2. Introduction into Artificial Intelligence
AI encompasses a wide spectrum of techniques like artificial neural networks (ANN), genetic algorithms (GA), Hidden Markov Models, and others. First introduced at the famous 1956 Dartmouth conference with the goal to emulate general human cognitive capabilities, AI experienced three major waves of enthusiasm and disillusionment as a consequence of initial hype and overestimations on one side and hardware and software limitations on the other. It was not until the early 2010s that AI experienced major breakthroughs in real-world applications and adoption rates, with the most common AI techniques used today being deep neural networks (DNNs) (Ongsulee, 2017).
Fig. 1 depicts the basic principle of ANNs. Being loosely inspired by the brain, the fundamental building blocks are neurons, which are connected. The neurons are arranged in layers, with the first layer being denoted as the input layer and the last one as the output layer. Each input and output node is a representation of an input and output, e.g., a parameter of a process, a pixel in an image, or a word in a text. Inputs can be binary, integers, or continuous values. Between these two layers are a number of hidden layers, in which the modeling is taking place. Between the neurons of neighboring layers, the different connections have dedicated weights associated with them.

As can be seen in the right part of Fig. 1, which is zoomed out for one representative neuron, inputs are multiplied with their respective weights and consequently summed. The summed weight is further processed via an activation function; the resulting value is then propagated forward to successive neurons of the following layer. Through different activation functions, linearities, non-linearities, or other patterns can be introduced, with the resulting behaviors of the overall system changing, such as spiking neural nets appearing, etc. Being a hierarchical statistical system, ANNs have generalizing capabilities because they process more complex patterns of a higher order on the basis of detected lower-order patterns of more limited complexity. The goal of AI training is the iterative optimization of connection weights in order to get correct outputs for given inputs based on training data. The classical approach for this is backpropagation in which after each iteration, a loss function is determined for the successive analytical approximation and adjustment of the weights. Specifically, for large AI systems with an abundance of training data, backpropagation is the classically used training approach, although it has a strong tendency toward overfitting in cases with limited data sets. Alternative systems exist, which are focused on training with more limited data, such as genetic reinforcement learning (GRL), which was described in greater detail in Thon et al. (2022b) and can be described as the training of AI via a genetic algorithm.
In addition, there exists a plethora of techniques to prevent overfitting, which can also be combined to achieve more general models, such as regularization, feature selection, early stopping, layer removal, or dropout. Regularization encompasses techniques to prevent the training of too complex models, e.g., through the use of penalties or changes in the neural network architecture upon training. L1 (Lasse regularization) and L2 (ridge regression) modify the penalties in training by adding an absolute value or the squared value of magnitude (Demir-Kavuk et al., 2011). In dropout, as another regularization method, neurons are randomly deactivated during training to prevent excessive co-adaptation (Srivastava et al., 2014). Feature selection is another method to prevent overfitting by restricting the training to only the most relevant features in case of the initial number of features in the data being too large (Hawkins, 2004). Early stopping describes the techniques of evaluating training over epochs with independent data (also termed “hold up”) to quit training once a degradation of the loss becomes detectable, indicating overfitting and a loss in generalizing capabilities (Ying, 2019). Cross-validation, as a more advanced version of hold up, allows for training and evaluation with independent data, with varying assignments of the data groups to train and test data, allowing all data to be used for training (Schaffer, 1993).
GAs are another tool often used, specifically for optimization tasks but also for modeling and regulatory applications. As shown on the left in Fig. 2, GAs are a population-based approach that mimics Darwinian evolution in biology.

As a starting point, a population of parameter sets (usually consisting of a fixed and, throughout the population, identical number of entries with variable values) is evaluated according to a stated goal. If, for instance, process parameters in a stirred media mill are to be optimized with regard to maximum energy efficiency, production yield, or the optimal combination of both KPI, measures for the optimization goal or for multiple goals are established, and the optimizable parameters are defined. Evaluation of the specified goals of initial parameter sets is performed for the selection of the most suitable parameter sets. A subsequent crossover of selected areas in the parameter space results in a new generation with mixed attributes from the previous generation. In addition, mutations are induced at specified rates to increase the “genetic” diversity of the population and to avoid optimization within local minima. Through iterative execution over multiple generations, eventually (under constant environmental conditions), a steady state is reached with ideally close to optimal parameter settings.
Genetic programming, shown on the right side of Fig. 2, applies the same steps for the iterative evolution of decision tree structures or decision trees. These tree structures can represent computer programs, with respective operators and numbers being the nodes in the tree, to automatically develop code. Alternatively, the trees can represent mathematical operators for the evolution of fitting equation systems for the description of data sets for modeling tasks. The technical term for genetic programming, when applied to formulas, is symbolic regression. In principle, all tree-based tasks can be optimized with genetic programming.
A more detailed summary of underlying AI techniques can be found in more general review papers (Krishna et al., 2018; Rupali and Amit, 2017; Raschka et al., 2020; Rahmani et al., 2021; Thon et al., 2021).
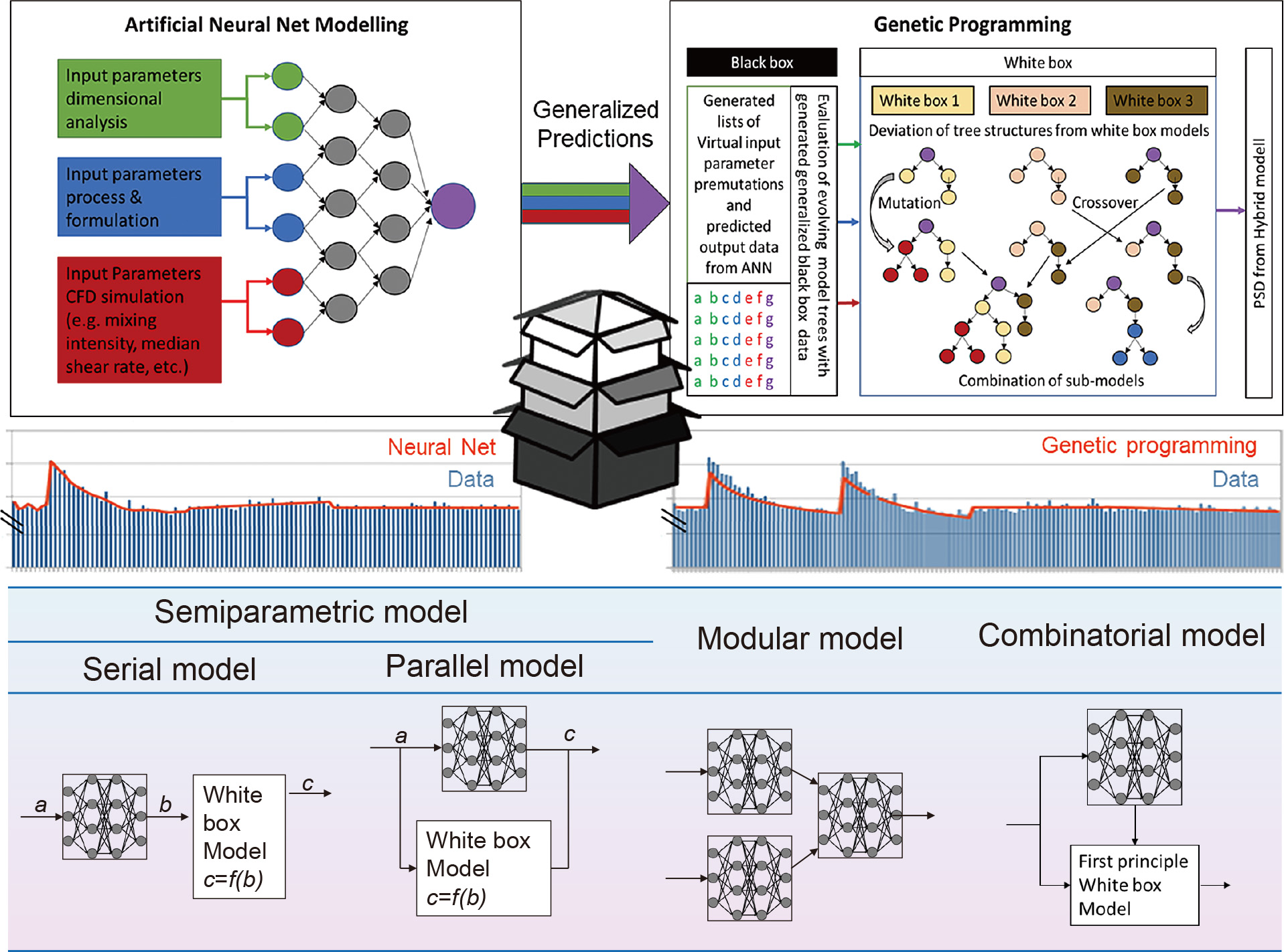
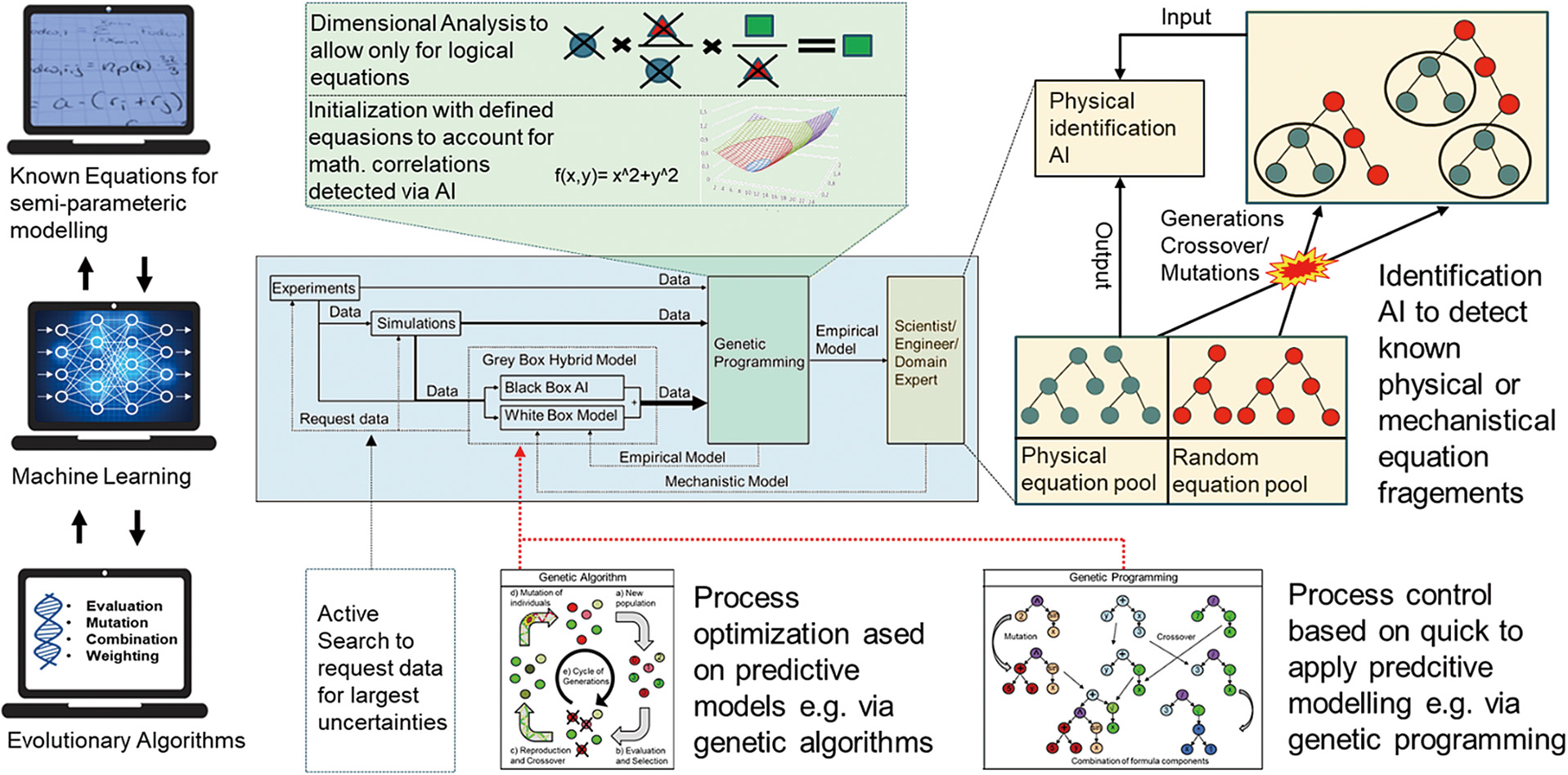
Key criticisms of AI are usually its inherent lack of transparency and its empirical nature. Different methods exist to address these issues including explainable AI (XAI), reverse engineering strategies, and hybrid or gray-box modeling. Often, respective disadvantages of different AI methods can be compensated for by the intelligent combination of different methods such as ensemble methods or hybrid approaches (Stosch et al., 2014). For instance, as seen in Fig. 3, predictive neural net modeling as a black box can be utilized in order to create a model with generalizing capabilities for the subsequent prediction of virtual training data for genetic programming.
The generalizing capabilities of genetic programming are more limited than those of neural nets. The technique is, however, intrinsically more transparent. In conjunction with additional methods, genetic programming even allows for the incorporation of physical relations (Udrescu et al., 2020).
In addition, as can be seen in Fig. 3, for an exemplary data foundation (blue), the generated equation represents a simpler (more transparent), though still accurate, relation when compared to neural net predictions (orange lines).
Similarly, McKay et al. (1996) proposed a nonlinear dynamic model using two different paradigms. In this work, they tried to compare the recurrent neural network and the genetic programming algorithm to build a viscosity model. They showed that in this particular case, the genetic programming model has simpler transparency than neural networks.
Beyond the combination of neural nets and evolutionary approaches, hybrid models, shown in the lower part of Fig. 3, are well suited for mechanistic modeling and the incorporation of existing empirical or white-box models. In a serial approach, a white-box model can be applied to preprocessed data from AI or in a direction opposite to the preprocessed data based on known relations for subsequent AI modeling. Running in parallel, black-box AI models can be used to compensate for the shortcomings of existing white-box models by merely modeling the divergence between white-box model predictions and reality. The parallel AI can, for instance, be broken down again via genetic programming to iteratively extend the white-box model (Thon et al., 2021, 2022b; Evans et al., 2019). In modular hybrid models, an interconnected system of sub-AI models is set up to mirror the known structure of its physical counterpart and facilitate the modeling effort. Combinations of hybrid models are possible, such as a mixture of a serial and a parallel semiparametric model, as Psichigios and Ungar (1992) demonstrated.
In addition, a wide variety of reverse engineering strategies exist to deconstruct or deduce the inner workings of trained AI systems, such as sensitivity analysis, dropout, deconvolution, rationalization, LIME, GAM, gradient descent, neuron activation, etc.
3. Applications of AI in particle technology
Table 1 provides an overview of AI applications for various categories of particle technology unit processes. The four classical unit operations of grinding, separation/classification, mixing, and agglomeration/granulation are elaborated on later in this paper, as well as bottom-up methods such as particle synthesis and characterization methods, including rheology.
Table 1
Overview (state July 2022) of some examples for AI in particle technology with the author, a broad description, the task, and used AI types, as well as the data foundation, sorted according to a classification scheme featuring unit operations, and tasks. Abbreviations are defined in the nomenclature before the references.
|
|
Example |
Description |
Task (process and AI) |
AI type |
Data foundation |
| Operations |
Grinding |
Qu et al. |
Fault recognition in the grinding process |
Classification |
ANNs: BP, LSTM, Auto-Encoder |
Experiments |
| Thon et al. |
Predictive modeling of kinetic energies in a wet stirred media mill with subsequent mechanistic modeling via genetic programming |
Predictive and mechanistic modeling |
ANN, GA, GP |
Simulation |
| Dai et al. |
Particle size estimation in grinding (ball mill, spiral classifier) |
Predictive modeling |
Hybrid; ANN: random vector functional-link network |
NA |
| Synthesis |
Pellegrino et al. |
Process parameter-dependent prediction of TiO2 nanoparticle morphology, size, polydispersity, and aspect ratio in hydrothermal synthesis. Reverse engineering for optimal process conditions |
Modeling and process optimization |
NA |
NA |
| Li et al. |
Identify likely synthesis patterns of gold nanoclusters |
Process optimization |
NA |
NA |
| Chen et al. |
Prediction and classification of energy expressions on the basis of structure and energy in ZnO nanoparticle morphologies |
Classification and predictive modeling |
NA |
NA |
| Zhang et al. |
Control particle distribution in a cobalt oxalate synthesis process |
Hybrid model; process control |
NA |
NA |
| Mixing |
Ittiphalin et al. |
Process control of fat addition for feed pellets for animals |
Predictive modeling for process control |
LLM, BPNN |
Preexisting data base of case study |
| Khaydarov et al. |
Data rectification through image recognition of a physical stirred reactor coupled with a CFD simulation to act as the surrogate model for process control |
Preprocessing and data rectification for process control |
DNN (YOLO model); serial hybrid model |
Mixed experimental and simulation setup |
| Aggregation |
Leal et al. |
Prediction of chemical equilibrium states effecting precipitation |
Predictive modeling |
NA |
Simulations |
| Nielsen et al. |
Prediction of process kinetics for flocculation, crystallization, and fracture to model the kinetics of nucleation, growth, shrinkage, fracture, and agglomeration |
Hybrid based on preexisting process knowledge |
NA |
Experimental (sensor data) |
| Classification/ Removal |
Hoseinian et al. |
Prediction of ion flotation-based Zn(II) removal |
Hybrid ANN-GA; predictive modeling |
ANN-GA |
NA |
| Dai et al. |
Size estimation in classification via a classifier (ball mill, spiral classifier) |
Predictive modeling |
Hybrid; ANN: random vector functional-link network |
Experiments |
| Combined System |
Tie et al. |
Online soft sensor: Particle size estimation for hydrocyclone overflow, combined with ball mill and classifier |
Predictive modeling and classification |
Modular-hybrid: 2x ANN; radial basis function networks |
NA |
| Dai et al. |
Size estimation in grinding (ball mill, spiral classifier) |
Predictive modeling |
Hybrid; ANN: random vector functional-link network |
Experiments |
| Characterization/ analysis |
Rheology |
Finke et al. |
Fit rheology model via a genetic algorithm |
Mechanistic modeling; GA |
GA |
Experiments |
| Sun et al. |
Electron transfer properties (e.g., Femi energy) dependent on the structural and morphological features of silver nanoparticles |
Predictive modeling |
ANN (three layers) |
Experiments |
Unit operations in particle technology are sometimes applied in isolation. In industrial operations, however, they are often combined and interconnected in complex plants. Possible assemblies vary to a significant degree, with some being more prominent. As can be seen in Fig. 4, the characterization of educts, products, or intermediary products can accompany the entire production flow and is often performed online during processes, as is modeling and the scale-up of operational steps. Mixing is an important operation embedded in the beginning of a process, repeated throughout the process flow, or integrated into other unit operations. Grinding as a top-down approach and synthesis as a bottom-up approach are typical operations for the production of particles. Stabilization/functionalization, agglomeration, or precipitation are unit operations often performed successively after the production of primary particles, although integrative approaches such as parallel stabilization during grinding or synthesis are also often applied. After production, primary particles, agglomerates, or aggregates can be classified, e.g., according to their size, morphology, or other characteristics and can be further processed, e.g., via extrusion. This brief overview is intended as a simplified representation of inter-dependencies and how unit operations can be integrated and connected in practical applications. The individual unit operations and accompanying steps are discussed in regard to the application of AI and evolutionary approaches.
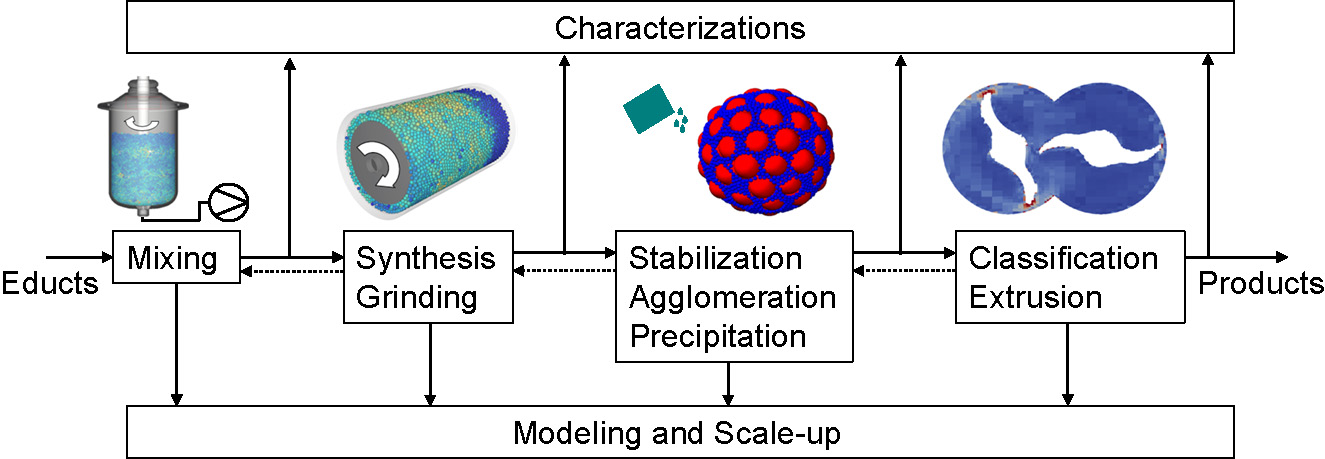
In this regard, descriptions are given together with the AI-specific tasks (predictive modeling, classification, optimization, etc.) and the used types of AI (ANNs, genetic, algorithms, and hybrid models, etc.), as well as the training data source (experiments, simulations, data banks, etc.). In the following, the respective examples for the different categories are described in more detail.
At the time of this review article, numerous works existed. However, distribution throughout the different tasks and unit operations is inhomogeneous, with many mostly small-scale academic applications and a much smaller number of practical industrial adoption cases for large connected systems or plants. Distribution between individual unit operations and accompanying steps is similarly inhomogeneous, with most publications focusing on initial unit operations such as grinding, while examples for later unit operations such as extrusion are rarer. Furthermore, most of the published works with real-world applicability are very recent since they became possible only in the last five years, with more publications appearing closer to the date of this review. This indicates that there is significant untapped potential in the field for the adoption of AI techniques and aligns well with adoption rates in most other industries, with some featuring more advanced adoption rates.
3.1 Grinding
A plethora of techniques for the creation of product particles exists, as is elaborated on in subsequent chapters. Grinding is the most widespread technique used throughout many industries for a large variety of materials and products. As a top-down approach, it is suitable to cost-effectively process large quantities of material. With a developmental history almost as old as human cultural history itself, starting with the grinding of grains, modern available equipment is well established, sophisticated, and available in a large variety for more specialized applications such as mechanochemical reactions.
AI-based preprocessing can, for instance, be applied as an initial step for predictive modeling. Going to more sophisticated systems, modular predictive models allow for the modeling of more complex plants, which can be aided by hybrid modeling and white-box model combinations. Based on this optimization, anomaly detection and mechanistic modeling can be utilized, and examples for these increasingly sophisticated models are provided.
Dimensionality reduction: As depicted in Fig. 5, one of the first possible tasks that can be performed in an AI process flow is data preprocessing and dimensionality reduction, for instance, through the use of auto encoders. With grinding, Qu et al. (2017) trained a hybrid auto-encoder-Softmax network and an RNN-LSTM network for fault recognition in a grinding system. One thousand experimentally gained data points were used, with 30 dimensional input features.

Via the reduction of the number of involved dimensions, the complexity of the data set can be drastically reduced, making successive conventional or AI modeling easier. In Qu et al., dimensionality can be reduced from 30 dimensions (such as temperatures, pressures, sounds, vibrations in different regions of the grinding system) to 24 (Qu et al., 2017). Input and output layers are set up identically. The encoder side is intended to reverse engineer and reconstruct the previously decoded representations from the input side as accurately as possible. The narrowing of intermediary hidden layers enforces more compact representations with reduced features.
Predictive modeling of single units: Based on experimental data, the authors of this review article trained predictive models (see Fig. 6), for grinding Quarz in a stirred media mill (PM1 from Bühler). Input process parameters such as tip speed, solid content, and fluid volume flow were varied, and additional values for torque and power were measured. An ANN was then optimized and trained.
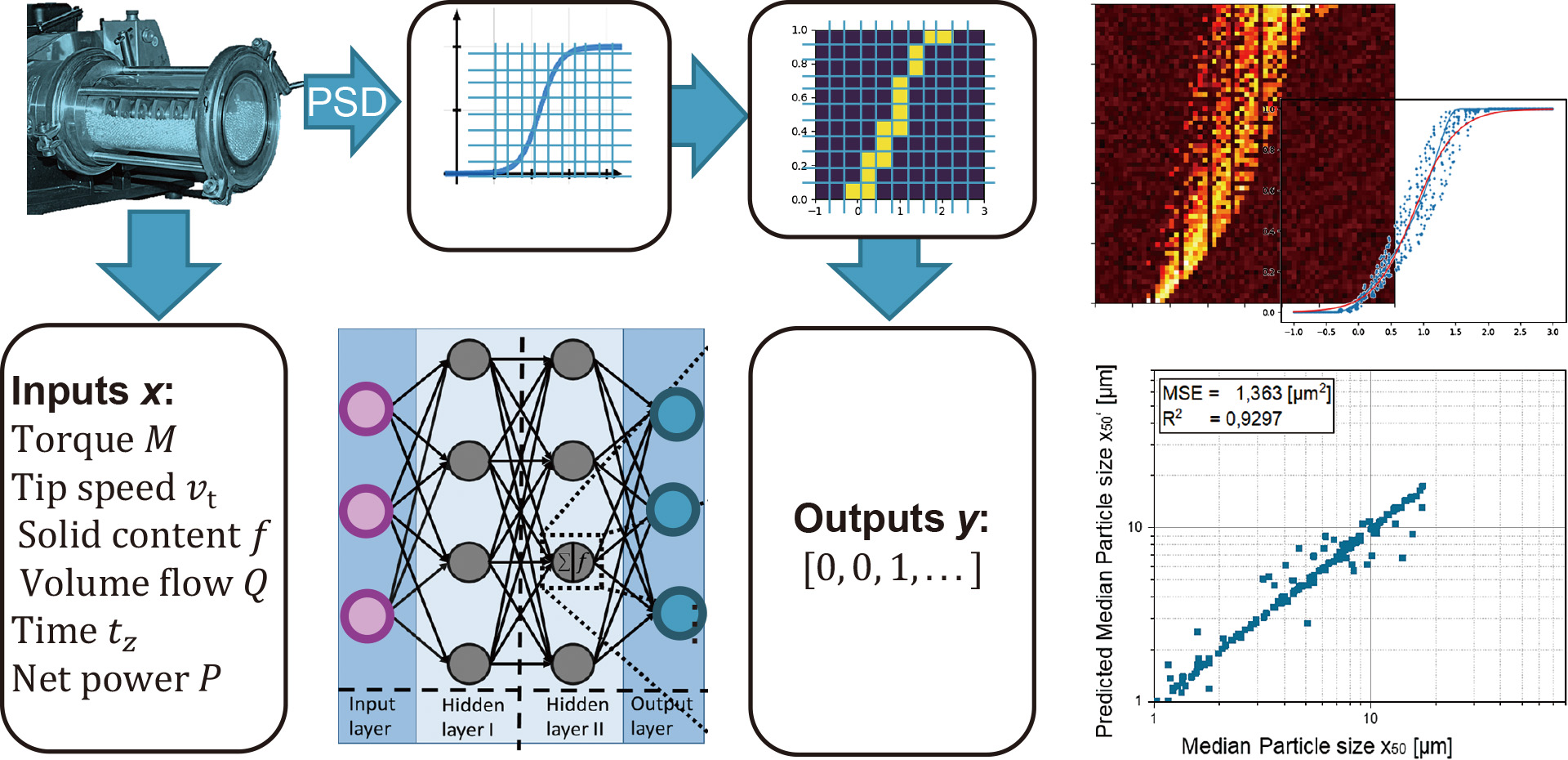
The cumulative particle size distributions (PSD) were normalized and represented via a discretized grid, with the distribution curve being in a grid cell translating to a cell value of 1 or 0. The resulting binary values were assigned to the output nodes of the net. Consequently, for novel input parameter settings, heat-maps can be generated to mark the likelihood that the respective cumulative curve will pass through a cell. During post-processing, resulting scatter plots were derived and converted to approximation cumulative curves. In the right lower part of Fig. 6, predicted X50 (describing the particle size within the distribution, at which 50 percent of particles are smaller and 50 percent larger) values are depicted over the respective X50 values of the independent evaluation data points. The approach was further optimized for the prediction of fitting parameters, which is elaborated on later in the context of describing a predictive breakage tester AI.
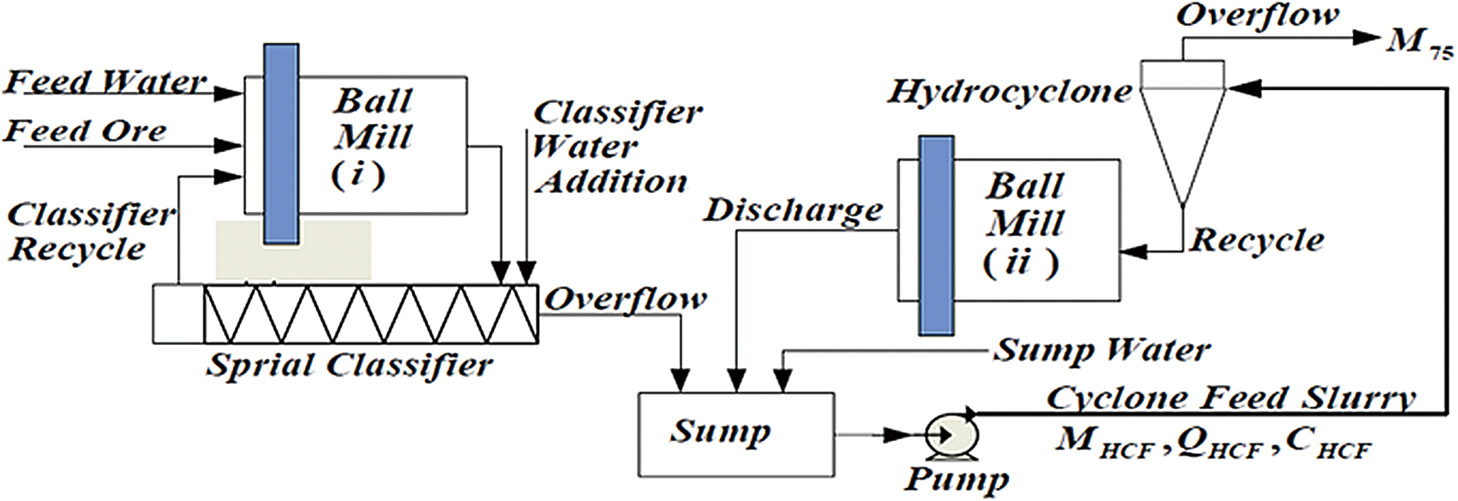
Modular predictive hybrid modeling of plants: Dai et al. proposed a parallel semiparametric hybrid particle size estimation model, in combination with a random vector functional-link network (RVLFN), with the examined grinding circuit mainly consisting of an interconnected system comprising a ball mill and spiral classifier (see Fig. 7).
The ball mill’s first principle model was based on population balance equations; the classifier was described by its own mechanistic model (Dai et al., 2015).
Based on these underlying models, sensitivity analysis and pre-predator optimization algorithms were utilized in order to reduce parameter optimization complexity. For the resulting error, the RVFLN was trained to compensate for the first principle method’s error, resulting in an overall system with significantly higher accuracy (Dai et al., 2015).
Similarly, Tie et al. (2005) demonstrated PSD estimation via an on-line soft sensor for a setup consisting of a hydrocyclone overflow and a multitude of accompanying machines such as ball mills in two connected semi-circular grinding circuits, as shown in Fig. 8.
The underlying basic structures were divided utilizing a modular approach, while the classifier and hydrocyclone were described with respective ANNs.
The percentages of solids in the mass flow with diameters smaller than 75 μm, M75, were modeled via AI in dependence of masses, concentrations, and respective flows for both the cyclone and spiral classifier. Mass percentage was furthermore modeled in dependence of multiple relevant parameters such as shaft power and recycle slurry flow rate. Sump modeling was based on a first principle population balance equation approach. The respective nets acting as functions in the overall setup (f1 for the cyclone and f2 for the classifier) were both radial basis function networks (RBF). In addition to the described models for the modeling of nominal process conditions, an adaptive neuro fuzzy inference system (ANFIS) model was trained for the upstream prediction of anomalies and malfunction, e.g., in case of excessive slurries. A subsequent fuzzy logic coordinator was applied for model connection (Tie et al., 2005).
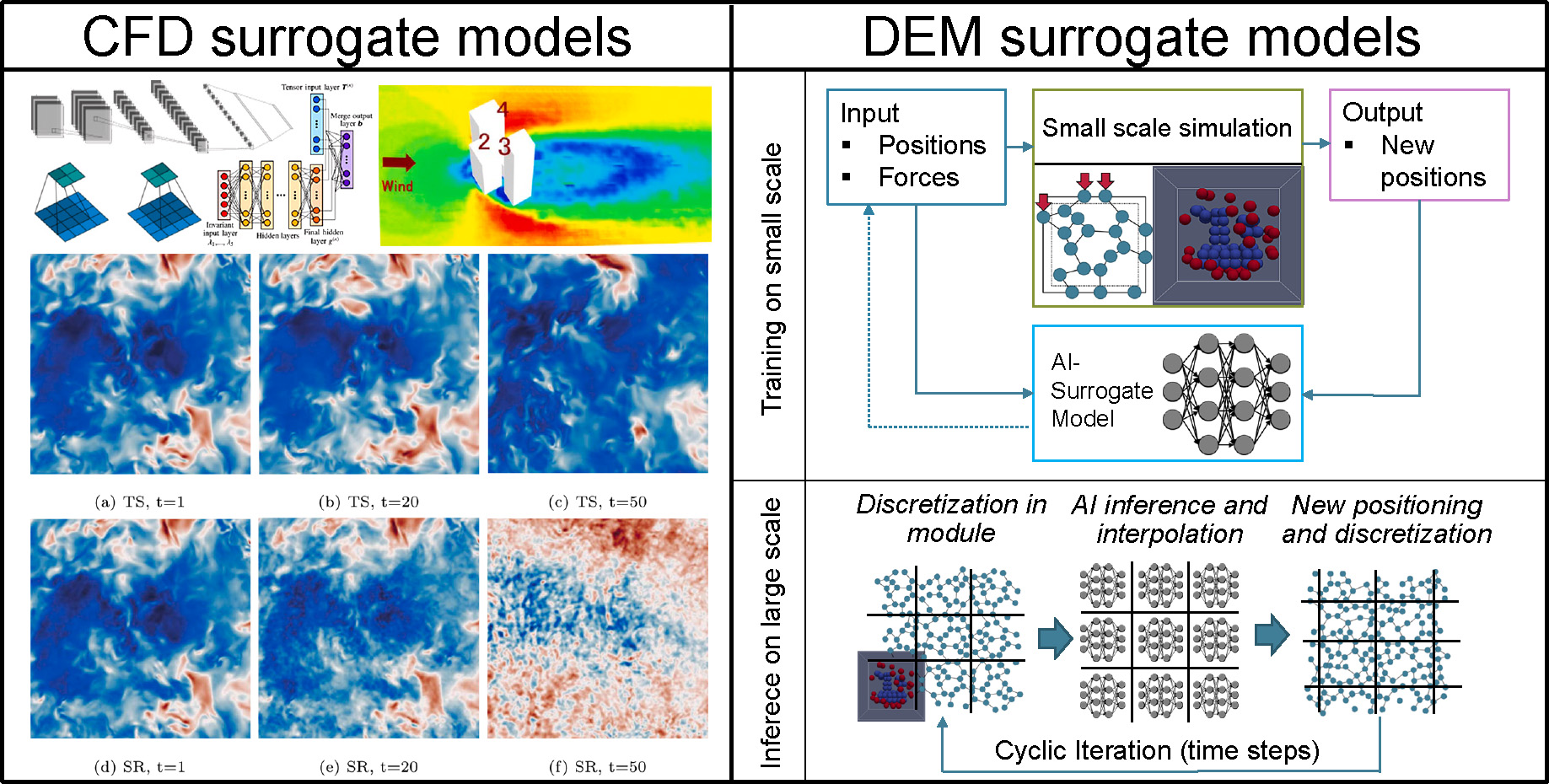
Simulation-based modeling and breakdown for mechanistic modeling: AI modeling based on simulations is an approach with distinct advantages due to the coupling of two numerical approaches, as they can autonomously interact with one another unsupervised (for instance in active learning (AL), etc.). As an example, on the basis of two-way coupled computer fluid dynamics - discrete element method (CFD-DEM) simulations with Rocky DEM and Ansys Fluent, a representative slice of a wet operated stirred media mill was simulated with varying tip speeds and grinding bead diameters (Thon et al., 2022a; 2022b). Heatmaps were extracted, with each voxel representing the averaged values of relative velocities. Fig. 9 depicts the results of the approach.
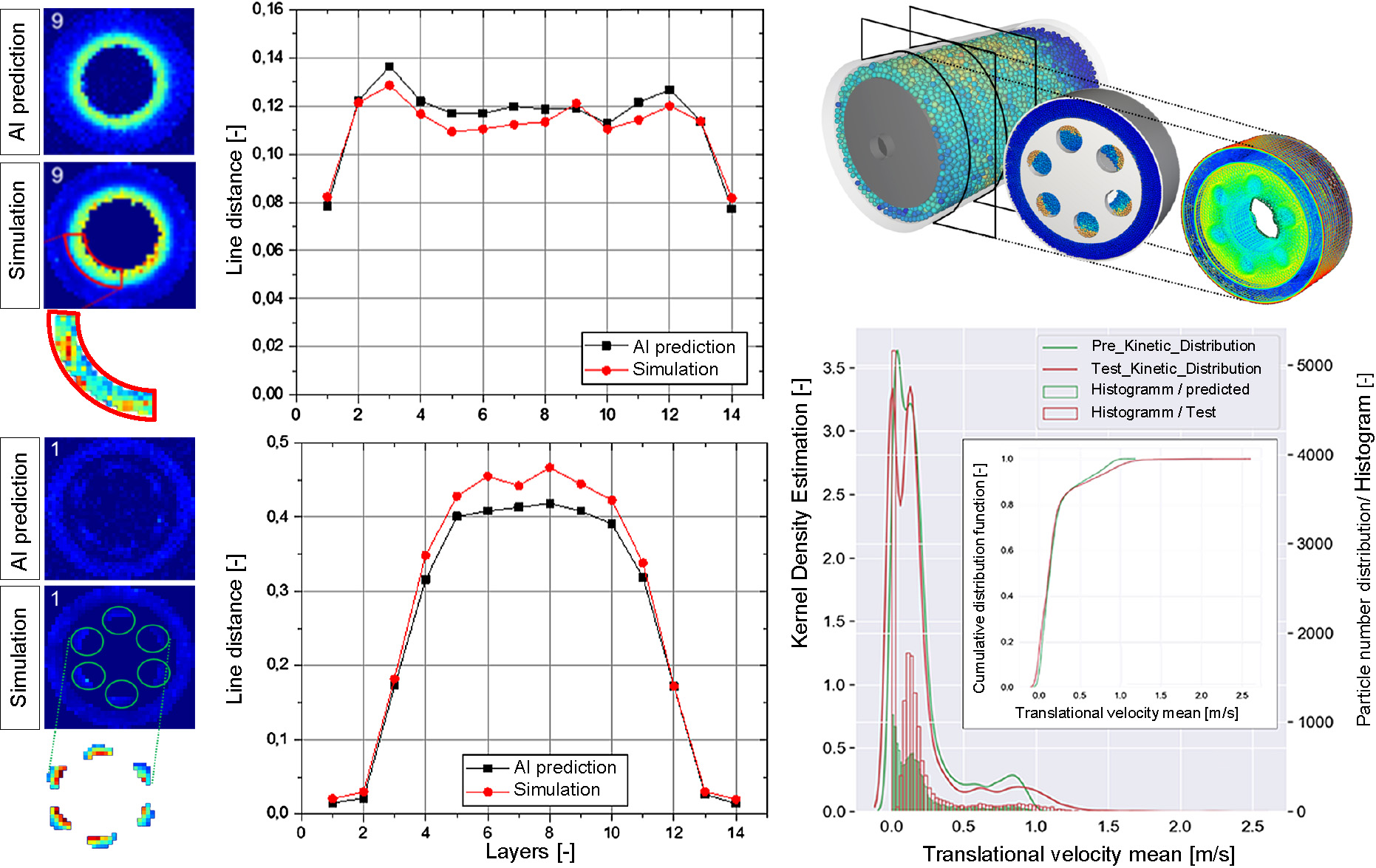
On the left side of Fig. 9, heatmaps for an independent test case not used in training are shown, with the prediction respectively depicted over the independent simulation result. Averaged values in 14 layers, as well as the density distribution of the entire domain for relative velocity, demonstrate the good fit of the result. The results also proved the advantages of GRL, as the models achieved significantly more accurate results in comparison to classical backpropagation. Finally, genetic programming was applied to identify a fitting equation to describe the relationship between the relative velocities 99 of colliding beads (99 percent had smaller energies) and the absolute tip speed of the stirrer. Depicted in the lower right corner of Fig. 9, parameter settings in random order are depicted, with red marking the equation and black the evaluation data.
The methodology was further improved and adapted to a vertical dry stirred media mill (original unpublished work by the author), demonstrating its universality, regardless of wet and dry states in grinding. In this case, a vertical mill was numerically investigated in Rocky DEM. Restitution coefficients and friction coefficients were determined and calibrated beforehand. Stirrer tip speed, grinding bead size, and grinding aids for the variation of powder flowability (considered via the preliminary determined calibration parameters in the simulation) were chosen as input parameters, and the relative velocity voxels of the discretized mill domain (with a resolution in x, y and z of 46 × 22 × 22 voxels) were considered the output (see Fig. 10).

Adding to the previous approach, a convolutional neural net (CNN) was applied. CNNs are an approach often used in image recognition, in which pooling layers are introduced, with a sliding box sampling and condensing the features of a wider discretized domain, which can be seen in the upper part of Fig. 10. It can be seen that the predicted result comes close to the real values, which is also evident in the density distribution curve with close to convergent curves.
The main advantage of predictive AI as an intermediary modeling tool lies in its generalizing capabilities. Based on evaluated generalizing models, AI predictions can be obtained in inference for a large parameter space of high resolution whose systematic simulation, if performed completely, can take significantly longer. In the case of the wet mill simulation, systematic AI predictions were generated in the order of seconds, which would have taken time in the range of years with conventional CFD-DEM simulations (Thon et al., 2022a; 2022b).
3.2 Synthesis
AI can be used for the prediction of various particle properties and required synthesis pathways, as well as for the investigation of their correlations. Furthermore, AI can be used for synthesis control and optimization to achieve desired results.
Energy growth prediction: Chen and Dixon (2018) developed a machine learning (ML) approach to identify the relationships between the structure and surface and fragment energy in ZnO nanoparticle morphologies in bottom-up growth using nanoparticle fragments and derived means for the classification and energy expression of the nanoparticles. The focus was on the ML-based investigation of the stability, phase transition, and growth patterns of clusters, ultra-small nanoparticles, and bulk-sized particles based on fragment geometries and energy parameters.
Shape prediction: Pellegrino et al. (2020) demonstrated an ML approach for the predictive modeling of TiO2 nanoparticle morphology, the size, polydispersity, and aspect ratio in dependence of process parameters such as the initial concentrations of Ti (TeoaH)2, additive concentrations of TeoaH3 as the shape controller, pH values, temperature in a hydrothermal synthesis process. Inversely, it can be used as a reverse-engineering approach to predict optimal process conditions for specific desired product characteristics in terms of aspect ratio, morphology, and size.
Process control for shape (hybrid): Zhang et al. (2012) demonstrated a hybrid model to control particle size distribution in a cobalt oxalate synthesis process, with the first principle model capturing the known process characteristics with a partial least-squares (PLS) regression ML model to compensate for its shortcomings, with the combined model being capable to model the PSD evolution. The reaction took place in a two-reactor system being connected in series, with the first acting as an ammonium oxalate dissolver and the second being responsible for the successive crystallization.
Process optimization for yield: Jose et al. (2021) demonstrated that AI in the form of multi-object ML optimization can also be used for the optimization of product yields with the example of ZnO nanoparticle synthesis. The optimization relied on high-yield microreactors and high-throughput analysis. In less than 100 experiments, optimization could be achieved, allowing for the continuous production of 1 kg per day. A scalability assessment of the approach was conducted.
Prediction, experimental planning, and synthesis-assistance: A dedicated review article that Tao et al. (2021) conducted focused on the use of AI in the specific context of nanoparticle synthesis. Examples were provided for the prediction of nanoparticle properties, the assistance of the synthesis, experimental planning, and data generation in the contexts of semiconductor, metal, carbon-based, and polymer nanoparticles. However, most current applications in the field focus on the identification and optimization of existing procedures, with some targeting the identification of novel particles and procedures.
3.3 Stabilization and Functionalization
After or during synthesis (e.g., during in-situ stabilization) and in the context of other unit operations (such as fine grinding, agglomeration, etc.), stabilization is required, as generated product particles would otherwise agglomerate uncontrollably. Identification of suitable stabilizers can be a laborious task, with the result and emerging properties often being unpredictable. Here, AI modeling can be a useful tool in predictive identification and the estimation of resulting properties in regard to solution or adsorption capabilities and resulting stability.
Prediction of solution capabilities: Astray et al. (2017) showed an AI model to predict the solution properties of alkylammonium surfactants such as density, surface tension, and kinematic viscosity as functions of input parameters such as concentration, carbon number, and the molecular weight of surfactants, with an R2 of 0.97.
Prediction of adsorption capabilities: Faghiri et al. (2019) trained an AI model based on least-square vector machines to predict the surfactant adsorption of sandstone in the context of oil recovery. Parameters were surfactant density, concentration, time, and kinetic adsorption density. Good predictive capability could be reached for kinetic adsorption density, with R2 accuracies for independent testing data of around 0.96.
Prediction of final stability: Kundu et al. (2016) focused on stabilization in emulsions. A hybrid multiple inputs and multiple outputs (MIMO) ANN-GA model was used to predict the formation and stability of (o/w) petroleum emulsions during stirring, with parameters being oil and surfactant concentration, stirrer tip speed, and pH value. Prediction errors were at around five percent.
Li L. et al. (2020) modeled the stability of Al2O3-ethylene glycol nanofluids via an ANN in dependence of particle size distribution and velocity ratio (the ratio between Brownian particle velocity and gravitational settling velocity). The nanoparticles in ethylene glycol were magnetically stirred and positioned in an ultrasonic bath. Input parameters were thermal conductivity, viscosity, mass fraction, and temperature. R2 accuracy ranged between 0.98 and 0.99.
3.4 Precipitation
Precipitation is an approach whereby the addition of agents or changes in other influencing parameters such as temperature in a solution can rapidly force specific materials out of the solution to form defined, mostly amorphous particles. In slower dissolution, the resulting particles crystalize. In both cases, the prediction of suitable conditions and the estimation of the result are difficult tasks, which usually involve much often intuitive manual experimentation to identify equilibrium states, resulting process kinetics, and the final amount of precipitate.
Equilibrium prediction: Leal et al. (2020) demonstrated an on-demand ML (ODML) algorithm to predict based on simulation results new chemical equilibrium states effecting precipitation in fluids on the basis of the already past chemical equilibrium states in reactive transport simulations to reduce computing costs based on simulation results.
Kinetics prediction: Nielsen et al. (2020) described an AI framework for modeling particle processes based on preexisting mechanistic process knowledge and sensor data to estimate underlying process kinetics. Three case studies of flocculation, crystallization, and fracture were described and modeled for the kinetics of different underlying processes such as nucleation, growth, shrinkage, fracture, and for agglomeration.
Final precipitate prediction: Hoseinian et al. (2020) demonstrated a hybrid neural network–genetic algorithm with first principle models for the prediction of ion flotation-based Zn(II) removal.
3.5 Mixing
Most processes require homogenous distributions, although on some occasions, controlled inhomogeneities can be desirable. Therefore, mixing is an important aspect, also due to energetic reasons. In particular, mixing parameters should be chosen to not exaggerate energy intake, which can cause inefficiencies, excess wear, or product degradation, etc. In addition to the modeling of the process, control modeling and monitoring are highly significant, as mixing is, in many processes, a highly influential parameter that often requires active and dynamic adaptations or continuous control during the process.
Qualitative and quantitative monitoring: Bowler et al. (2020) showed ML-based monitoring of a mixing process with ultrasonic sensors in which classification models were applied for the general mixing capabilities of materials and regression models for the progress monitoring for mixing time.
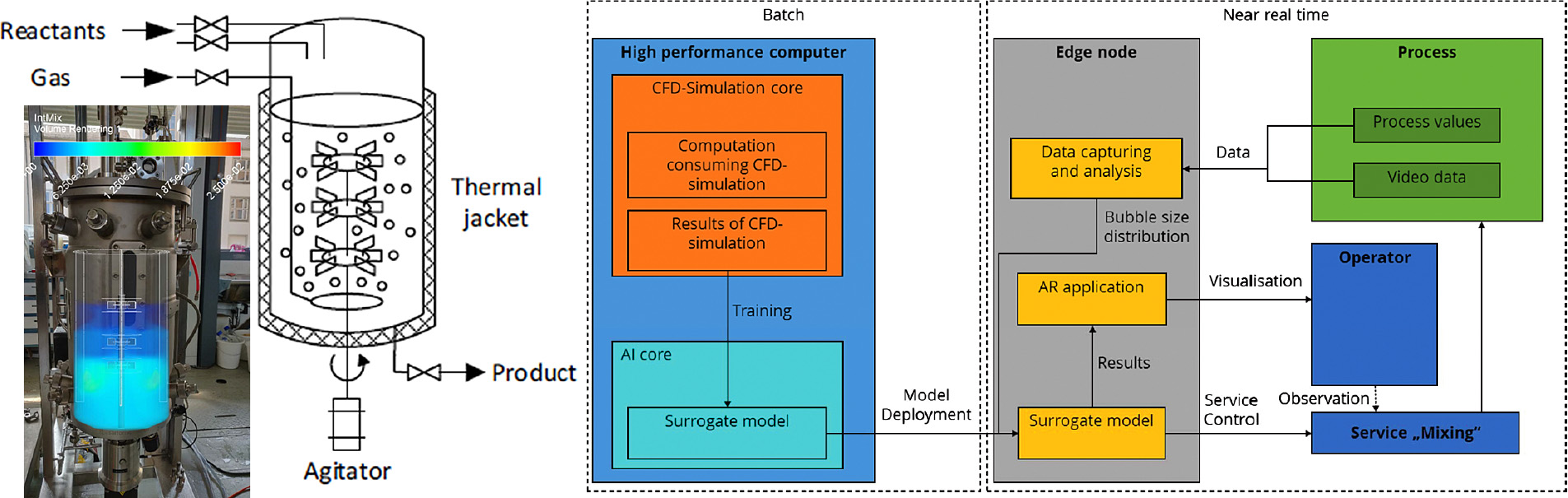
Predictive real-time digital twins: Khaydarov et al. (2020) demonstrated a hybrid surrogate model with bubble recognition and online video processing in a physical stirred tank reactor for the enhancement of a parallel-running AI-based surrogate model for a CFD simulation, as depicted in Fig. 11. The trained surrogate model could be implemented on a near real-time running edge-node, with online AR displaying the result for a human operator. As resource-efficient real-time modeling with direct feedback to human or machine interfaces is a desirable goal beyond mixing, the use case is interesting for other unit operations or plant operations. Furthermore, the given case demonstrates a quick mostly numerical AI-based digital twin for the real-time processing of the inner mechanisms of a parallel-running process, yet with periodic alignment to physical reality via direct measurement feedback (which can be a soft-sensor approach).
Mixing additive control prediction: Ittiphalin et al. (2017) demonstrated the addition of fat to a mixing process of feed pallets for animals. Among others, a backpropagation neural network was trained considering mold size, total percentage of fat, percentage of additional fat, percentage of fibers, and pallet shelf-life as inputs for the estimation of additional fat to be added. In order to achieve an optimum process for increasing the production rate and deteriorating pallet shelf-life with an increased fat content, optimal fat quantities can be added during the dynamic mixing process.
3.6 Aggregation
As described in precipitation and stabilization, primary particles can aggregate, agglomerate, or flocculate, which can be desirable under controlled circumstances. As in the previous operations, AI can assist in the prediction of suitable conditions and kinetics or the estimation or results. In addition to the prediction of specific given processes, it can also be used to identify suitable novel pathways within large parameter spaces.
Hybrid predictive kinetics modeling: Nielsen et al. (2020) described an AI framework for modeling particle processes based on preexisting mechanistic process knowledge and sensor data to estimate the underlying process kinetic rates of constitutive equations based on state variables and control actions. Depending on the investigated phenomena in the model, kinetic rates included one or more of the variables of nucleation, growth, shrinkage, agglomeration, and breakage. Three case studies, namely flocculation, crystallization, and fracture, were described and modeled for the kinetics of different underlying processes such as nucleation, growth, shrinkage, fracture, and agglomeration.
Aggregation pathway identification: Li J. et al. (2019) described the accelerated synthesis of gold nanoclusters with AU(III) to Au(I) reduction and subsequent coordination via thiolate ligands for complexation, considering all relevant parameters to identify likely patterns for the successful synthesis of nanoclusters using deep learning (DL).
Combined structure and pathway prediction: Wahl et al. (2021) demonstrated a ML-based approach to predict both the aggregate particles (polyelemental heterostructures) via colloidal self-assembly, as well as the way in which they formed, using a technique called a diffuse map. The approach proved capable of predicting many body phenomena and long-term assembly dynamics.
3.7 Extrusion
Another significant process in particle technology is extrusion. In this process, particles, and eventually, a fluid are first conveyed and then mixed. In the second step, the compression and shearing of a viscous mass under high pressure and temperature take place, then the mass is finally pressed through a shape-giving opening. The parameters are highly interdependent, and the selection of optimal operating conditions is usually time-consuming and increasingly costly. Consequently, the quality control of the extruded material is associated with various challenges, including the control of process parameters such as velocity and temperature or of the final product quality. Therefore, a more intelligent method needs to be developed. To achieve this goal, AI methods can be beneficial, in addition to being able to close the gap between often used simulations and accurate but costly experiments. In the following extrusion processes, pure polymers are described as the AI methods can be used similarly for particle-filled polymers.
Curing property prediction: Marcos et al. (2007) demonstrated the prediction of the extrusion properties of rubber, relying on compound composition and mixing conditions during extrusion. Despite being applied to molten rubber in this case, extrusion is often based on granular material, e.g., in many extrusion processes for battery production, wherefore the general approach is also of interest in the context of particle technology. Online information about specific curing properties can be predicted via integration into the process, eliminating waiting time for laboratory results and increasing product traceability.
Velocity control: Martínez-de-Pisón et al. (2010) presented a dynamic model for extrusion velocity control, which was capable of controlling manufacturing processes based on previously successful start-ups with data about pressure, temperature, and velocity. The complexity of this task was due to the open-loop control system and the constant alterations inherent to the process.
Temperature control: Taur et al. (1995) proposed a fuzzy PID temperature controller for the temperature control of the extruder cylinder using if-then rules and membership functions.
Tsai and Lu (1998) developed a predictive fuzzy PID controller with single-loop monitoring for extruder cylinder temperature control.
Quality control: Liu X. et al. (2012) proposed dynamic gray-box modeling based on a soft-sensor approach to control the quality of polymer extrusion. In this article, an attempt was made to use a gray box to provide real-time monitoring of the quality of the extrudate in order to reduce the setup time and improve the operation of the system. In this work, a soft-sensor structure was combined with a feedback observer to estimate the viscosity and control the final quality of the material.
Simulation-experiment translator: Bajimaya et al. (2007) used an ANN to predict the process parameters in extrusion. Simulation analyses are usually unable to take into account the boundary conditions of the manufacturing process, which is why their results remain mainly theoretical. On the other hand, conducting experiments is usually expensive and time-consuming, which is why the use of AI methods can reduce the gap between simulation and real data. The trained AI algorithm acted as a transfer tool to translate the theoretical variables gained from finite element method (FEM) simulations such as stress, strain, and shearing into realistic measures for extrusion pressure, temperature, and velocity.
3.8 Classification
Classification has many applications in particle technology that can be performed analytically to determine distributions or properties or as physical separation according to the respective properties. There exist many separation categories, with some being easier to implement, such as the classification of compact particles according to size, e.g., via sieving. For other aspects such as morphology or composition, sorting can be difficult. In such cases, manual human involvement or application-specific hardcoded automation is often required, but this can be expensive, unreliable, and inflexible and can limit the quantities that can be processed. Consequentially, the application of AI is a viable alternative in such instances.
Analytical classification with machine vision: Gonçalves et al. (2010) demonstrated an ANN-based technique of analytically classifying microscopic wear particles. Binarized particle images were obtained, and features such as area, perimeter, width, height, diameter, circularity, ferret diameter, elongation, and aspect ratio were obtained via ImageJ. Supervised classification reached accuracies of around 95 percent.
Massarelli et al. (2021) used computer vision and ML to analytically (i.e., with no physical separation involved) classify and count particles depending on dimensional size and morphology. The particles could be classified under supervision according to predetermined groups or without supervision to act as a measure for sample representativeness and in order to identify hidden features.
Physical separation: In addition to mere analytical classification, physical sorting can be performed, as Kattentidt et al. (2003) demonstrated, for the sorting of bulk solids. In an online operation, AI-based quality control was performed with two optical sensors for the separation of recycled glass. Distinguishing features were dimensionality, surface area and volume, texture, morphology, homogeneity, conductivity, and spectral reflection. Finally, a separation unit sorted the bulk material into dedicated fractions.
The AI-based sorting of particles, also in the context of recycling, has the potential to be a crucial pillar for a circular economy. For instance, Wilts et al. (2021) demonstrated AI-based waste sorting via a robotic arm and a sorting belt with a multitude of sensors (metal detector, high-resolution RGB camera, NIR sensor, VIS sensor).
Furthermore, Peršak et al. (2020) demonstrated the sorting of transparent plastic granulates based on computer vision and subsequent pneumatic air separation. The plastic particles had sizes of 2–4 mm, sorting accuracy for 9 classes equaled 90 percent, and for two classes, it was 100 percent.
3.9 Characterization and Analysis
In almost all cases, after or during unit operations, the characterization of properties and their distribution is required. Sometimes, these can easily be gathered, while in other cases, directly obtaining the required data can be challenging or impossible due to limitations in measurement equipment, physical constraints, accessibility during operations, etc. Often, analysis is possible but limited in regard to the executable quantity due to the nature of the measurement technique or the hardware. In all these cases, AI can be a useful technique to use with parallel running predictive or surrogate models, as these can be enriched by limited physical information, as previously shown in the case of mixing (Khaydarov et al., 2020). In addition to use in soft sensors, AI and evolutionary approaches can be used to enhance measurement results through post-processing or to derive mechanical descriptions of the measured properties and their influencing parameters.
AI as a soft sensor: Reliable predictive models can also be used to directly replace measurement, or as additional assistance in the context of soft sensors.
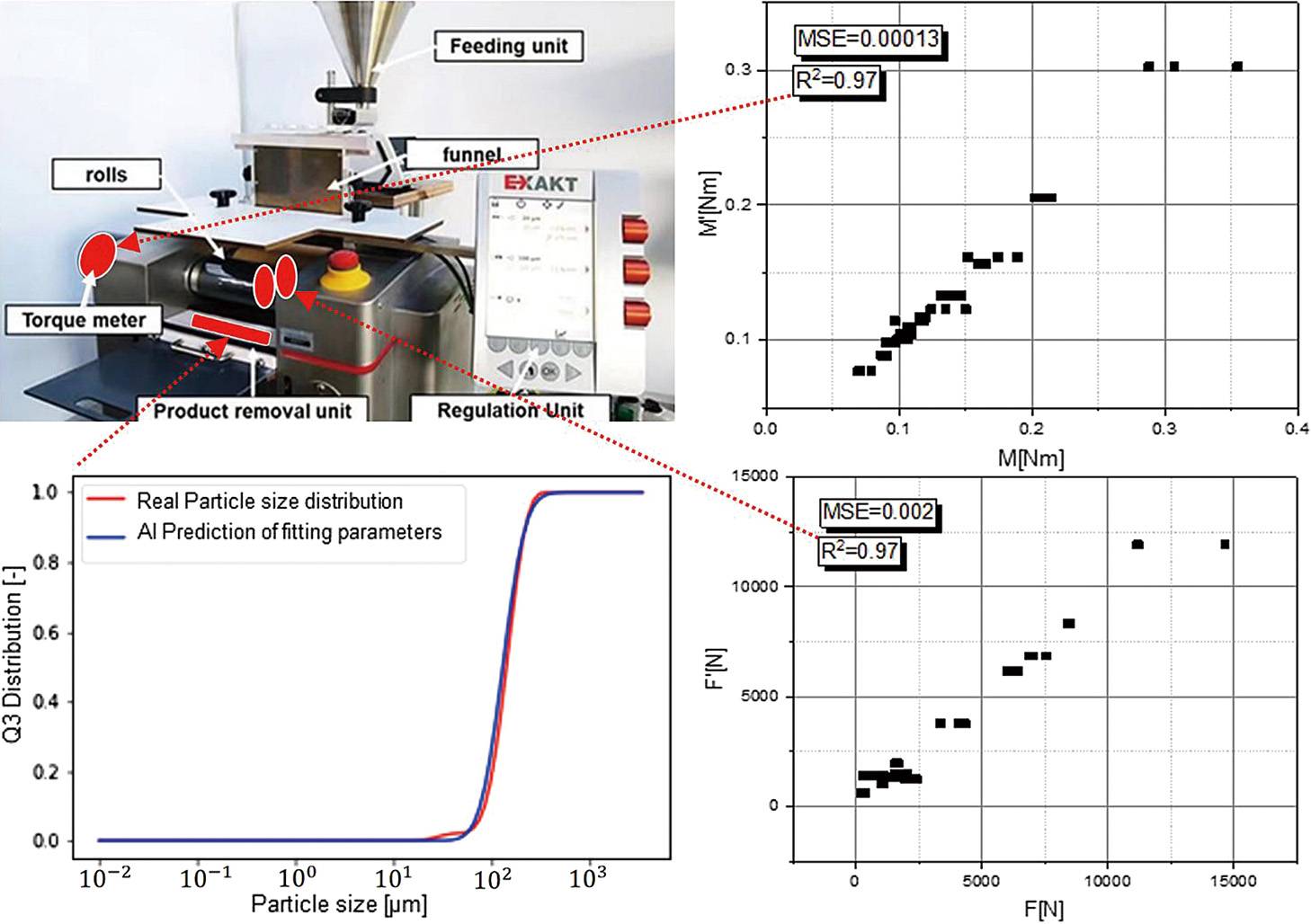
An important characterization method for particle breakage is the particle breakage function, which can be determined via a breakage tester, as described in Böttcher et al. (2021) (see Fig.12).
In the breakage tester, rotational velocity and gap size can be adjusted, while torque and normal force between the rollers are measured. Based on GRL for rotational velocity, with gap size and initial particle size as input parameters, a predictive model was trained for the prediction of power, force, and resulting particle size via two fitting parameters. Both, the prediction of power and force achieved high accuracies, with an R2 in both cases of 0.97.
Sun et al. (2017) successfully trained a three-layer neural net for the prediction of electron transfer properties such as the Femi energy of silver nanoparticles and successfully identified correlations with structural and morphological features.
Measurement improvement: Furat et al. (2022) applied generative adversarial networks (GANs) to retrospectively super-resolve images of particle based Li-ion electrodes for the quantification of features such as the identification of cracks in aged cathodes. Consequentially, the trade-off between resolution and field of view in the SEM imaging of bulk-pictures was significantly reduced.
Mechanistic analysis measure modeling: GAs provide another AI method that is often used for optimization tasks by mimicking the process of evolution involving the mutation, selection, and reproduction of system states and parameters. Finke et al. (2021) used a GA for the identification and optimization of suitable model parameters for a viscosity model of nanoparticulate suspensions.
3.10 Other Applications
A method with great potential for future applications is a combination of nature-based or mathematical algorithms and AI.
Drilling and blasting through hybrid models: One possible hybrid approach was introduced by Mojtahedi et al. (2019), which was developed for the prediction of particle size distribution in mining and is presented below.
Drilling and blasting are the most widely used methods in mining for rock crushing. In order to describe the fragmentation, the ANFIS method was combined with the firefly algorithm (FA). By extending a fuzzy inference system (FIS) with an artificial neural network (ANN), the system becomes self-learning and can solve nonlinear complex problems. In addition, the combination of ANFIS with the FA provides an ability to determine optimal values for complex nonlinear problems. More precisely, the FA describes a nature-based algorithm of firefly social behavior, where the convergence speed of the algorithm is high and the number of iterations for an optimal result is low. The objective of the ANFIS-FA was to predict the D80 (the 80 percent passing size at which 80 percent of the particles are smaller) value for different input parameters of the resulting particle distribution, using a data set from 88 blasting operations at the Shur river dam in Iran. For further validation of the predictions, the ANFIS-FA method was contrasted with linear multiple regression (LMR) methods alongside the test data set.
Six different hybrid models were created, each differing in the choice of input parameters used. Each of these models achieved higher R2 values with a minimum of 0.856 in predicting the D80 value than the LMR method, with 0.669 in relation to the test data set.
In summary, combining AI methods with existing algorithms has been demonstrated to significantly improve the accuracy of particle size predictions (Mojtahedi et al., 2019).
5. AI-based design and scale-up
In addition to modeling, the optimization or control of individual processes such as synthesis, grinding, analysis etc., the design, modeling, and control of plants and complex networks as a whole, as well as layout and optimization, including the design of the underlying processes and units, is of major economic significance. Using AI for design, layout, optimization, or scale-up can lead to significant savings and improved efficiency.
Other than for the task or unit’s specific applications, elaborated on earlier in the publication, adoption of AI in particle technology in this respect is still in an early stage. However, there are some examples, more advanced examples, and real-world applications in other fields, with the used approaches being transferable to particle technology, e.g., the use of GAs for the autonomous design of heat exchangers, which can be easily adopted for the design of milling geometries.
Generally, two major approaches can be distinguished, the design and optimization of dedicated production systems, processes, unit operations, plants, and logistics infrastructure for dedicated goals or the intelligent dynamic identification, connection, and management of suitable (potentially decentralized) infrastructure already in existence.
The former method of dedicated design tasks can be used for basic operations or if products will be required in the long term and in large quantities, making application-specific inflexible yet efficient high-throughput systems a suitable option.
With GAs, Wisniewski (2004) demonstrated an optimal design of reinforcing fibers within a composite, while Jatti et al. (2013) optimized the milling of aluminum alloys. For the design of process units, RatnaRaju and Nandi (2013) used GAs for the construction of heat exchangers while considering pressure drop and effectiveness.
In contrast to evolutionary techniques, Lee X.Y. et al. (2019) used deep reinforcement learning for micro-fluidic flow sculpturing, finding it to be superior to a GA approach. Similarly, with classical AI techniques such as neural nets, Sarkar et al. (2019) demonstrated an autonomous design of a compressor rotor and optimization through AL.
Specifically, GANs, in which two competing AIs train each other, are useful for the design process. In this approach, a generator learns from training examples in order to produce similar results, while a discriminator AI evaluates the results and learns through feedback to improve the accuracy of its evaluation. Being mostly known from deep fakes, the generation of realistic images, they can also be applied to generate solutions for given problems. Via the iterative interaction of generator and critique AI, the two networks improve each other’s capabilities.
Chen and Fuge (2019) demonstrated GANs for design synthesis, the generation of hierarchical designs in conjunction with generative models. Similarly, Oh et al. (2019) applied GANs for the generation of 2D wheels. Nobari et al. (2021) demonstrated autonomous design synthesis for constrained 3D geometry generation for different purposes via deep generative models and constraint GANs.
In addition to the complete execution of the design process, AI can be used in a semi-automated manner to assist manual design endeavors. For instance, Khan et al. (2019) discussed iterative design adjustment in the construction endeavor in a loop with user feedback. Similarly, Deshpande and Purwar (2019) demonstrated the solution generation of mechanisms and synthesis for abstract inputs.
Raina et al. (2019) applied transfer learning to incorporate historical design strategies from past cases into AI systems. Combining these approaches in the future, a closed loop of adjustment with continued learning based on human feedback can be implemented.
Similarly, GA-, ANN-, and GAN-based design or the evolution of design strategies can be applied for processes or production units in particle technology, such as in the design of mill geometries and operating conditions or for the morphological features of product particles.
In regard to the second major variant in design, optimization and scale-up, the intelligent management and interconnection of existing infrastructures, units, systems, and processes, a key foundation is digital twins, which can be predictive AI models, as already discussed in this publication. Cyber-physical systems, which include sensors, communication, computation, and control elements, are closely associated with digital twins as virtual representations of physical systems. Ideally, they rely on a digital twin for monitoring, control, and autonomous decision-making (Lee E.A., 2008; Tao et al., 2019). Together with cloud computing, big data, and the internet of things (IoT) as the foundation, both cyber physical systems and digital twins, which can rely heavily on AI, are important components of the concept of smart factories and industry 4.0.
As already discussed, in a fixed production environment, management and control are vital for the dynamic interconnection and allocation of resources, units, processes, or entire plants in a decentralized (potentially global) manner while considering the available infrastructure and its flexibility, intelligent supply chain management and decision-making are of paramount importance. Toorajipour et al. (2021) performed a more detailed review of AI in supply chain management and successive decision-making, focusing on marketing (including sales, pricing, segmentation, consumer behavior, decision support, direct marketing, industrial marketing, new products, etc.), logistics (containing container terminal operations, inbound, logistics automation, sizing, etc.), production (assembly, integration, product driven control, etc.), and the supply chain itself (facility location, supplier selection, supply chain network design, risk management, and inventory replenishment), with references to specific examples. Supply chain management and autonomous decision making are important aspects that mirror, to a large degree, process control in a fixed system, although challenges in a dynamic decentralized system can strongly outweigh those in a fixed system.
In terms of the online monitoring of large connected production systems, the company Hosokawa Alpine (2019) applies an ML-based platform intelligent software assistant (ISA) for the maximization of efficiency and quality.
Regarding the supply chain network design under consideration of profit maximization, Zhang et al. (2017) demonstrated a competition-based intelligent physarum solver.
Wang et al. (2012) demonstrated autonomous collaboration between heterogeneous actors (multi-robotic systems) and AI to solve complex formation performance in a dynamic environment.
In regard to the dynamics of product life-cycles and supply chain networks and the resulting inbound fluctuations, Knoll et al. (2016) demonstrated predictive inbound logistics planning.
Kwon et al. (2007) presented an integrated multi-agent framework to solve collaboration tasks in supply chain management in regard to supply and demand uncertainties.
In cases when human supervision is desired, Kasie et al. (2017) demonstrated a decision support system combining AI and discrete-event simulations (DES), as well as database management.
Applied to particle technology, the existing production sites addressed earlier in this review can be intelligently connected in a dynamic, decentralized, self-organizing structure based on digital twins and cyber physical systems. Based on AI market prediction, as well as autonomous real-time monitoring and decision making, the cost and efficiency benefits of smart factories and industry 4.0 can be adopted more progressively in the field of particle technology.

 https://ror.org/010nsgg66
https://ror.org/010nsgg66 

;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/41_2024011_15.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/41_2024011_16.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/41_2024011_17.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/41_2024011_18.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)
;%0A%09%09%09newWindow.document.open();%0A%09%09%09newWindow.document.write('<img src=%22./Graphics/41_2024011_19.jpg%22>');%0A%09%09%09newWindow.document.close();%0A%09%09)