Primers
植物科学・農学におけるAI協働研究の現状と今後の活用性
2024 年 5 巻 2 号 p. 28-34
詳細
2024 年 5 巻 2 号 p. 28-34
今や人工知能(AI)の時代と言われて久しく、未だ夢物語が飛び交いつつも、かなり理解が進み適用も多くなってきたと感じる。他方、植物科学・農学におけるAI研究はお世辞にも盛んであるとは言えず、よく言えば、伸びしろがあるとも言える。本著では、AIの基礎的な部分から紹介を行っていくが、説明可能なAI (explainable-AI)という概念が実装されたことにより、単なる予測ツールからAI観点の解釈を科学に持ち込めるようになった。ここでは植物科学における、よくある画像解析だけでなく、遺伝配列を用いた解析においてもどのような研究が可能なのかを、その実例を追いながら紹介を進めていくとともに、ChatGPTやAlphaFoldシリーズの鍵となるTransformerの特性なども併せて解説する。正しいAIへの理解が浸透すれば、その使い道・活用法だけでなく、脆弱性やロバスト性に配慮した幅広い解析が可能になるだろう。
近年のAIにおける進展はすさまじく、もはや生物学における一般的な解析手法として定着しつつあると言っても過言ではない。一方、何を以てAIなのか、という問いは極めて難しいものである。例えば私たちが想像するAIとはChatGPTや、生物分野ではAlphaFold3などと言ったものであり、詳しいアルゴリズムは後述するが、これらは「深層学習」という、いわゆる「機械学習」の範疇において、特徴量を自動的に抽出可能なネットワーク構造を基にしたものをそう呼ぶ傾向にあるようである。(図1:深層学習の階層構造)。実際は、機械学習の範疇には含まれない、単純な統計手法であってもそれをAIと呼んでいることも多く、線引きが難しいものであるが、本解説では、特に深層学習について、植物科学・農学における現状とその活用性について解説していこうと思う。

深層学習という概念は既に1980年代から存在しているものであるが、これが世に広く知られるようになったのは2012年以降である。AlexNetと呼ばれるネットワークアーキテクチャが画像分類問題コンテストで、それまでの古典的な機械学習を抜いて初めてトップに立ち[1]、それ以降、VGG16、ResNet50など、次々と新しいモデルが構築されていった[2]。これらはいずれも「畳み込みニューラルネットワーク」(Convolutional Neural Network: CNN)と呼ばれるものであり、大雑把な特徴としては「移動不変性」(特徴量の場所がどこにあっても柔軟に発見できる)に得意な側面を持ったネットワークである[3]。しかし、生物学におけるCNNの適用に当たって(当時の)大問題、「そう予測した原因が分からない」という課題があった。「なぜ?」が分からなければ、深層学習などただの予想ツールに過ぎず、科学的適用は難しい。これに対して、2015年くらいから世に出始めたのが「説明可能なAI:Explainable AI (X-AI)」という存在である。Gradient-weighted Class Activation Mapping (Grad-CAM)、Layer-wise relevance propagation (LRP)などのツールが代表例であり[4, 5]、疑似的ではあるが、CNNの予測に対して「予測の鍵となった領域」を重みとして表現してくれるものであり、生物学的な活用も可能になった。もっとも、その後、2017年になって、自然言語処理のブレイクスルーとして登場したTransformer[6]による解析では「アテンションマップ」と呼ばれる要素間の繋がりに重みを検出することで、予測クラスに対して寄与率の高い要素を検出可能になっており(詳細は後述)、X-AIという概念自体がもはや当たり前のものになっているのかもしれない。有名なところではDeepMindが開発したAlphaFoldシリーズや発現パターンをプロモーター領域の膨大な情報から予測するEnformerなどにもこのTransformerがコアとして使用されている。このTransformerについての詳細は最後の段落で説明したいと思う。
CNNの開発(とX-AIの存在)により画像解析への適用可能性は一気に広がった。医学などに比べると遥かに適用件数は少ないものの、植物科学においても2018年ごろから、まずは簡単な植物種の判別問題や、病徴の自動検出、葉や花・果実の自動検出と言った技術群が登場している[7, 8]。そもそも、AIと一口に言ってもその用途は幅広く図2に示すように、物体認識タスク・分類問題・回帰問題など、様々なフレームが存在しており、これらは研究分野によって大きく使用頻度が異なる。

物体認識という側面で言えば、初期段階では単純な葉の自動認識による葉数測定などが行われていたが、現在では根の詳細な分化パターンの検出・認識タスクを行うツールなどが使用されている[9, 10]。一方、広大な圃場試験ではドローンを駆使した作物における認識、つまり病害発生パターンの自動検出や、可食部となる果実の認識や、密集した果実を切り分けたうえで、その成熟度を認識するようなツールも登場している[11, 12]。物体認識という特性上、直接的に科学的な成果に結びつくものは少ないが、特に農学分野では、回帰タスクや気候データなども加味したマルチモーダルテストによる収量予測、自動収穫技術なども提案されており、実用面での適用性は高い。
他方、植物学分野における分類問題の汎用性は高く、特に農学分野において需要が高く、使用用途も多彩である。これには農学特有の事情が隠れており、極めて古典的な農学分野では体系立った技術群よりも「経験」による「暗黙知」とも呼ばれる直感に依存したタスクが多く存在する。言い換えれば何十年も経験を積んだ熟練者にのみ可能な「ウラワザ」のような概念が存在し、それに依存した育種・栽培が展開されていることも少なくない。簡単な分類問題としては、作物の品種判別などがあるが、近年では果実の生理障害の発生運命の予測や日持ち性(加食期間)の推定、内部形質の判断など、熟練者でも判別の難しいタスクに対して高精度な予測を可能とするモデルがいくつも開発されている[13, 14, 15]。ただし、必ずしも複雑なCNNモデルが高水準な結果を生むものでは無く、案外、学習サンプル数に応じては、簡単な層構造のモデル(例えばVGG16など)の方が高精度をたたき出すことが多い。極端な例では、上述したTransformerベースの画像分類モデル(Vision Transformer: ViT)も存在するが、一般的に、このViTの出力を活用するには、大量の学習画像データ(筆者らの予備的解析では10,000以上)が必要であり、特にサンプル数が限られる分野では、必ずしも新規・高度なモデルがフィットするわけではない。これに関連して、学習サンプル数の足りない場合は、データの回転・色調変化などによる水増し(augmentation)や、人工的にデータを生成して学習させるもの、それに敵対的生成ネットワーク(GAN)を組み合わせるという概念もあるだろう。
さて、画像解析を単なる「予測」に終わらせずに活用するとなると、どのような研究が可能であろうか?近年における基礎的な植物科学では、ゼニゴケにおいて生育初期段階ではほとんど判別のつかない雌雄差(性的二型性を含む)を予めCNN学習させたうえで、Grad-CAMを使用することで、「どの領域が雌雄発生差の起点となっているのか?」を明らかにしようとした研究がある[16]。また、X-AIによる運命予測はオミクス解析との相性も良く、数十年の経験を経た専門家でさえ判別精度が50%にも満たないカキ果実の「早期過熟障害」に関してX-AIを使用し、鍵となっている果実領域と、障害に関係のない領域を明らかにし、それらの間の微細な差異を生む生理学的要因をトランスクリプトーム解析によって明らかにした研究などもある[17](図3)。いずれも「人では気付かない微細な兆候」をAIが捉え、様々な媒体(視覚に依らず、オミクスデータなど)を通して人に教えてくれるという、AIとの協働研究が可能になりつつあるというのが現状である[18]。

上述の通り「説明可能なAI (X-AI)」の技術により、ブラックボックスであった判断要因の可視化を行うことができるようになった。実は、X-AIは遺伝(ゲノム)配列と非常に相性が良い。深層学習技術自体は画像や自然言語に用いられているケースが多いが、「行列」形状のデータであればどのようなものでも解析対象となり得る。DNA配列は、A・T・G・Cの4つの塩基がそれぞれ[1, 0, 0, 0]、[0, 1, 0, 0]、[0, 0, 1, 0]、[0, 0, 0, 1]と表されるOne-hot-arrayとした二次元行列に変換可能である(図4)[19]。本来はDNA配列情報を見続けた専門家など存在しないが、DNA情報を深層学習に適用することで、その中に存在する暗黙知的な特徴を特定する「人工的なDNA配列専門家」なるものの迅速な生成が期待できる。DNA配列を深層学習に適用した例として、遺伝子発現やエピジェネティクスを予測[20, 21, 22]したものがある。ここでは、植物の進化学特徴も考慮した観点から、著者らが行ったプロモーター配列から遺伝子発現を予測する深層学習モデルの構築例を紹介する。遺伝子発現は転写因子(trans因子)とそれが認識するCis-regulatory elements (CRE)間の複雑な相互作用ネットワークによって制御されている。CREは、転写因子によって認識される短い非コードDNA配列であり、植物特異的に頻繁に生じる全ゲノム重複[23]や栽培化過程において、系統特異的な進化の原動力として機能していることが分かっている[24, 25]。このCREの系統特異的な進化は作物の重要形質に関連する新しい発現調節をもたらしてきたことが知られており[26]、CREの変異は作物における形質多様化の原動力であることが考えられる。しかし、cis-trans相互作用における「複雑性」や「曖昧性」のために、プロモーター領域からの遺伝子発現決定要因の予測は極めて難しい。

ここでは、2例ほど遺伝子発現予測に着目した研究例を紹介する(図5)。まずは、トマトのゲノムワイドなプロモーター配列を深層学習に適用することで果実成熟における遺伝子発現パターンを予測する技術についてである[27]。本技術は2段階の深層学習ステップにより構築されている。最初のステップでは、モデル植物であるシロイヌナズナの転写因子結合モチーフの網羅的解析(DAP-seq)データを深層学習することにより、ゲノム配列からCREを網羅的に予測できるモデルを構築した。このモデルにトマト全ゲノム配列を適用し、全遺伝子プロモーター配列において各転写因子が結合するCRE行列情報を作成した。シロイヌナズナのDAP-seqデータにより構築された深層学習モデルをトマトゲノムに適用可能であるのは、CREが植物種間の転写因子ファミリー内で非常に保存されているためである[28, 29]。次に作成したCRE行列を説明変数、トマト果実の成熟時における発現パターンを目的変数として1次元畳み込みモデル(1d-CNN)による分類を行った。X-AIにより各遺伝子の発現パターンに寄与するCREを特定することに成功し、そのcis-trans相互作用はトマト果実でのwet実験によって実証された。さらに、今後はこの特定された発現変動の鍵となるCREを遺伝子編集(cis-edit)することによって既存多様性の組み合わせでは構築できない新規発現パターンを創出できる可能性も考えられる。

遺伝子発現予測技術は、k-merベースの解析が多く行われている。機械学習であるランダムフォレストにイネ科植物のプロモーター領域k-merパターンを学習させることにより、低温ストレスに応答する遺伝子発現の予測を可能にした研究[30]や深層学習(CNN)にシロイヌナズナのプロモーター領域のk-merを学習させることにより、熱・乾燥ストレスに関する遺伝子発現予測に成功し、X-AIによって予測に寄与するk-merを特定した研究[31]が見られる。これまで紹介した研究はただ単にプロモーター領域の配列をインプットデータとして考慮したものだが、エピゲノム情報や種間の同祖遺伝子の対応性[32]を考慮したモデル構築をしている例もあり、多様なゲノム情報の適用はさらなる遺伝子発現決定因子の特定につながると考えられる。
ただし、これらの深層学習モデルの予測精度は各生物学的コンテクストに大きく依存する。つまり、予測精度のみでモデルの精度を評価することは適切ではなく、各モデルにおいて予測に重要であった特徴に着目することが重要である。酵母では、はるかに大規模な配列データを使用した深層学習モデルを使用して、非常に高い精度で遺伝子発現パターンを予測可能である[32]。しかし、植物では膨大なゲノムデータを準備することは非常に困難である。そのため植物科学では、不完全な予測精度についてのリスクを理解しながら、生物学的観点からの特徴の解釈の重要性に焦点を当てることが重要である。
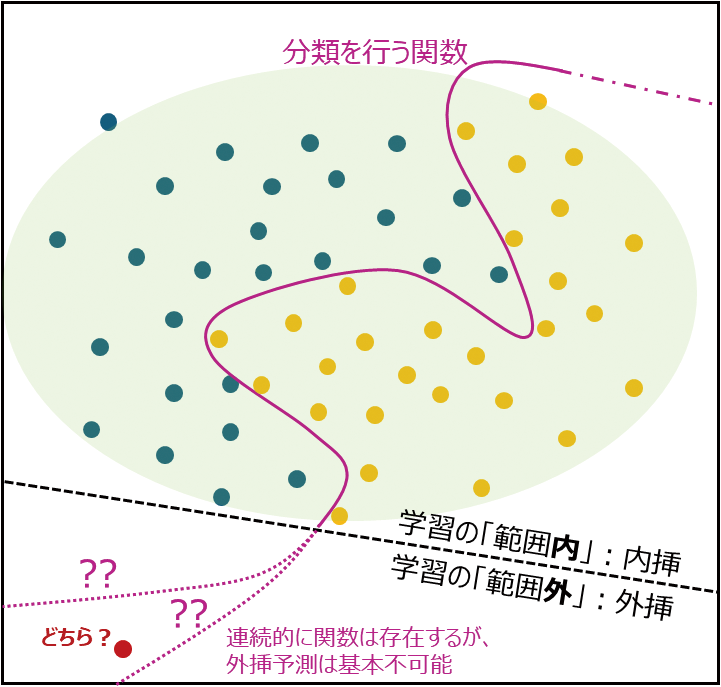
ChatGPTはもとより、AlphaFoldシリーズが生物分野では有名であるが、これらの鍵になっているアーキテクチャはいずれもTransformerである。Transformerは、アテンションマップと呼ばれる各トークン(説明変数)間の総当たり戦においての相関性・連動性を検出したものを解析の基本としており、予測クラス(目的変数)自体もこのアテンションマップの1トークンとして扱われるため、概念的には重回帰分析のようなイメージに近いだろう(図6)。トークンには言語を用いれば自然言語解析になるが、ここに遺伝配列を入れれば遺伝的な解析に、画像を細かく分けて入れれば画像解析になる。実際、画像へ適用した例としてViT[33]が、また、柔軟な学習モデルとしては適用できないものの、遺伝子プロモーターの各パラメータを膨大に学習させて遺伝子発現パターンを予測させるenformer[34]などがある。AlphaFoldシリーズは、これをタンパク質配列で行ったものであり、最新のAlphaFold3においても、その基本は各残基間の連動性(共進化性)を学習し(pairformerと呼ばれる)、既存タンパク質の残基共局在性と立体配置の関係から、座標上に共局在する2残基間の位置を収束させていくという方法に基づいたものである。詳しく述べるにはあまりにも複雑であるが、AlphaFold3では生成モデルの一つに良く活用されるdiffusionモデル(拡散モデル)を活用することで、立体配置のアノテーションのような部分を強く補完している。無機/有機小分子やDNA配列などとの結合も予想可能というふれ込みで、無敵の存在のように思われがちであるが、その構造上、というか、AIの特性上、当然弱点も存在するため、私たちはその脆弱性とロバスト性の両者を理解しておくべきだろう。AlphaFoldの使用に際してよく議論されるが、「突然変異による構造変化予測は可能か?」「相互作用の予測は可能か?」という議論がある。簡単な結論は「理論上は」難しいかもしれないけど、ケースによっては出来る、と答えるべきかと思う。AIは「学習モデル」であり、学習特徴量の範囲における世界の中でそれを予測する関数を構築する(図7)。その既学習世界(内挿)の外(外挿)については、内挿の連続体としての予測化できず、そもそも特徴量のパターンが異なる場合は外挿予測の極みとなってしまう。AlphaFoldシリーズではアテンションマップを見れば一目瞭然なのだが、1遺伝子の配列内の残基間共進化性からタンパク質間の電気的繋がりを捉えるようなプラットフォームは予測モデル内に用意されてはおらず、例えば電気的繋がりに依存した相互作用をその観点のみで予測するのは至難の業である(が、内挿予測の関数が構築されている以上、何かしらの答えは出力してくれる)。「ケース次第」で正解を当てるのは、その相互作用や突然変異が「既学習世界」に何らかの形で入っている場合であろう。いずれもアテンションマップにおいてその変化は捉えることが可能であり、著者自身が一部調べた範囲でも、予測相互作用が実際の結合状態と相似である場合は、やはり学習データ内にそのアテンションを捉えられる傾向が見て取れた。最新ツールの強みを最大限生かすためにも、その中身を十分に知っておくことが重要であろう。

| 赤木 剛士 2011年京都大学大学院農学研究科博士課程修了、京都大学白眉プロジェクト特定助教、京都大学農学研究科助教を経て2019年より岡山大学環境生命科学研究科准教授に着任、2021年同研究科研究教授、2023年より同研究科教授に着任。横浜市立大学木原生物学研究所客員教授。趣味は音楽(オーケストラの演奏活動や作編曲)・釣り。 |