環境の変化がなくとも20~60%くらいの個人の回答は変動するが,全体の賛否の回答比率は安定していることが分かっている(統計数理研究所・研究リポートNo. 26, 49, 52).また「おはじき調査」と称する実験調査で,「賛成と思う比率」と「反対と思う比率」を回答させると,人々は「個人の内なる少数意見」(心の中で賛否の比率分布)を持っていて,各調査時点では賛否のどちらかが観測されるのが分かる(統計数理研究所・研究リポートNo. 59).これも確率過程としてモデル化可能だが,本論文の範囲を超え,将来の展開を待つ.)
5.3. 標本抽出誤差と非標本抽出誤差例えば,日本人の成人全体1 億人の番号リストがあるとして,標本サイズ(n 人)に対応して,数学的に1 から1 億までの間のn 個の重複しない「乱数」を発生させ,それに対応する人々を一つの標本とする(単純無作為標本抽出).結果として,調査主体の恣意性を排除し,かつ,確率的にあらゆる属性について偏らないように代表標本を選び出せる.そのような操作を繰り返せばn 人の標本がいくつも得られるが,調べるべき統計量(例.母集団の内閣支持率p)の各標本での観測値p′は少しずつ異なるであろう.その統計的分布の標準偏差の2 倍をもって「標本抽出誤差」(95%の信頼区間)とすることが多い.
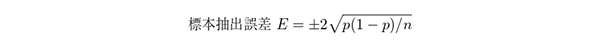
これはp = 0.5 のとき最大となるので,一つの調査票の多数の項目について,概数として と比べ,それ以下の差は統計的には意味があるとは言えないと解釈する.
と比べ,それ以下の差は統計的には意味があるとは言えないと解釈する.
現実には,コストを勘案して,多段抽出を行うことが多い.例えば,全国をいくつかのブロックに分け,各ブロックは多くの国政選挙の投票区の単位で構成され,各ブロックの人口比例で投票区(調査地点)数を例えば400 地点割り振り,各地点で住民基本台帳や選挙人名簿から25 名ずつ,統計的に無作為に選び出すような2 段抽出が行われる.2 段抽出の場合,概数として,単純無作為標本抽出の1.75 倍程度の誤差を見込むことがある.同じ統計的無作為標本抽出でも,実践手続きでは細部に違いがあるため,現実の実験的検討で試行錯誤された数字が扱われている(杉山・小寺, 1994).
さらに,現実には完全には防げない調査員の勘違い,記録ミス,データ捏造等の不正行為,等々の非標本抽出誤差も勘案する.林(1984) では,調査の各段階での綿密な確認作業は前提としたうえで,さらに標本抽出誤差と同程度の非標本抽出誤差を見込むことを示唆している.林(1984),西平(2004) は,回答者のウソの率,調査員によるメーキングに触れている.
標本抽出理論については,西平(2004),林(1984),林(2002),鈴木・高橋(1998),杉山(1984)が参考になろう.誤差推定の定量的な理論は有効回収率が100%であることを想定しているが,抽出標本のうち,転居,住居不明,病気や死亡等で面接不能な人,単身赴任者や特殊な労働している人等,接触困難な人々がいるので,回収率が100%ということはない.本人や家族から調査拒否されることも多い.100%ではない場合については,吉野(2006) が参考になろう.「データの科学」では,非現実的な仮定の下での統計的検定は参考程度の使用であり,多次元データ解析の活用でデータの安定性を解析することが多い(吉野・林・山岡, 2010).
また,調査モードの差異や,理論上は同じ標本抽出でも実践上の差異(鈴木, 1964),調査機関による差異(機関の名前の効果等),調査員と回答者のパーソナリティタイプの関係(青山, 1959;鈴木, 1964) 等にも注意する.こういった実践研究の成果は統計数理研究所・研究リポートに発刊されているが(http://www.ism.ac.jp/editsec/kenripo.html),内閣府やマスコミ各社による実験調査研究は各機関のノウハウとして蓄積され,公刊されてはいないものが多い.この辺りの事情が,調査の実践現場を知る本当の専門家と,公刊されている論文や書籍のみで勉強している学者たちとの間に大きな差を生んでいる.
5.4. 世論調査と社会学的調査の区別—意見調査と意識調査フランスの社会学者Bourdieu (1984) は,世論調査は3 つの「前提」に立っているが,現実にはそれらの前提は満たされていないと警告している.西平(2009) はそれと関連させ,日本の世論調査に対して以下のような疑問を呈した.
1.「聞かれたから答えただけ」というような不確かなものを,その人の意見としてよいか?
2. 当該の調査のテーマと直接関係がある「当事者の賛成」と,それには全然関心がない「第三者としての賛成」を同じ賛成として数えてよいか?
3. 社会・政治・経済・外交,教育,学術などなど,あらゆる問題に対してすべての人々が意見を持っているとして,皆に調査する意味があるのか?
西平(2009) は多面的に世論調査の現状を検討しているが,以下に筆者の観点からその主旨をまとめ,次節での実践的提言の参考としよう.
欧米の世論調査は,政治問題や具体的な社会政策について賛成・反対の二者択一の意見投票がほとんどで,疑似国民投票というべきものである.アメリカでは世論調査のことをpublic opinionpoll という.poll とは,かつてのイギリスで投票権に結び付いたpoll tax(人頭税)からきていて,これが後に投票数の意味となった.他方で,欧米のconsciousness 調査やattitude 調査は意見構造の分析を目指すものであり,社会学的な調査というべきものであろう.日本では「意識調査」と称するが,海外の文献でconsciousness survey というのは見当たらない.また,深く因果関係まで調べるような日本の社会学的調査を世論調査形式の大規模観察でできるのか疑問である.世論調査形式で,大規模観察できるのは,二者択一の意見投票で賛成が何%という程度のもので,日本の社会学的調査には無理があろう.
前述の「3. だれもがいかなる問題についても意見をもっているのか」については,日本では戦前は皇国史観や儒教道徳など,戦後は民主主義という社会的ノルムがあり,自分で意見を作るのではなくて,世の中はこういうものであるということを教え込まされる傾向が強い.さらに毎日,マスメディアが世論調査と接触をさせ,入試対策では「正解探し」教育をさせ続けている.このような環境が,世論調査の回答における「社会的望ましさ(social desirability)」(たてまえ)の効果を強くしている.
また,日本の世論調査では深く踏み込み「意見の理由」まで追求しようとする.そうすると,欧米人は自身の意見を強化する理由を並べるが,日本人は逆に「賛成といったが,反対論にも傾聴すべき点が沢山ある」等と言い始め,自分の意見を弱める傾向が強い.
以上のような考察は,現行の世論調査が本当に「民衆の意見を集約した」といってよいのか疑義を呈する.
本節では,各調査の分類を意識し,特に世論調査とその他の社会調査について,それぞれの本来の目的に応じた調査方法を見直すための示唆を試みよう.
6.1. 世論調査 6.1.1. 一人一票の民主主義における世論調査内閣府の遂行している世論調査や,放送法(第44 条)に「公衆の要望を知るため,定期的に,科学的な世論調査を行い,かつ,その結果を公表しなければならない」と規定されているNHK の世論調査が,これに該当する.調査結果は,調査方法とともに速やかに公表し,結果は,研究者の仮定に基づく複雑な尺度化や多変量解析などはせず,単純集計表や,せいぜい性別や年齢層別のクロス集計表等を公表する.
狭義に「世論調査」とは,ユニバースが有権者全体であり,有権者が一人一票を有することを尊重し,各人の意見の抽出確率は等しくならねばならない.この場合,十分な時間やコストをかけて,厳密な統計的無作為標本抽出方法を遵守すべきである.(他方で,国政選挙で,有権者の一票の重みの平等が大きく崩れているのは大問題である.)
現在の「回収率の低下」は,主として「拒否」と「不在者」の増加に伴うものである.他方で,当該の調査に無関心な人々や,調査拒否するものに執拗に尋ねても,いい加減な回答やマスメディアで報じられていることを鸚鵡返しするだけである.また,回収率向上の特別な努力は,しばしば主婦層,高齢層の回答を増やすだけで,データの質向上には必ずしもつながらない.
一つの考えとして,本人に接触できた上での(強い)調査拒否は,それも回答のうちと捉えることができる.選挙でも,投票しなければ他の人々に結果が委ねられたものと見なされ,投票率が低いといって選挙結果が無効になることはない.しかし,病気や死亡などの場合を除き,不在等で回答者に接触できない事態は解決を図るべきであろう.つまり,回収率向上には,拒否率の低減よりも,まず,標本となる回答者への非接触率を低減させるべきである.
また,ある回答者から協力拒否されても,別の面接員が協力要請すると応じてくれるという場合は少なくない.調査会社のコスト削減のために各調査地点で面接調査員が1 名に限定されてしまっている現実は問題が大きい.
他方で,そもそも政治・経済・外交等の複雑な問題において,頻繁な世論調査が必要なのか?日露戦争の終戦締結に関する過激な世論の沸騰(日比谷焼打ち事件)や,昭和31 年前後の日ソ条約に関する世論の急激な変化が思い起こされる(林, 1984).報道に流される「大衆の世論」に従っていては,結局,世論に裏切られることを,過去の経験から学ぶべきである.民衆をプロパギャンダで操る国家は,逆に他国のプロパギャンダや民衆の反乱に怯える国家であろう.調査回数を減らし,重要で必要な調査に日数とコストを十分にかけた方がよいのではないか.
なお,Sudman (1966) はクォータ法を統計学的に正当化する「無作為的クォータ法」を論じている.それによると,回答分布に関しては統計的無作為標本抽出に近似され,調査期間は多少短縮されるので緊急調査には向くが,コストは削減されることはない.しかし,米国は当時,面接調査で6 週間かけていることや,調査コストの削減にはならないことを考慮すると,最近の日本の調査機関がコスト削減の方法として,無作為性を十分には考慮していないクォータ法を採用しているのを正当化するものではない.米国のクォータ法も,現在では,安易なstreet-catch(道行く人に調査)はともかく,mall-intercept(ショピングセンターで住民調査)等を正当化しようとするように,困難を極めている様相である
6.1.2. RDD 電話世論調査この10 年以上,既に,RDD 電話世論調査は「世論調査」としての市民権を得てしまった.電話調査は固定電話を持たぬ人を除外しているので,「一人一票の民主主義のための世論調査」ではありえず,1990 年代初めまでは飽くまでもその近似としての可能性が慎重に検討されていた.しかし,国政での小選挙区制に伴う調査区の急増とコストとの勘案から,マスコミの選挙予測は面接調査から電話調査,さらにRDD 電話調査に移行し,さらに世論調査も多少の時間遅れを伴いながらも,その道を辿った.
世論調査には「国民投票の擬制」としての役割があるが,近年のマスコミの頻繁な世論調査報道,特に内閣支持率の人気投票並みの扱いは簡単に政権を揺るがす力を不当に持ってしまっている.web アンケートは無論,電話RDD 調査など,その方法による回答の精度や,深く突っ込めば意見を弱める日本人の傾向などを考慮すると疑義は深い.
筆者は電話RDD 調査を完全に否定するものではない.ただし,これを「世論調査」とは区別し,その近似を目指す「世論動向調査」として活用すべきと思う.
6.1.3. 選挙予測のための世論調査この場合,最終的に予測結果の当否が分かるので,その都度,その当否から必要な修正する等の正当化ができる.多少,質の劣るデータでも経験的に予測の成績が良ければ活用される.したがって,成績とコストを勘案した調査方法を採用すれば十分である.この予測には,無党派層や団塊の世代など,日本全体の中での主要な各サブ集団のプロファイリングが重要で,それができていれば,たとえ全体を偏りなく調査できていなくとも,一部のデータを適正に読み解いて,全体の動向を大きな間違いがなく推定できよう.
6.1.4. 日本人全体を対象とする市場調査や学術調査市場調査や学術調査でも,世論調査と同様に日本人全体を対象としたい場合がある.しかし,それらの調査の目的を考慮すると,一人一票の民主主義のための世論調査とは,林の即物的定義でユニバースは同じでも母集団が異なる.市場調査の場合,最終的には性・年齢層等の外的属性で特定される集団の嗜好や行動の傾向を市場の戦略に結びつけるのが目的であるから,その市場に関し主要因となる属性について偏らず抽出されていることが必要十分である.そのため主要因の属性についての割り当て法が用いられることも多いし,また,それらの属性に関するウェイト調整,さらには傾向スコアによる推定などが正当化されることもある.
学術調査でも,初めて挑む研究テーマで当該の調査対象について知識の蓄積がない探索的調査であれば,世論調査と同様の統計的無作為標本抽出が理想であろう.しかし,過去の研究で当該の調査テーマに影響を与える主要因が既知である,あるいは理論で主要因が特定されるのであれば,無作為標本抽出で低回収率のデータを得るよりも,割り当て法で主要因に関し十分な数の標本を得る方が妥当であろう(6.3 も参照せよ).
6.2. 各世帯の生活に関する実態の世帯調査家計調査等,世帯内で一人が代表して回答すればよい場合,各世帯の抽出確率が等しくなるようにすれば十分である.エリア・サンプリングによる世論調査では個人抽出確率を等しくする補正が問題となるが,世帯調査ではこの問題はない.
全国の家計調査等では,全国の推計値,各県別の推計値,さらには各県別の差異の検定等が目的となることが多い.全国の推計では,各県の世帯数に比例させて標本抽出する.しかし,県間の比較で同じ精度で標本抽出するには,各都道府県の全てで十分な大きさで,かつ同じ標本サイズを用いることとなる.現実には,全国レベルの推計も各都道府県間比較も目的なので,総標本サイズを抑え,かつ各都道府県間もある程度の精度を保つ比較には,ネイマン比例割当(鈴木・高橋, 1998) が一つの方法である.
6.3. 統計科学的な学術調査(社会学的調査)「日本人の国民性」調査は,厳格な標本抽出調査法によって遂行されているが,これは学術調査,あるいは社会学的調査である.統計数理研究所は世論調査を含む各種の調査方法論研究とともに,統計手法の開発を目的としているので,厳格な統計的無作為標本抽出法に固執し,他方で世論調査には用いられない多次元データ解析等,統計技法を開発する試行をしている.この調査は,戦後の調査研究における模範として教育啓蒙の一翼を担ってきたが,他方で,学術調査すべてに同様の標本抽出法を用いなければならぬという誤解を与えてきたかもしれない.これが,現行の学術調査における混乱の一因になっている懸念があり,もし,そうであれば正すべきである.
例えば,国立国語研究所では「岡崎敬語調査」と称し,人々の言語行動の経年変化を長年,調査している.この調査では,最初の昭和29 年の時点では当該の調査事項に関しての知識は限られていたので,まず統計的無作為標本抽出法を用いた.限定された調査地域や予算の下で,500 名の計画サンプルを設定し,調査を遂行したが,回収率が高くなかった.そのため,十分な量のデータを確保するために,計画サンプル数に不足する分を,性・年齢層の分布を勘案した標本で捕捉することにした(代替標本の使用).言語活動に影響を与える要因は,性別と年齢が決定的であろうとの推察からである.したがって,統計的無作為標本抽出法と割り当て法を折衷した形となった.事後には,前者と後者で得られた回答傾向を慎重に解析し,その差が誤差の範囲とみなせることを確認した.勿論,より深い分析では,学歴や職業等も影響を与える要因となり得るが,この規模の地域調査でそれらが弁別可能か否かは別の問題となる.そして,半世紀以上にわたる調査結果から見ても,初期の方法は適切であったと確認されている(杉戸, 2010).
昔と比べ調査環境が悪化し調査協力率が低くなったとする人が多いが,これは調査主体の知名度や調査テーマ等にも依存し,昔からの問題であった.国語研究所の例は,代替標本の活用の仕方を示唆している.また,回収データに対して国勢調査データに合わせた性別・年齢層別の「補正」がしばしばみられるが,上記のように回収データのバイアスの慎重な評価がなされて初めてそのような「補正」が正当化されるのである.
ここで,「マクロデータ解析」と「ミクロデータ解析」の区別についても注釈しておこう.
有権者1 億人から標本サイズ1 万人の単純無作為抽出による調査の場合,標本抽出誤差は最大1%と計算される.多段無作為抽出の場合の誤差はその幾倍かになる.したがって,少なくとも1億人の1%である100 万人程度のオーダーは,世論調査では誤差のうちとなる.例えば,日本人の自殺数は3 万人を越え,先進国の中で著しく高いが,この数字は世論調査の手法では誤差の範囲に隠れてしまう.また,この10 年ほどか,国内外で「格差問題」が論じられてきたが,日本人の国民性調査(統計数理研究所・研究リポートNo. 99, 2009) や米国のGSS (Roper Center, 2011)を見ると,数十年にわたり,日米とも社会を5 段階に分けた「階層帰属意識」はほとんど変化がない.現実の社会では,例えば失業者や生活保護世帯者が100 万人増加すれば無視しえないが,このオーダーは世論調査の手法では誤差の範囲に隠れてしまうのである.
研究の対象や目的に応じ,対象を望遠鏡で観るか,顕微鏡で観るか,肉眼で観るか,複眼的思考が重要であり,それはアプリオリに定まっているわけではない.
6.4. インターネット・アンケート調査現行のインターネット調査やweb 調査のほとんどは,標本の母集団の代表性を保証しない「アンケート調査」に過ぎない.web アンケートの比較実験調査によると,同じ質問でも,実施する会社によって回答データに無視できない差が出る(林・大隅・吉野, 2010; 林・吉野, 2011).各社の用いている登録モニターは,日本人の母集団とは性・年齢・学歴・職業だけでも離れている.さらに,「想定される回収標本」が国勢調査の性別・年齢層別に整合するように,それぞれの層の過去の調査協力率にもとづいて,「国勢調査の分布とは性別・年齢層別とはかなり異なる計画標本」を設定したり,データ回収時の調査打ち切り基準が様々あったり,同じ会社でも調査ごとにアドホックな作業がされている.
インターネット調査の権威Couper (2010) も,近い将来,世論調査がインターネットでできるとは考えていない.さらに,回収率向上のため,面接,郵送,インターネット等,各回答者に都合のよい方法で回答してもらうmixed-mode 調査を提案する人がいるが,同じ回答者でも異なるモードでの回答に相違があるのみならず,そもそも現実には回収率の向上には繋がっていないと報告をしている.
しかし,例えば,保健医療等でプライバシーに踏み込む場合,回答者は面接よりも郵送やwebアンケートでの自記式の方が正直に回答し易いこともあろう.その場合,全員が同様にホンネを回答するとは限らないので,母集団の推定よりも,少数でも詳細に問題点を開示してくれた回答者の情報を検討するのが肝要であろう.特に,医療保健では100 万人は勿論,1 万人も疎かにはできず,前述のミクロとマクロの視点の区別を念頭に,慎重な検討が必要とされる.
また,web 調査は「世論調査」の近似ですらないが,世論の一部として参考にはなろう.むしろ,多様な方法で世論の安定性,多面性を検証するという意味では,推奨され得る.
前節で筆者なりの提言を試みたが,種々の理由で実践上の困難は想像できる.理論と実践は相補的に考えなければならず,絶対的な解決法はない.
歴史を振り返ると,昭和20 年代末に国立世論調査研究所が廃止され,世論調査が民間に委託されるようになり,市場に埋め込まれた.それにより,統計的厳密性を保持することが第一義であった世論調査は,調査コストとの兼ね合いを考慮せざるを得なくなった.そして,この20 年ほど政府の構造改革の中で世論調査にまで入札制度が導入され,品質を計量し難い制度の中で落札されるようになってきた.それとともに,調査会社の登録調査員の質の低下も著しい.
本論文で展開した「理論の見直し」は,まだまだ未熟な段階で本当に「歴史」と「実践」と有機的に結び付くにはほど遠いであろう.しかし,21 世紀の新たな世界情勢が展開されていく中で,我々の学問をいかに現実の社会に生かしていくかという課題に少しでも示唆ができ,読者の方々がより厳密な実践的理論の構築へ向かうことがあれば,幸いである.