
- |<
- <
- 1
- >
- >|
-
Naoya SAWAGUCHI2022Volume 21Issue 1 Pages A1-A2
Published: 2022
Released on J-STAGE: August 22, 2022
JOURNAL FREE ACCESS FULL-TEXT HTMLDownload PDF (391K) Full view HTML
-
Rumiko TANAKA, Shin-ichi NAKAYAMA2022Volume 21Issue 1 Pages 1-9
Published: 2022
Released on J-STAGE: August 05, 2022
JOURNAL FREE ACCESS FULL-TEXT HTMLTo effectively utilize the knowledge on chemicals, it is necessary to efficiently extract, organize, and collate the names of core chemical substances and their respective structures, functions, manufacturing methods, chemical reactions, and uses. This activity, indeed, takes time and effort. While extracting the names of these substances from Japanese sentences, it is important to remember that unlike English, Japanese words are not separated by spaces or symbols. Therefore, firstly, one needs to perform a morphological analysis of the chemical names, divide them into distinct words, and group them accordingly. When an additional word comes to be attached to the name of a chemical substance owing to the bonding of unnecessary words, it needs to be removed. In this study, we focus on the character type, arrangement, and context of the names of these chemicals in Japanese sentences. We created a corpus tagged with the chemical names extracted from patent publications and used it as training data material for a machine learning model. Further, we examined the possibility of extracting the chemical names using this method.
View full abstractDownload PDF (1193K) Full view HTML -
Tsubasa KANEZAKI, Gakushi ISHII, Kyozaburo TAKEDA2022Volume 21Issue 1 Pages 10-19
Published: 2022
Released on J-STAGE: August 05, 2022
 JOURNAL FREE ACCESS FULL-TEXT HTML
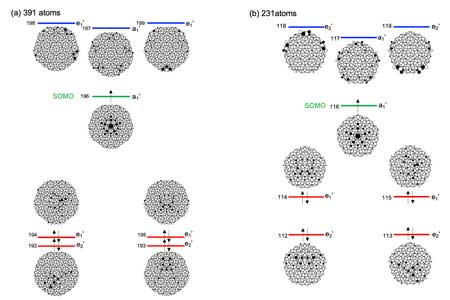
JOURNAL FREE ACCESS FULL-TEXT HTMLPenrose tile cluster (PTC) is an ideal lattice of the two-dimensional (2D) quasicrystals, having a short-range order and a long-range aperiodicity (Figure 1). Focusing on these novel geometrical properties, We here study the electronic structure of PTCs and extract their inherent characteristics. For the systematic understanding of PTCs' electronic structures, we employ the tight-binding (TB) approach, combining the Slater-Koster method with Harrison's transfer integrals. The present TB calculation demonstrates that the five-fold rotational symmetry and the long-range aperiodicity result in an interesting state localized at the central position of PTCs (Figure 3). Of more an interest, the resultant state is "insensitive" to the PTC peripheral structure owing to its central localization. Accordingly, this state possibly changes into the SOMO when one modifies the PTC periphery by the removal/addition of atomic groups with conserving the five-fold symmetry (Figure 6). As such, the short-range order and long-range aperiodicity in PTCs has a potential to result in a naked spin localized at the central part.
View full abstractDownload PDF (7356K) Full view HTML -
Masahiro OHTOMO, Takashi KOBAYASHI, Hiroaki KATO2022Volume 21Issue 1 Pages 20-32
Published: 2022
Released on J-STAGE: August 05, 2022
 JOURNAL FREE ACCESS FULL-TEXT HTML
JOURNAL FREE ACCESS FULL-TEXT HTMLIn eukaryotic genome sequences, there are exons that are translated into proteins, and introns that are not. It is important task to estimate the functional sites in the genome sequence. In the other hand, it is well known that the amino acid sequence of a protein is closely related to its function. This is especially true for particular structural features called motifs, and they are considered to be well reserved sites in the genome sequence. In this work, we have developed the Dynamic Programming (DP) -based functional site estimation system using the codon reduced representation and its approximation. The motif codon reduced representation has been also proposed based on codon weight matrix which is represented frequency of each nucleotide corresponding to the amino acid sequence in PROSITE motif. PROSITE is public database of motif dictionary. Our system successfully estimated Coding sequence (CDS) region in TNNC1 genome sequence of Human. The experiments were also executed using EF-hand motif in TNNC1 and HPCA genome sequence of several model species including Human. These results show the potential applicability of our approach for the functional sites in genome sequence.
View full abstractDownload PDF (4577K) Full view HTML
- |<
- <
- 1
- >
- >|