原著
説得による態度変容プロセスの認知モデリング:中村・三浦(2019)の事前登録済み二次分析
2024 年 39 巻 3 号 p. 180-191
詳細
2024 年 39 巻 3 号 p. 180-191
Nakamura and Miura (2019) conducted an experiment to examine the attitude change process in a situation where someone is persuaded in multiple directions from different sources, and showed the applicability of the heuristic-systematic model (HSM), a model of the attitude change process in unidirectional situations. In this study, we elucidated that the data analysis method taken by Nakamura and Miura (2019) has two limitations: (1) its conclusions depend on the untestable assumptions of the analyst, and (2) it is not purposive to the objective of testing the applicability of the model. To overcome these problems, we proposed a cognitive model appropriate to the experiment. Moreover, we analyzed Nakamura and Miura’s data (2019) using that model. As a result of the posterior predictive check and a model comparison by the Bayes factor, it was shown that the HSM is applicable in such a situation, while also obtaining some evidence against the HSM. Furthermore, the parameter estimates indicated that the quality of some messages and manipulations was not as intended by the experimenter.
中村・三浦(2018)は、日常生活場面において、「ある題材について、複数の源泉がそれぞれ異なる唱導方向に説得を行う状況」、すなわち「複数源泉・複数方向の説得状況」(中村・三浦,2018, p. 157)が多いにもかかわらず、先行研究ではこの状況においてどのようなプロセスで説得の受け手の態度が変容するかについて、十分に議論されてこなかったことを指摘した。その上で、単一源泉・単一方向の説得状況における態度変容プロセスとして議論されてきた説得の2過程モデル、特にヒューリスティック・システマティックモデル(以下、HSM; Chaiken, 1980; Chen & Chaiken, 1999)を念頭に置いた実験案とその結果の予測について議論した。この実験を実際に行い、複数源泉・複数方向の説得状況におけるHSMの適用可能性を検討したのが、中村・三浦(2019)である。本研究は、中村・三浦(2019)で収集されたデータを用いて、HSMの適用可能性の検討という同じ目的に対して、認知モデリングという別の方法でアプローチするものである。
中村・三浦(2019)による検討はじめに、実験の前提となるHSMについて述べる。このモデルは、ヒューリスティック処理とシステマティック処理という2つの処理様式で態度変容プロセスを説明するものである。ヒューリスティック処理とは、メッセージ内容の詳細な処理をせず、過去の経験などから得た簡単に利用できる手がかり(以下、ヒューリスティック手がかり)に基づいて、説得を受容するかを判断するプロセスである。ヒューリスティック手がかりとして、中村・三浦(2019)の実験(以下、NM実験)では説得者が説得の受け手と同じ集団に属しているか否かという集団成員性を操作している。一方、システマティック処理とは、ヒューリスティック手がかりだけでなく説得の論拠も含めて包括的、分析的に処理を行い、説得を受容するかを判断するプロセスである。論拠の強弱を決める要因として、NM実験では論拠の具体性を操作している。これら2つの処理は同時に生起し得るものであり、どちらが優勢になるかは、説得を処理しようとする動機づけ、および処理の際に使われる認知資源に依存して連続的に変動する。具体的には、動機づけと認知資源が共に十分であればシステマティック処理が優勢になり、逆にどちらか一方でも不十分であればヒューリスティック処理が優勢になるとされる。HSMではさらに、加算効果や減弱効果といった2つの処理様式の相互作用が仮定されているが、中村・三浦(2019)ではこの点についての議論はされていない。本研究も同様に、これらの相互作用を考慮しないこととする。
次に、HSMを念頭に置いて実施されたNM実験の概要を説明する。NM実験では、実験参加者(以下、参加者)が集団成員性の異なる2人からそれぞれ異なる方向への説得を受ける状況を、シナリオとして参加者に提示した。具体的には、参加者の居住市町村における架空の首長選挙で2人の候補者が立候補しており、そのうち参加者自身と同じ出身地(内集団成員)の候補者が具体性に欠ける弱い論拠で、反対に自身と異なる出身地(外集団成員)の候補者が具体性のある強い論拠で政策を論じている、といった状況を提示した。参加者は認知資源の制限あり群・なし群の2群に分けられ、群毎に異なる認知資源の操作を受けた状態で両者の説得メッセージ(以下、メッセージ)を読んだ後、どちらの政策がより重要だと思うか(以下、相対態度)、それぞれの候補者の政策がどの程度重要だと思うか(以下、絶対態度)などの複数の態度指標に回答した。
実験結果の予測は以下の通りである。HSMにおける処理の決定要因のうち、動機づけについては、首長選挙という身近なシナリオを用いることで十分確保されていると仮定されている。このとき、認知資源の制限あり群では、認知資源の不足によってヒューリスティック処理が優勢になりやすく、したがってヒューリスティック手がかりである集団成員性が好ましい、内集団成員の説得をより選好すると考えられる。一方、制限なし群では、動機づけと認知資源が共に十分であるためシステマティック処理が優勢になりやすく、したがって論拠が強い外集団成員の説得をより選好すると考えられる。分析では、この予測に従う傾向で各態度指標に群間差が見られるという作業仮説が、分散分析や中央値回帰による帰無仮説検定で検証された。
NM実験の結果、研究1では一部の態度指標で仮説が支持されなかった。その原因として、メッセージの音読に加えて二重課題を実施した制限あり群のみならず、メッセージの音読のみを行った制限なし群でも認知資源が不足しており、認知資源の操作が不適切であった可能性が挙げられた。そこで研究2ではその操作方法を変更して、制限あり群では時間制限のある状況でメッセージを黙読し、制限なし群では時間制限なしでメッセージを黙読することとした。再度実験を行ったところ、すべての態度指標で、仮説と整合的な方向の有意な群間差が確認された。これらの結果より、複数源泉・複数方向の説得状況におけるHSMの適用可能性が示唆されたと結論づけている。研究の詳細に関しては中村・三浦(2019)を参照されたい。
中村・三浦(2019)の限界点現実社会における説得状況の多くが複数源泉・複数方向であることに鑑みれば、その状況における態度変容プロセスの解明、またその手始めとして、より単純な単一源泉・単一方向の説得状況におけるモデルであるHSMの適用可能性の検討という目的を設定することは、説得研究の生態学的妥当性を高める上で必要な展開である。加えて中村・三浦(2019)では、動機づけの影響が未検討であるなどの限界はあるものの、おおむねHSMに沿う形で実験計画が行われている上、その実験には選挙という身近なシナリオが用いられており、データの収集方法についても今後の説得研究における1つの規準になり得ると考えられる。
しかし、この研究で採られているデータ分析方法には2つの限界点がある。第一に、分析結果から導くはずのHSMの適用可能性に関する結論が、分析者による検証不可能な仮定に強く依存している。上で述べた実験結果の予測とそれに基づく作業仮説は、HSMが適用可能であることに加えて、処理様式に十分な群間差が生じるよう認知資源の操作が施され、かつその処理様式と態度得点とが十分に対応するようにメッセージのヒューリスティック手がかりや論拠が構成されていることを仮定してはじめて導かれる。しかし、これらの十分性はアプリオリに仮定されているのみで、実際に十分性が満たされているかデータに基づいて検証されてはいない。これはすなわち、認知資源の操作、ないしメッセージの構成が不適切であると仮定を変更しさえすれば、HSMが適用可能であるという仮定を保持したまま、態度指標に群間差がないという、予測に反する結果を導けることを意味する。実際、NM実験では、「態度の群間差が有意でなければ認知資源の操作が不適切であり(研究1)、有意であればHSMが適用可能である(研究2)」という旨の推論が行われており、分析結果から「HSMは適用可能でない」という結論にたどり着き得ることが保証されない論理構成となっている。実験によるデータ収集を通じて実証的に結論を導くのであれば、データに基づかない仮定の影響はなるべく小さい方が望ましいだろう。
第二に、分散分析や中央値回帰(以下、単に分散分析5))といった、代表値の群間差を検定するアプローチは、モデルの適用可能性の検討という目的にそぐわない方法である。そもそも「モデル」とは、「対象システムの潜在的な表現6)」(Weisberg, 2013 松王訳 2017, p. 270)である。「モデルが適用可能か」という問いは、「モデルが現実の適切な表現になっているか」、すなわち「モデルと現実とが良く類似しているか」と言い換えられる。この類似性の評価基準は、モデルによる出力の予測と現実の出力との類似性を意味する動的な忠実度基準(dynamical fidelity criteria)、およびモデルの構造と現実の構造との類似性を意味する表象の忠実度基準(representational fidelity criteria)の2つに大別される(Weisberg, 2013 松王訳 2017)。心理学研究において、データ分析によって「モデルが適用可能か」という問いに答えるためには、これらの評価基準に照らしてモデルと現実のデータとの類似性を評価し、モデルの改善への示唆を得られるような方法を用いる必要があると考えられる。
分散分析はこの条件を満たしているとは言い難い。分散分析は、無作為割り当てにより交絡変数を統制した状況において、因果効果の1つである平均処置効果を推定する方法である(高橋,2022)。ここで、因果効果の推定という目的の下では、その因果プロセス、すなわち「なぜXがYに影響するのか」は無視されているということに注意が必要である(清水,2021; 打越,2016)。NM実験の文脈に立ち返ると、分散分析は「認知資源の操作によって処理様式に群間差が生じた結果、処理様式と対応している態度得点に群間差が生じる」というロジックから導いた、「認知資源の操作によって態度得点に群間差が生じる」という予測と、現実のデータとの類似性を評価していると考えることができる。しかし、分散分析による予測の評価は、「認知資源の操作によって態度得点に群間差が生じない」とする帰無仮説に基づく予測と整合的か否かを評価しているという意味で、あくまで間接的かつ定性的なものでしかない。加えて分散分析では、「認知資源の操作によって態度得点に群間差が生じる」という予測を導く任意の代替理論とHSMとを区別できない。つまり、「なぜ認知資源の操作が態度得点に影響するのか」を処理様式という構成概念で説明するHSMの構造が、現実の構造と類似しているのかをデータから評価できない。これを忠実度基準によって換言すれば、分散分析は動的な忠実度基準を間接的かつ定性的に評価するにとどまり、表象の忠実度基準を無視していることになる。中村・三浦(2019)がHSMによって態度変容プロセスを、単なる予測ではなく説明しようとしていることに鑑みれば、特に表象の忠実度基準の無視は看過できないだろう。したがって、分散分析は合目的的な方法ではない。
本研究の目的と概要そこで本研究では、前述した限界点を克服しつつ、HSMの適用可能性の検討という目的を達成するため、HSMの主張やNM実験の内容と整合的な構造になるように、態度変容プロセスの説明要因をパラメタとして措定し、それらのパラメタとデータとの関係を数理的に表現した認知モデルを提案する。分散分析とは異なり、態度変容プロセスのモデルと対応した構造を持つ認知モデルをデータ分析に用いることで、前述の限界点を克服できる。限界点の1点目については、メッセージや操作の質をパラメタとしてモデル内で表現することで、それらをデータから推定できる。さらに、それらの十分性の仮定を用いずにHSMの適用可能性に関する結論を導くこともできる。また2点目については、事後予測チェックによって、モデルの構造の誤設定やその改善に関する示唆が得られ、表象の忠実度基準を評価できる。加えて、ベイズファクター(以下、BF)を用いたモデル比較によって、モデルの予測とデータとの類似性、すなわち動的な忠実度基準を直接的かつ定量的に評価できる。これらの分析の詳細、および忠実度基準との対応については後述する。
本稿ではまず、HSMの主張やNM実験の内容を踏まえた認知モデルを提案する7)。次に、実データ分析として中村・三浦(2019)のデータの二次分析を行い、HSMの適用可能性を検討する。最後に、提案した認知モデルや実データ分析の結果に基づいて考察を行う。
なお、本研究ではデータ取得前に、一部の分析内容を事前登録している。ここでは本研究における事前登録の意義を論じる。本研究には、その確証的性質を侵し得る側面が2つ存在しているものの、いずれの側面も事前登録によって対処が可能である。第一に、認知モデリングは通常のデータ分析方法に比べて、どのような認知モデルやパラメタ推定法を使うのか、認知モデルをどの基準で評価するかなど、研究者の有する自由度が大きいため(Crüwell & Evans, 2021)、都合の良い結果ばかりに注目する確証バイアスにより、それらのみを報告するチェリーピッキングを起こしやすい。しかし有用なモデルを見つけるためには、その大きな自由度を活かした探索的分析も必要である(Lee et al., 2019)。そこで事前登録を行うことで、確証的分析における自由度を減らし、チェリーピッキングを抑止できるのみならず、その後の探索的分析との区別が容易となる。第二に、本研究で行う二次分析では、分析者が分析計画時点でデータに関する事前知識を有しているため、後知恵バイアスにより都合の良い結果を見越して分析を計画するHARKing (hypothesizing after the results are known)を起こしやすい(Baldwin et al., 2022; van den Akker et al., 2021)。そこで事前登録の中で、分析者がデータ取得前にどの程度の事前知識を有した状態で分析を考えたかを記すことで、事前知識の影響を後から自他が検討できるようになる。なお本研究では、分析者は事前登録段階で、中村・三浦(2019)に掲載されている以上の事前知識を有していない。中村・三浦(2019)のデータは、同論文でHSMの適用可能性についての肯定的な結論を導いたものではあるが、上で述べたデータ分析方法の限界点を踏まえれば、たとえデータに関する事前知識の影響があったとしても、中村・三浦(2019)とは異なる分析方法で、同じデータからHSMの適用可能性を検討する意義は小さくないと言えるだろう。とは言え、事前知識の影響は完全には免れ得ないため、少なくともその影響の如何を検討できる透明性の担保は重要である(Weston et al., 2019)。以上より本研究では、データ取得前に事前登録した分析を確証的分析として、またデータ取得後に考えた分析を探索的分析として報告する。
以下では、個人、メッセージ、群をそれぞれ添字i(=1,…,I), j(=1,…,J), c(=1,…,C)で表す。メッセージ数Jについては、NM実験にて1種類の弱い論拠のメッセージおよび4種類の強い論拠のメッセージが使用されたため、J=5とし、j=1が内集団成員による弱い論拠のメッセージ、j=2, 3, 4, 5が外集団成員による強い論拠のメッセージを表すとする8)。また、群の数Cに関しては、研究1, 2で計4群が設けられたため、C=4とする。特に、認知資源の制限が最も小さいと想定されている、研究2の制限なし群をc=1とする。
第一に、群cに属する個人iの処理様式を数理的に表現する。個人iの動機づけ、認知資源の相対的な程度をそれぞれηi, θi∈[−∞,∞]とする。HSMでは、これら2つの要因のうちどちらかでも不十分であればヒューリスティック処理が優勢になるという非補償的な関係を仮定している。この関係を表現するために、システマティック処理の度合いを表すzic∈[0,1]が、
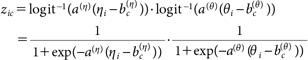 | (1) |
で決定されるとする。この関数形は二次元非補償型項目反応モデルと同形である(Reckase, 2009)。a(η), a(θ)∈(0,∞)はそれぞれ、ηi=bc(η), θi=bc(θ)付近における、ηi, θiのzicへの影響の大きさに対応している。また、bc(η), bc(θ)∈(−∞,∞)はそれぞれ、logit−1(a(η)(ηi−bc(η)))=0.5, logit−1(a(θ)(θi−bc(θ)))=0.5となるηi, θiの値に対応しており、これらの値が大きいほど、群cでの操作による動機づけの低下ないし認知資源の制限の程度が大きいことを表す。(ηi−bc(η)), (θi−bc(θ))の少なくとも1つが小さいとき、zicは0に近くなり、システマティック処理があまり行われないことを示す。反対に、これらが共に大きな値の時にはzicは1に近くなり、システマティック処理がよく行われることを示す。
なお、中村・三浦(2019)は、動機づけが十分確保できていることを仮定することで、群毎に異なる処理様式が主流となることを導いている。認知モデルでもこの仮定を用いて、ηi=∞と仮定する。また、モデルの倹約性とそれに伴う推定の安定性のため、a(θ)=1と制約すると、(1)式は簡単に、
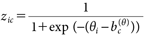 | (2) |
となる9)。ここで、θi~N(0, 12)という事前分布により原点の不定性を解消する。ワーキングメモリを測定するさまざまなテストの得点分布が正規分布で近似できることから(Kane et al., 2004)、この正規性の仮定は妥当だと考えられる。また、推定の安定性のため、b1(θ)<0とする。この仮定は、c=1の群、つまり最も認知資源の制限が小さい操作を受けた群では、E[zi1]>0.5となる、すなわち平均的に中程度以上のシステマティック処理が行われることを意味しており、解釈上妥当な仮定と言える。
第二に、メッセージを読んだ際の認知的処理について表現する。ヒューリスティック手がかりと論拠という2つの情報を処理するに伴って、参加者が主観的な満足感、言い換えれば心理的な効用を得ると仮定する。より望ましいヒューリスティック手がかりや、より強い論拠を処理したときに、大きな満足感、すなわち効用を得られるとするこの仮定は、直観に沿った自然なものだと考えられる。個人iがメッセージjのヒューリスティック手がかりと論拠から得る効用をそれぞれuij(h), uij(s)∈(−∞,∞)と表現する。特にヒューリスティック手がかりの効用については、NM実験で測定されている集団同一視尺度の標準化得点xiをモデルに投入して、効用の個人差を表現する。論拠の効用の個人差に関する変数は特に測定されていないため、個人差はないと仮定する。以上より、効用uij(h), uij(s)を
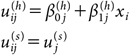 | (3) |
で表現する。xiは中心化されているため、β0j(h)はヒューリスティック手がかりの効用の平均を表す。
群cに属する個人iがメッセージjから得る効用uijcは、これら手がかり毎の効用uij(h), uj(s)と、システマティック処理の度合いzicを用いて、
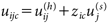 | (4) |
と決まると仮定する。この関数形は、効用の重みを1,zicとしたときの加法的効用関数と同形である(Keeney, 1974)。zic≈0のときuijc≈uij(h)となり、これはヒューリスティック処理の際にはヒューリスティック手がかりのみの効用を得ることを表す。反対に、zic≈1のときuijc≈uij(h)+uj(s)となり、これはシステマティック処理の際にはヒューリスティック手がかりと論拠の両方の効用を得ることを表す。この表現はHSMの主張と整合的である(中村・三浦,2019)。
なお、uijcは原点と単位、符号の不定性を有している。このうち符号の不定性を解消するため、メッセージj=1の弱い論拠から得られる効用が負であること、すなわちu1(s)<0を仮定する。残りの不定性については後述する。また実験状況上、メッセージj=2, 3, 4, 5のヒューリスティック手がかりはいずれも外集団成員であるという情報なので、
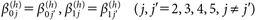 | (5) |
と制約する。
第三に、効用と態度指標の回答データとの関係を表現する。絶対態度の回答データyijc(abs)はそのメッセージの効用uijcによって、相対態度の回答データy(rel)ijj′cは比較する2つのメッセージの効用の差uijc−uij′cによって決まるとする。これらの関係を因子分析モデルで仮定すれば、
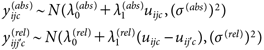 | (6) |
と表せる(σ(abs), σ(rel)>0)。
ここで、uijcの原点と単位の不定性を解消するため、uijc=0のときの絶対態度の回答の期待値λ0(abs)が、回答範囲(ここでは7件法)の中央値であると仮定する。さらに、効用の1単位を絶対態度の回答における1点に対応させることで単位の解釈性を担保する。同様に、比較する2つのメッセージの効用が等しいとき、つまりuijc=uij′cのときの相対態度の回答の期待値λ0(rel)も、回答範囲(ここでは10件法)の中央値であるとする。これらの仮定は、
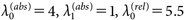 | (7) |
と表現できる。またλ1(rel)については、uijc−uij′cが大きいほど相対態度の回答y(rel)ijj′cが大きい値になるよう、λ1(rel)>0とする。
最後に、本研究ではベイズ推定によりパラメタを推定するため、事前分布を指定する必要がある。認知資源に関わるパラメタθi, bc(θ)については、θi~N(0, 12)に対して、|bc(θ)|<3の範囲で、ほぼすべての個人でzic<0.5となる、つまりヒューリスティック処理が優勢になる状況から、zic>0.5となる、つまりシステマティック処理が優勢になる状況までを網羅できるため、この範囲にある確率を約95%と仮定する。効用については、(6), (7)式より、7件法である絶対態度の回答データyijc(abs)とその中央値λ0(abs)=4との差の期待値として、効用uijcを見ることができる。この差の絶対値は3以下であることから、効用に関わるパラメタβ0j(h), β1j(h), uj(s)の絶対値が3以下である確率を約95%と仮定する。因子分析モデルに関わるパラメタのうち、λ1(rel)は2つのメッセージの効用の1単位の差が相対態度の回答における何点に対応するかを表すものである。効用の1単位が絶対態度の1点に対応していることから、相対態度での対応がほぼ3点以内だと想定し、3以下である確率を約95%と仮定する。またσ(⋅)は測定誤差を表しており、大きくても3点以内に収まると想定できることから、誤差の絶対値が3以下である確率を約95%と仮定する。これらの仮定と、今までに導入した符号の制約を踏まえて、事前分布を
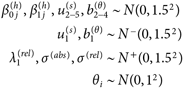 | (8) |
とする。ここでNの上の符号の添字はその符号の範囲のみを台に持つ半正規分布であることを表している。
以上の認知モデルについてシミュレーションを行い、認知モデルがデータから適切にパラメタを推定できることを確認した。詳細な方法と結果はSIを参照されたい。
中村・三浦(2019)と同様のデータを用いるが、そのうち使う変数は表1の通りである。NM実験で測定された他の変数に関しては、構成概念との対応が明らかでないため使用しないこととした。これらのデータを用いて、認知モデルのパラメタをマルコフ連鎖モンテカルロ(MCMC)法によりベイズ推定した。計算にはR version 4.2.0 (R Core Team, 2022)およびStan version 2.26.1 (Stan Development Team, 2022)を用いた。長さ12,000(うちウォームアップ期間2,000)のチェーンを4本発生させ、計40,000の乱数により事後分布を近似した。すべてのパラメタについて乱数列がR̂≤1.10を満たした場合に収束したと判断した。
| 実験内の変数 | モデル内の変数 | 備考 |
|---|---|---|
| 全般的な態度 | y(rel)ijj′c | 大きな値であるほどメッセージjをj′よりも選好していることを表す。 |
| 各候補者の政策に対する態度 | yijc(abs) | |
| 集団同一視尺度 | xi | 得点を標準化して用いる。 |
| 強論拠メッセージのパターン | j(=2, 3, 4, 5) | j=1は弱論拠メッセージに対応する。 |
| 認知資源の操作 | c(=1, 2, 3, 4) | 順に研究2の制限なし群、制限あり群、研究1の制限なし群、制限あり群に対応する。 |
注)実験内の変数の表記は中村・三浦(2019)に準じた。
まず、表象の忠実度基準を評価するために、事後予測チェックを行った。事後予測チェックとは、観測された実データ、予測データ、パラメタをそれぞれY, Ỹ, φとするとき、事後分布で尤度を重みづけて算出される事後予測分布p(Ỹ|Y)=∫p(Ỹ|φ)p(φ|Y)dφと実データの分布とを比較するものである10)。データに差異をもたらす重要な要因や構造が認知モデルで表現されていれば、実データから推定した事後分布で重みづける事後予測分布は実データの分布と近いものとなる。反対に、重要な要因や構造が認知モデルで表現されていない場合には、事後予測分布と実データの分布との間に大きな乖離が生まれる。よって、事後予測チェックは表象の忠実度基準を評価する方法だと言える。そこで、態度指標yijc(abs), y(rel)ijj′cの事後予測分布と実データの分布とを視覚的に比較した。加えて、態度指標間の相関係数に関する事後予測p値を算出した(Gelman et al., 2014)。
モデル比較次に、動的な忠実度基準を評価するため、BFを用いたモデル比較を行った。BFは事前分布で重みづけた尤度である周辺尤度p(Y)=∫p(Y|φ)p(φ)dφの比として定義される。周辺尤度はその定義より、データを用いずにパラメタの分布を決める場合の予測である事前予測分布と、データとの類似性を評価する指標だと解釈できる。また、データを部分的に用いてパラメタの分布を更新したモデルの予測性能を表す交差妥当性の観点からも、周辺尤度を解釈できる。すなわち、対数事後予測確率をスコアリングルールとするとき、p個抜き交差検証スコアのpに関する総和が対数周辺尤度に等しくなる(Fong & Holmes, 2020)11)。以上より、周辺尤度の比であるBFを、モデルの予測性能、すなわち動的な忠実度基準の評価指標として用いる。BFの値の解釈には、Lee & Wagenmakers (2013 井関訳 2017)の表7.1(p. 92)を用いた。また周辺尤度の計算には、ブリッジサンプリング法を用いた(岡田,2018)。
比較対象のモデルとしては、中村・三浦(2019)で用いられていた、絶対態度に関する分散分析モデル12)、相対態度に関する中央値回帰モデルを用いた。前者のモデルのうち事前分布を除いたものは、Rouder et al. (2017)を参考に、
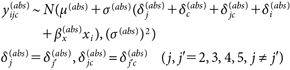 | (9) |
とした。また、後者のモデルのうち事前分布を除いたものは、Benoit & Van den Poel(2017)を参考にしつつ、分散分析モデルとの統一性を考慮して、
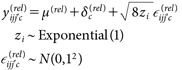 | (10) |
とした13)。
BFは事前分布の影響を強く受けるため(岡田,2018)、比較対象とするモデルについて事前分布を複数設定し、結果の頑健性を検討する感度分析を行った。ここでは特に、客観的事前分布としてよく用いられるJeffreys-Zellner-Siow (JZS)事前分布、および提案した認知モデルと同様の主観的事前分布を考えた。JZS事前分布では、岡田(2018)を参考にして
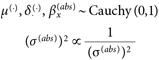 | (11) |
とした。主観的事前分布では、
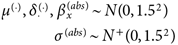 | (12) |
とした14)。
メッセージや操作の質最後にパラメタの推定値から、実験におけるメッセージや操作の質が実験者の意図通りだったかを検討した。具体的には、以下の5つの命題が意図されていると考えた。(a)メッセージのヒューリスティック手がかりについて、候補者が内集団成員である方が外集団成員よりも平均的に好ましいこと、すなわち
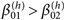 | (13) |
であること。(b)メッセージのヒューリスティック手がかりについて、集団同一視尺度の得点が高い人ほど、内集団成員を好み、また外集団成員を好まないこと、すなわち
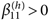 | (14) |
 | (15) |
であること。(c)メッセージの論拠について、強い方が弱い方よりも好ましいこと、すなわち
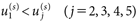 | (16) |
であること。(d)メッセージの論拠について、強論拠の間で好ましさに差がないこと、すなわち
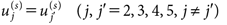 | (17) |
であること。(e)認知資源の操作について、研究1、2のそれぞれで制限あり群の操作による認知資源の制限が制限なし群よりも大きいこと、すなわち
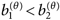 | (18) |
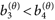 | (19) |
であること。
上記の各命題について、補仮説(complement hypothesis)を対立仮説としたBFによるモデル比較で検討した。具体的には、(13)式のような情報仮説については、
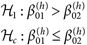 | (20) |
としたときの、
 | (21) |
を評価した(Hoijtink et al., 2019)15)。ここでc1とf1はそれぞれ、事前分布と事後分布における、H1と整合的なパラメタ空間の割合を表している。実際の計算においては、c1には事前分布から解析的に求めた理論値を用い、f1にはMCMCサンプルのうちH1と整合的なサンプルの割合を近似値として用いた。また、(17)式の点仮説に対しては、無制約仮説(unconstrained hypothesis)を対立仮説として
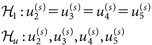 | (22) |
としたときのBF1uを評価した。ここで、提案した認知モデルはHuに対応しているため、H1の制約を加えたモデルで別途推定を行った。周辺尤度の計算にはブリッジサンプリング法を用いた。以上の分析内容は、すべてデータ取得前に事前登録したものである。
結果推定の結果、すべてのパラメタについて、乱数列がR̂≤1.10を満たしたため、収束したと判断した。パラメタの事後分布はSIにて示す。
事後予測チェック事後予測チェックの結果を図1に示す。各態度指標の分布については、事後予測分布が実データの分布とよく類似した。態度指標間の相関係数のうち、絶対態度と相対態度との相関係数については、事後予測p値は0.5に近い値となった。一方、内集団成員と外集団成員に対する絶対態度間の相関係数については、事後予測分布が負の範囲を中心に分布していたのに対して、実データではほぼ無相関であり両者に乖離が見られ、事後予測p値が0.017と極端な値を示した。

注)対角成分の図は、左上から順にそれぞれ、内集団成員(弱論拠メッセージ)に対する絶対態度、外集団成員(強論拠メッセージ)に対する絶対態度、相対態度の事後予測チェックを表す。濃線は実データの分布、薄線は50個のMCMCサンプルそれぞれから生成した予測データの分布に対応している。下三角部分は各指標間の相関係数の事後予測分布を表す。ヒストグラムは各MCMCサンプルから生成した予測データの相関係数についてであり、濃線は実データの相関係数を示している。上三角部分は各指標間の相関係数の事後予測p値を示す。
提案した認知モデル、およびJZS事前分布、主観的事前分布を持つ比較対象のモデルの対数周辺尤度はそれぞれ、−635.071, −739.071, −727.170であった。比較対象のモデルの両者に対して、認知モデルを支持する極めて強い証拠が得られた(認知モデルを分子として、順にBF=1.468×1045, 9.953×1039)。
メッセージや操作の質メッセージのヒューリスティック手がかりのうち、(a)平均的なメッセージ間差については、(13)式を支持する極めて強い証拠が得られた(BF1c=Inf)16)。一方、(b)集団同一視尺度との関連については、(14)式を支持する中程度の証拠、(15)式を支持する事例的な証拠が得られるにとどまった(それぞれBF1c=3.511, 1.580)。メッセージの論拠のうち、(c)弱論拠と強論拠との比較については、いずれの強論拠のメッセージについても、(16)式を支持する極めて強い証拠が得られた(j=2, 3, 4, 5のいずれもBF1c=Inf)。また、(d)強論拠間の比較についても、(17)式を支持する極めて強い証拠が得られた(BF1u=3451.597)。(e)認知資源の操作については、(18)式を支持する非常に強い証拠が得られた一方、(19)式については強い証拠が得られるにとどまった(それぞれBF1c=48.867, 13.583)。
事後予測チェックでは、絶対態度間の相関係数について、認知モデルによる事後予測と実データとの間で乖離が見られた。この乖離が、モデルの重要でない仮定によるものか否かを確認するため、仮定を変更した2つの認知モデルでパラメタを推定し、確証的分析と同様の事後予測チェックを行った。その結果、元の認知モデルと同様の結果が得られた。
また、メッセージや操作の質の検討では、(b)メッセージのヒューリスティック手がかりと集団同一視尺度との関連について、実験者の意図通りとは言えない結果が得られた。この原因として、集団同一視尺度の標準化得点を用い、尺度項目の異質性を考慮していなかったことが考えられる。そこで、項目反応モデルを用いて推定した個人毎の集団同一視の程度と、標準化得点との相関を調べた結果、両者の間に高い相関が見られ、尺度項目の異質性が結果に影響しないことが確認された。探索的分析の詳細な方法と結果はSIを参照されたい。
本研究では、複数源泉・複数方向の説得状況におけるHSMの適用可能性について、中村・三浦(2019)と同じデータを用いつつも、認知モデリングという異なる方法で検討した。ここでは、分析結果から得られる示唆と共に、本研究の意義と今後の展望について論じる。
HSMの適用可能性事後予測チェックでは、提案した認知モデルが実データの重要な要因や構造をおおむね把捉していた。またBFによるモデル比較では、認知モデルが分散分析モデルよりも実データを良く予測できた。よって、HSMないしこれに基づいたモデルである認知モデルは、表象の忠実度基準および動的な忠実度基準の観点から高く評価できるため、複数源泉・複数方向の説得状況における態度変容プロセスのモデルとして適用可能だと結論づけられる。この結論は中村・三浦(2019)と同様であるが、本研究では2つの忠実度基準に照らして、モデルと現実との類似性を評価している。加えて、メッセージや操作の質の十分性は仮定せずに、事後予測チェックではデータから推定した質を所与とした事後予測、BFによるモデル比較ではデータ取得前に有し得る弱い情報を用いた事前予測と、実データの分布とを比較しており、「HSMは適用可能でない」という結論にたどり着く可能性を確保している。したがって、本研究の結論はより適切に導かれたものだと考えられる。
ただし事後予測チェックでは、絶対態度間の相関係数について事後予測分布と実データが乖離するという、認知モデルを支持しない証拠も得られた。探索的分析では、この乖離がモデルの重要でない仮定によるものではなく、頑健であることを確認した。探索的分析はあくまで部分的な頑健性の検証に過ぎないものの、HSMに従えば、システマティック処理の度合いが大きい個人ほど、弱論拠のメッセージを低く、強論拠のメッセージを高く評価するという予測は理に適っている。よって、絶対態度間に負の相関があるという事後予測は、HSMの主要な仮定に起因しており、故に実データの無相関性はHSMに反する証拠と言えよう。
BFによるモデル比較では認知モデルが支持されたものの、この支持はあくまで相対的なものであり、より説明・予測性能の良いモデルの存在を否定しない。今後はこの無相関性をも説明・予測できるように、HSMの改良、ないし新たなモデルの提案が望まれる。態度指標間の相関係数という、中村・三浦(2019)では検討されなかった指標を、モデルの改善への道標として提示した点は、本研究の意義の1つである。
メッセージや操作の質認知モデルを所与としたときのパラメタの解釈では、(b)メッセージのヒューリスティック手がかりと集団同一視尺度との関連について、(14)式、(15)式のいずれも実験者の意図通りとは言えないという結果が導かれた。探索的分析では、この結果が尺度項目の異質性の考慮の有無に対して頑健であることを確認した。これらの結果は、中村・三浦(2019)の分析において、ほぼすべての態度指標と集団同一視尺度得点との間に有意な相関が見られなかったことと対応している。
このような結果となった原因としては、参加者自身が意図しない内に集団同一視が働いているという可能性が挙げられる。実際、集団同一視に関する顕在測度と潜在測度との相関は大きくないという証拠が得られている(March & Graham, 2015)。今後は潜在測度など他の測度を用いることで、集団成員性がヒューリスティック手がかりとして態度の個人差を説明・予測し得るかを検証することが望まれる。また、本研究では二次分析の都合上、論拠の効用には個人差がないと仮定した認知モデルを用いたが、今後はヒューリスティック手がかりのみならず、論拠についてもその効用の個人差を測定する共変量を投入することで、より正確に認知モデルが態度を説明・予測できるようになるかを検討することが求められる。
また、(e)認知資源の操作のうち、実験1の操作の効果の群間差についての仮説である(19)式は、強い支持を得るにとどまった。この結果は、研究1で認知資源の操作が不適切だったとする中村・三浦(2019)の考察と一致する。しかし本研究の結果は、分析結果を見た後の推論ではなく、認知資源と態度指標との関係を、データ取得前に数理モデルで制約した上で導かれたものであるため、より信頼できる結果だと言えよう。
その他、(a)メッセージのヒューリスティック手がかりの平均的な差、(c)弱論拠と強論拠との比較、(d)強論拠間の比較については、実験者の意図通りであったことが示唆された。特に(c), (d)に関しては、中村・三浦(2019)における論拠の操作チェック項目の分析結果とおおむね一致している。中村・三浦(2019)は考察で、論拠の操作チェックに集団成員性が影響してしまっている可能性について論じているものの、もし操作チェック項目の評定値が論拠の強さと十分対応しているならば、この一致は認知モデルのパラメタと想定している構成概念とが十分対応していることの証左として解釈できる。パラメタを通したメッセージや操作の十分性の検討は、あくまで認知モデルを所与とした上での推測であるため、今後は操作チェックをより多く含めた実験を行うことで、その他のパラメタも構成概念と対応しているのかを検証する必要があるだろう。
今後の展望最後に、本研究の限界と今後の展望について述べる。第一に、本研究ではデータに関する事前知識を持った状態で認知モデルを開発し、二次分析を行った。そのため、認知モデルは今回のデータ特有の頑健でない特徴に対して過適合している可能性がある。事後予測チェックで確認した事後予測分布と実データとの類似も、この過適合によるものかもしれない。今後は追試を行うことで、事後予測チェックやBFによるモデル比較で得られた本研究の結果の再現性を検証していくことが望まれる。
追試データの分析においても、認知モデルの果たす役割は大きい。認知モデルを用いれば、元の研究と追試との共通点および相違点を、分析に自然に反映できる。NM実験をそのまま追試する直接的追試であれば、本研究の事後分布を、メッセージや操作のパラメタの事前分布として置けばよい。対して、メッセージや操作を一部変更する概念的追試であれば(加藤,2018)、変更していないメッセージや操作のパラメタには本研究の事後分布を、変更したメッセージや操作のパラメタには弱情報事前分布を、事前分布として置けばよい。これにより、本研究で用いたような弱情報事前分布をすべてのパラメタに置く場合よりも、適切に不確実性を小さくした形での予測ができ、データ特有の特徴に対する過適合を抑止しつつ認知モデルを評価できる。この情報の反映は、パラメタと構成概念との対応が想定されている認知モデルの強みだと言える。なお、追試研究の事前分布として元の研究の事後分布を置いた場合のBFはreplication Bayes factorとして知られている(Ly et al., 2019)。
第二に、NM実験で未検討の説明要因についても実験を行い、HSMの適用可能性を検討する必要がある。特にNM実験では、HSMの主要な説明要因である動機づけが十分確保されていることを仮定しており、認知モデルでもその仮定を踏襲した。今後は認知資源と動機づけの双方を操作する実験により、HSMで仮定されているこれらの非補償的な関係が実データで見られるかを検証することが望まれる。また、説得の順序効果(Brunel & Nelson, 2003)などその他の要因を認知モデルに含めることで、モデルの説明・予測性能がどう変化するかについても検討の余地がある。BFによるモデル比較では、影響の小さな要因を含まないモデルが支持されるため(岡田,2018)、本研究の分析の枠組みを援用した変数選択が可能である(Heck et al., 2023)。
第三に、態度変容プロセスに関する他の既存モデルを本研究の枠組みで数理的に表現することで、どのモデルがデータに照らしてより適切と言えるのかについて定量的に検討できるようになる。ここでは特に既存モデルとして、精緻化見込みモデル(elaboration likelihood model (ELM); Petty & Cacioppo, 1986)、および単一モデル(unimodel; Kruglanski & Thompson, 1999; 澁谷,2010)について考えることとする。ELMとHSMの主要な相違点は、2つの処理様式の共起に伴う相互作用を認めるか否かである(Chen & Chaiken, 1999; Luttrell, 2018)。本研究で提案した認知モデルでは、中村・三浦(2019)に則ってこの相互作用を認めず、ELMとHSMを特に区別しなかった。相互作用には、ヒューリスティック手がかりおよび論拠が同方向の態度を導くときに生じる加算効果、および逆方向の態度を導くときに生じる減弱効果があるが、これらを表現する1つの方法としては、符号関数をsgn(⋅)としたとき、uijcを決める(4)式において、sgn(u(h) u(s))に依存する項を導入することが考えられる。また、単一モデルとHSMの主要な相違点は、2つの処理様式の違いをあくまで1過程の中の量的な違いとみなすか、異なる2過程の間の質的な違いとみなすかである(Kruglanski & Thompson, 1999; Luttrell, 2018)。認知プロセスが1過程か2過程かについては、説得研究に限らず心理学研究のさまざまな領域で長く議論がされてきたが(De Neys, 2021)、認知モデルの使用によってこの議論が解決される可能性がある(Dewey, 2021)。すなわち、本研究の認知モデルでは、処理様式をzic∈[0,1]のように連続値としていたが、これをzic∈{0,1}のように二値のパラメタとし、p(zic=1)を例えば(1)式のような形で仮定することで、処理様式の違いが量的か質的かについて、モデル比較の結果に基づいて定量的に主張できる。本研究では比較対象のモデルとして、中村・三浦(2019)で用いられた分散分析などの統計モデルを用いたが、今後は数理的に表現した既存モデルとのモデル比較を行うことで、データ分析からより理論的に有意義な結果を得ることができるだろう。複数源泉・複数方向の説得状況における態度変容プロセスを説明・予測できるようになる上で、本研究は長期的に有益な知見を提供している。
1)本論文は、第1著者が2022年度に東京大学大学院教育学研究科へ提出した修士論文の一部を加筆・修正したものである。
2)本研究の実施に当たり、JSPS科研費21H00936、23KJ0684の助成を受けた。
3)本研究の実施に当たり、帝塚山学院大学人間科学部の中村早希先生、および大阪大学大学院人間科学研究科の三浦麻子先生から、貴重なデータの提供をはじめとする多大なご協力をいただきました。この場を借りて深く感謝申し上げます。
4)事前登録した分析とコード、Supplementary Information(以下、SI)、および実データ分析に用いたコードを、Open Science Framework (https://osf.io/7npma/; 以下、OSF)にて公開している。
5)中村・三浦(2019)の分析では、絶対態度については分散分析を、分布の正規性を逸脱した相対態度については中央値回帰を行っている。両者は群毎の代表値が平均値か中央値かという違いこそあるが、代表値の群間差の有無を分析する点で共通している。以下では簡便のため、より一般的な方法である分散分析に焦点化して述べる。
6)対象システムとは、現実の現象が持つ特性の一部のことであるが、以下では簡便のため、単に現実と記述して話を進める。
7)紙幅の都合上、中村・三浦(2019)のデータに対して適用する具体的な認知モデルについて説明する。HSM、およびそれを踏まえて提案された中村・三浦(2018)の実験案に適用できるより汎用的な認知モデルについては、事前登録を参照されたい。
8) NM実験では、研究1と研究2で用いたメッセージに若干の違いがあるものの、本研究ではこの違いが効用に及ぼす影響は小さいと判断し、両者のメッセージは区別せず扱うこととした。
9) HSMの仮定に従い、認知資源θiの大小によって処理様式zicが決まるようにするためには、a(θ)の値はある程度大きいことが要求される一方で、a(θ)が大きくなると、|θi|の大きな範囲ではθiのzicへの影響がほぼ0になるという問題がある。本研究ではこれらのバランスを取り、a(θ)=1とすることでθiのzicへの影響を一定程度確保した。
10)事後予測分布の名前にある「予測」とは、「(パラメタではなく)データに関する分布」であることを意味している(Lee, 2018)。事後予測チェックは、モデルの更新に用いた実データYそれ自体を予測対象とする手法であるため、「予測対象のデータ自体をモデルの更新に使用しない状態での予測」という意味での「予測」を評価できない点には注意が必要である。
11)事前登録での記述は誤っており、本稿の記述が正しい。
12)中村・三浦(2019)では、態度指標と共変量との相関が有意であった場合に共変量を分析に投入しており、その結果研究1では共変量として集団同一視尺度を加えている一方、研究2では加えていない。本研究では、研究1, 2のデータをまとめてモデルに投入して分析することを踏まえ、研究2のデータに対しても集団同一視尺度を加えて分析することとした。
13)Benoit & Van den Poel (2017)の(14)式において、50%分位点回帰を行うためτ=0.5とした。また、一般性を失わずにσ=1と制約した(Sriram et al., 2013)。
14)認知モデルから生成したデータを用いてBFによるモデル比較を行うシミュレーションを実施した結果、常に認知モデルについての極めて強い証拠が得られることを確認した。シミュレーションに用いたコードはOSFにある。
15)事前登録での式の記述は誤っており、本稿の記述が正しい。なお、事前登録した分析コードでは正しい式となっている。
16)この結果は簡便な近似計算の結果であり、真の値がBF1c=∞であるわけではないため、あくまで計算機上の出力であることがわかるよう表記した。