総説
行列・テンソル分解によるヘテロバイオデータ統合解析の数理
―第5回 ランダムウォーク―

2024 年 5 巻 1 号 p. 1-15
詳細
2024 年 5 巻 1 号 p. 1-15
生命科学分野で取得されるデータ集合は、雑多(ヘテロ)な構造になり、ヘテロなデータ構造を扱える理論的な枠組みがもとめられている。本連載では、汎用的なヘテロバイオデータの解析手法である行列・テンソル分解を紹介していく。第5回では、第4回で紹介しきれなかったグラフデータの解析の仕方、特にグラフ上でのランダムウォークをベースとした行列・テンソル分解に注目する。
これまでの連載[1, 2, 3, 4]のうち第4回[4]では、自己ループの無い無向グラフを扱った。そのようなデータはエッジの有無を意味する対称な正方行列である隣接行列(Adjacency Matrix)として表現され、その後(正規化)グラフラプラシアンという行列に変換し固有値分解(Eigen Value Decomposition;EVD)を行うことで、グラフの最小カット問題が解けることを紹介した。本稿でも引き続き、グラフデータに対するアルゴリズムを紹介する。ただし、第4回[4]のグラフと異なる点としては、第4回[4]では{0, 1}のみの値を格納した隣接行列と、0以上の実数の重みを格納した隣接行列とを陽に区別して表記していたが、本稿での議論はどちらに対しても区別なく適用可能であるため、より一般的な重みの隣接行列を想定する。また、ここでは自己ループはあっても良いとする(後述するランダムウォークの計算安定性の観点から自己ループはむしろ推奨)。エッジの向きに関しては、手法ごとに想定するグラフが有向グラフ(非対称な隣接行列)であったり、無向グラフ(対称な隣接行列)であったりするため、必要に応じてその都度明記する。有向グラフにおいては、あるノードから別のノードに張られるエッジの本数を出次数、あるノードが別のノードから張られるエッジの本数を入次数とする。無向グラフにおいては、出次数と入次数の区別が無いため、単に次数とする。また有向グラフを非対称な行列(例:隣接行列A、遷移確率行列P(後述))として表現する際に、ノードjからノードiに張られる有向エッジに関する情報(例:重み、確率(後述))は、A[i,j]やP[i,j]に格納されているものとする。なお、グラフのノード数は全てNとする。
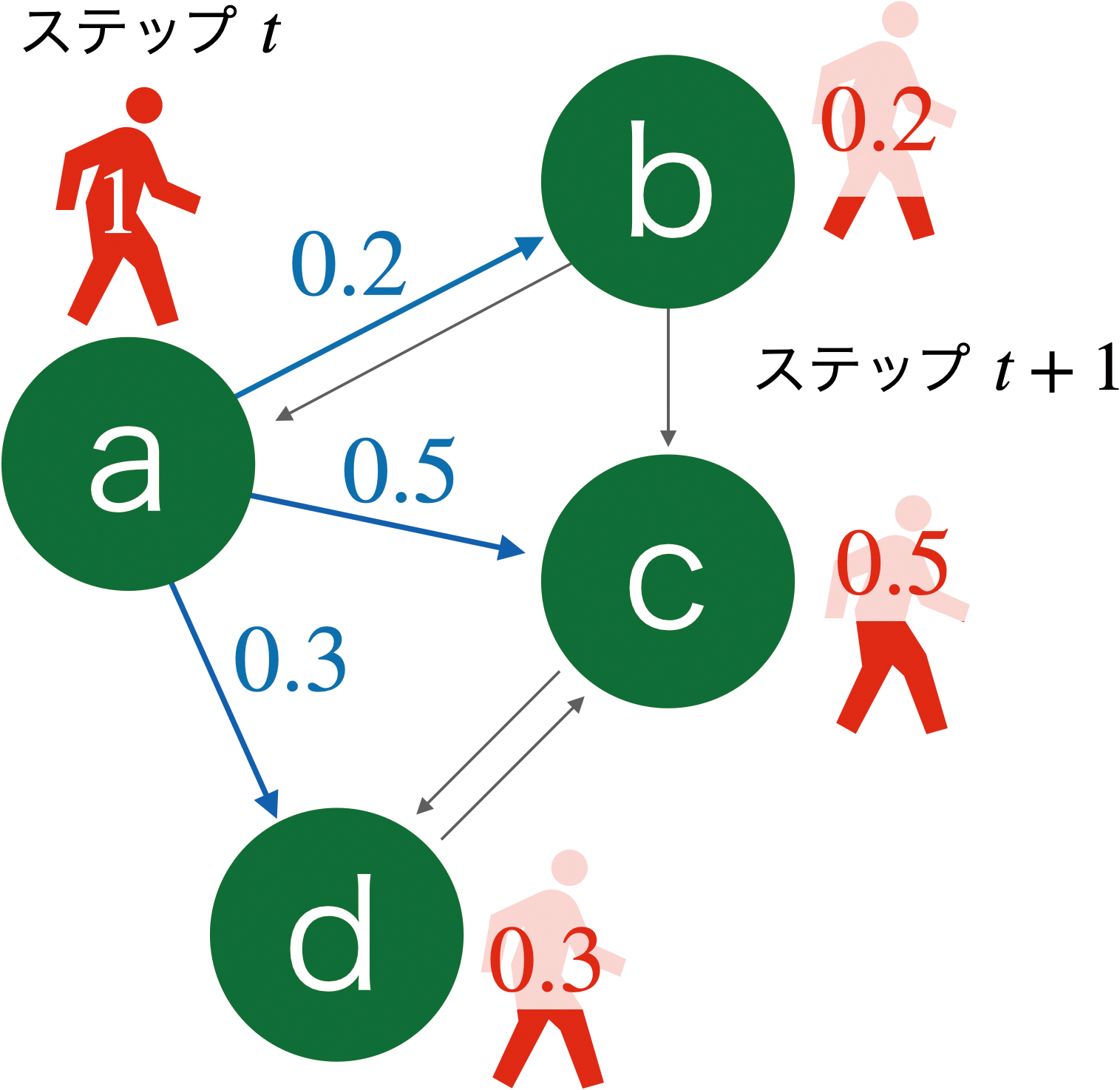
ここでは図1の有向グラフを考える。グラフ上のノードaはノードb, c, dとエッジで接続しており、エッジには各々重み(例:[4, 10, 6])が付与されているものとする。まずはこの重みベクトルを正規化して確率ベクトルに変換する(例:[4, 10, 6]/20=[0.2, 0.5, 0.3])。この正規化を全てのノードに対して同時に行うことは、各ノードの重みベクトルを列ベクトルに持つ非対称隣接行列A(N×N)に対して、ノードの出次数を対角要素に持つ行列D(N×N)の逆行列を、Aの右側からかけることに相当する
| (1) |
(例:
グラフ上のランダムウォーカーは、エッジ上の確率に従い隣接ノードを移動する。移動先ではエッジ上の確率値の分だけそのノードにランダムウォーカーが存在する可能性がある。
今aからb, c, dに確率の値に応じてランダムに移動することを考える。このような操作をランダムウォーク(図1)といい、ランダムウォークを行う仮想的なエージェントをランダムウォーカーという。ここでは「現在の状態は1つ手前の状態にのみ影響を受ける」1次のマルコフ連鎖を仮定している。ある長さNの確率ベクトルx0を初期値ベクトルとして設定し、これをランダムウォーカーがノードごとに存在する確率とする(図2)。このx0をPにかけると、全ノードでランダムウォーカーが隣接ノードに一斉に移動することになる。この時に、ノード上のランダムウォーカーの存在確率に、エッジ上の確率がかけられ、次のステップのランダムウォーカーの存在確率x1が得られる(図2)。
| (2) |

ステップtにおいてノードごとにランダムウォーカーが存在する確率ベクトルxtに対して、遷移確率行列Pをかけることで、全ノードでランダムウォーカーを隣接ノードに一斉に移動させ、次のステップt+1における確率ベクトルxt+1を求める。べき乗法では、この行列ベクトル積を初期値x0から定常状態に達するまで繰り返し行い、固有ベクトルxS(S:逐次計算回数)を求める。
Pが確率性[5](列ベクトルの和が1であること)、既約性[5](ランダムウォーカーがどのノードからスタートしても全ノードに行き渡ること)、非周期性[5](あるノードからスタートしたランダムウォーカーが、元のノードに帰ってくるまでのステップ数に周期がないこと)といった条件を満たす場合は、この操作をt=1, 2, . . ., S(S:逐次計算回数)と繰り返すことで、段々とベクトルの値が変化しなくなる定常状態(図2)へと達し、特定のベクトルに収束するため、以下の等式が成り立つようになる。
| (3) |
これは、固有ベクトルの定義そのものである(ただし、Pは非対称な正方行列)。読者においては、これまでの連載[1, 2, 3, 4]で紹介してきた「射影」や「パターンの和」に加えて、第3の行列分解のイメージとしてぜひこれを覚えておいて欲しい。すなわち、ここでは固有ベクトルは、十分な時間グラフ上を歩き回ったランダムウォーカーが最終的にどのノードにどの程度とどまるのかを示す「定常状態における存在確率」である。
実際に、上記の計算でEVDをするアルゴリズムがべき乗法(Power method)[5, 6](図2)であり、初期値ベクトルx0の値をランダムに変えても、xSが固有ベクトルに収束することがわかっている(ただし収束性はPの性質に依存する、cf. Eigen gap[5, 6])。べき乗法は行列ベクトル積を繰り返すだけでの非常にシンプルなアルゴリズムである(ただし遷移確率行列以外の行列に適用する場合は、オーバーフロー回避のために、ステップtごとにxtの正規化を伴う[5, 6])。また行列が十分に疎であった場合、ゼロ要素に関わる計算は省略できることから、疎行列形式との組み合わせにより高速化が望める[7]。べき乗法をベースとしてAugmented implicitly restarted Lanczos bidiagonalization methods(IRLBA)や、Implicitly Restarted Arnoldi Method(IRAM)など、より収束の早いEVDアルゴリズムも提案されており、主成分分析(Principal Component Analysis;PCA)や正準相関分析(Canonical Correlation Analysis;CCA)、対応分析(Correspondence Analysis;CA)など様々な多変量解析手法に利用されている[8, 9]。
Katzの手法[10]はべき乗法と類似した手法であるが、Ptの計算の代わりに、対称な隣接行列の行列積Atを求める。この時に、グラフ上で移動する距離を制御する非負値のハイパーパラメーターβを利用して、ランダムウォーカーが最初にいたノードから大きく移動し過ぎないようにペナルティを加える。
| (4) |
なお、ここでは右辺の式変形に行列の幾何級数展開を利用している。他にもハイパーパラメーターでランダムウォークの移動距離をコントロールするアプローチとして、Heat Kernel[11]が挙げられる。
遷移確率行列Pにべき乗法をそのまま適用した場合、ランダムウォーカーが入次数の高いノードにとどまりすぎて、他のノードの確率値がほとんど0になってしまう「シンク」や、ランダムウォーカーが特定の経路だけを循環してしまう「閉路」といった問題があり、グラフ全体の情報を引き出せなかったり、計算の安定性や収束性に影響を及ぼすといったことが知られている[5, 6, 12, 13, 14, 15, 16, 17]。2000年代にGoogleやYahoo!で実際に利用されていた検索アルゴリズムであるPageRank[5, 6, 12, 13, 14, 15, 16, 17]は、こういった問題を解消した手法である。PageRankでは、ランダムウォーカー(PageRankの説明ではネットサーフィンにちなんでランダムサーファーとも呼ばれる)はべき乗法と同様、確率α(0≤α≤1)でエッジ上の遷移確率に従いランダムウォークしつつも、有向グラフ上での接続の有無に関わらず、確率1-αで全てのノードに等確率(1/N)で移動するテレポーテーション(または、ジャンプ、ワープ)と呼ばれる仮定を置くことで、上記の問題を解消している(図3)。
| (5) |
ただしx0は全ての要素が1/Nの初期値ベクトルである。αの値は経験的に0.75~0.9程度の値が設定される[5, 6, 12, 13, 16]。なおα=1の時はPageRankとべき乗法は等価である。

なお、上記の非対称隣接行列を転置したATに対して、PageRankを行ったものはCheiRankといい[16]、PageRankの確率値がどれだけ他のノードからランダムウォーカーを集めるのかを意味する権威スコアであるのに対し、CheiRankの確率値はどれだけそのノードが別のノードを参照しているのかを意味するハブスコアとなる。PageRankとは独立に開発されたHITS[5, 10, 13, 16]というアルゴリズムでは、以下のように特異値分解(Singular Value Decomposition;SVD)を非対称隣接行列Aに適用する。
| (6) |
ただしσはAの最大の特異値、a, hはσに対応する長さNの特異ベクトルである。左特異ベクトルaと右特異ベクトルhが各々権威スコアとハブスコアに相当するため、PageRankとCheiRankの性質を併せ持った手法と言える。HITSの類似手法として、非対称隣接行列から行方向と列方向とで各々正規化した2種類の遷移確率行列を求めてから、それらの行列積のSVDを行うSALSAというアルゴリズムもある[5, 12]。
Personalized PageRank[16](PPR、またはTopic-specific PageRank、Focused PageRank)と呼ばれるPageRankの拡張手法では、PageRankのテレポーテーション項の初期値ベクトルx0を等確率とするのではなく、事前にユーザーの興味があるノード集合の確率を大きめに設定しておく(図3)。これにより、有向グラフ上でそれらノードの周辺が重点的にランダムウォークされるようになり、それらの確率値がより大きく算出される。PPRの極端な場合として、グラフ上の1つのノードにだけ1、それ以外は0としたものにRandom Walk with Restart(RWR[16])がある(図3)。
なお、式(5)のPageRankの逐次式は、定常状態xt+1=xt=xを仮定することで、逆行列計算により解析的に解くこともできる。
| (7) |
ただし、逆行列計算はΟ(N3)だけ計算コストがかかることから、実際には数値計算により逐次的に求めることの方が一般的である。同様の理由で式(4)のKatzの手法も、逆行列計算を回避するために、適当なtの値までで打ち切って計算することが多い。
PageRankはデータの一部にだけラベルが付いている場合に、データ間の類似度から他のラベル未知データにもラベル付けを行う「半教師あり学習」の一種、ラベル伝播法(Label Propagation)[16, 18]と等価である(図3)。ラベル伝播法では、まず第2回[2]で紹介したダミー変数ベクトル(またはOne-hotベクトル)を導入し、あるクラスに属する場合は1、属さないかラベルが未知の場合は0とする長さNのベクトルyを利用して、以下のように逐次的にベクトルftを計算する。
| (8) |
ただし行列EはE=D-1/2 A D-1/2として、対称な隣接行列Aを次数行列Dで正規化を行ったものである。ここで、両辺に左側からD1/2をかける。
| (9) |
そして、式(1)より、EをPに入れ替えると、
| (10) |
となる。最後に
| (11) |
となり、実際に式(5)のPageRankの逐次式が得られる。
ランダムウォークのノードのクラスタリング問題への適用も可能である。例えば、Walktrap[19, 20]という手法では、有向グラフ上でのランダムウォークの結果をノード間の距離として、階層的クラスタリングなど各種クラスタリング手法の入力として利用する。マルコフクラスタリング(Markov Clustering[MCL[19, 21])という手法では、S回逐次計算したべき乗法の結果である
| (12) |
のPSの部分を適当な閾値で{0, 1}に2値化(枝刈り)し、どのノード同士が同じクラスタに属するのかを示すN×Nのメンバーシップ行列Bを得る。
| (13) |
ただし値により強弱を出すために、何ステップかに1度Pt全体を2乗した後に正規化する操作が入る。Leading Eigenvector[19, 22]は、対称な隣接行列A、次数ベクトルd、リンクの本数
| (14) |
に対してEVDを適用する手法であり、第4回[4]で紹介したラプラシアン固有マップ(Laplacian Eigenmaps;LEM)と同様、クラス数-1だけ固有ベクトルを計算した後に、k-meansなど別のクラスタリング手法を適用することで2値化する。期待値から逸脱した残差に対して行列分解するこの目的関数は、第4回[4]で紹介したCAの目的関数(Pearson残差)とも類似している。なお、この目的関数を近似的に最適化する別のクラスタリング手法としてLouvain法[23, 24, 25, 26]があり、非常に高速であり、かつUMAPの散布図上のクラスタ構造とよく一致したクラスタリング結果が得られることから、1細胞オミックス分野で現在デファクトスタンダード的手法となっている。
生命科学分野で得られるデータ解析では「一部のよく知られたデータを除き、ほとんどのデータに属性情報が与えられていない(例:機能未知、未アノテーション)」という状況がしばしば起きる。このようなデータの解析においては、Guilt-By-Association(GBA)という原理が適用される(図4)。GBAとは、グラフ上で属性未知のノードaと属性既知のノードbが関連づけられた場合、bの属性をaの属性としても流用するという考え方である(例:疾患X関連遺伝子bと共発現していた遺伝子aもまた疾患Xに関係するだろう)。

元々は「関連する人々が有罪であるための個々への罪の帰属(証明のない)」を意味する法律用語。転じて、生命科学分野においては「ある生体分子や現象間の何らかの関連性を根拠に、片方の属性情報をもう片方に流用する」というアプローチを指す。
GBAの原理に基づき、少しでも参考になりそうな付加情報を取り込んで、未知のデータ間のリンク(Missing link)を予測するという方針が取られるが、ランダムウォーク系の手法はまさにこのような解析において基盤技術となっている。例えば、遺伝子-疾患の関連性の優先順位づけ(Gene Prioritization)[27, 28, 29, 30, 31, 32, 33]、ドラッグリポジショニング[34, 35, 36, 37]、タンパク質間相互作用(Protein-Protein Interaction;PPI)[38, 39]、micro RNA、lnc RNA、circ RNAなどのnon-coding RNAの機能予測や疾患との関連性予測[40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50]、マイクロバイオームと疾患との関連性予測[51, 52, 53, 54]、メタボロームデータのアノテーション[55, 56]、遺伝子制御ネットワーク(Gene Regulatory Network;GRN)[57, 58, 59, 60, 61, 62]、ゲノムワイド関連解析(Genome-wide Association Study;GWAS)[63]、タンパク質折りたたみ[64]、マルチオミックス解析[65]など、数多くの問題設定においてランダムウォーク系の手法が活用されている。昨今では、データがノイジーなシングルセルオミックスデータ(例:scRNA-Seq、scATAC-Seq、scHi-Cなど)における欠損値補完(Imputation)[66, 67, 68, 69, 70, 71, 72, 73, 74]や、計測値の平滑化(Smoothing)[75, 76]、細胞ダウンサンプリング[77]、細胞間相互作用[78, 79]といった解析にも活用されつつある。
関連するデータは少しでも取り込んで、データ解析の性能を向上させようという動きは生命科学分野以外にも見られる。特にWebデータマイニングの分野においては、Heterogenous Information Network(HIN)というキーワードの下、精力的にそのような研究が取り組まれている[80, 81, 82]。HINが扱う課題は、関連データを統合しつつも、データの種類が異なる場合には、ノードの次数分布やノード間の距離といった統計的性質や、データの品質も異なることから、これらの違いを補正しつつ1つのモデルとしてどのように扱うかという点にある。
例えばA(例:遺伝子)とB(例:疾患)の関係性を調べる解析を考えてみる(図5)。既知の両者の関係性(例:OMIM, DisGeNET)をA-B隣接行列として表現すると、全組み合わせに対してごく一部しか関係性が知られていないためかなり疎な行列になるが、これに加えてA-A隣接行列(例:PPI, GRN)や、B-B隣接行列(例:Disease Ontology)を統合し、1つのグラフとした上でランダムウォークし、未知の遺伝子と疾患間のMissing linkを推定するということがよく行われる[80, 81, 82]。この時にHIN的なモデルでは、遺伝子や疾患といったデータの種類の違いを考慮し、A→A、A⇄B、B→A間の移動に関する遷移確率に関して別々にランダムウォークをしたり、同種ネットワーク間と異種ネットワーク間のランダムウォークで、移行のしやすさを変えるといった工夫がなされる。このようなランダムウォークモデルは、Multiplex Random Walk[83, 84]、Multi-layer Random Walk[85, 86]、Colored Random Walk[87]など様々な呼び方がされている。

左上:A-A隣接行列(例:遺伝子間制御ネットワーク)、A-B隣接行列(例:疾患関連遺伝子データベース)、B-B隣接行列(例:疾患間類似度)を1つの行列としてマージした行列。データ構造としては1つの行列になっているが、これらは統計学的性質やデータの品質が異なることから、データの出所を考慮したモデリングが必要となる。右上:Meta-pathでは、始点(例:A)や終点(例:D)、パス長(例:2)などを事前に設定し、取りうるパスを列挙した上で、パスごとに解析手法を適用する。下:符号付き有向グラフに対するランダムウォークでは、ランダムウォーカーの符号にエッジの符号がかかった値が隣接ノードにおける符号となる。この性質を利用して、味方の味方(=味方)、味方の敵(=敵)、敵の味方(=敵)、敵の敵(=味方)を区別できる。
HIN分野の代表的なアプローチであるMeta-path[80, 81, 82]では、例えばA(例:遺伝子)からD(例:疾患)の関係性を知りたいとなった場合に、他にも関連するBやCといった情報を経由する経路(パス)も考慮し、A→D、A→B→D、A→C→B→Dのように、明示的にランダムウォークで通るパスを区別しておき、パスごとに別々にモデルを適用して最後に解析結果を(重み付きで)マージしたり、性能の良いパスだけを採用するといった方針がとられる(図5)。
類似した考え方である符号付きランダムウォークでは、エッジに付随した重みに正の値、負の値が両方含まれているタイプの非対称隣接行列(符号付き有向グラフ)を、正の隣接行列、負の隣接行列に分離して、別々にランダムウォークを行う(図5)。ランダムウォーカーの符号にエッジの符号がかかった値が隣接ノードにおける符号となる性質を利用して、味方の味方(=味方)、味方の敵(=敵)、敵の味方(=敵)、敵の敵(=味方)を区別できる。これにより、初期ランダムウォーカーから見た味方度合い、敵度合いを全ノードに対してスコア化できる。既に符号を考慮したPageRank[88]、HITS[88]、PPR[89]、RWR[89]、スペクトラルクラスタリング[90]、Leading Eigenvector[90]、ラベル伝播法[91]など、様々な手法が提案されている。
生命科学分野においては、上記のようなランダムウォークの拡張手法は、疾患関連遺伝子予測[92]やドラッグリポジショニング[93, 94, 95, 96, 97, 98]、non-coding RNAの機能予測や疾患との関連性予測[99, 100, 101, 102, 103, 104, 105, 106]、発現変動遺伝子やコピー数多型の検出[107]、マイクロバイオームと薬剤との関連性予測[108]、漢方データのアノテーション[109]、といった様々な問題に適用されている。
データの種類の違いを考慮したランダムウォークをする別の方法としては、テンソルデータにランダムウォーク系手法を適用するアプローチが挙げられる。まずN×Nの非対称隣接行列がMセットある場合、それらを奥行き方向で束ねることでN×N×Mの3階テンソル
| (15) |
という高次のべき乗法を適用するHITSのテンソル拡張であるTOPHITS[110, 111]が挙げられる。ただし、×mはテンソルのm番目のモードに作用するモード積である(第3回[3])。原著論文[110, 111]では、PageRankが想定するようなWebサイト間のハイパーリンクの隣接行列が話題ごとにあるテンソルデータであることから、x, y, zをそれぞれ、ハブスコア、権威スコア、トピックスコアとしている。同様に、N×Nの遷移確率行列がMセットある場合、N×N×Mの3階テンソル

TOPHITSでは複数の隣接行列に高次べき乗法を適用する。正規化後の複数の遷移確率行列に対してテンソル分解を行った事例もある。第4回[4]で紹介したハイパーグラフ上のランダムウォーク系手法としてHypergraph PageRankや、Hypergraph RWR、Hypergraphラベル伝播法などがある。m次マルコフ連鎖は、m+1階テンソルに相当し、このデータに対するランダムウォーク手法としてZ-固有ベクトルやMultilinear PageRankなどがある。
第4回[4]で紹介したグラフを拡張した概念であるハイパーグラフは、多対多の関係性をハイパーエッジとして集合的にとらえることができる(図6)。N×Nのハイパーグラフ上の遷移確率行列
| (16) |
なお、任意のj(1≤j≤N)において
グラフ上で2ステップ以上離れたノードまでの依存関係を考慮する、2次以上の高次マルコフ連鎖を考えたランダムウォークでは、m次マルコフ連鎖に対して、m+1階遷移確率テンソル
| (17) |
(またはx=
遷移確率行列の確率値に基づき、実際に系列データを生成できる。これにより、グラフデータの系列データ向けモデルへの流用も可能である(図7)。例えばグラフ分散表現学習、またはグラフ埋め込み(Embedding)と呼ばれる分野では、グラフを系列データ化した後に、次元圧縮を適用することで、グラフという特殊なデータ構造をより扱いやすい数値ベクトルに変換し、その後に次元圧縮、クラスタリング、回帰、判別などより一般的な機械学習のタスクに利用する。例えば、系列化したデータに対してニューラルネットワークを利用した次元圧縮手法word2vecを適用する手法としてDeepWalkやnode2vecが挙げられ[125, 126]、第4回[4]で紹介したLEMもグラフ埋め込み手法の一種とも言える(余談だが、分散表現学習分野では、ベクトル化するという意味で~2vecという手法名が付けられることが多い)。このようなアプローチは、生命科学分野においては、ドラッグリポジショニング[127, 128]や、non-coding RNAの機能予測[129, 130]、時系列scRNA-Seqデータの統合「131」、生命医科学分野で利用されるグラフ状の知識データベース(Resource Description Framework;RDF)の次元圧縮[132]といった研究に利用されている。またHIN特化型のグラフ埋め込みであるmetapath2vecやHIN2Vecといった手法も提案されている[133]。

遷移確率行列から系列データを生成し、様々な系列データ向け解析手法を適用することが可能である。また逆に、系列データから遷移確率行列を学習(行列化)し、ランダムウォーク系解析手法を適用することも可能である。
また逆に系列データから遷移確率行列を学習(行列化)し、ランダムウォーク系の手法を適用することも可能である(図7)。例えば、Goncalvesらの研究[134]では、時系列計測したDNAマイクロアレイデータに対しHeat Kernelを利用したランダムウォークを適用することにより、酵母の熱ストレスに関連した転写因子の優先順位付けを行なっている。
最後に1つ面白い事実を紹介しておく。上述したグラフ埋め込み手法は、どれも行列分解として定式化できることが近年示されている[135](ただし、現段階では数式上だけの話しであり、具体的にどのように最適化することで、そのような行列分解を直接計算できるようになるのかは不明である)。一見行列分解とは関係の無い手法が、行列分解として後から再定式化されるケースはこれまでに幾つもあり(トピックモデル[136]、k-means[137]、スペクトラルクラスタリング[138]、DBSCAN[138]、隠れマルコフモデル[139]、ニューラルネットワーク[140, 141])、機械学習分野における1つの潮流となっている。
今回は、第4回[4]で紹介しきれなかったグラフデータ解析、特にグラフ上でのランダムウォークをベースとした行列・テンソル分解手法を紹介した。このようなアプローチは、GBA原理に基づき、関連するデータを少しでも寄せ集めることで、アノテーションが不十分なデータの意味づけや、ノイジーなデータの欠損値補完などに利用されている。特に昨今HINをキーワードに進められている、データの種類の違いを考慮したグラフ上でのランダムウォークは、生命科学の問題設定に深く通じるものであり、またテンソル分解との親和性が高く、今後様々な手法が提案されていくと思われる。また、遷移確率行列(グラフ)と系列データとは互いに変換可能であり、それに各分野で提案されたモデルを異なる分野に流用可能であることが面白い。次回は、系列データにより特化した行列・テンソル分解について紹介する。
Eigen Value Decomposition
・IRLBAAugmented implicitly restarted Lanczos bidiagonalization methods
・IRAMImplicitly Restarted Arnoldi Method
・PCAPrincipal Component Analysis
・CCACanonical Correlation Analysis
・CACorrespondence Analysis
・SVDSingular Value Decomposition
・PPRPersonalized PageRank
・RWRRandom Walk with Restart
・MCLMarkov Clustering
・LEMLaplacian Eigenmaps
・GBAGuilt-By-Association
・PPIProtein-Protein Interaction
・GRNGene Regulatory Network
・GWASGenome-wide Association Study
・HINHeterogenous Information Network
・RDFResource Description Framework
 |
露崎 弘毅 2015年、東京理科大学生命創薬科学科博士後期課程終了。博士(薬科学)。同年より、理化学研究所(所属3)に在籍し、シングルセルオミックスのデータ解析や解析ツール開発に従事。現在は千葉大学(所属1、2)で医療データの解析を行なっている。パッケージングに特化したハッカソンBio“Pack”athonを主催。 ホームページ:https://researchmap.jp/kokitsuyuzaki |